Czy zastanawiałeś się kiedyś, jak działa doker i co sprawia, iż potrafi uruchomić odizolowane niezależne względem siebie kontenery? Niektórzy sądzą, iż Doker to wirtualna maszyna, niektórym wystarczy, iż działa i nie ma co zagłębiać się w detale.
Niektórzy tak jak i ja uważają, iż poświęcenie trochę czasu w zdobycie wiedzy jak coś działa i jak jest zbudowane pod spodem, procentuje i pozwala lepiej wykorzystać moc drzemiącą w wykorzystywanym narzędziu. Nie mam tu na myśli wertowania dokumentacji od góry do dołu i wchodzenie w Karnel internals, ale troszkę wiedzy "Deep dive" zawsze się przyda :)
W pierwszej części przedstawię ci, jak zbudowany jest Doker jego obraz oraz kontener dokerowy. Dodatkowo postaram się zaprezentować optymalizację obrazów dla aplikacji Spring. W drugiej części dorzucę również Angular, opiszę Multi-stage build i buildkit, dzięki którym przejdziemy od FAT Image zawierającego mnóstwo niepotrzebnych rzeczy do lekkiego obrazu zawierającego tylko aplikację i środowisko potrzebne do jej uruchomienia.
Doker to nie VM
Zacznijmy od tego, iż Doker to nie maszyna wirtualna, oczywiście w Windows/Mac Doker używa wirtualnej maszyny do dostarczenia karnela dla kontenerów linuksowych. Jednak jeżeli ktoś wykorzystuje kontenery Windowsowe, to maszyna Wirtualna w Windowsie nie jest powoływana. Podobnie jak ktoś korzysta z WSL2, wtedy doker zamiast VM wykorzystuje Windows Subsystem for Linux jako backend. Więcej o WSL dowiesz się w innym moim poście TUTAJ
Zarówno Docker jak i Wirtualna maszyna używana jest do zapewnienia aplikacji odizolowanego przenośnego środowiska. Jednak oba rozwiązania realizują to na swój sposób.
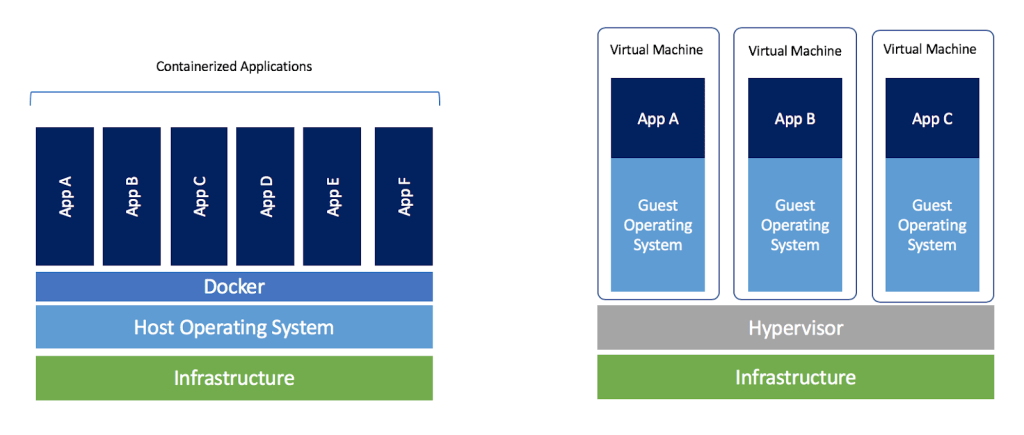 Źródło: https://www.docker.com/blog/containers-replacing-virtual-machinesa
Źródło: https://www.docker.com/blog/containers-replacing-virtual-machinesaWirtualna maszyna:
- Każda wirtualna maszyna posiada pełną kopię systemu operacyjnego, oraz kopię wirtualnych podzespołów(CPU, RAM, DYSK itp.). Powoduje to dość dużą zasobożerność oraz dłuższy czas uruchamiania względem dokera.
- W maszynie wirtualnej zaczynasz od pełnego systemu operacyjnego i w zależności od aplikacji możesz próbować usunąć rzeczy, których nie potrzebujesz
- W maszynie wirtualnej może być uruchomionych wiele aplikacji
Kontener Dokera:
- Współdzieli karnel i zasoby systemu operacyjnego, przy czym przez cały czas jest odseparowanym procesem w przestrzeni użytkownika. Jako iż nie musimy hostować całego systemu operacyjnego, kontenery zużywają mniej zasobów komputera niż VM.
- Budujesz obraz, który dokładnie potrzebujesz. Zaczynasz od podstaw i dodajesz tylko to co jest wymagane do uruchomienia aplikacji.
- Doker rekomenduje uruchamianie jednego serwisu/procesu per kontener.
- Kontener żyje tak długo jak żyje uruchomiony w nim proces
Po przeczytaniu cech jednego i drugiego rozwiązania mogą nasuwać się pewne pytania:
- Skoro Kontener to nie wirtualna maszyna to jak doker izoluje proces i odseparowuje dla niego dysk / sieć i inne zasoby?
- Skoro doker container nie ma w sobie pełnego OS to dlaczego kontener często posiada dystrybucje Linuksa typu Alpine, Ubuntu itp.?
