Cotygodniowa dawka linków, czyli archiwum newslettera Dane i Analizy
Dzisiejszy numer newslettera przynosi zwyczajowy mix technologii i trendów, które kształtują obecny krajobraz danych i AI. Zaczynamy od zaskakującego zwrotu w podejściu do sztucznej inteligencji: coraz więcej firm odwraca się od kosztownych wdrożeń AI, stawiając ponownie na kompetencje ludzkie. To doskonały moment na refleksję nad tym, gdzie AI rzeczywiście przynosi wartość.
W tym numerze znajdziesz praktyczne rozwiązania, które możesz wdrożyć już dziś. Dowiesz się, jak zespół obniżył koszty bazy danych z 10 tysięcy do 500 dolarów miesięcznie, poznasz siedem trików przyspieszających walidację Pydantic dwukrotnie, a także odkryjesz ukryte możliwości context managerów w Pythonie, które wykraczają daleko poza klasyczne "with open()".
Dla miłośników analizy danych przygotowaliśmy interesujące spojrzenie na wykorzystanie danych w skautingu piłkarskim na przykładzie Legii Warszawa oraz techniki tworzenia bardziej insightowych wykresów rozrzutu. Nie zabrakło również konkretnych rozwiązań architektonicznych - od auto-skalowania FastAPI w Kubernetes po budowę pipeline’ów danych w architekturze lakehouse.
Czy wiedziałeś, iż można pracować z notebookami Jupyter bezpośrednio w terminalu? A może interesuje Cię wykrywanie anomalii w logach systemowych z użyciem AI? Wszystko to i więcej znajdziesz w dzisiejszym numerze.
Zapraszam do lektury - każda sekcja kryje praktyczne rozwiązania, które mogą odmienić Twoją codzienną pracę z danymi!
ai_ml
Firmy coraz częściej odwracają się od AI
Rosnąca krytyka skuteczności i kosztów wdrażania sztucznej inteligencji skłania coraz więcej firm do rewizji strategii, stawiając ponownie na kompetencje ludzkie w kluczowych obszarach biznesu. Analiza pokazuje, iż choć AI przez cały czas jest postrzegane jako ważne narzędzie, implementacja okazuje się droższa i bardziej skomplikowana niż przewidywano. Wyzwania związane z kosztami, jakością danych oraz ryzykiem błędów w tej chwili przesłaniają entuzjazm wobec automatyzacji, co może wpłynąć na przyszłe inwestycje w technologię.
airflow
Where does your task run in Apache Airflow?
Szczegółowe wyjaśnienie kluczowych aspektów działania Apache Airflow w kontekście przepływu zadań - od planowania (scheduling) po rzeczywiste wykonanie (execution). Autor rozkłada mechanizm działania Airflow na części, pokazując gdzie konkretnie i w jakim kontekście uruchamiane są zadania w DAG-ach, jak działa Scheduler, Worker i Queue oraz jakie znaczenie mają wybrane strategie uruchamiania (LocalExecutor vs. CeleryExecutor).
analiza_danych_projekty
6 OpenSearch Aggregations for Better-Than-SQL BI
Sześć typów agregacji w OpenSearch, które pozwalają na tworzenie zaawansowanych zapytań analitycznych wykraczających poza możliwości tradycyjnego SQL. Autor wyjaśnia, w jaki sposób każda z agregacji może wspierać bardziej elastyczne i efektywne przetwarzanie danych biznesowych oraz jak łączyć agregacje wewnątrz zapytań, by uzyskać wyniki dopasowane do potrzeb systemów BI, dashboardów czy automatycznych raportów.
Detecting Anomalies in Real-Time Logs Using AI
Praktyczne podejście do wykrywania anomalii w logach systemowych w czasie rzeczywistym z wykorzystaniem sztucznej inteligencji. Autor opisuje kompletny pipeline: od zbierania i parsowania surowych logów, przez ekstrakcję cech i budowę modelu detekcji anomalii z użyciem AutoEncoderów w TensorFlow, po końcową integrację z systemem alertowania w Prometheusie i Grafanie.
architektura
Top 10 Mistakes Developers Make When Building Microservices (and How to Avoid Them)
Dziesięć najczęstszych błędów popełnianych przez programistów przy projektowaniu mikroserwisów wraz z konkretnymi sposobami ich unikania. Artykuł omawia nadmierne uzależnienie od komunikacji synchronicznej, niezrozumienie granic kontekstu, ignorowanie zagadnień związanych z monitoringiem i testowaniem oraz błędną konfigurację zależności między serwisami.
