Ostatecznie poszedłem na "Building systems that are #neverdone", Jamesa Lewisa. Było ogólnie o zasadach YAGNI, DRY, TDD, SRP, KISS… Nic konkretnego, już Wujek Bob i inni powiedzieli to 100 razy. Jedyne co to biblioteka Pact się przewinęła po raz drugi na konferencji.
Następnie udałem się na wykład Tomka Nurkiewicza pt.: "Hystrix – managing failures in distributed systems". Jest to biblioteka od Netflix’a, który w tej chwili generuje sporo ruchu internetowego. A sam Hystrix jest implementacją wzorca Fail Fast. Chodzi o to, iż w rozproszonych systemach (np. modne ostatnio wszem i wobec mikroserwisy) czasem część usług może ulec awarii. Jakiś serwis / część systemu może być pod dużym obciążeniem, chwilowo niedostępna, lub odpowiada dopiero po długim czasie. Zamiast próbować taką usługę ciągle odpytywać (i robić jej DoS’a) to może lepiej jest się wstrzymać z zapytaniami i od razu propagować błędną odpowiedź w systemie, albo jakoś inaczej na nią reagować. Podejście takie powoduje, iż szybciej mamy informację, iż coś nie działa. Dodatkowo jak odciążymy daną usługę, to jest szansa, iż się ona naprawi, tzn. skończy przetwarzać zaległe zadania i będzie można z niej ponownie skorzystać. System wtedy jest w stanie samemu się wyleczyć.
Jak działa Hystrix? Mianowicie każde wywołanie, które może się nie udać, opakowujemy w HystrixCommand. Po wywołaniu metody execute() zostanie zwrócona wartość tego co zostało opakowane. Gdy serwis nie odpowiada dłużej niż 1 sekunda (oczywiście można to zmienić), to zostanie zwrócona wartość błędu (Fallback), którą możemy sobie zdefiniować (domyślnie UnsupportedOperationException). Domyślnie każda komenda (tzn. tego samego typu) posiada pulę wątków ustawioną na 10. Według twórców Hystrixa nie potrzeba więcej.
Oczywiście mamy też większą możliwość konfiguracji zachowania, np. przy jakim procencie błędnych odpowiedzi, albo przy jakiej minimalnej liczbie błędnych request’ów, w danym oknie czasowym nie męczyć więcej zewnętrznej usługi.
static class CircuitBreakingDownloadCommand extends HystrixCommand {
protected CircuitBreakingDownloadCommand() {
super(
Setter.withGroupKey(HystrixCommandGroupKey.Factory.asKey("Download"))
.andCommandKey(HystrixCommandKey.Factory.asKey("SomeCommand"))
.andThreadPoolPropertiesDefaults(
HystrixThreadPoolProperties.Setter()
.withMetricsRollingStatisticalWindowInMilliseconds(10_000))
.andCommandPropertiesDefaults(
HystrixCommandProperties.Setter()
.withCircuitBreakerEnabled(true)
.withCircuitBreakerErrorThresholdPercentage(50)
.withCircuitBreakerRequestVolumeThreshold(20)
.withCircuitBreakerSleepWindowInMilliseconds(5_000))
);
}
}
Kod z repozytorium Tomka.