Na te pytania postaram się odpowiedzieć w następnym akapicie
Kontenery w Linuksie
Stworzenie "kontenera" było możliwe w karnelu Linuksa na długo, zanim powstał Doker, jednak raczej nieliczni potrafili to zrobić, było to bardzo trudne i wymagało ogromnej wiedzy, o tym jak zbudowany jest karnel.
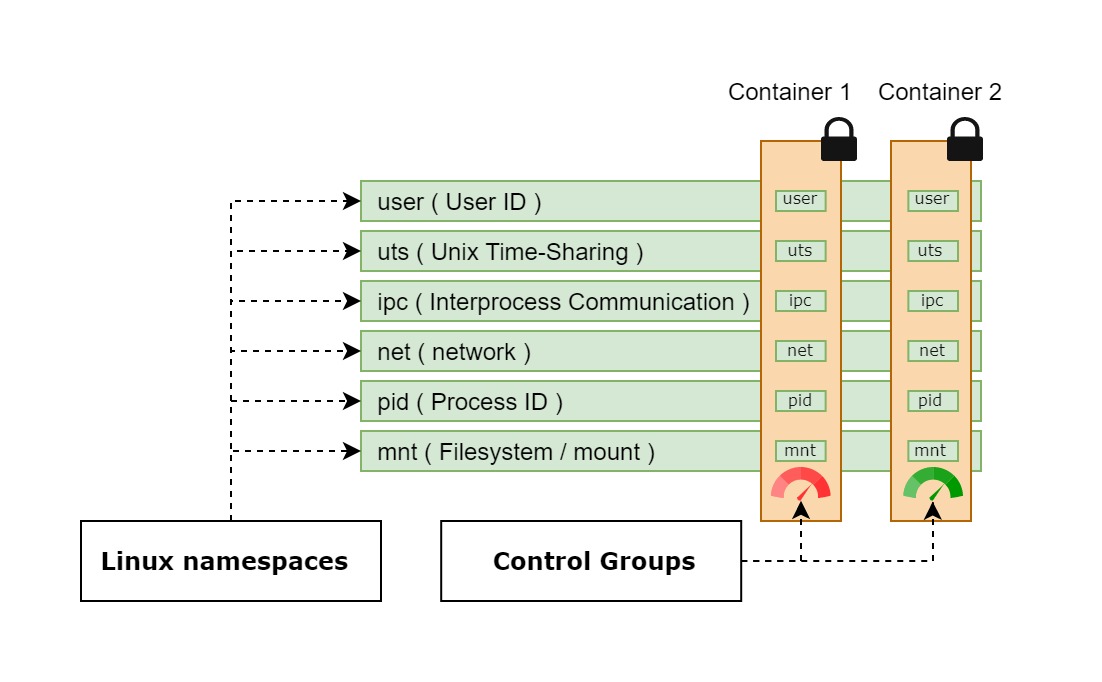
Aby stworzyć kontener i go odseparować trzeba umiejętnie wykorzystać 2 rzeczy:
- Namespace - Odpowiedzialne za izolacje i dzielenie zasobów jądra ( ogranicza to co kontener może zobaczyć )
- Control Groups (cgroups) - grupowanie i nakładanie limitów ( ogranicza to ile kontener może użyć )
Zanim powstał Doker, oprogramowaniem potrafiącym zarządzać wyżej wymienionymi możliwościami Karnela było LXC (LinuX Containers). Początkowo Doker również wykorzystywał je do tworzenia kontenerów jednak przez to, iż nie miał nad nim kontroli, W 2014 roku postanowił porzucić LXC i stworzyć swoje własne rozwiązanie o nazwie libcontainer (runc)
Libcontainer (runc) tworząc kontener tworzy własne odizolowane grupy przestrzeni nazw z własnym Process ID, własną siecią i adresem IP, własny system plików i tak dalej. Wszystkie przydzielone przestrzenie są zabezpieczone i niewidoczne dla innego kontenera. Jednak to nie wszystko, aby nie pozwolić jednemu kontenerowi na zabranie zasobów innym kontenerom, runc nakłada Controle Groups ustalające ile poszczególnych podzespołów może wykorzystać dany kontener (RAM, CPU itp)
Wracając do pytań:
Skoro Kontener to nie wirtualna maszyna to jak docker izoluje proces i odseparowuje dla niego dysk / sieć i inne zasoby?
Po przeczytaniu Akapitu poświęconemu kontenerom Linuksa powinieneś już znać na to odpowiedź :)
Skoro docker container nie ma w sobie pełnego OS to dlaczego kontener często posiada dystrybucje linuxa typu Alpine, Ubuntu itp?
Żeby odpowiedzieć na to pytanie musimy wyobrazić sobie podział systemu na 2 części karnel oraz usermode/userland. Wiemy już, iż kontenery nie posiadają swojego karnela i wykorzystują ten dostępny w systemie, na którym zainstalowany jest Doker. Jednak każdy kontener może posiadać swój własny usermode dostarczany przez dystrybucje Linuksa.
