Cześć.
Dawno, dawno temu, na produkcji, pojawił nam się problem z wydajnością aplikacji. Analiza i rozwiązanie problemu pochłonęła nam dobre kilka dni. Debugowaliśmy, czytaliśmy dokumentację, analizowaliśmy logi. Nic nie mogliśmy znaleźć, do momentu, gdy nas oświeciło. Analizowaliśmy requesty i zauważyliśmy, iż większość czasu żądania była na odczycie wartości z… cache. Problem był banalny. Zapychaliśmy cache’a generując za każdym razem uniwersalny klucz wartości. Chwilę wcześniej mergowaliśmy ogromnego PR, który pozmieniał w kodzie dużo – za dużo. Zmiany były w różnych częściach aplikacji – technicznych i biznesowych. To był nasz ogromny błąd.
Uznałem, iż artykuł, który w sposób początkujący przedstawi temat cache pomoże innym. Mi też będzie punktem referencyjnym w przyszłości. W dzisiejszym artykule:
- Czym jest cache
- Cache lokalny vs rozproszony
- Algorytmy przechowujące dane
- Inwalidacja cache
- Monitorowanie cache
Czym jest cache
Cache w Javie to mechanizm przechowywania często używanych danych, w celu szybszego dostępu i poprawy wydajności aplikacji. Możemy zastosować go do operacji, które są czasochłonne lub kosztowne w wykonaniu. Dobrymi przykładami takich operacji są zapytania do bazy danych, requesty do API czy powtarzalne obliczenia matematyczne.
Załóżmy, iż tworzymy aplikację pobierającą informacje o pogodzie. Informacje pobieramy z różnych lokalizacji, z zewnętrznego serwisu pogodowego dzięki REST API. Pobierane dane zmieniają się co 3 godziny. Z naszej aplikacji dziennie korzysta około 50 000 osób, co przekłada się na średnio 2000 requestów na godzinę (upraszczamy, iż ruch został rozłożony na całą dobę równomiernie). Użytkownicy pochodzą głównie z Polski i często pytają o te same lokalizacje. Aby uniknąć wywoływania zewnętrznego serwisu pogodowego wiele razy, możemy użyć mechanizmu cache. Przyspieszymy dostęp do informacji i unikniemy ciągłego zapytywania zewnętrznego API.
Cache lokalny vs rozproszony
Pamięć cache, możemy podzielić na dwa typy: lokalny i rozproszony. W tej sekcji postaram się opisać ich cechy, wady oraz zalety. Na końcu sekcji wrzuciłem też dwie tabele. Jedna porównująca cechy obydwu typów i druga z przykładami i rekomendacjami, który rodzaj wybrać w danej sytuacji.
Cache lokalny (In-memory cache)
In-memory cache to lokalny cache w procesie aplikacji, który przechowuje dane w pamięci RAM na jednym serwerze. Pozwala to na błyskawiczny dostęp do danych tam przechowywanych. Jest on najszybszy, ale ograniczony rozmiarem pamięci dostępnej w jednej instancji aplikacji. Jego główne cechy to:
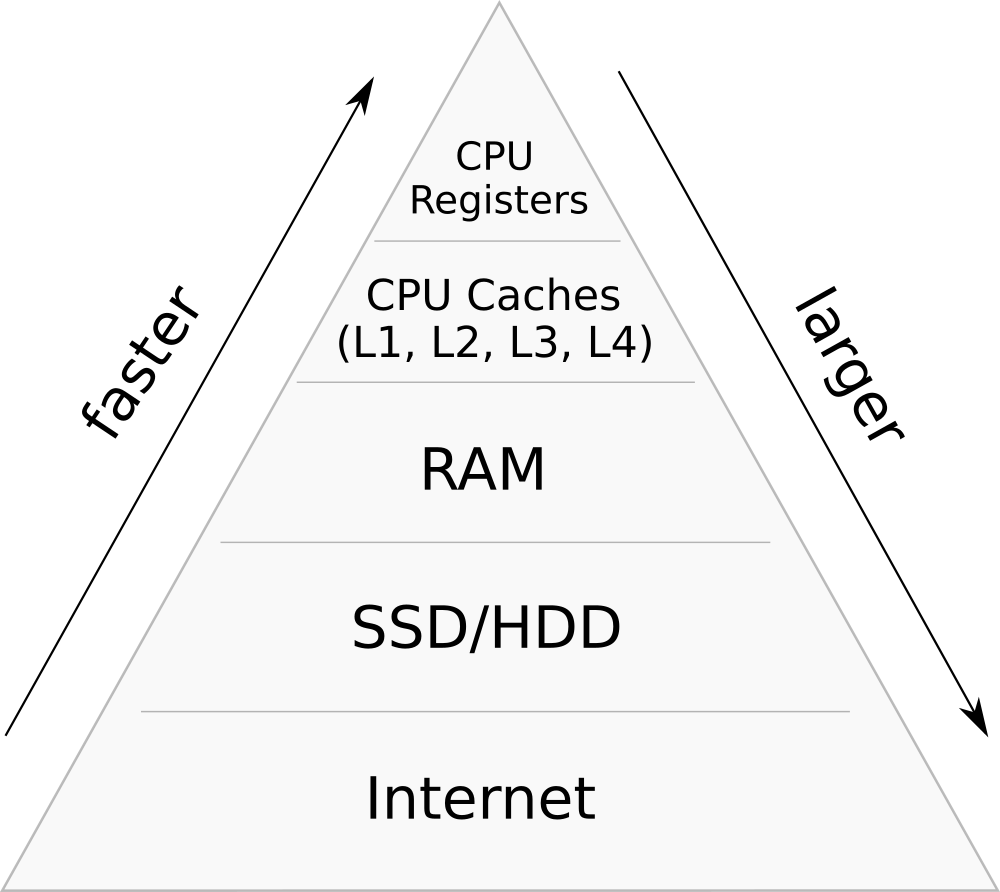 Hierarchia pamięci
Hierarchia pamięci- Lokalność: dane przechowywane są w pamięci RAM konkretnego procesu lub instancji aplikacji.
