Podobno, o ile twoim jedynym narzędziem jest młotek, wszystko zaczyna Ci przypominać gwoździe. Jako inżynier machine learning warto by było mieć w swoim narzędziowniku coś więcej niż tylko młotek.
Trochę tak jak z matematykiem, który dostał deskę z dwoma wbitymi gwoździami. Jeden gwóźdź był wbity do końca, a drugi trochę wystawał. Popatrzył na deskę i stwierdził:
– Przypadek z gwoździem wbitym do końca jest ciekawszy.
I zajął się tym przypadkiem… Po długich męczarniach udało mu się wyciągnąć gwoźdź wbity do końca.
Został ten niedobity. Patrzy… myśli…
– A ten przypadek możemy sprowadzić do rozwiązywanego uprzednio problemu.
I wbił gwóźdź do końca…
Nie wbijaj gwoździa do końca. W ogóle – odczep się od tych gwoździ!
Chcesz wydajnie pracować nad rozwiązaniami uczenia maszynowego. Co powinieneś włożyć do swojej skrzyneczki z narzędziami inżyniera machine learning?
1. Python
Tutaj krótko. Jak chcesz zajmować się uczeniem maszynowym, musisz znać Pythona. Nie mówię o znajomości na poziomie turbo eksperta, ale podstawy musisz znać. Dlaczego, spytasz? Wszak władasz Javą niczym indyjski flecista kobrami.
Ano dlatego, iż w świecie ML większość bibliotek i frameworków jest tworzona w Pythonie. Rad nie rad, na prawdę warto go poznać. Ale nie lękaj się, Python jest prosty. No heloł, ja w nim piszę, więc nie może być trudny.
2. Terminal / Linux Shell
Jeżeli nigdy nie używałeś terminala / konsoli / shella, to zdecydowanie powinieneś zacząć. Ja wiem, iż wydaje się, iż szybciej jest coś przeklikać, niż pisać mozolnie komendy (a w początkowej fazie kopiować komendy z forów).
Moim zdaniem jest to całkowicie mylne przeświadczenie. Im bardziej przyzwyczaisz się do operowania klawiaturą zamiast myszki, tym częściej docenisz, jak to terminal ułatwia Twoją pracę.
Dlaczego warto korzystać z konsoli?
Żeby wyglądać cool w oczach zwykłych śmiertelników.
A tak serio to:
a) Szybkość – rzadziej przełączasz się mysz – klawiatura. Masz wszystko pod ręką. Nie ma GUI, nie ma narzutu na klikanie, szukanie, a choćby RAM! No dobra to ostatnie to w dzisiejszych czasach przeginka.
b) Automatyzacja – po opanowaniu podstaw pracy w terminalu jest krótka droga do automatyzowania sobie często wykonywanych czynności. Wszystkie powłoki (cmd na Windows, bash / zsh / fish na Linuksie czy Macach) pozwalają na pisanie skryptów.
Czy muszę zostać mistrzem terminala, żeby być inżynierem uczenia maszynowego? Wystarczy, iż dobrze opanujesz podstawy, a gwarantuję, iż to ułatwi Ci codzienną pracę.
Dodatkowo, warto znać poniższe narzędzia.
SSH – sięgaj tam, gdzie wzrok nie sięga!
W końcu trzeba wyjść z pieleszy własnego laptopa i zrobić coś na zdalnym serwerze. Wtedy, gdy trzeba podłączyć się do jakiegoś samotnego komputera na drugim końcu świata z pomocą przyjdzie SSH! Tak, dobrze przeczytałeś. Do innego komputera. Ja wiem, iż teraz wszyscy operują w chmurze, ale mam złą wiadomość…
 There is no cloud it’s just someone else’s computer.
There is no cloud it’s just someone else’s computer.Aby pierwszy raz podłączyć się do zdalnej maszyny musimy mieć na niej utworzone konto (znać login i hasło), a także znać adres IP lub nazwę hosta, którą możemy wykorzystać do połączenia. Samo połączenie jest dosyć proste. W terminalu wykonujemy komendę
Przy pierwszym połączeniu dostaniemy komunikat o tym, iż “halo halo, tego serwera to ja jeszcze nie znam”. A dokładniej, nie mam o nim informacji w pliku known_hosts. Komunikat wygląda tak:
Wklepujemy Enter i już jesteśmy na zdalnej maszynie. Komendy, które od tej pory wprowadzimy, będą się wykonywały na serwerze, do którego jesteśmy podłączeniu.