W porównaniu do pełnej dystrybucji Linuksa ta przeznaczona dla dokera jest mocno przyciętą i zawiera tylko niezbędne binarki i biblioteki. Przykładowo Ubuntu po wyrzuceniu wszystkich zbędnych rzeczy waży 72.9 MB zamiast około 2.5 GB (pełna dystrybucja). Istnieją również dużo mniejsze dystrybucje np. Linux Alpine zajmuje TYLKO 5.57 MB przyznaj imponujące. Co ważne mniejszy rozmiar obrazu = mniej dziur bezpieczeństwa.
⚡Ważne⚡
Używając Dokera na Linuksie nie uruchomisz kontenera z Windowsem w środku. Dlaczego ? A no dlatego, iż kontener wykorzystuje karnel Hosta, Kontener z Windowsem wymaga karnela Windows NT, którego nie ma na Linuksie
Tak samo uruchomienie kontenera Linuksowego na Windowsie/macOS nie jest możliwe bez specjalnie przygotowanej przez Dokera wirtualnej maszyny z karnelem Linuksa.
Ostatnio sprawy się trochę zmieniły i na Windowsie, zamiast maszyny wirtualnej doker może wykorzystać WSL2 co znacząco przyspiesza wydajność względem tradycyjnej maszyny wirtualnej, o tym co to jest WSL możesz przeczytać w moim poście TUTAJ
Ok koniec teorii przejdźmy do praktyki :)
Dokeryzacja Springa 🐳
Według dokumentacji
Posługując się oficjalną dokumentacją, aby skonteneryzować aplikację springa, musimy ją zbudować przed wrzuceniem do obrazu dokerowego. Po zbudowaniu w Dockerfile możemy wskazać wygenerowany jar i go wykorzystać, wygląda to mniej więcej tak:
FROM openjdk:11-jdk-slim ARG JAR_FILE = target/*.jar COPY ${JAR_FILE} app.jar ENTRYPOINT ["java","-jar","target/jhipster-0.0.1-SNAPSHOT.jar"]Ok zbudujmy mavenem aplikację i zmierzmy czas budowania oraz rozmiar
do wszystkich budowań jako source będę korzystał z jhipster, ponieważ ma dużo zależności a najlepiej będzie widać przeprowadzone optymalizacje na projekcie z dużą ilością zależnosći
| 1 | Brak | 6.48 Min | 402MB |
| 2 | w kodzie | 15 Sec | 402MB |
Jak widać pierwsze budowanie trwa dłużej, ponieważ musimy ściągnąć zależności aplikacji do lokalnego cache mavena .m2/repository przed zbudowaniem aplikacji. Drugie budowanie korzysta z wcześniej ściągniętych zależności, przez co trwa o wiele krócej.
Według mnie wady takiego rozwiązania to:
- Maszyna, na której budujemy obraz dokerowy musi mieć zainstalowaną Javę i mavena
- Maszyna musi mieć skonfigurowane odpowiednie wersje oprogramowania do zbudowania artefaktu np. Java 11, Maven 3.6
- Źródłem prawdy dla obrazu nie jest kod, tylko dostarczony artefakt
- Jeśli artefakt się nie zbuduje np. zła wersja Javy doker nie zbuduje obrazu (dwa punkty gdzie może coś pójść nie tak)
- Żeby postawić aplikację składającą się z kilku mikroserwisów lokalnie np. dzięki docker-compose musimy wcześniej zbudować wszystkie artefakty manualnie i zadbać o odpowiednie środowisko uruchomieniowe 😔
Skoro mamy tyle wad to może spróbujmy zbudować wszystko dokerem w jednym obrazie ? Prawda, iż dobry pomysł ? Czemu ludzie od springa sami na to nie wpadli ? :)
Po małych modyfikacjach nasz Dockerfile będzie wyglądał tak:
FROM maven:3.6.3-openjdk-11-slim COPY src app/src COPY pom.xml /app RUN mvn -f app/pom.xml clean package -Dmaven.test.skip=true ENTRYPOINT ["java","-jar","app/target/jhipster-0.0.1-SNAPSHOT.jar"]uruchommy budowanie i sprawdźmy rezultaty :) (testy pominięte celowo)
| 1 | Brak | 10.13 Min | 711MB |
| 2 | kodzie | 8.21 Min | 711MB |
| 3 | Brak | 3 Sec | 711MB |
Chyba jednak to nie był dobry pomysł ...
Dlaczego tak się stało ? Dlatego iż wraz z przeniesieniem budowania aplikacji do dokera tracimy local cache dla zależności w postaci .m2/repository a wszystkie zależności są pobierane i zapisywane w obrazie. Dodatkowo za pierwszym razem musimy pobrać obraz mavena z repozytorium dokera, co wydłuża czas pierwszego budowania.
W drugim budowaniu nie musimy pobierać obrazu na nowo stąd nieco krótszy czas. przez cały czas jednak trwa ono długo, ponieważ znowu musimy pobrać wszystkie zależności. Również wielkość obrazu jest bardzo duża jak na tak prostą aplikację.
ale czy możemy coś z tym zrobić ?
Słynne powiedzenie co się dzieje w Vegas, zostaje w Vegas możemy również odnieść do obrazów dokera, ponieważ Co się dzieje w doker image* zostaje w doker image*. Obraz nam puchnie dlatego, iż do zbudowania jara w dokerze potrzeba ściągnąć masę zależności, które nie są później wykorzystywane, ale niestety już w nim zostają.