- Szybkość: dostęp do danych jest ekstremalnie szybki, ponieważ omijana jest komunikacja sieciowa i operacje na dysku.
- Prostota: może być implementowany dzięki prostych struktur danych, np. ConcurrentHashMap, lub dedykowanych bibliotek, np. Caffeine.
- Brak współdzielenia: dane w cache są dostępne tylko dla jednego procesu lub instancji aplikacji (chyba iż używana jest rozproszona implementacja in-memory, np. Hazelcast).
Zalety:
- Wysoka wydajność: zapewnia bardzo niski czas dostępu do danych, ponieważ przechowuje je w pamięci RAM. Odczyt danych z pamięci jest znacznie szybszy niż z dysku twardego czy bazy danych, co przyspiesza działanie aplikacji.
- Prosta implementacja: jest stosunkowo łatwa i nie wymaga skomplikowanej konfiguracji. Istnieje wiele gotowych rozwiązań, oferujących gotowe mechanizmy.
Wady:
- Ulotność danych: dane zostaną utracone w przypadku restartu serwera lub awarii aplikacji.
- Ograniczona pojemność: pojemność jest ograniczona przez dostępność pamięci RAM na serwerze. W przypadku dużych aplikacji lub intensywnego wykorzystania pamięci może to prowadzić do problemów z wydajnością lub brakiem miejsca na nowe dane (OutOfMemoryError).
- Trudności w skalowaniu: w architekturze rozproszonej każda instancja aplikacji ma swoją własną pamięć podręczną, co może prowadzić do problemów z synchronizacją danych między instancjami oraz zwiększonego ryzyka nieaktualnych informacji.
Cache rozproszony (Distributed cache)
Działa na wielu serwerach w klastrze, umożliwiając szybki dostęp do często używanych danych. Pamięć współdzielona jest między wieloma instancjami aplikacji i umożliwia obsługę dużych wolumenów danych oraz zapewnia wysoką dostępność danych. Jego główne cechy:
- Rozproszenie danych (eureka!): te same dane dostępne z różnych instancji aplikacji.
- Skalowalność: może być łatwo skalowany poprzez dodawanie nowych węzłów do klastra. To pozwala na zwiększenie pojemności cache i obsługę większej liczby żądań.
- Odporność na awarie: dzięki replikacji danych na różnych węzłach, choćby w przypadku awarii jednego z nich, dane pozostają dostępne.
- Partycjonowanie (sharding): każdy węzeł przechowuje tylko część danych, a aplikacja odwołuje się bezpośrednio do odpowiedniego serwera.
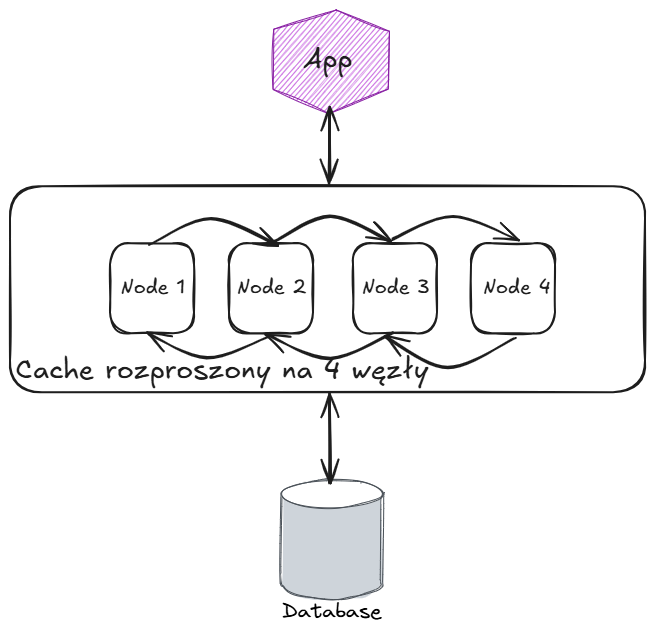 Schemat cache’u rozproszonego
Schemat cache’u rozproszonegoZalety:
- Wysoka dostępność i odporność na awarie: dane mogą być replikowane na wielu węzłach, dzięki czemu awaria jednego serwera nie powoduje utraty danych.
- Szybkość i niskie opóźnienia: dane przechowywane są w pamięci RAM (z tym, iż na wielu węzłach w porównaniu z lokalnym cache).
- Usprawnienie pracy mikroserwisów: w systemach mikroserwisowych cache rozproszony pozwala na szybką wymianę danych między usługami bez konieczności ciągłego odpytywania bazy danych.
- Obsługa dużych wolumenów danych: dzięki partycjonowaniu dane mogą być równomiernie rozłożone na węzłach, co pozwala na obsługę dużych zbiorów danych w rozproszonym środowisku.
Wady:
- Opóźnienia Sieciowe: cache działa na wielu serwerach, co oznacza, iż każde zapytanie musi przejść przez sieć. jeżeli węzły są oddalone geograficznie, latencja wzrasta.
- Koszt Pamięci RAM: RAM jest znacznie droższy niż dysk, a cache rozproszony przechowuje dane w pamięci operacyjnej. Skalowanie dużych systemów wymaga serwerów z dużą ilością RAM-u.