Hystrix oferuje jeszcze domyślny servlet, który generuje strumień statystyk odnośnie każdego rodzaju Hystrix’owej komendy. Widać go standardowo pod /hystrix.stream i maksymalnie 5 klientów może się pod niego podłączyć. W ładny sposób są te dane wizualizowane dzięki Hystrix Dashboard. Gdy chcemy na naszej "desce rozdzielczej" widzieć informacje z wielu miejsc, to dzięki Turbine możemy połączyć wiele strumieni w jeden i pod niego podłączyć dashboard. Przykładowy wygląd poniżej:
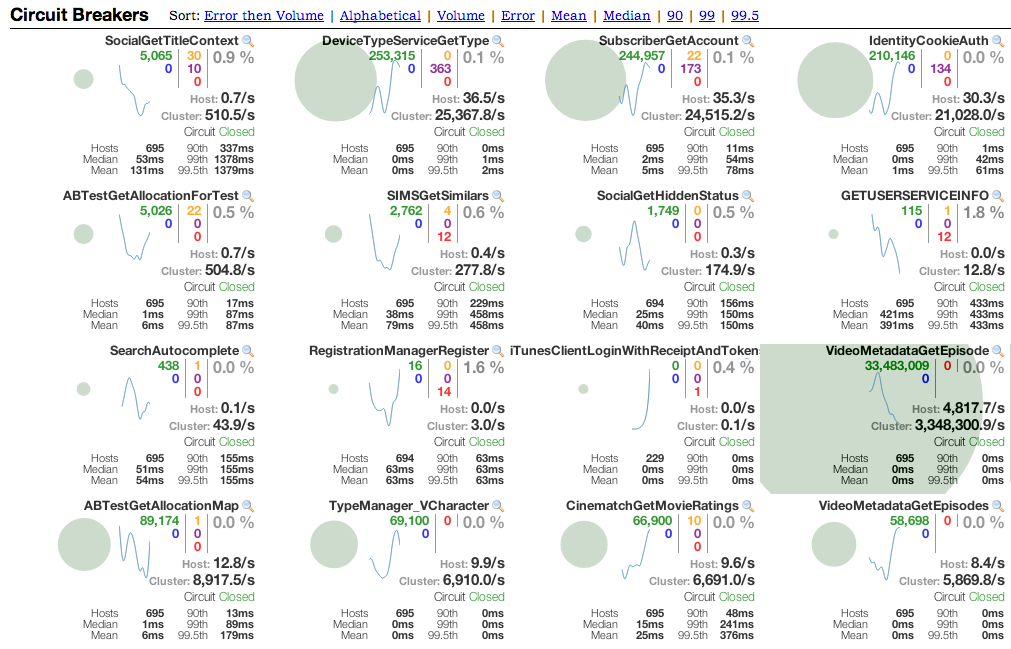
Możemy również zapisywać sobie te statystyki i ładnie wyświetlać w Graphite. Dokładny opis jak tego dokonać znajdziemy na blogu Tomka. Było jeszcze omawiane pobieżnie parę zagadnień, ale czas już gonił. Z ciekawostek to jeszcze było o Executors.newFixedThreadPool(), które to są niebezpieczne w środowisku EE, bo wrzucają wątki do kolejki, która jest nieskończona. Może to się zakończyć błędem OutOfMemory i to nie koniecznie w tym miejscu.
Z ciekawych trików, to Tomek jeszcze korzystał z Ctrl + C do zaznaczania całej linii w IntelliJ-u. Dobre na prezentacje. I jeszcze korzystał z Apache Bench. Jest to odpowiednik JMeter’a, ale działa w linii komand i jest dołączony (i był stworzony) do serwera Apache httpd. Przykładowy kod z prezentacji jest dostępny na githubie: nurkiewicz/hystrix-demo, a prezentację (i to po polsku) można obejrzeć na kanale Warszawskiego JUGa: WJUG #161.
Następnie udałem się na prezentację programisty z Elastic’a, David Pilato na temat: "Make sense of your (BIG) data!". Akcent francuski i żarty z których siał się tylko prowadzący były straszne, ale prelegent nie okazał się kompletnym francuskim ignorantem. Na koniec choćby próbował powiedzieć coś po polsku.
Na początku prezentacji było o tym jak dużo danych generujemy każdego dnia.

Następnie prelegent pokazał, jak można budować przykładowe zapytania w Elastic’u (dawniej ElasticSearch) i skupił się na aggregacjach. Pokazał jak wygląda Marvel, który służy do monitorowania instancji Elastic’a. Dla instancji produkcyjnych narzędzie jest płatne, dla pozostałych serwerów (typu test, QA, stage itp) darmowe. Z ciekawych funkcjonalności, to można sobie odtworzyć, co się działo w shardami, gdy do klastra dołączały się kolejne instancje węzłów.
Dalej prelegent pokazał jak dzięki Kibany można w łatwy sposób wizualizować wszelakie dane jakie mamy zapisane w indexie Elastica.