Skoro na tą chwilę nie możemy nic zrobić z wielkością obrazu, to zobaczmy czy uda nam się, chociaż przyspieszyć czas budowania
spróbujmy zamienić miejscami kopiowanie pom.xml i folder src oraz przestawmy mavena w (częściowy) tryb offline
FROM maven:3.6.3-jdk-11-slim COPY pom.xml . RUN mvn -e -B -Dmaven.test.skip=true dependency:go-offline COPY src ./src RUN mvn -e -B -Dmaven.test.skip=true package ENTRYPOINT ["java","-jar","target/jhipster-0.0.1-SNAPSHOT.jar"]| 1 | Brak | 9.16 Min | 735MB |
| 2 | w kodzie | 1.38 Min | 735MB |
| 3 | w pom.xml | 9.16 Min | 735MB |
Tym prostym zabiegiem w drugim budowaniu gdzie zmieniamy tylko kod aplikacji bez jej zależności, obcieliśmy czas budowania drastycznie z 9:16 do 1:16 minuty. Niestety wielkość obrazu przez cały czas jest ogromna jak na tak prostą aplikację
Powyższy eksperyment pokazuje, iż są jednak istotne zalety budowania artefaktu poza dokerem ( tak jak to zostało zrobione w pierwszym podejściu ) mianowicie:
- Mały rozmiar obrazu
- korzystanie z lokalnego repozytorium mavena brak konieczności ściągania dependency przy budwaniu
Aby oprócz czasu budowania zmniejszyć znacząco rozmiar obrazu, doker wprowadził Multi-stage builds. Więcej o tym rozwiązaniu dowiesz się w 2 części artykułu.
A więc skąd ta różnica?
Co się stało, iż czas budowania po zamianie miejscami pom z src i dodaniu jednej linijki w Dockerfile tak się skrócił? Jedno słowo Warstwy
Warstwy
Cebula ma warstwy, ogry mają warstwy i tak się składa, iż Doker też ma warstwy :)
Czy zastanawialiście się kiedyś, czym tak adekwatnie jest doker image i co takiego ma w środku ?
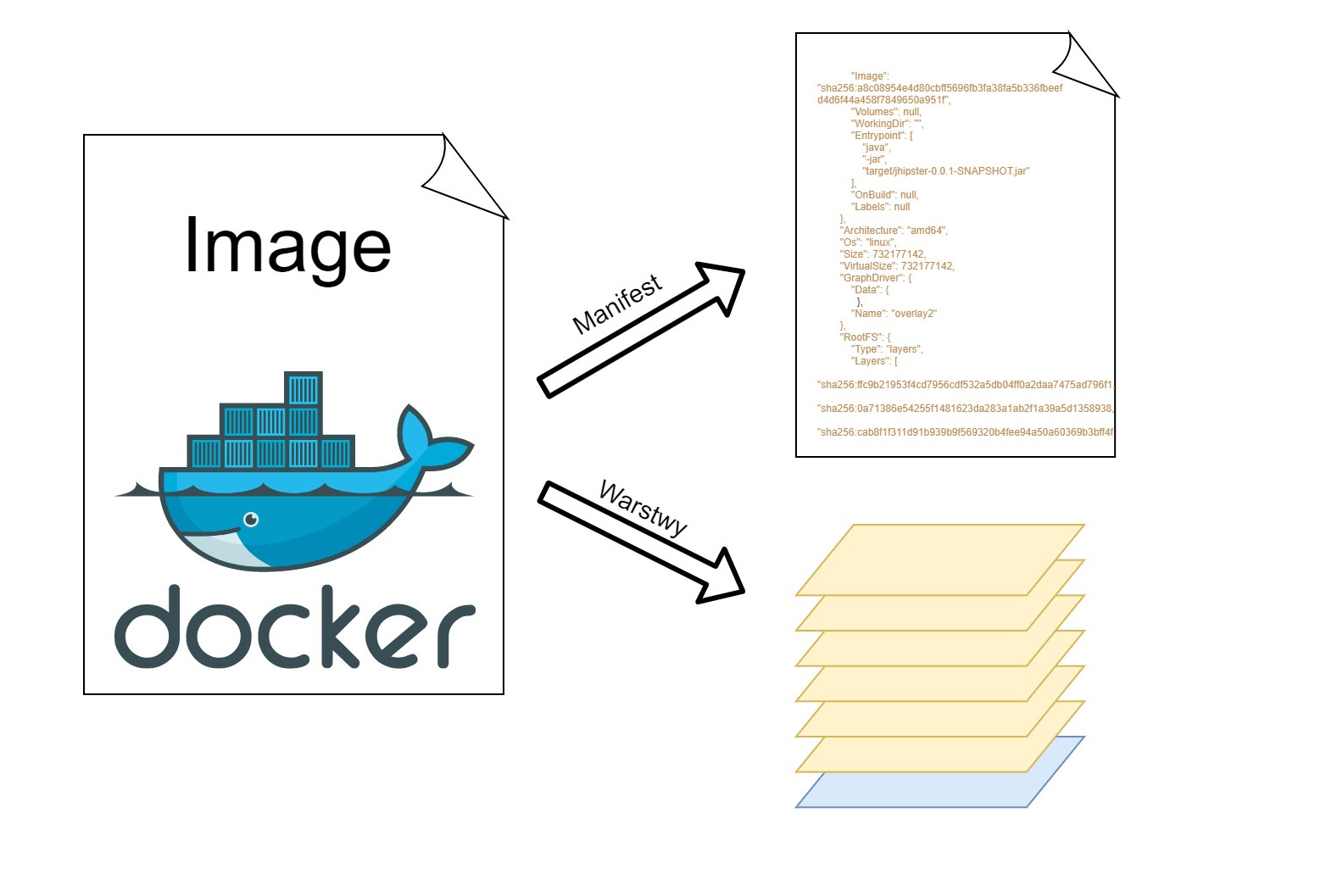
Otóż doker image to tak naprawdę zbiór niezależnych luźno powiązanych warstw read only (o tym później). Oraz plik manifest opisujący metadane obrazu takie jak np. tag, to kiedy obraz został stworzony i to jak połączone są ze sobą pobrane warstwy. Dla lepszego zrozumienia pobierzmy obraz mavena z dockerhub i zajrzyjmy do środka

Jak widać nie pobieramy jednego pliku a kilka w tym warstwy i manifest no dobra, ale co to są te warstwy ?