- Nieścisłości w Danych (Data Inconsistency): dane na różnych węzłach mogą być przez chwilę niespójne. Możesz odczytać stare dane, zanim propagacja zmian się zakończy.
- Złożoność architektury: wprowadza dodatkową złożoność do architektury systemu. Wymaga planowania i zarządzania, aby zapewnić prawidłowe działanie i integrację z innymi komponentami systemu.
- Split-Brain: jeżeli węzły stracą komunikację między sobą, może dojść do stanu „split-brain”, gdzie różne węzły mają różne wersje danych. Część aplikacji może korzystać z nieaktualnych danych.
Rozproszony vs Lokalny
| Lokalizacja danych | Dane są przechowywane na wielu instancjach. | Dane są przechowywane w pamięci RAM lokalnej instancji aplikacji. |
| Dostępność danych | Dane są współdzielone między wszystkimi instancjami aplikacji w klastrze. | Dane są dostępne tylko dla jednej instancji aplikacji. |
| Przykłady technologii | Redis, Memcached, Hazelcast, Infinispan, Apache Ignite, Ehcache (tryb rozproszony) | Caffeine, Guava, Ehcache (tryb lokalny), ConcurrentHashMap |
| Szybkość dostępu | Dostęp jest szybszy niż do bazy danych, ale wymaga komunikacji sieciowej. | Dostęp jest ekstremalnie szybki, ponieważ dane są przechowywane w pamięci lokalnej. |
| Skalowalność | Łatwo skalowalny dzięki rozproszonej architekturze – nowe węzły można dodawać w celu zwiększenia pojemności. | Skalowalność ograniczona do zasobów (RAM) jednej instancji aplikacji. |
| Niezawodność danych | Może obsługiwać replikację i trwałość danych. | Dane są ulotne – tracone w przypadku restartu aplikacji lub awarii instancji. |
| Złożoność zarządzania | Zazwyczaj wymaga dodatkowej konfiguracji. | Łatwe w zarządzaniu – wystarczy biblioteka lub struktura danych w aplikacji. |
| Przeznaczenie | Do współdzielenia danych między wieloma instancjami lub usługami w architekturze rozproszonej | Do lokalnego buforowania danych specyficznych dla jednej instancji aplikacji. |
| Czas życia danych (TTL) | Obsługuje globalne TTL dla danych, które są ważne niezależnie od instancji. | Dane wygasają tylko w kontekście jednej instancji aplikacji. |
| Koszty | Wymaga dodatkowych zasobów infrastruktury (np. serwery Redis, Memcached). | Niskie koszty – wykorzystuje lokalną pamięć aplikacji. |
| Odporność na awarie | Może być replikowany, co zwiększa odporność na awarie | Dane są tracone w przypadku awarii procesu aplikacji. |
Kiedy wybrać który?
| Współdzielenie danych między wieloma instancjami. | Distributed Cache |
| Dane muszą być dostępne po awarii instancji. | Distributed Cache |
| Maksymalna szybkość dostępu bez komunikacji sieciowej. | In-Memory Cache |
| Aplikacja monolityczna z pojedynczym węzłem. | In-Memory Cache |
| Architektura mikrousługowa lub klaster aplikacji. | Distributed Cache |
| Buforowanie krótkotrwałych danych specyficznych dla jednej instancji. | In-Memory Cache |
Algorytmy przechowujące dane
Wiemy już czym jest cache i jakie są jego typy. Teraz pora poznać jakie algorytmy są implementowane najczęściej. Warto poznać co się dzieje pod bebechami, w jaki sposób nasze dane są organizowane w cache. W gotowych rozwiązaniach mamy możliwość customizowania, znając skróty (np. LRU, LFU) oraz teoretyczne działanie algorytmu, jesteśmy w stanie lepiej go ustawić.
 Książka do algorytmów cache
Książka do algorytmów cache- Zastosowania i ograniczenia: Omówienie, kiedy i dlaczego warto stosować dany algorytm oraz ich potencjalne ograniczenia.
Najpopularniejsze algorytmy to:
- LRU (Least Recently Used)
- LFU (Least Frequently Used)
- FIFO (First In, First Out)
- ARC (Adaptive Replacement Cache)
- SLRU (Segmented LRU)
- 2Q (Two-Queue)
LRU (Least Recently Used)
Algorytm LRU usuwa najdawniej używane elementy z cache, aby zrobić miejsce dla nowych. Jest to jeden z najczęściej stosowanych algorytmów, ponieważ dobrze odzwierciedla rzeczywiste wzorce użycia danych. Warto go stosować gdy ważne są najświeższe dane.
 Algorytm LRU
Algorytm LRUWyobraźmy sobie aplikację udostępniającą zdjęcia. Zdjęcia są przechowywane na dysku, a ich pobieranie zajmuje pewien czas. Aby przyspieszyć dostęp do często żądanych zdjęć, aplikacja może użyć cache LRU. Kiedy użytkownik żąda zdjęcia, aplikacja najpierw sprawdza, czy znajduje się ono w pamięci podręcznej. jeżeli tak, zdjęcie jest natychmiast zwracane. jeżeli zdjęcia nie ma w pamięci podręcznej, aplikacja pobiera go z dysku, zapisuje w pamięci podręcznej i zwraca użytkownikowi. Pamięć podręczna LRU ma ograniczoną pojemność, więc gdy jest pełna, algorytm usuwa najdawniej używane zdjęcie, aby zrobić miejsce dla nowego. Dzięki temu często żądane zdjęcia są gwałtownie dostępne, co poprawia wydajność serwera i skraca czas ładowania strony dla użytkowników
Dlaczego warto?
- Wykorzystuje lokalność czasową – elementy używane niedawno prawdopodobnie będą używane ponownie.
- Sprawdza się w systemach z przewidywalnym wzorcem dostępu do danych.