Na Windowsie do połączenia przez ssh będzie potrzebna oddzielna aplikacja, bo “Wiersz poleceń” domyślnie dostępny w Windows tego nie ogarnie. Polecam (i nie tylko ja) narzędzie o nazwie PuTTy.
TMUX – nie strać tego, co ważne!
Jest to moim zdaniem podstawowe narzędzie, które musisz znać, o ile łączysz się po SSH do zdalnych maszyn. Dlaczego? Bo o ile (nie)chcący zamkniesz okno terminala albo zerwie Ci połączenie internetowe, to zrywana jest sesja.
A no i jak zerwie sesję to wszystkie procesy są ubijane. Tak, jakbyś się wylogował. A o ile np. uruchomiłeś długo trwające obliczenia, to raczej tego nie chcesz, prawda?
Co nam daje TMUX?
- Możliwość zachowania sesji po rozłączeniu połączenia. o ile wyrzuci nas z jakiegoś powodu z sesji, to wystarczy, iż po ponownym podłączeniu do serwera wydamy polecenie tmux a i wracamy do stanu sprzed rozłączenia!
- Tworzenie wielu „okien”. TMUX pozwala nam pracować na wielu „kartach” / „oknach”. Do tego, możemy dzielić ekran jednego okna na tzw. pane’y – czyli na jednym ekranie możemy mieć uruchomione wiele oddzielnych sesji.
- Dodatkowe informacje na pasku stanu. Tutaj wiele zależy od tego, jak sobie skonfigurujesz tmuxa. Po fajne inspiracje zapraszam np. tutaj.
 Okno terminala z uruchomionym TMUXem
Okno terminala z uruchomionym TMUXemNo prawie fajnie, ale jak się po tym poruszać?
Ctrl+b Twoim przyjacielem. TMUXa używasz wykorzystując skrót modyfikatora (bind key) + inny klawisz. Startowo skrót modyfikatora to Ctrl+b, ale można to zmienić. A resztę znajdziesz pod hasłem TMUX cheatsheet
Vim / Nano – zmieniaj, bo kto nie ryzykuje, ten nie pije szampana!
Na zdalnej maszynie nie będziesz miał dostępu do graficznych narzędzi. Warto się zaprzyjaźnić z Vim*, bo jest to edytor dostępny domyślnie na większości najpopularniejszych dystrybucji Linuksa.
* czy Vim się odmienia?
Uwaga, będzie żart:
– Jak wygenerować losowy ciąg znaków?
– Posadzić użytkownika Windowsa przed Vim i kazać wyjść.
BADUM TSS
Po opanowaniu podstawowych komend i swoistego języka edytora Vim może on być bardzo dobrym edytorem, choćby na codzień. Do Vim można instalować pluginy i dzięki temu rozszerzać jego funkcjonalności, a wręcz stworzyć pełnoprawne IDE obsługiwane tylko klawiaturą.
Drugim z edytorów jest Nano. Jest dużo prostszy w obsłudze, ma „bardziej ludzkie” skróty klawiszowe, ale nie oszukujmy się, funkcjonalnie przy Vim jest jak Notatnik przy PyCharmie Chociaż do szybkiej, prostej edycji wystarczy.
Skrypty
No i to co jest największą zaletą pracy w terminalu, a w zasadzie z powłokami (ang. shel) takimi jak bash. Te komendy, co je mozolnie kopiujemy z forów internetowych, można składać w całe skrypty, okraszone standardowymi wygibasami programistycznym, takimi jak zmienne, pętle czy instrukcje warunkowe.
Dzięki temu, możemy w prosty sposób automatyzować często powtarzalne czynności, a następnie wykonywać je jednym poleceniem w terminalu.
Ale ja mam Windowsa!