Warstwa to zestaw plików, które nie są z niczym innym połączone oprócz niej samej, Jedna warstwa nie ma żadnego połączenia z inną, dodatkowo, jako iż warstwa jest tylko do odczytu, nie możemy nic w niej zmienić. To storage driver unifikuje warstwy zgodnie z plikiem manifest i prezentuje je jako całość, dlatego możemy stworzyć kontener. Aby wyświetlić metadane obrazu używamy polecenia docker inspect <nazwa obrazu> zwraca ono wszystkie informacje dotyczące obrazu w postaci JSON.
Gdzie znajdują się warstwy?
Lokalizacja warstw zależy od tego, na jakim systemie pracujemy i jakiego sterownika używa nasza instalacja dokera, aby sprawdzić lokalizacje warstw wystarczy wpisać polecenie docker system info i odnaleźć wpis Root Dir oraz Storage Driver
w moim przypadku są to:
Storage Driver: overlay2 Docker Root Dir: /var/lib/dockerPierwszy wpis to sterownik drugi to mniejsce na dysku gdzie trzymane są dane związane z dokerem, dokładne miejsce gdzie trzymane są warstwy wskazuje połączenie tych dwóch wartości
/var/lib/docker/overlay2⚡ nie dotyczy to instalacji dokera, który jako backend wykorzystuje WSL2 . W przypadku WSL dane trzymane są w:
z poziomu wsl: /mnt/wsl/docker-desktop-data/data/docker/overlay2 z poziomu Windows \\wsl$\docker-desktop-data\mnt\wsl\docker-desktop-data\data\docker\overlay2
Po wy listowaniu zawartości wcześniej wspomnianej ścieżki widzimy katalogi odpowiadające za wszystkie warstwy, jakie aktualnie posiadamy na komputerze.
Aby zobaczyć, które katalogi/warstwy dotyczą konkretnego obrazu wystarczy wpisać polecenie
docker inspect --format '{{json .GraphDriver.Data}}' <id lub nazwa obrazu>
{ "LowerDir":"/var/lib/docker/overlay2/c073cd798015f67df457288151d46908523bc9a445da7fc61144418dc613a258/diff :/var/lib/docker/overlay2/80824eead4dd18b2edee01ab40b6cb673e0a4bbfa8747125ebed3e027c469987/diff :/var/lib/docker/overlay2/2dd2ebfe1b5296a1a37c9d6210b8c0be76a2067f3e22a2cf546530678626e1b9/diff :/var/lib/docker/overlay2/6acab0ed5cc40adccaee4250d4ae4623670775107dd49717dd7d7e8b8c2d674a/diff :/var/lib/docker/overlay2/3ff4ece40f02dbbe62d152c7460d4fc55160fa65e191f76793272975d4140b15/diff :/var/lib/docker/overlay2/f0e285d3c96d7227bef68f720f53b5182a4d50255b28fc4310655597ce5a240a/diff :/var/lib/docker/overlay2/54d85ae0666e07b611940b00925ace499ecb353dbdeb499d77e28f2e08af0286/diff", "MergedDir": "/var/lib/docker/overlay2/3101748efbd2384d1670bc831c7b7371acdb9881092c62fd7d5df58d03d05909/merged", "UpperDir": "/var/lib/docker/overlay2/3101748efbd2384d1670bc831c7b7371acdb9881092c62fd7d5df58d03d05909/diff", "WorkDir": "/var/lib/docker/overlay2/3101748efbd2384d1670bc831c7b7371acdb9881092c62fd7d5df58d03d05909/work" }Polecenie to wyciąga ścieżkę GraphDriver. Data z informacji o obrazie/kontenerze, która przechowuje dane o wykorzystywanych warstwach. Zajrzyjmy do środka warstwy z LowerDir i zobaczmy, co jest w środku.

Jak widać warstwa przechowuje po prostu pliki. Patrząc po zawartości zakładam, iż jest to pierwsza warstwa obrazu z dystrybucją Linuksa, na której fundamentach zostały wykonane dalsze warstwy. Z ciekawości zajrzyjmy jeszcze do innej warstwy i zobaczmy czym się od siebie różnią

Ponieważ warstwy przechowują tylko zmiany wykonane przez operacje na tej warstwie, w tym katalogu jest o wiele mniej plików niż w poprzednim, widocznie operacja wykonywana w tej warstwie nie była duża.