- Prosta i sprawdzona strategia – po prostu usuwa element, który był najdawniej używany.
- Dobra wydajność dla większości zastosowań – operacje dostępu (get i put) są w czasie O(1) w LinkedHashMap, jeżeli używamy listy podwójnie powiązanej.
Ograniczenia:
- Cache pollution – jeżeli aplikacja chwilowo użyje dużej liczby rzadko używanych obiektów, cache może zostać „zalany” niepotrzebnymi danymi.
- Wysokie koszty operacyjne – wymaga dodatkowej pamięci do przechowywania wskaźników (np. w LinkedHashMap jest to lista podwójnie powiązana).
- Brak adaptacyjności – każdy nowy dostępny element traktowany jest jednakowo, co może prowadzić do błędnych decyzji o usunięciu. jeżeli aplikacja używa dwóch zestawów danych naprzemiennie, LRU może stale usuwać jedną grupę na rzecz drugiej.
LFU (Least Frequently Used)
Algorytm LFU usuwa elementy, które były najrzadziej używane w danym okresie czasu. Wymaga on śledzenia liczby odwołań do każdego elementu w cache, co może zwiększać złożoność implementacji i obciążenie pamięci. Warto go stosować gdy ważna jest częstotliwość użycia.
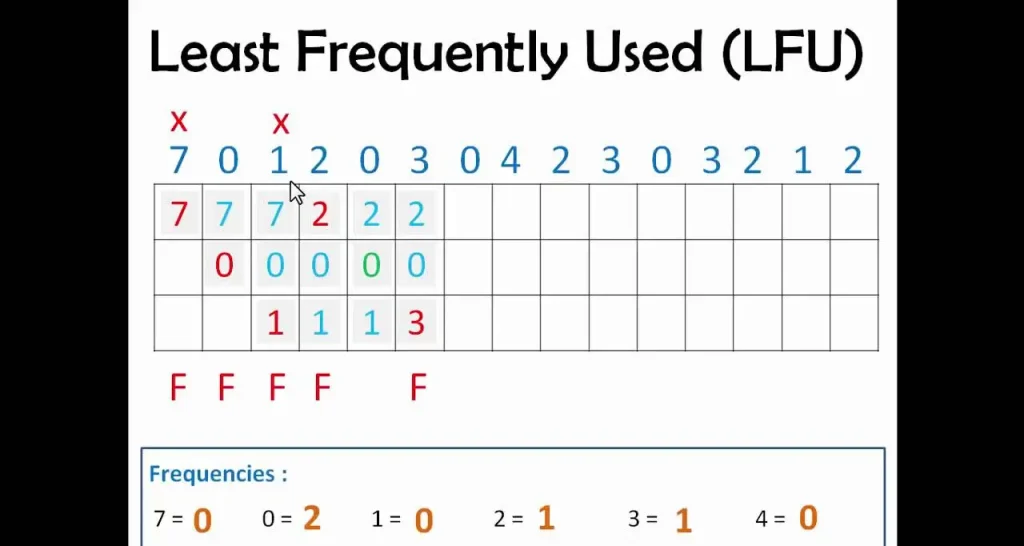 Algorytm LFU
Algorytm LFUWyobraź sobie, iż tworzysz aplikację finansową, która pokazuje kursy walut w czasie rzeczywistym. Każdego dnia tysiące użytkowników sprawdza notowania, ale większość z nich interesuje się tylko kilkoma najpopularniejszymi walutami – np. USD, EUR i PLN. Zamiast za każdym razem pobierać dane z API, przechowujemy w pamięci najczęściej pobierane kursy walut, a rzadko używane usuwamy.
1⃣ Użytkownik pyta o kurs USD/PLN. Sprawdzamy, czy mamy go w LFU Cache.
2⃣ Im częściej dana waluta jest wyszukiwana, tym dłużej pozostaje w cache.
3⃣ jeżeli cache jest pełny, usuwamy najrzadziej pobierane waluty.
Dlaczego warto?
- Idealny dla danych o wysokiej lokalności częstotliwościowej – rzadko używane obiekty są usuwane, a często odczytywane pozostają.
- Sprawdza się w aplikacjach, gdzie dostęp do pewnych obiektów jest naturalnie „gorący” (np. ranking produktów w sklepie).
Ograniczenia:
- Problem zimnego startu – nowo dodane elementy mogą zostać gwałtownie usunięte, zanim zdążą być użyte wystarczająco często.
- Wysoka złożoność operacji – O(log n) zamiast O(1). W odróżnieniu od LRU Cache, który można zaimplementować w O(1), standardowa implementacja LFU wymaga struktury danych, która potrafi śledzić częstotliwość użycia i usuwać najrzadziej używany element.
- Nie radzi sobie dobrze z nagłymi zmianami trendów – dane, które były często używane dawno temu, mogą długo pozostawać w cache, choćby jeżeli nie są już potrzebne.
FIFO (First In, First Out)
Algorytm FIFO usuwa najstarsze elementy z cache’a w momencie, gdy osiągnięty zostaje jego maksymalny rozmiar. Jest to prosty algorytm, ale może nie być optymalny w przypadku, gdy starsze dane są przez cały czas często używane.
Załóżmy, iż budujemy serwer proxy, który buforuje strony internetowe, aby zmniejszyć liczbę żądań wysyłanych do serwera źródłowego. Kiedy użytkownik odwiedza stronę, jej zawartość jest zapisywana w pamięci podręcznej. jeżeli inny użytkownik zażąda tej samej strony, proxy zwróci ją z cache, zamiast pobierać ponownie z internetu.