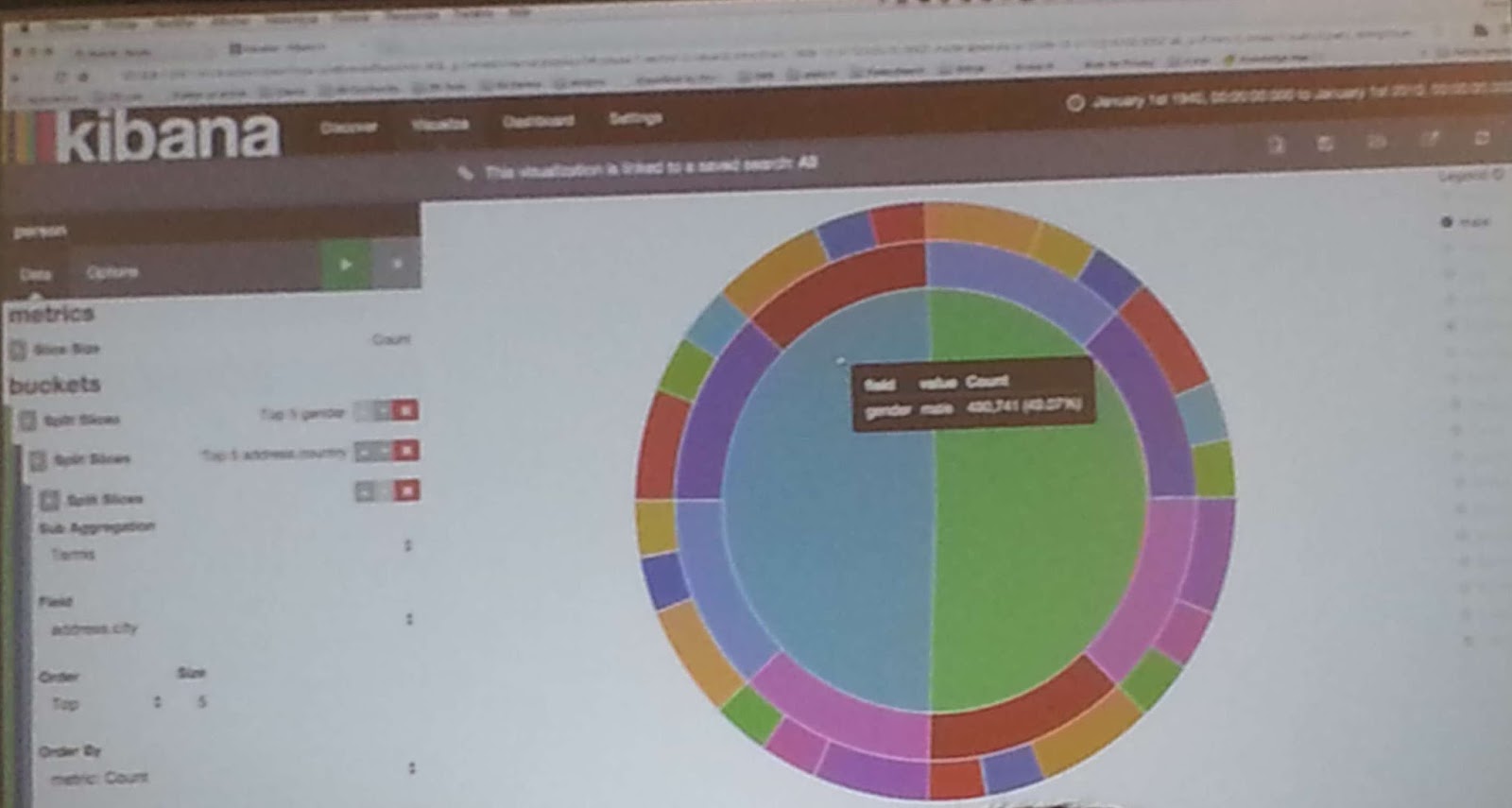
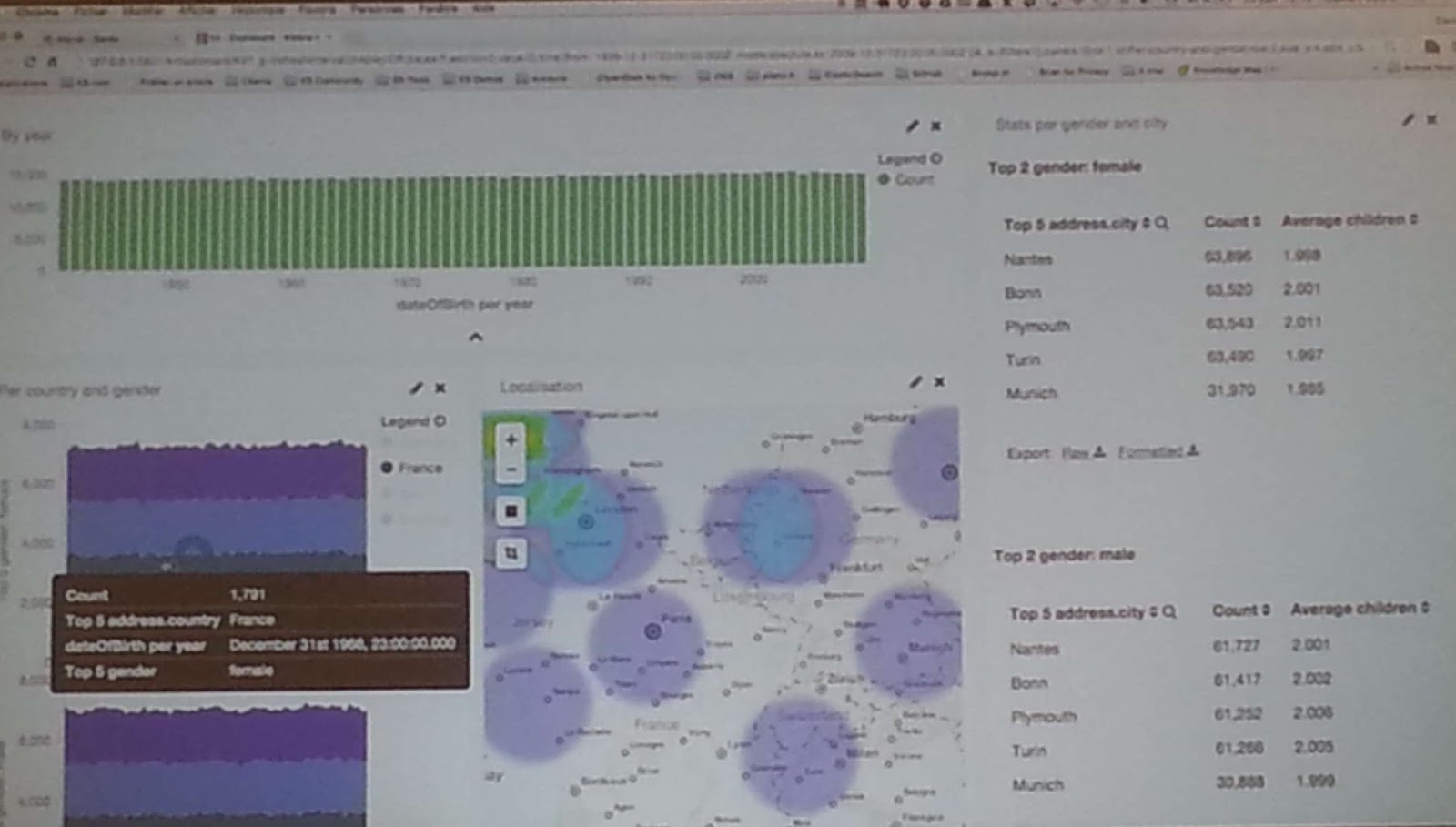
I to chyba tyle z prezentacji. Całkiem dobra, ale dla osoby która miała już kontakt z tymi narzędziami nie była bardzo odkrywcza. Miałem jednak za to okazję zadać parę pytań i tak rekomendowaną biblioteką javową do Elastica jest jej oficjalna wersja która to może działać jako węzeł w klastrze, wykorzystywać warstwę transportową między węzłami (udostępnianą standardowo na porcie 9300) i pytać bezpośrednio do miejsca gdzie znajdują się poszukiwane dane.
