Problematyka podatności bezpieczeństwa dotyczy praktycznie wszystkich programów lub bibliotek wykorzystywanych w codziennej pracy. Proaktywność w tej kwestii jest jednym z kluczy do dostarczania wysokiej jakości oprogramowania, które zapewni spokojny sen osobom zajmującym się bezpieczeństwem IT.
W ciągu ostatnich dwóch lat firma Google dzięki inicjatywy OSS-Fuzz, wykryła oraz zgłosiła ponad osiem tysięcy błędów w szerokim spektrum projektów open source, m.in. Tor Browser, ImageMagick czy FreeType2.
CERT Polska również pracuje nad rozwojem mechanizmów i wyszukiwaniem podatności w projektach wykorzystywanych szeroko w Internecie. W tym momencie równolegle testujemy 12 projektów z 56 obsługiwanych przez nasz system.
Efekt? Znaleźliśmy prawie 500 błędów w oprogramowaniu open source, z czego ponad 130 miało wpływ na bezpieczeństwo i otrzymało numer podatności CVE.
Jak to się zaczęło?
Przez ostatnie cztery lata wiele wydarzyło się zarówno w obszarze podatności bezpieczeństwa oprogramowania, jak i technik ich wyszukiwania.
Przełomowym momentem był drugi kwartał 2014 roku, który rozpoczął się gorączkowym łataniem serwerów, korzystających z pakietu OpenSSL. Wszystko przez podatność znaną jako HeartBleed. Jeszcze w tym samym roku udostępniony został fuzzer AFL oraz narzędzie AddressSanitizer (ASAN). Niecały rok później podatność HeartBleed została już znaleziona dzięki LibFuzzera w zaledwie 10 sekund!
W tamtym okresie wyszukiwaniem podatności oraz następstw ich wykorzystania zajmowali się głównie badacze bezpieczeństwa. Projekty open source cierpiały na brak osób testujących kod pod kątem security. Sytuacja zmieniła się zdecydowanie na plus dopiero w 2016 roku. Rozpoczęliśmy regularne badania bezpieczeństwa aplikacji open source. Działać zaczęła również inicjatywa Google OSS-Fuzz.
Integracja narzędzi do fuzzingu stała się bardzo prosta, przez co zyskała uwagę deweloperów, którzy sami zaczęli testować swój kod oraz wprowadzać fuzzing jako nieodłączny element procesu wytwarzania systemu (Fuzz-Driven Develompment). Dzięki taniejącej mocy obliczeniowej, zwiększyła się też skala testowania.
Automatyzacja bughuntingu
Podstawowym mechanizmem, który stosujemy do testowania systemu jest fuzzing – w tej chwili jeden z najskuteczniejszych sposobów na wykrycie błędów bezpieczeństwa. Jego założenia są bardzo proste: przekazujemy programowi („ofierze”) nieprawidłowe dane wejściowe i badamy, jak zareaguje oprogramowanie. Przekazywane informacje są mutowane dzięki algorytmów fuzzera, m.in. modyfikując poszczególne bajty wejścia.
W 2014 roku
Michał „lcamtuf” Zalewski zaprezentował swój fuzzer AFL. Działał on w oparciu o badanie pokrycia kodu (code coverage) dzięki dwóch metod:
- instrumentacji dodanej podczas procesu kompilacji,
- emulatora QEMU dla binariów, których kod źródłowy nie jest upubliczniony.
Badanie pokrycia kodu pozwala na „sprytne” wyszukiwanie nowych przypadków testowych, co powoduje znaczący wzrost skuteczności testów. Od tamtego czasu pojawiło się wiele rozwiązań opierających się na tej koncepcji.
Podstawowymi fuzzerami wykorzystanymi w trakcie badania były American Fuzzy Lop (AFL) oraz LLVM LibFuzzer. Oba rozwiązania są ściśle zintegrowane z narzędziami:
- AddressSanitizer,
- MemorySanitizer (MSAN),
- UndefinedBehaviorSanitizer (UBSAN).
Dzięki temu możliwe jest wykrywanie wielu klas problemów z oprogramowaniem: klasyczne naruszenia pamięci, użycie niezainicjalizowanych zmiennych, nieprawidłowa konwersja typów oraz przepełnienia typu int ze znakiem.