Jednak cache ma ograniczoną pojemność, więc najstarsze strony muszą być usuwane, aby zrobić miejsce na nowe. FIFO dobrze sprawdza się w tym przypadku, ponieważ starsze strony są mniej prawdopodobne do ponownego użycia.
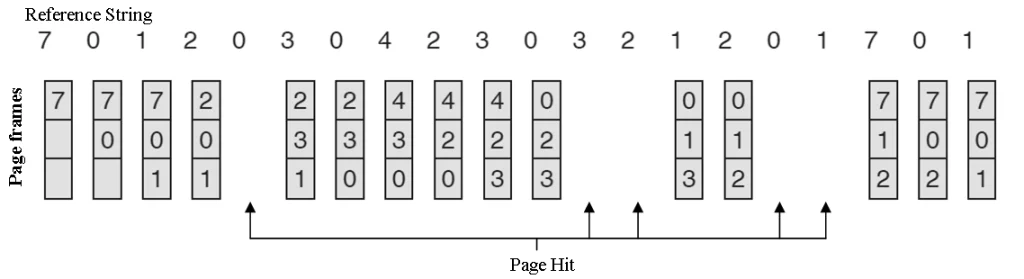 FIFO algorithm
FIFO algorithmDlaczego warto?
- Bardzo prosty do implementacji i tani obliczeniowo.
- Może działać dobrze w sytuacjach, gdzie stare dane są naturalnie mniej istotne.
- Brak kosztów obliczeniowych związanych z priorytetyzacją w przeciwieństwie do algorytmów takich jak LRU czy LFU, FIFO nie wymaga monitorowania częstotliwości ani czasu dostępu do danych.
- Działa w przewidywalny sposób, ponieważ zawsze usuwa najstarszy element. Nie wymaga skomplikowanych heurystyk ani analizy częstości użycia danych.
Ograniczenia:
- Ignoruje rzeczywisty dostęp do danych – może usuwać często używane dane, jeżeli zostały one załadowane wcześniej niż inne mniej używane elementy
- Może prowadzić do niskiej efektywności cache (tzw. Problem Belady’ego) – zwiększenie rozmiaru cache może pogorszyć jego skuteczność zamiast ją poprawić.
- Brak kontroli nad priorytetami danych – w FIFO wszystkie dane są traktowane jednakowo, niezależnie od ich ważności dla aplikacji.
ARC (Adaptive Replacement Cache)
ARC to bardziej zaawansowany algorytm, który łączy cechy LRU i LFU. Dostosowuje się do zmieniających się wzorców użycia danych, starając się utrzymać równowagę między częstością a świeżością danych w cache’u. Algorytm opiera się na czterech listach, które służą do zarządzania pamięcią podręczną. Dwie główne listy, T1 i T2, odpowiadają za przechowywanie odpowiednio niedawno używanych oraz często używanych elementów. Dodatkowo istnieją dwie listy pomocnicze, B1 i B2, które przechowują referencje do elementów wcześniej usuniętych z T1 i T2, co pozwala na inteligentne dostosowanie algorytmu do zmieniających się wzorców dostępu do danych.
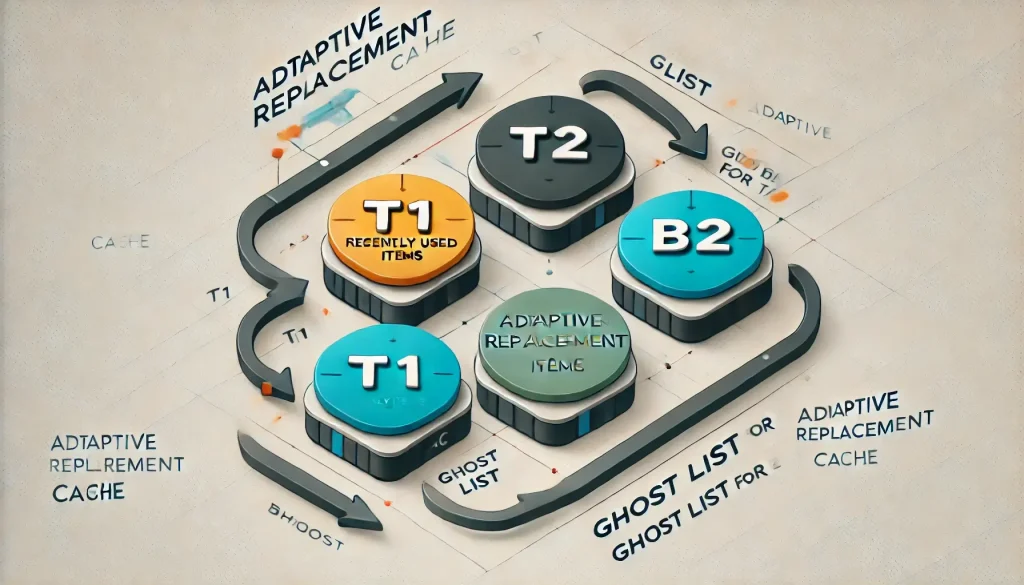 ARC algorithm
ARC algorithmZałóżmy, iż mamy system rekomendacji filmów w serwisie streamingowym. Filmy mogą być często oglądane przez różnych użytkowników (np. hity kinowe), ale niektóre treści mogą być oglądane tylko raz przez jednego użytkownika (np. premierowe odcinki seriali). ARC może być tu użyty do cache’owania najczęściej oglądanych filmów, jednocześnie dostosowując się do zmieniającego się trendu popularności. jeżeli dany film jest nagle często oglądany przez wielu użytkowników, ARC zwiększy swoją pamięć dla takich elementów (T2). jeżeli użytkownicy konsumują głównie nowe treści (np. nowy sezon serialu), ARC dostosuje się do tego, zwiększając T1 i usuwając mniej popularne starsze filmy.