Stało się, korzystasz z Windowsa. Wydaje się, iż jedyne, co masz do wyboru, to Wiersz poleceń (cmd). Niby wygląda podobnie jak linuksowa konsola, ale to trochę jak Maluch vs Audi RS6 – i to i to jeździ, ale tym drugim – można więcej i szybciej. Czy jesteś skazany na cmd?
Otóż nie. Masz co najmniej dwie drogi.
- Cygwin (nie, nie pingwin) – czyli narzędzie umożliwiające uruchamianie sporej liczby narzędzi Open Source dostępnych na linuksa. Nie uruchomisz tam każdej aplikacji dostępnej na linuksa, ale sporo najczęściej wykorzystywanych jest tam do wykorzystania.
- Windows Subsystem on Linux (WSL) – o ile masz Windows 10, to masz już z górki. Uruchamiasz WSL i masz pełnoprawne jądro Linuksa na Windowsie. Piękne
3. GIT
Git to rozproszony system kontroli wersji. Przechowuje historię plików. Co w jakim pliku się zmieniło. Jakie pliki zostały usunięte. Jakie dodane. Kto jest autorem danej zmiany (git blame FTW!).
Git jest “obowiązkowym” wyposażeniem każdej szanującej się drużyny programistycznej. Ale choćby o ile działasz solo, warto go używać. Chociażby po to, żeby móc w przypadku jakiejś pomyłki uruchomić wehikuł czasu i cofnąć się do miejsca, gdzie nasz kodzik był piękny, pachnący i działający.
 Podstawowa instrukcja bezpieczeństwa w zespołach programistycznych. Źródło
Podstawowa instrukcja bezpieczeństwa w zespołach programistycznych. ŹródłoZ Git można korzystać na różne sposoby.
Są dostępne GUI, które pozwalają zarządzać Twoimi repozytoriami. Przykłady? Wejdź tutaj i przebieraj niczym dzik w truflach.
IDE czy edytory programistyczne, jak PyCharm, VS Code, Atom czy SublimeText, mają często albo wbudowaną obsługę Gita, albo możliwość doinstalowania rozszerzenia. Wtedy już z poziomu edytora widzimy jakie pliki się zmieniły, co się zmieniło, na jakiej gałęzi (ang. branch) pracujemy, itp.
Ale i tak, najlepszym klientem Gita jest…
Klient terminalowy! Chcemy jak najwięcej pracować w terminalu, żeby ujednolicać sobie środowisko. A Git w terminalu ma przepotężne możliwości.
Naprawdę warto poświęcić trochę czasu, żeby przejrzeć jakiś kurs gita, zapoznać się z jego możliwościami, a potem – korzystać!
4. (Ana)Conda
Powoli robi nam się tu małe zoo. Małe Gadzie Zoo Inżyniera Machinie Learning… Najpierw Python, po drodze pingwin, a teraz Anaconda. Po co nam drugi wąż w arsenale?
Otóż Anaconda jest menadżerem pakietów (package manger) a jednocześnie menadżerem środowiska dla języków takich jak Python czy R. W bardzo prosty sposób umożliwia instalowanie potrzebnych nam narzędzi i bibliotek.
Jeśli miałeś wcześniej styczność z Pythonem, pewnie w głowie zapaliła Ci się lampka.
– Hola hola, a czym się różni anaconda od virtualenv, pyven, venv, albo tego no, jak mu tam, pip?
W skrócie: anaconda łączy w sobie możliwości menadżera pakietów (package manger) i menadżera środowiska (environment manager):
- virtualenv, pyven, venv służą do tworzenia środowisk;
- pip – służy do instalacji pakietów wewnątrz środowiska;
- conda – ogarnia i to i to.
Dodatkowo, nic nie stoi na przeszkodzie, żeby wewnątrz środowiska utworzonego w Conda zainstalować pakiet przy użyciu pip. Jednak warto, o ile paczka istnieje, trzymać się condy jako głównego “instalatora”.
I ostatnie, równie ważne. Pip działa tylko z Pythonem. Conda – ogarnia Pythona i R.