Skrócony raport AddressSanitizer podatności CVE-2017-8929 znalezionej w projekcie Yara:
READ of size 4 at 0x604000000450 thread T0
#0 0x5ac75d in sized_string_cmp XYZ/yara/libyara/sizedstr.c:39:14
#1 0x58cca4 in yr_execute_code XYZ/yara/libyara/exec.c:1096:21
#2 0x536784 in yr_rules_scan_mem_blocks XYZ/yara/libyara/rules.c:472:3
#3 0x537b80 in yr_rules_scan_mem XYZ/yara/libyara/rules.c:586:10
#4 0x537b80 in yr_rules_scan_file XYZ/yara/libyara/rules.c:610
#5 0x4f6084 in main XYZ/yara/yara.c:1229:14
#6 0x7f0ac130e82f in __libc_start_main (/lib/x86_64-linux-gnu/libc.so.6+0x2082f)
#7 0x41a7d8 in _start (/usr/local/bin/yara+0x41a7d8)
0x604000000450 is located 0 bytes inside of 44-byte region [0x604000000450,0x60400000047c)
freed by thread T0 here:
#0 0x4c23c2 in __interceptor_free (/usr/local/bin/yara+0x4c23c2)
#1 0x514c93 in yr_object_set_string XYZ/yara/libyara/object.c:1048:5
#2 0x56bd9d in data_md5 XYZ/yara/libyara/modules/hash.c
#3 0x593434 in yr_execute_code XYZ/yara/libyara/exec.c:572:22
#4 0x536784 in yr_rules_scan_mem_blocks XYZ/yara/libyara/rules.c:472:3
#5 0x537b80 in yr_rules_scan_mem XYZ/yara/libyara/rules.c:586:10
#6 0x537b80 in yr_rules_scan_file XYZ/yara/libyara/rules.c:610
#7 0x4f6084 in main XYZ/yara/yara.c:1229:14
#8 0x7f0ac130e82f in __libc_start_main (/lib/x86_64-linux-gnu/libc.so.6+0x2082f)
previously allocated by thread T0 here:
#0 0x4c26f3 in malloc (/usr/local/bin/yara+0x4c26f3)
#1 0x514cab in yr_object_set_string XYZ/yara/libyara/object.c:1052:41
#2 0x56bd9d in data_md5 XYZ/yara/libyara/modules/hash.c
#3 0x593434 in yr_execute_code XYZ/yara/libyara/exec.c:572:22
#4 0x536784 in yr_rules_scan_mem_blocks XYZ/yara/libyara/rules.c:472:3
#5 0x537b80 in yr_rules_scan_mem XYZ/yara/libyara/rules.c:586:10
#6 0x537b80 in yr_rules_scan_file XYZ/yara/libyara/rules.c:610
#7 0x4f6084 in main XYZ/yara/yara.c:1229:14
#8 0x7f0ac130e82f in __libc_start_main (/lib/x86_64-linux-gnu/libc.so.6+0x2082f)
Problemy fuzzingu w dużej skali
Fuzzery – skuteczność i sposoby działania
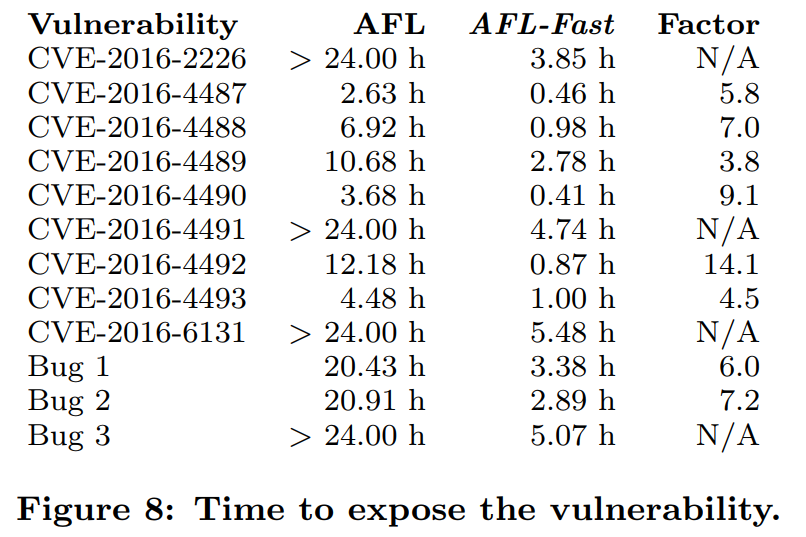
Podstawowa „odmiana” AFL w dosyć prosty sposób określa interesujące ścieżki w kodzie – pod kątem potencjalnie nowych obszarów kodu. Założenia tego rozwiązania powodują jednak, iż najczęściej wybierane są ścieżki wyzwalane przez dużą liczbę przypadków testowych. Jest to zachowanie niepożądane, ponieważ nie chcemy testować najczęściej wybieranych elementów. Dużo większe prawdopodobieństwo sukcesu gwarantuje wyszukiwanie po najrzadziej wybieranych ścieżkach w kodzie.
Taki mechanizm radzenia sobie z problemem doboru ścieżek implementuje projekt AFLFast opracowany przez Marcela Böhme [https://research.monash.edu/en/persons/marcel-boehme] z Monash University. Pozwala on na wybranie pięciu sposobów obliczania współczynnika wagi ścieżki, opartych o metody statystyczne.
Poniżej porównanie skuteczności AFL / AFL-Fast w procesie wyszukiwania podatności, które wyraźnie pokazuje znaczące różnice w podejściu obydwu narzędzi.
Na szeroko pojętą efektywność wpływa jednak nie tylko dobór ścieżek. Ważnymi czynnikami powodzenia i skuteczności kampanii fuzzingu są również:
- wiedza jakim stopniem trudności są obarczone przyszłe testy,
- prawdopodobieństwo znalezienia awarii.