Dlaczego warto?
- Lepsza adaptacja do zmieniających się wzorców dostępu – eliminuje problem wyboru między LRU i LFU.
- Efektywne wykorzystanie cache – dynamiczne dostosowanie do obciążenia zapewnia mniejszą liczbę niepotrzebnych wymian.
- Dobre działanie w przypadku zarówno skokowych zmian popularności, jak i stabilnych trendów.
Ograniczenia:
- Większa złożoność obliczeniowa niż LRU czy LFU – zarządzanie wieloma listami i dynamiczne dostosowywanie kosztuje więcej CPU.
- Większe zużycie pamięci – dodatkowe struktury (B1, B2) zwiększają overhead.
- Może nie sprawdzić się w scenariuszach z bardzo ograniczoną pamięcią – w ekstremalnie małych cache’ach, prostsze algorytmy jak LRU mogą działać lepiej.
SLRU (Segmented LRU)
SLRU to wariant klasycznego algorytmu LRU, który wprowadza podział pamięci podręcznej na dwa segmenty: ochronny i próbny. Ochronny przechowuje często używane elementy, które zostały uznane za „ważne”, próbny natomiast nowe elementy, które jeszcze nie zostały uznane za istotne. Nowo wczytane elementy trafiają najpierw do segmentu próbnego. jeżeli element zostanie ponownie użyty, jest przenoszony do segmentu ochronnego. Elementy z segmentu ochronnego mają pierwszeństwo przed usunięciem – jeżeli pamięć cache jest pełna, elementy usuwane są w pierwszej kolejności z segmentu próbnego, co zwiększa szanse na zachowanie często używanych danych.
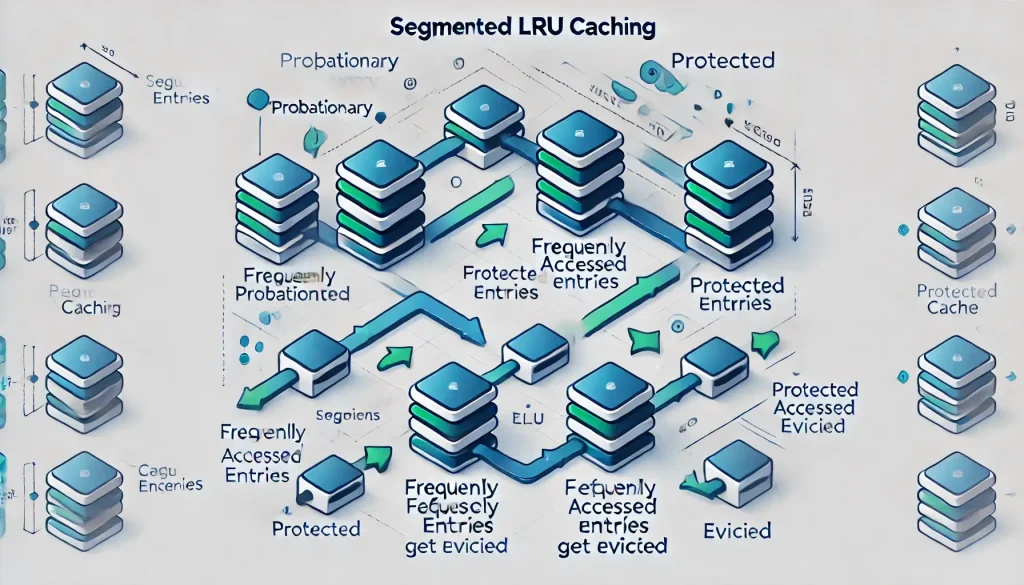 SLRU algorithm
SLRU algorithmWeźmy realny przykład z e-commerce. Każdy użytkownik, odwiedzając sklep internetowy, otrzymuje sesję, która może być wykorzystywana wielokrotnie, np. podczas dodawania produktów do koszyka, ale w wielu przypadkach jest jednorazowa – użytkownik przegląda stronę i nigdy nie wraca. W takim scenariuszu nowo utworzone sesje trafiają najpierw do segmentu próbnego pamięci podręcznej. jeżeli użytkownik podejmuje kolejne działania, jego sesja zostaje przeniesiona do segmentu ochronnego, co oznacza, iż uznano ją za wartościową. W momencie, gdy pamięć cache się zapełni, system usuwa w pierwszej kolejności elementy z segmentu próbnego, pozostawiając w cache sesje użytkowników aktywnie korzystających z platformy. Dzięki takiemu podejściu unika się przechowywania w cache sesji użytkowników, którzy odwiedzili stronę tylko raz i nie wykazali żadnej aktywności.
Dlaczego warto?
- Lepsza retencja często używanych danych – rzadko używane elementy są usuwane szybciej, co sprawia, iż cache lepiej przechowuje istotne dane.
- Unikanie problemu „jednorazowych” danych – nie przenosi od razu nowych elementów do segmentu ochronnego, co zapobiega przypadkowemu wyrzuceniu bardziej wartościowych danych.
Ograniczenia:
- Nieadaptacyjny – w przeciwieństwie do ARC, SLRU nie dostosowuje automatycznie swoich segmentów do zmieniających się wzorców dostępu.
- Możliwa suboptymalna wymiana – jeżeli segment ochronny jest pełny, rzadko używane elementy mogą utrzymywać się zbyt długo, zamiast zrobić miejsce na bardziej wartościowe dane.