Kolejna prezentacja, na którą poszedłem, była o "Flavors of Concurrency in Java" prowadzona przez Olega Šelajeva. Na początku było dużo wstępu i dopiero po 20 minutach pojawił się pierwszy kod, na którym omawiał wątki w oldschool’owym wydaniu. Nie dałem rady i wyszedłem. Byłem jeszcze chwilę na Reviewing Architectures, Nathaniela Schutta, ale nie byłem we właściwym kontekście i nie dałem rady.
Kolejna prezentacja była najbardziej futurystyczna z całej konferencji a mianowicie: "WebVR - democracy in Virtual Reality", Marcina Lichwały. Był jeszcze jakiś drugi prowadzący, ale nie był wymieniony z nazwiska. Obaj prelegenci pracują w firmie Unit9, która dostarcza rozwiązania wirtualnej rzeczywistości. Organizowali również pierwszy w Polsce festiwal i konkurs wirtualnej rzeczywistości w Łodzi.
Chłopaki opowiadali, jakie zastosowania ma wirtualna rzeczywistość. I jest to nie tylko rozrywka, kampanie reklamowe, ale i edukacji i medycyna (np.: redukcja bólu youtu.be/jNIqyyypojg).
Nie pamiętam jakimi okularami się zajmują chłopaki, ale trend jest taki, aby całość obrazu była generowana przez przeglądarki internetowe. Dzięki temu staje się to przenośne. W tym momencie jedynie MozVR (z Mozilli) i Chromium wspierają generowanie doznań wirtualnej rzeczywistości. Ostatecznie zawsze zostaje nam wersja dla ubogich w postaci Cardboard.
W ramach prezentacji miałem możliwość (podobnie jak inni chętni) przetestować okulary. Obraz całkiem dobry, widać było jedynie małe punkty, na które składał się obraz. Ale to bardzo dobry kierunek i powoli zbliżamy się do już całkiem porządnego sprzętu. Jedynie niektóre osoby z chorobą lokomocyjną nie będą w stanie do końca korzystać z tych wynalazków, bo patrząc w bok i do góry, ciągle niby biegnąc, może zrobić się niedobrze.
W kolejnym bloku nie było możliwości wyboru, bo był zaplanowany tylko jeden wykład: "Get Past the Syntax, The Real Scare is in the Semantics", prowadzony przez Venkata Subramaniama. Oczywiście była pełna sala.

Zaczęło się od tego, iż ludzie rożnie postrzegają te same rzeczy. Programiści dlatego nie lubią nowej składni kodu, dlatego wiele języków programowania jest do siebie podobnych C# jest jak Java, a ta jak C++, a C++ jak C...
Venkat chciał nam przez to uświadomić, iż nie powinniśmy zwracać uwagi na składnię kodu, a na jego semantykę. No i nasza strefa konfortu powoduje, iż się zawsze doszukujemy w nowej składni, tego co już znamy. Jak dla mnie nic więcej konkretnego się nie dowiedziałem na tej prezentacji.
Na koniec drugiego dnia poszedłem jeszcze na "Painfree Object-Document Mapping for MongoDB" prowadzoną przez Philippa Krenna. Prelegent opowiadał o rozwiązaniu Morphia, które pozwala na mapowanie obiektów Javowych na dokumenty MongoDB. Całość bardzo wygląda jak implementacja JPA (adnotacje na klasach i polach).
Dalej było o sposobach wykorzystania tego narzędzia, przykłady i dobre praktyki. Na koniec było jeszcze krótko o spring-data-mongodb. Niby robi to samo co Morphia, ale twórcom się nie spodobała ta implementacja i w zamierzchłych czasach miała sporo błędów, więc twórcy MongoDb wzięli się za własną implementację. Ciekawie też brzmi Fongo, który dostarcza implementację in memory dla MongoDb. I ostatnie narzędzie: Critter, które daje nam coś ala Hibernate’owe Criteria API dla Morphi. To już zostawię bez komentarza.