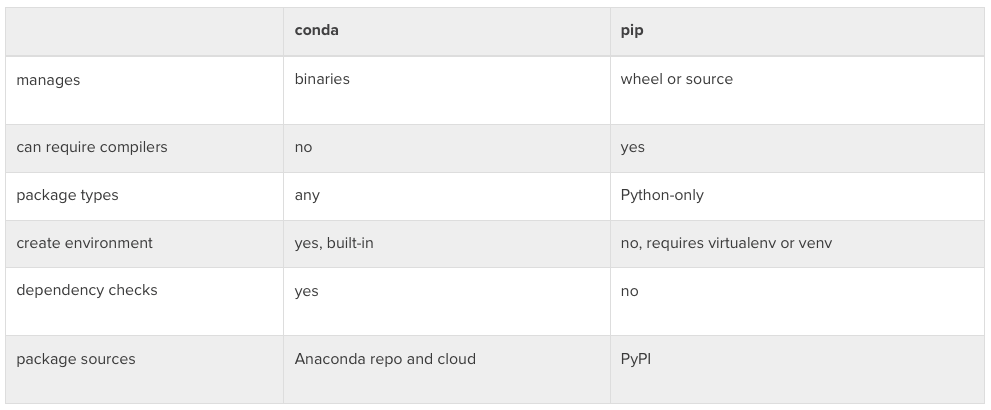 Różnica pomiędzy conda i pip. Źródło
Różnica pomiędzy conda i pip. ŹródłoPodsumowując – Conda jest fajnym narzędziem, po które chętnie sięga inżynier machine learning . o ile jesteś developerem Pythona i nie interesuje Cię ML – pip + venv będzie lepszy.
Wybór ostatecznego narzędzia i tak zostawiam Tobie, ewentualnie Twojemu zespołowi – bo warto mieć pewną spójność, gdy pracujemy w więcej osób przy jednym projekcie.
5. Jupyter Notebook
“Zerkniesz na tego notebooka?”
“Przesłałem Ci notebook z rozwiązaniem.”
“Odpal sobie Jupyter’a.”
Jupyter Notebook to bardzo często spotykane narzędzie w świecie Machine Learning. Jest to webowe środowisko do tworzenia dokumentów, w których możesz dowolnie mieszać kod, wizualizacje i tekst “pisany”. Dzięki temu można tworzyć analizy, prezentować proces myślowy, okraszać nasze przemyślenia obrazami oraz popierać je danymi, które generujemy na bieżąco dzięki wykonaniu kodu.
 Jupyter Notebook w całej okazałości. Źródło
Jupyter Notebook w całej okazałości. ŹródłoKod możemy uruchamiać komórka po komórce. Pozwala to nam w bardzo prosty i szybki sposób eksperymentować, podmieniać, podglądać, patrzeć co się dzieje wewnątrz naszego kodziku. I właśnie dlatego to narzędzie tak dobrze przyjęło się w świecie data science czy machine learning.
Co więcej, w Notebookach można pisać w Pythonie, R, Julia albo Scali.
Sam notebook to format pliku oparty o JSON. Niby nic. Ale ale! Pod tym prostym JSONem jest uruchomiony kernel, który odpowiada za wykonywanie kodu z komórek. Możemy też mieć wiele różnych kerneli i się pomiędzy nimi przełączać (np. Python 2 i Python 3)
Warto też zerknąć na Jupyter Lab - czyli webowe IDE dla Jupyter NotebookówJest to często podstawowe narzędzie każdego, kto ma styczność z Data Science lub Machine Learning. Łączenie kodu, wizualizacji i opisu, a dodatkowo możliwość dzielenia się wynikami swojej pracy z innymi.
Rozwiązanie idealne? Prawie. Ma swoje wady. Kto próbował merge’ować notebooki w GIT, ten się w cyrku nie śmieje…
Ale do szybkiego prototypowania i eksperymentowania – niezastąpione.
O czymś zapomniałem?
Czy pozostało jakieś narzędzie, bez którego wg szanujący się inżynier machine learning nie jest w stanie wydajnie pracować? Coś, co używasz każdego dnia i pomaga Cie w pracy z modelami, danymi, kodem, wersjonowaniem? Podziel się proszę w komentarzu!
Może uda się stworzyć mini-toolbox inżyniera uczenia maszynowego, który będzie można pokazywać każdemu, kto chce zająć się uczeniem maszynowym