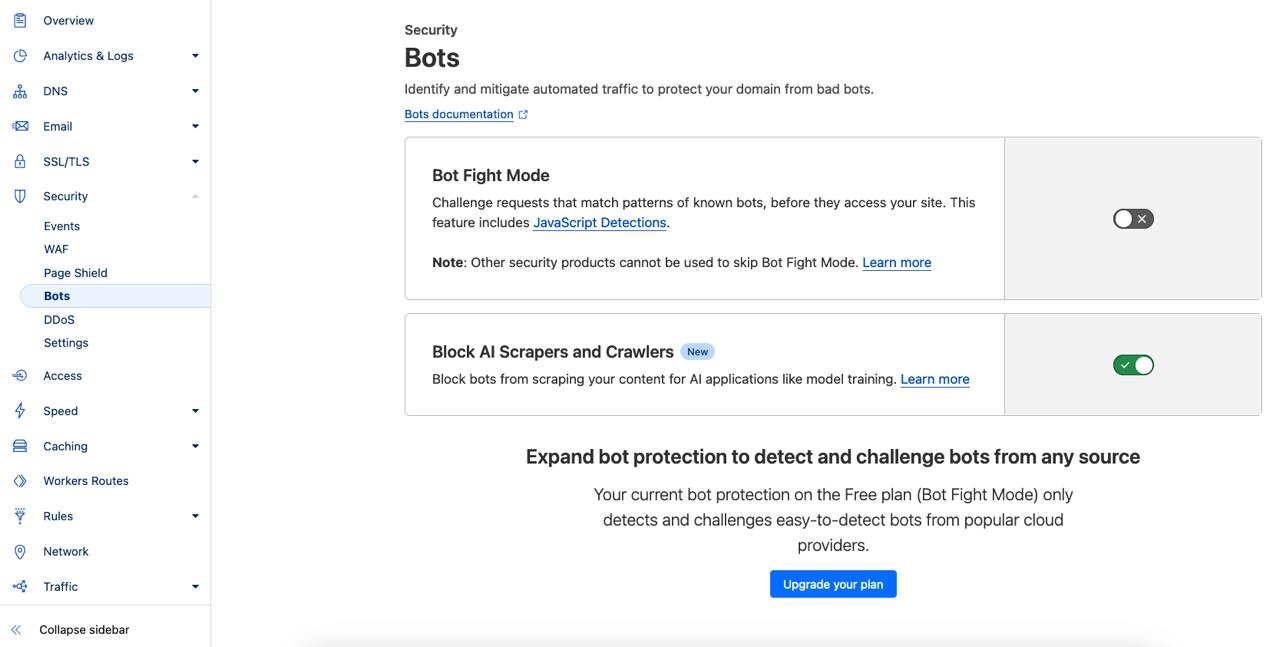
Serwisy internetowe korzystające z proxy oferowanego przez Cloudflare mogą zastosować nową funkcję zapewniającą blokowanie różnych crawlerów używanych do treningu modeli sztucznej inteligencji. Ochrona nie działa wyłącznie na podstawie filtrowania nagłówka User-Agent, bo niektóre modele „przedstawiają się” jako standardowe przeglądarki internetowe właśnie w celu uniknięcia wykrycia przez administratorów czy różne usługi WAF. Cloudflare opisuje, iż zastosowali ochronę opartą na uczenia maszynowego, który z kolei skuteczne rozpoznaje narzędzia używane przez modele do indeksowania zawartości witryn WWW. Funkcjonalność dostępna jest także w bezpłatnym planie, a jej aktywacji dokonamy po wejściu w zakładkę Security -> Bots i zaznaczeniu checkbox’a przy opcji Block AI Scrapers and Crawlers.
Zastosowanie wydaje się oczywiste i może mieć duże znaczenie w kontekście ochrony własności intelektualnej. Podany przez Cloudflare przykład wartej około 60 milionów USD umowy pomiędzy Google a Reddit dotyczącej udostępniania danych z tej platformy do trenowania AI od Google świadczy, iż takowe usługi są cenne z biznesowego punktu widzenia. Nie widać więc uzasadnienia w bezpłatnym udostępnianiu naszych informacji choćby zaawansowanym botom. Wiadomo oczywiście, iż nie każdy serwis zawiera jakkolwiek użyteczne dane, natomiast kwestia ochrony wspomnianej własności intelektualnej powinna być absolutnie kluczowa.