Kolejna prezentacja, na którą poszedłem, była o "Flavors of Concurrency in Java" prowadzona przez Olega Šelajeva. Na początku było dużo wstępu i dopiero po 20 minutach pojawił się pierwszy kod, na którym omawiał wątki w oldschool’owym wydaniu. Nie dałem rady i wyszedłem. Byłem jeszcze chwilę na Reviewing Architectures, Nathaniela Schutta, ale nie byłem we właściwym kontekście i nie dałem rady.
Kolejna prezentacja była najbardziej futurystyczna z całej konferencji a mianowicie: "WebVR - democracy in Virtual Reality", Marcina Lichwały. Był jeszcze jakiś drugi prowadzący, ale nie był wymieniony z nazwiska. Obaj prelegenci pracują w firmie Unit9, która dostarcza rozwiązania wirtualnej rzeczywistości. Organizowali również pierwszy w Polsce festiwal i konkurs wirtualnej rzeczywistości w Łodzi.
Chłopaki opowiadali, jakie zastosowania ma wirtualna rzeczywistość. I jest to nie tylko rozrywka, kampanie reklamowe, ale i edukacji i medycyna (np.: redukcja bólu youtu.be/jNIqyyypojg).
Nie pamiętam jakimi okularami się zajmują chłopaki, ale trend jest taki, aby całość obrazu była generowana przez przeglądarki internetowe. Dzięki temu staje się to przenośne. W tym momencie jedynie MozVR (z Mozilli) i Chromium wspierają generowanie doznań wirtualnej rzeczywistości. Ostatecznie zawsze zostaje nam wersja dla ubogich w postaci Cardboard.
W ramach prezentacji miałem możliwość (podobnie jak inni chętni) przetestować okulary. Obraz całkiem dobry, widać było jedynie małe punkty, na które składał się obraz. Ale to bardzo dobry kierunek i powoli zbliżamy się do już całkiem porządnego sprzętu. Jedynie niektóre osoby z chorobą lokomocyjną nie będą w stanie do końca korzystać z tych wynalazków, bo patrząc w bok i do góry, ciągle niby biegnąc, może zrobić się niedobrze.
W kolejnym bloku nie było możliwości wyboru, bo był zaplanowany tylko jeden wykład: "Get Past the Syntax, The Real Scare is in the Semantics", prowadzony przez Venkata Subramaniama. Oczywiście była pełna sala.

Zaczęło się od tego, iż ludzie rożnie postrzegają te same rzeczy. Programiści dlatego nie lubią nowej składni kodu, dlatego wiele języków programowania jest do siebie podobnych C# jest jak Java, a ta jak C++, a C++ jak C...
Venkat chciał nam przez to uświadomić, iż nie powinniśmy zwracać uwagi na składnię kodu, a na jego semantykę. No i nasza strefa konfortu powoduje, iż się zawsze doszukujemy w nowej składni, tego co już znamy. Jak dla mnie nic więcej konkretnego się nie dowiedziałem na tej prezentacji.
Na koniec drugiego dnia poszedłem jeszcze na "Painfree Object-Document Mapping for MongoDB" prowadzoną przez Philippa Krenna. Prelegent opowiadał o rozwiązaniu Morphia, które pozwala na mapowanie obiektów Javowych na dokumenty MongoDB. Całość bardzo wygląda jak implementacja JPA (adnotacje na klasach i polach).
Dalej było o sposobach wykorzystania tego narzędzia, przykłady i dobre praktyki. Na koniec było jeszcze krótko o spring-data-mongodb. Niby robi to samo co Morphia, ale twórcom się nie spodobała ta implementacja i w zamierzchłych czasach miała sporo błędów, więc twórcy MongoDb wzięli się za własną implementację. Ciekawie też brzmi Fongo, który dostarcza implementację in memory dla MongoDb. I ostatnie narzędzie: Critter, które daje nam coś ala Hibernate’owe Criteria API dla Morphi. To już zostawię bez komentarza.