bazy_danych
How We Cut Database Costs from 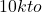 500/Month
500/Month
Proces radykalnej optymalizacji kosztów baz danych, w którym zespołowi udało się obniżyć miesięczne wydatki z 10 tysięcy do 500 dolarów przy zachowaniu wydajności i niezawodności systemu. najważniejsze kroki obejmowały zmianę podejścia do modelowania danych - przejście z bazy dokumentowej MongoDB na strukturę opartą na PostgreSQL, refaktoryzację zapytań, usunięcie zbędnych indeksów i ograniczenie nieefektywnych operacji. Całość poparta konkretnymi przykładami technicznymi oraz analizą kosztów.
ciekawostki
Data vs. Reality: How a Change in Style Affects Scouting at Legia Warsaw
W zeszłym tygodniu artykuł o Wiśle Kraków budził spore zainteresowanie. Dzisiaj analiza wykorzystania danych w skautingu piłkarskim na przykładzie Legii Warszawa, pokazująca jak zmiana stylu gry drużyny wpływa na skuteczność modeli predykcyjnych przy ocenie zawodników. Autor demonstruje, iż ocena gracza oparta na jego statystykach w jednym systemie taktycznym może być myląca, jeżeli nowy zespół operuje w zupełnie inny sposób. Zastosowanie danych kontekstowych - tempo ataku, pressing, intensywność gry w poszczególnych strefach boiska - pozwala lepiej przewidzieć, czy dany piłkarz odnajdzie się w nowym środowisku.
data_engineering
Building Fully-Automated Data Pipeline on Lakehouse Architecture
Szczegółowy opis procesu budowy w pełni zautomatyzowanego pipeline’u danych w oparciu o architekturę lakehouse, łączącą zalety data lake i data warehouse. Autor przedstawia konkretne komponenty rozwiązania: ingestion danych z użyciem Autoloader (Databricks), transformacje oparte na notebookach SQL oraz zarządzanie jakością danych z wykorzystaniem systemu delta tables i walidacji schematów. Omawia również harmonogramowanie zadań przy użyciu Databricks Workflows i integrację z dbt.
The Best GitHub Repos for Data Engineers in 2025
Zestawienie najbardziej wartościowych repozytoriów GitHub istotnych dla inżynierów danych na 2025 rok. Projekty pogrupowane tematycznie - od pipeline’ów danych i orkiestracji (Airflow, Prefect), poprzez budowę hurtowni danych i Lakehouse’ów (dbt, DuckDB, Spark), aż po monitorowanie, testowanie i sprawdzanie jakości danych (Great Expectations, Datafold).
devops
From Single Instance to 100 Pods: Auto-Scaling FastAPI in Kubernetes
Praktyczny przewodnik po budowie skalowalnej aplikacji FastAPI działającej w środowisku Kubernetes z wykorzystaniem auto-skalowania do obsługi dużego ruchu - choćby do 100 replik. Krok po kroku omówiono sposób pakowania aplikacji w Dockerze, konfigurowania zasobów w YAML (Deployment, Service, HPA), definiowania metryk poziomu CPU oraz integracji z Prometheusem i Metrics Serverem.
llm_&_chatgpt
Building a Data Analyst Agent with Streamlit and Pydantic-AI
Autor przedstawia, jak zbudować prostego agenta wspierającego analitykę danych, który samodzielnie analizuje dane z plików CSV i odpowiada na pytania w języku naturalnym. Kluczową rolę odgrywają struktury Pydantic do definiowania typów danych wejściowych/wyjściowych oraz mechanizm pamięci konwersacyjnej pozwalający agentowi śledzić kontekst zadanych pytań.