Teraz już powinieneś zauważyć, iż warstwy przypominają coś, co każdy programista powinien znać, a przynajmniej kojarzyć :) Mianowicie system kontroli wersji git a dokładniej git commits, oczywiście doker i git to zupełnie inne narzędzia do zupełnie innych zastosowań, ale patrząc na warstwy w dokerze i komity w gicie można zauważyć sporo podobieństw, upraszczając:
- przechowywanie tylko nowych danych lub tych, które się zmieniły
- przyrostowość coś co zostało zakomitowane zostaje w histori choćby jak to usuniemy następnym komitem. Tak samo w warstwach coś, co zostało zrobione w jednej warstwie, nie może być usunięte fizycznie z tej warstwy.
- repozytorium gita rośnie z każdym komitem, doker image rośnie z każdą warstwą choćby jeżeli nowa warstwa "usuwa" połowę plików z poprzedniej wartwy
Tworzymy nowe warstwy
Wiemy już, ze docker image składa się z warstw, mówiłem również, iż istniejące warstwy są tylko do odczytu 🔒, tak więc jak to się dzieje, iż możemy stworzyć swój obraz na fundamentach istniejącego obrazu i dodać tam nowe rzeczy ?
Warstwa R/W kontenera
Więc jak to się dzieje, iż mamy jeden obraz dokerowy z warstwami tylko do odczytu🔒 a możemy stworzyć za jego pomocą wiele odizolowanych od siebie kontenerów, które nie wpływają na inne?
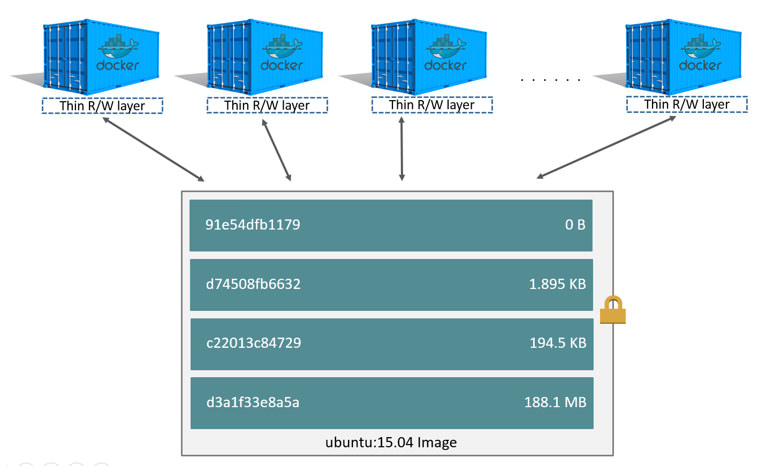 źródło: https://docs.docker.com/storage/storagedriver/
źródło: https://docs.docker.com/storage/storagedriver/Otóż kiedy tworzymy kontener, wraz z nim tworzymy jego własną warstwę, na której możemy tworzyć/usuwać i modyfikować co chcemy. Jedynym ograniczeniem jest Copy-on-write oznacza to, iż jeżeli modyfikujemy coś na plikach z innych warstw, każdy zmieniony plik zostaje przekopiowany do warstwy, w której się znajdujemy i dopiero wtedy wykonywane zostają modyfikacje. Co ważne pliki z oryginalnego obrazu nie są zmieniane, dlatego każdy kontener ma ten sam stan inicjalny oraz modyfikacja jednego kontenera nie sprawia, iż magicznie nowe pliki pojawiają się w innym kontenerze.