2Q (Two-Queue)
Algorytm 2Q to ulepszona wersja LRU, która lepiej radzi sobie z jednorazowymi dostępami do danych. Dzieli pamięć cache na dwie główne kolejki: A1 i Am. Nowe elementy trafiają najpierw do A1, która pełni funkcję filtra. jeżeli dany element zostanie użyty ponownie po usunięciu, przechodzi do Am, gdzie przechowywane są często wykorzystywane wpisy. Dzięki temu system unika sytuacji, w której jednorazowe żądania wypierają wartości bardziej istotne.
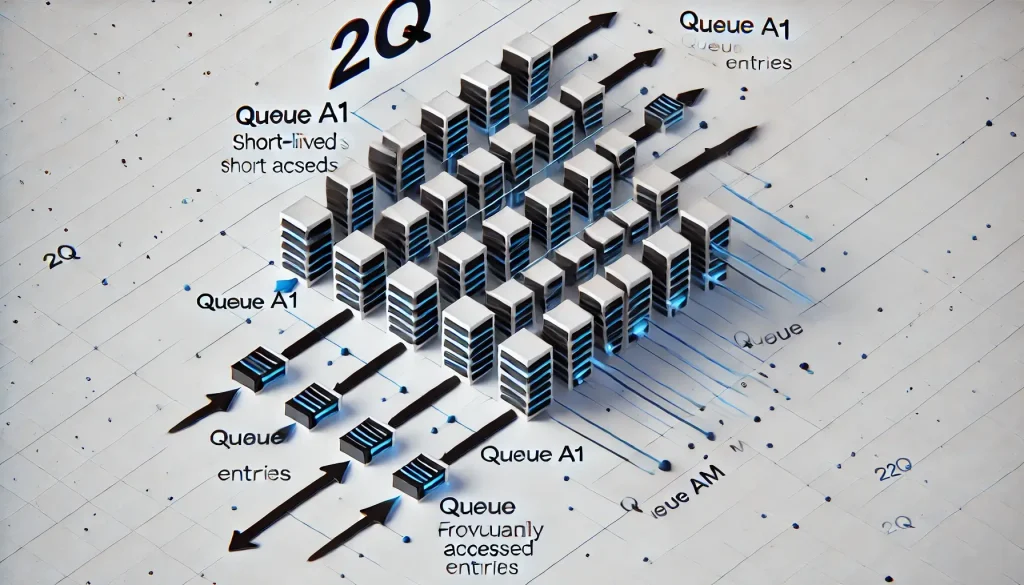 2Q algorithm
2Q algorithmWyobraź sobie aplikację internetową dla sklepu online, który obsługuje zapytania użytkowników o szczegóły produktów. Każde zapytanie pobiera dane z bazy, co może powodować duże obciążenie serwera. Standardowy mechanizm cache oparty na LRU miałby problem, gdyby użytkownicy jednorazowo przeglądali wiele różnych produktów – te mniej popularne mogłyby wypierać z cache’a często wyszukiwane artykuły.
Algorytm 2Q rozwiązuje ten problem poprzez wstępną kolejkę A1, do której trafiają nowo pobrane produkty. jeżeli dany produkt zostanie zapytany tylko raz, po krótkim czasie zostanie usunięty, nie wpływając na cache długoterminowy. Natomiast produkty często wyszukiwane zostaną przeniesione do kolejki Am, gdzie będą utrzymywane dłużej, co przyspieszy ich późniejsze ładowanie. Dzięki temu aplikacja efektywnie zarządza pamięcią cache, zmniejsza liczbę zapytań do bazy danych i poprawia czas odpowiedzi dla użytkowników.
Dlaczego warto?
- Zamiast natychmiastowego usuwania elementów, algorytm przenosi je między kolejkami, co może zminimalizować usuwanie przy małym dostępie.
- Dobre rozwiązanie, gdy nie wiemy, jaki wzorzec dostępu dominuje w systemie.
Ograniczenia:
- Wymaga więcej pamięci i złożonych struktur danych.
- Nie zawsze najlepszy w systemach z bardzo małą pamięcią cache – może nie być opłacalny przy niewielkich zasobach.
Porównanie algorytmów
| LRU | Lokalność czasowa, np. cache przeglądarki | Wrażliwy na zalanie cache nowymi danymi |
| LFU | Obiekty z wysoką częstotliwością dostępu (np. rankingi) | Problem zimnego startu, większa złożoność |
| FIFO | Proste przypadki (np. cache kolejki) | Nie uwzględnia lokalności czasowej |
| ARC | Zmienny wzorzec dostępu, wymagająca wydajność | Złożona implementacja |
| SLRU | Dobre dla mieszanej lokalności | Wymaga dostrajania wielkości segmentów |
| 2Q | Przeciwdziała problemowi zimnego startu | Większe wymagania pamięciowe |
Inwalidacja cache
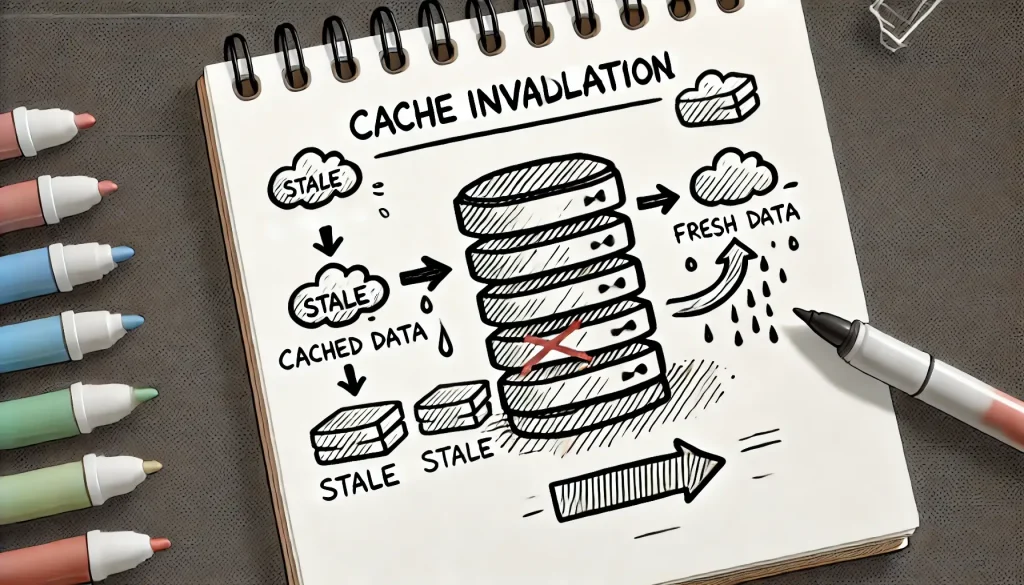 Cache invalidation
Cache invalidationInwalidacja cache to proces usuwania lub aktualizowania nieaktualnych danych w pamięci podręcznej. Jest kluczowa dla zapewnienia spójności danych i zapobiegania zwracaniu przestarzałych wartości. Istnieją różne strategie inwalidacji, zależnie od wymagań aplikacji.