Generative AI as Seniority-Biased Technological Change
Badanie naukowe analizujące wpływ narzędzi opartych na dużych modelach językowych na jakość systemu tworzonego przez programistów. W oparciu o eksperyment naukowcy wykazują, iż korzystanie z LLM może zwiększyć produktywność, jednak często obniża jakość wytwarzanego kodu - zarówno pod względem poprawności, jak i bezpieczeństwa. Użytkownicy mają tendencję do przeceniania jakości kodu generowanego przez modele językowe, zwłaszcza gdy towarzyszy im pewny styl wypowiedzi.
powerbi
DAX Solutions for Outlier Detection in Power BI
Praktyczne podejścia do wykrywania wartości odstających w Power BI z wykorzystaniem języka DAX. Tekst omawia trzy techniki: klasyczne odchylenie standardowe, interkwartylowy rozstęp (IQR) oraz analizę odchyleń od średniej ruchomej, pokazując ich zastosowanie w kontekście modelu danych i wizualizacji. Każda metoda zawiera szczegółowe formuły DAX oraz przykłady implementacji.
python
Pandas GroupBy Optimizations Nobody Uses
Optymalizacja operacji grupowania danych w Pandas oferuje znaczne ulepszenia wydajnościowe, jednak wiele z nich bywa pomijanych w praktyce. Artykuł wyjaśnia, jak unikać kosztownych wąskich gardeł przez lepsze wykorzystanie funkcji groupby, zwłaszcza przy pracy na dużych zbiorach danych. Przedstawia konkretne techniki: użycie agregacji wielofunkcyjnych, przekształceń z transform oraz wskazówki dotyczące zarządzania pamięcią i porządkowania danych przed grupowaniem.
Pydantic v2 at Scale: 7 Tricks for 2× Faster Validation
Siedem praktycznych technik optymalizacji wydajności walidacji danych z użyciem Pydantic v2 w aplikacjach działających na dużą skalę. Omawiane ulepszenia obejmują wykorzystanie funkcji model_construct do tworzenia modeli bez walidacji, prekompilację modeli dzięki model_rebuild, użycie customowych pól z FieldSerializer oraz unikanie nadmiarowej walidacji dzięki model_validated.
Erys - terminal Interface for Jupyter Notebooks
Narzędzie do otwierania, tworzenia, edycji, uruchamiania, interakcji i zapisywania notatników Jupyter w terminalu. Erys oferuje alternatywę dla tych, którzy preferują pracę w środowisku tekstowym, zachowując przy tym pełną funkcjonalność Jupyter Notebooks.
Working with Async Databases in Python Using databases and PostgreSQL
Siedem technik zwiększających bezpieczeństwo aplikacji tworzonych w FastAPI, ze szczególnym naciskiem na rozwiązania gotowe do wdrożenia w środowisku produkcyjnym. Autor omawia kontrolę dostępu dzięki Depends i OAuth2, ochronę wrażliwych endpointów przy użyciu JWT, ograniczanie liczby zapytań (rate limiting), bezpieczne zarządzanie danymi w plikach cookie oraz unikanie wycieków informacji przez poprawną konfigurację odpowiedzi HTTP.
7 FastAPI Security Moves That Ship
Siedem technik zwiększających bezpieczeństwo aplikacji tworzonych w FastAPI, ze szczególnym naciskiem na rozwiązania, które można gwałtownie wdrożyć w produkcyjnym środowisku. Autor omawia m.in. kontrolę dostępu dzięki Depends i OAuth2, ochronę wrażliwych endpointów przy użyciu JWT, ograniczanie liczby zapytań (rate limiting), bezpieczne zarządzanie danymi w plikach cookie oraz unikanie wycieków informacji przez poprawną konfigurację odpowiedzi HTTP.
Python Context Managers Beyond with open(): Hidden Superpowers You Should Use
Zarządzanie kontekstem w Pythonie wykracza daleko poza klasyczne użycie with open(). Artykuł pokazuje, jak tworzyć własne context managery zarówno dzięki klas z metodami __enter__ i __exit__, jak i dekoratorów opartych na contextlib. Omawia najważniejsze przypadki użycia: tymczasową zmianę katalogu roboczego, przechwytywanie wyjątków czy pomiar czasu wykonania fragmentu kodu.
wizualizacja_danych
Sweeping Through the Noise: Techniques for More Insightful Scatter Plots
Techniki poprawy czytelności i wartości analitycznej wykresów rozrzutu (scatter plots) w pracy z dużymi i zaszumionymi zbiorami danych. Skupia się na metodach takich jak podpróbkowanie, przezroczystość punktów (alpha), agregacja danych w siatce (grid-based binning), hexbinning, jittering czy wykorzystanie map gęstości, by lepiej ukazać ukryte korelacje i struktury. Zawarte przykłady i wizualizacje pokazują, jak odpowiedni dobór techniki może ujawnić informacje niewidoczne przy standardowym podejściu.