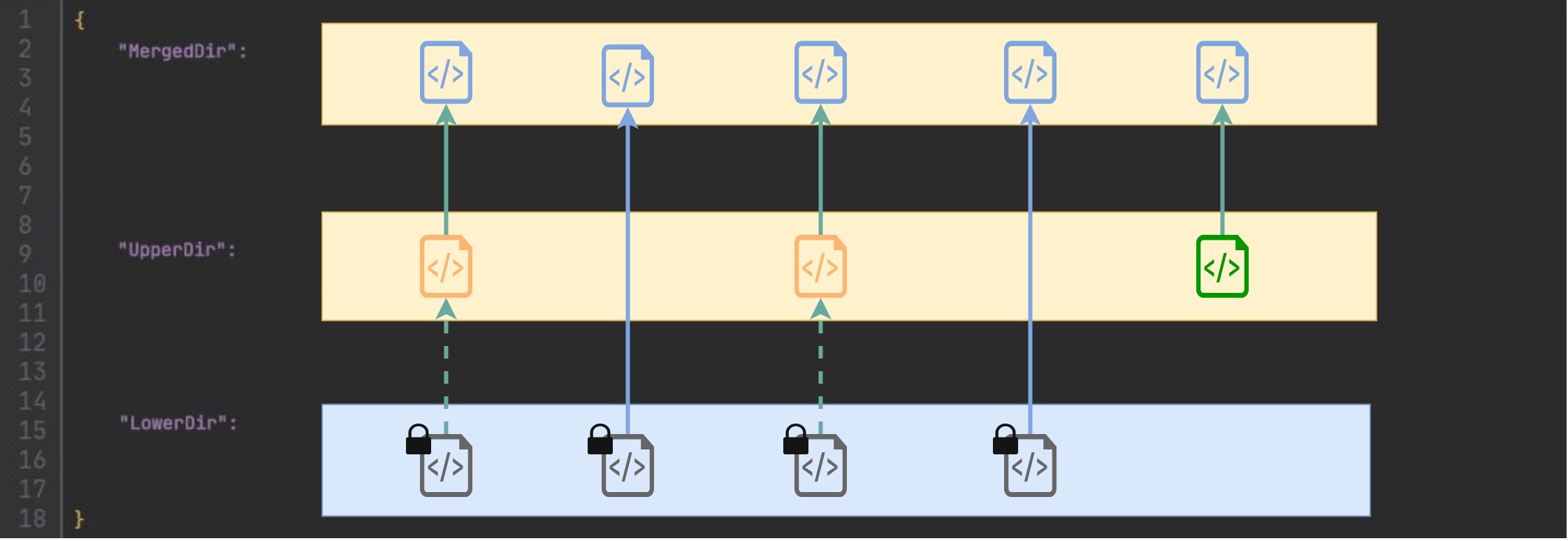
Kontenery ze sterownikiem overlay2 korzystają z systemu plików overlayFS. Dzieli on system plików kontenera na warstwy:
- MergedDir - Warstwa unifikująca wszystkie modyfikacje, tę warstwę widzimy po wejściu do kontenera
- UpperDir - Warstwa do modyfikacji plików przez kontener (własna warstwa kontenera ) jeżeli kontener próbuje zmodyfikować pliki obrazu, to są one kopiowane (copy-on-write przerywana strzałka) i dopiero później na kopii pliku zachodzi zmiana. Nowe pliki również się tu znajdują. Wielkość tej warstwy możemy sprawdzić wykonując polecenie docker ps -as
- LowerDir - Warstwa obrazu pliki tylko do odczytu, nigdy nie są modyfikowane dlatego możemy wykorzystywać je wielokrotnie do innych kontenerów
Tworzenie obrazu z kontenera
Jednym ze sposobów stworzenia obrazu dokerowego jest wykorzystanie kontenera, wprowadzenie w nim zmian i zakomitowanie jego warstwy. Dla przykładu Uruchommy kontener z serwerem nginx, skopiujmy do niego plik index.html zawierający wpis CupOfCode.
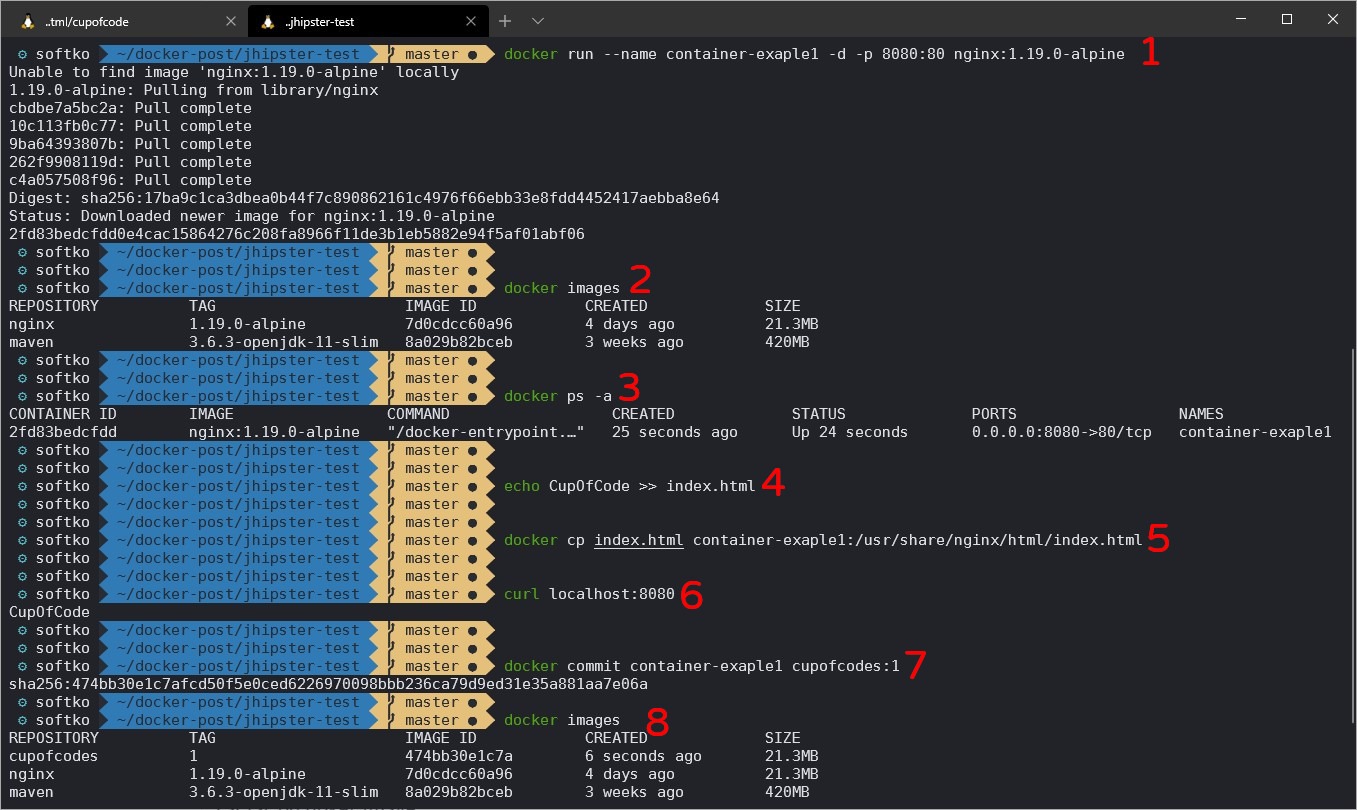 obraz z kontenera
obraz z kontenera- uruchamiamy kontener z nginxem (nie posiadam go lokalnie, więc musi zostać ściągnięty z DokerHub) i mapujemy wewnętrzny port kontenera 80 na port hosta 8080
- Lista aktualnie posiadanych obrazów
- Lista kontenerów (-a pokazuje również kontenery nieaktywne)
- Stworzenie pliku HTML z CupOfCode w środku
- Skopiowanie index.html do kontenera
- Sprawdzamy, czy nginx faktycznie serwuje nowy index
- Tworzymy nowy obraz z warstwą kontenera, na której pracowaliśmy
- W liście posiadanych obrazów znajduje się nasz nowy obraz
Sprawdźmy, czym różnią się obraz Nginx i nowo stworzony obraz cupofcodes. Poniższe polecenia zwracają całą historię obrazu.
docker history cupofcodes:1 docker history nginx:1.19.0-alpinePod spodem zrobiłem diff wyżej wymienionych poleceń. Podświetlona linijka to warstwa zakomitowana gdy stworzyliśmy obraz.