Metryki te zapewnia kolejny projekt Marcela Böhme o nazwie Pythia. Dodatkową zaletą jest możliwość oszacowania znalezionych ścieżek do górnej granicy możliwych ścieżek w kodzie – pokrycie powyżej 98% świadczy o tym, iż kampania fuzzingu jest kompletna i warto ją zakończyć.
Analiza awaryjnych przypadków testowych
Wspomniane wcześniej narzędzia – ASAN, MSAN, UBSAN – pozwalają w fantastyczny sposób zwiększać „czułość” fuzzera i wykrywać różne problemy związane z wykonaniem kodu. Czasami jest ich tak dużo, iż choćby 500 przypadków testowych powodujących awarię, nie jest niczym nadzwyczajnym. Jednak to nie liczba błędów stanowi najtrudniejszy problem do automatycznej analizy. Większym wyzwaniem są niestabilne warunki wyzwalania błędu czy problemy z zależnościami.
Jako przykład może posłużyć niedeterministyczny przypadek przepełnienia bufora na stercie w projekcie Wireshark. Jest on wykrywany podczas sesji fuzzingu, natomiast próby powtórzenia poza nią, kończą się niepowodzeniem.
READ of size 4 at 0x60200df8f0d2 thread T0
#0 0x44ae68 (fuzzshark_ip_proto-udp+0x44ae68)
#1 0x251e4ce (fuzzshark_ip_proto-udp+0x251e4ce)
#2 0x251f4d8 (fuzzshark_ip_proto-udp+0x251f4d8)
#3 0x649a89 (fuzzshark_ip_proto-udp+0x649a89)
#4 0x64a814 (fuzzshark_ip_proto-udp+0x64a814)
#5 0xd87103 (fuzzshark_ip_proto-udp+0xd87103)
#6 0xd84e5f (fuzzshark_ip_proto-udp+0xd84e5f)
#7 0x5e3de3 (fuzzshark_ip_proto-udp+0x5e3de3)
Niepowodzenie podczas manualnego wyzwalania błędu:
Running: ./crash-be8d94351dc2841dfc3bc7aaceba0a03f812bbce
Executed ./crash-be8d94351dc2841dfc3bc7aaceba0a03f812bbce in 156 ms
*** NOTE: fuzzing was not performed, you have only executed the target code on a fixed set of inputs.
Niestety analiza takich przypadków musi być przeprowadzana manualnie.
Przypadki zwyczajnych błędów w bardzo prosty sposób analizuje się automatycznie dzięki nieskomplikowanych wyrażeń regularnych. Poniżej wysokopoziomowy algorytm, który wykorzystujemy do przetwarzania raportów z narzędzi ASAN i Valgrind:
- Badanie raportu o błędzie:
- Typ awarii.
- Patterny crasha oraz blacklistowane wzorce.
- Patterny crasha oraz blacklistowane wzorce.
- Wykrywanie timeoutów.
- Deduplikacja i wyszukiwanie unikalnych awarii:
- Minimalizacja crasha.
- Sprawdzenie unikalności poprzez różnicowanie znanych patternów.
Do automatyzacji analizy i monitoringu serwerów został uruchomiony wewnętrzny system o roboczej nazwie „Cloudfuzz”. Architektura systemu jest oparta o centralny serwer i serwery z agentami raportującymi progres testów – podobne rozwiązania stosowane są w złośliwym oprogramowaniu ;-). Poza funkcjonalnością analizy, system generuje również statystyki z fuzzingu, integruje się z dostawcami VPS (DigitalOcean oraz Aruba Cloud). Pracujemy również nad integracją z OSS-Fuzz, a także automatycznym wdrażaniem fuzzingu projektów według przygotowanego wcześniej harmonogramu.

Zarządzanie korpusem testowym
Pliki do testów pozyskiwane były z każdego możliwego źródła:
- wyszukiwanie w Google’u po typie pliku „filetype:PPT”,
- pliki testowe np. z zestawu plików multimedialnych lub czcionki pozyskane z systemów operacyjnych,
- parsowanie i ekstrakcja testów jednostkowych i regresyjnych z wersji deweloperskich.
Dodatkowo zbudowaliśmy słowniki dla wszystkich badanego formatu plików i skrypty usprawniające zarządzaniem korpusu na podstawie prezentacji Mateusza „j00ru” Jurczyka z konferencji BlackHat Europe 2016.
Na początku maja 2018 roku pojawił się interesujący projekt wykorzystujący instrumentację AFL do tworzenia plików powodujących niestabilne zachowanie o nazwie PerfFuzz. W tej chwili testujemy go pod kątem użyteczności wygenerowanych plików testowych.
Podsumowanie
Szybki rozwój narzędzi do fuzzingu (i większa liczba testowanych projektów), dużo większe zainteresowanie badaczy automatyzacją testów bezpieczeństwa oraz wzrastająca świadomość wśród deweloperów powoduje dużo lepszą jakość (pod kątem bezpieczeństwa) projektów o otwartym kodzie. Dzięki wspólnym wysiłkom naszych fuzzerów, niezależnych badaczy oraz inicjatywy OSS-Fuzz, wyeliminowanych zostało ponad osiem tysięcy błędów w oprogramowaniu (w tym około dwa tysiące podatności).