Mimo wszystko warto zwrócić uwagę na inny trend, czyli korzystanie ze „sztucznej inteligencji” do wyszukiwania informacji. Niektóre modele podają źródła, w oparciu o które została wygenerowana odpowiedź, szczególnie gdy prompt dotyczy pewnych statystyk, konieczności przeprowadzania szerszej analizy czy zwyczajnego wyszukiwania treści w Internecie. W tym przypadku ChatGPT poprzez zapytanie do wyszukiwarki Bing podał jako przykład mój artykuł dotyczący GitLab.
 https://chatgpt.com/share/f49ee6f0-8de0-4716-920e-a622c4112616
https://chatgpt.com/share/f49ee6f0-8de0-4716-920e-a622c4112616
Z tego względu dostęp do naszych treści przez różne modele ma także pozytywny aspekt, bo w teorii może mieć wpływ na zwiększenie liczby odwiedzin w docelowym serwisie.
Blokadę botów możemy przeprowadzić także we własnym zakresie, o ile znamy ich źródłowe adresy IP bądź zawartość wysyłaną w nagłówku User-Agent. Druga metoda jest używana częściej i dzięki temu można m.in. zablokować na poziomie serwera WWW dostęp dla crawlerów wyszukiwarek, jeżeli chcemy możliwie skutecznie uniknąć indeksowania publicznie dostępnej witryny. Przykłady konfiguracji takiej blokady dla serwerów Apache, NGINX i IIS podano poniżej. User-Agent wykorzystywany przez Googlebot został podany na tej stronie.
Apache
Do pliku .htaccess lub w konfiguracji virtual host wystarczy dodać regułę rewrite.
Odpowiedź serwera:
NGINX
W location / należy dodać warunek zwracający odpowiedź HTTP 403, gdy w nagłówku znajdzie się fraza pasująca do wzorca.
Odpowiedź serwera:
IIS
W pliku web.config pozostaje dodać odpowiednią regułę. Wymagany jest zainstalowany URL Rewrite.
Przykładowa zawartość:
Odpowiedź serwera:
Użycie Cloudflare jako reverse proxy w ogólnych przypadkach jest dobrym rozwiązaniem. Często nie istnieje wtedy możliwość rozpoznania adekwatnego adresu IP serwera hostującego daną witrynę, ponieważ ruch w pierwszej kolejności zostaje obsłużony przez serwery Cloudflare, które przekażą zapytania klienta do docelowej maszyny — z zewnątrz nasza domena kieruje na adresy należące do Cloudflare. Natomiast jeżeli na jednym serwerze hostujemy kilka domen (co jest standardową praktyką) mogących zostać z nami powiązanych (np. inna domena najwyższego poziomu dla tej samej firmy), które nie są dostępne poprzez Cloudflare, to tym sposobem każdy będzie w stanie poznać prawdziwy adres IP serwera.
Należy też mieć świadomość, iż istnieją usługi pozwalające na sprawdzenie historii rekordów DNS dla dowolnej domeny. jeżeli wcześniej nie była obsługiwana przez Cloudflare, to możliwe będzie odkrycie np. poprzednich wpisów dla rekordu A (zawierającego adres IPv4), więc także poprzedniego adresu IP. Rozwiązaniem jest migracja witryny na nową maszynę przed dodaniem proxy Cloudflare.
Nie potrzebujemy oczywiście zewnętrznych usług w celu realizacji podobnej do Cloudflare architektury — popularny serwer NGINX bardzo dobrze sprawdza się w roli reverse proxy i z jego użyciem także istnieje możliwość „ukrycia” adresów IP adekwatnych maszyn, m.in. tych niedostępnych publicznie, a działających wyłącznie w sieci lokalnej. Z drugiej strony Cloudflare zapewnia szereg innych przydatnych funkcjonalności, jak ochrona przed atakami DDoS czy rozwiązanie WAF. Nie jest to oczywiście kompleksowa metoda zabezpieczenia naszej infrastruktury.
Z perspektywy administracji IT pojawia się konieczność dodatkowej konfiguracji. W standardowych sytuacjach, gdy nie korzystamy z żadnego reverse proxy, przez serwer WWW logowany jest faktyczny adres IP klienta, więc stosunkowo gwałtownie można sprawdzić m.in. skąd pochodzą odwiedziny danej domeny, zweryfikować zgłoszone błędy działania aplikacji, jak również zebrać dowody ewentualnych ataków. W przypadku Cloudflare adres klienta także jest ukrywany i do logów zapisany zostaje tak naprawdę adres jednego z serwerów Cloudflare. Rzeczywisty adres klienta można sprawdzić w panelu Cloudflare bądź skonfigurować serwer WWW zgodnie z dokumentacją.