IMAGE CREATED CREATED BY SIZE 474bb30e1c7a About an hour ago nginx -g daemon off; 1.13kB 7d0cdcc60a96 4 days ago /bin/sh -c #(nop) CMD ["nginx" "-g" "daemon… 0B <missing> 4 days ago /bin/sh -c #(nop) STOPSIGNAL SIGTERM 0B <missing> 4 days ago /bin/sh -c #(nop) EXPOSE 80 0B <missing> 4 days ago /bin/sh -c #(nop) ENTRYPOINT ["/docker-entr… 0B <missing> 4 days ago /bin/sh -c #(nop) COPY file:cc7d4f1d03426ebd… 1.04kB <missing> 4 days ago /bin/sh -c #(nop) COPY file:b96f664d94ca7bbe… 1.96kB <missing> 4 days ago /bin/sh -c #(nop) COPY file:d68fadb480cbc781… 1.09kB <missing> 4 days ago /bin/sh -c set -x && addgroup -g 101 -S … 15.6MB <missing> 4 days ago /bin/sh -c #(nop) ENV PKG_RELEASE=1 0B <missing> 4 days ago /bin/sh -c #(nop) ENV NJS_VERSION=0.4.1 0B <missing> 4 days ago /bin/sh -c #(nop) ENV NGINX_VERSION=1.19.0 0B <missing> 6 weeks ago /bin/sh -c #(nop) LABEL maintainer=NGINX Do… 0B <missing> 6 weeks ago /bin/sh -c #(nop) CMD ["/bin/sh"] 0B <missing> 6 weeks ago /bin/sh -c #(nop) ADD file:b91adb67b670d3a6f… 5.61MBOdszukałem folder odpowiedzialny za nową warstwę dzięki polecenia:
docker inspect --format='{{.GraphDriver.Data.UpperDir}}' 474bb30e1c7a
Po wejściu do warstwy widzimy, iż znajduje się tam pliki index.html z wpisem CupOfCode.

⚡Ważne⚡
Dzięki znajomości warstw w łatwy sposób możemy wejść do warstwy merged i przeglądać/kopiować potrzebne pliki. Ważne, aby nie modyfikować tych plików, ponieważ może to wpłynąć negatywnie na działanie kontenera.
Warstwy w Dockerfile
CDN.. w następnej części
Podsumowanie Cz1
W tej części pokazałem, jak duży wpływ na obraz ma znajomość mechanizmu warstw. To, iż warstwy możemy wykorzystać na naszą korzyść. Np. ustawiając je w odpowiedniej kolejności, w naszym przypadku plik pom.xml nie zmienia się za często więc logiczne, iż dobrym pomysłem byłoby umieszczenie go w niższej warstwie niż warstwa z kodem aplikacji, po to, aby gdy zmieni się tylko kod aplikacji docker przebudował tylko warstwę z kodem i warstwy następne, dzięki temu zeszliśmy z czasu 9:16 na 1:38. Jest to bardzo duża oszczędność, jednak obraz dokerowy przez cały czas jest opasły i nic nie udało się z tym zrobić. Jak zmniejszyć obraz dokerowy drastycznie i zachować pryzy tym krótki czas budowania dowiesz się w następnej części poświęconej Multi-stage oraz Buildkit.
Jeśli z tego artykułu miałbyś zapamiętać tylko 2 rzeczy to były by to:
- Docker to nie Wirtualna maszyna
- Obraz opiera się na systemie warstw, które możemy przeglądać