Inwalidacja oparta na czasie (TTL – Time-To-Live) / TTI (Time-To-Idle)
TTL jest najprostsza metodą, w której każdy wpis w cache ma określony czas życia. Po upływie tego czasu zostaje automatycznie usunięty. TTI powoduje usunięcie wpisu z cache, jeżeli nie był on używany przez określony czas. TTI i TTL można łączyć, np. ustawić TTL na 30 min i TTI na 10 min, aby zapewnić zarówno maksymalny czas życia, jak i usuwanie nieaktywnych danych.
Inwalidacja natychmiastowa (Explicit Invalidation)
Aplikacja manualnie usuwa wpisy z cache, gdy dane ulegną zmianie. Gwarantuje to aktualność danych, ale wymaga dokładnego zarządzania cachem.
Inwalidacja oparta na polityce zastępowania (LRU/LFU)
LRU usuwa najdawniej używane wpisy, a LFU najrzadziej używane wpisy. Sprawdza się, gdy cache ma ograniczony rozmiar. Jego wadą jest, iż może przetrzymywać nieistotne dane, które znalazły się w cache a mogłyby już z niego wylecieć.
Jaką strategię wybrać?
- Dane gwałtownie się zmieniają? → TTL + TTI + Explict Invalidation.
- Masz ograniczoną pamięć cache? → LRU/LFU.
- Dane muszą być zawsze aktualne? → Explict Invalidation.
Monitorowanie cache
Monitorowanie cache to najważniejszy proces, pomagający utrzymać wydajność, spójność danych i oszczędność zasobów. Aby efektywnie monitorować cache, należy zastanowić się nad metrykami.
 Metryki Cache w dashboardzie Grafany
Metryki Cache w dashboardzie GrafanyJakie metryki warto zbierać?
- Hit Ratio – określa, jak często dane są znajdowane w cache, zamiast być pobierane z bazy.
- *Miss Rate – pokazuje, ile zapytań nie znajduje danych w cache i musi iść do bazy. Jeśli zbyt wysoki, warto zwiększyć rozmiar cache lub poprawić strategię inwalidacji. Miss Rate i Hit Ratio wzajemnie sumują się do 100%, więc mierząc jeden, automatycznie otrzymujesz drugi.
- Eviction Rate (Wskaźnik usunięć) – Mierzy, ile obiektów zostało usuniętych z cache (z powodu przepełnienia, TTL lub inwalidacji). Zbyt wysoki wskaźnik oznacza, iż cache jest za mały.
- Memory Usage (Zużycie pamięci) – ile RAM zajmuje cache.
- Latency (Opóźnienie) – ile trwa odczyt/zapis w cache.
Jak monitorować Cache w Javie?
W Javie istnieje kilka sposobów monitorowania cache. Dużo zależy od tego, jakiego typu aplikację rozwijamy/tworzymy. o ile tworzysz aplikację w Spring Boot, możesz w prosty sposób dodać zależności do actuatora + micrometer’a i prometheusa.
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId> </dependency> <dependency> <groupId>io.micrometer</groupId> <artifactId>micrometer-registry-prometheus</artifactId> </dependency>Następnie w application.properties (lub analogicznie yaml z odpowiednią strukturą) wystarczy włączyć metryki i możemy strzelać do API:
management.endpoints.web.exposure.include=* curl 'http://localhost:8080/actuator/caches' -i -X GETTeraz można przenieść te dane do Prometheusa, zrobić dashboardy na Grafanie, dodać alerty i mamy gotowy system monitorujący. Nie jest to temat na ten artykuł.
Natomiast o ile nie używamy Spring Boota, możemy użyć MBean’ów JMX’a. o ile korzystasz z popularnego rozwiązania do cache’owania w Javie, to jest duża szansa, iż to rozwiązanie daje możliwość udostępnienia danych przez JMX. Osobiście korzystając z tych metryk, używałem bezpośrednio DataDog’a, więc nie jestem w stanie powiedzieć czy integracja ze stackiem Prometheus + Grafana jest tu możliwa, ale zakładam, iż tak.
Podsumowanie

Cache jest potężnym narzędziem, które może znacząco przyspieszyć działanie aplikacji. Poprzez inteligentne przechowywanie danych w pamięci podręcznej, możemy zmniejszyć czas dostępu do nich i zwiększyć wydajność. Warto zatem znać i rozważyć wykorzystanie cache’a.
Jeżeli chciałbyś rozwinąć którąś z sekcji, podzielić się swoją opinią czy doświadczeniami, to zachęcam do dyskusji w komentarzach.