Zaprogramuj Życie
git merge vs git rebase
Pytanie, które stawia sobie wiele osób pracujących z gitem. Zarówno początkujący jak i bardziej doświadczeni programiści nie zawsze „czują” różnicę w git merge vs git rebase. Dlatego dziś przy pomocy moich autorskich grafik postaram się rozwiać wątpliwości raz na zawsze

O co całe to zamieszanie?
Głównym „problemem” jest to, iż zarówno polecenie merge jak i rebase można wykorzystywać do łączenia zmian z różnych gałęzi. Oczywiście rebase w trybie interactive daje nam szerszy zakres możliwości ale myślę, iż to materiał na osobny wpis. Choć oba polecenia dają podobny wynik (przeniesienie kodu z gałęzi A do gałęzi B), to robią to zupełnie inaczej. Jeden bardziej bezpieczny, a drugi hmm… mniej. Który jest który? Przyjrzyjmy się im bliżej!
Jak działa git merge?
W poleceniu merge możemy wyszczególnić dwa tryby działania: fast-forward oraz 3-way merge (no-fast-forward). Uruchomienie jednego bądź drugiego algorytmu jest zależne od stanu w jakim znajdują się „mergowane” gałęzie lub w wyniku dodatkowego parametru, który podamy przy poleceniu (git merge —no-ff).
Fast-forward
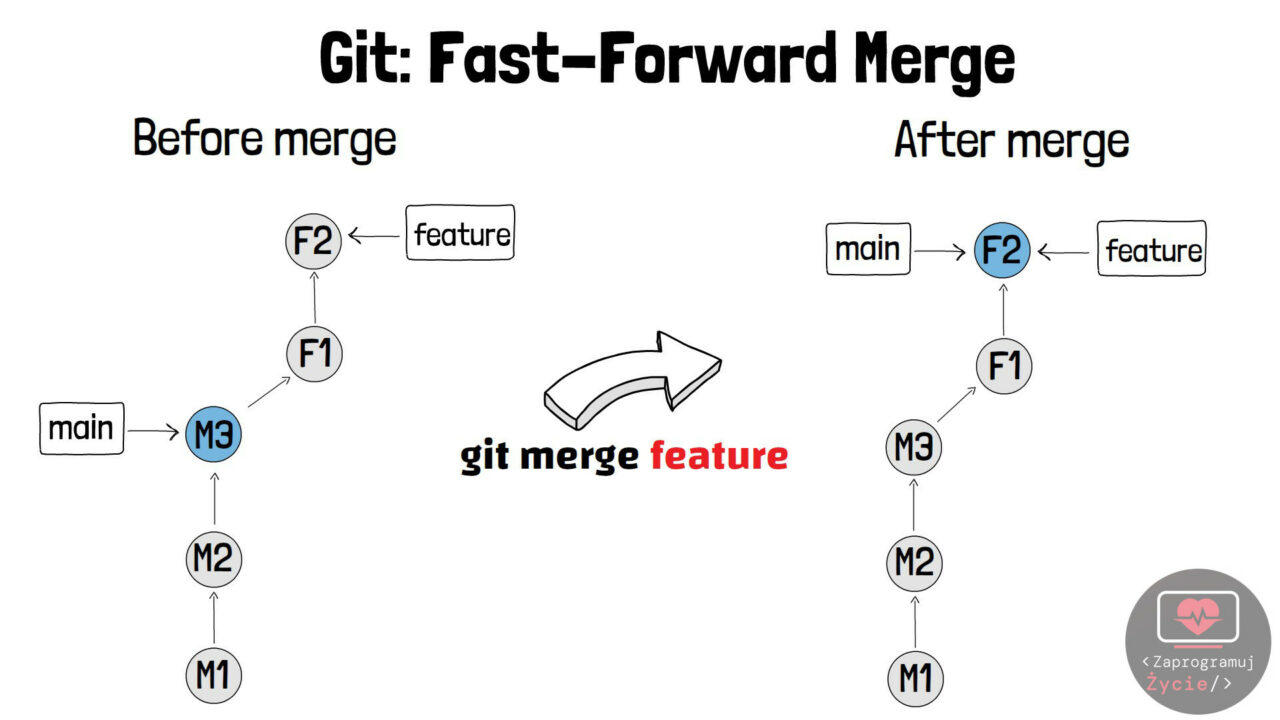
Najprzyjemniejsza sytuacja podczas przenoszenia zmian pomiędzy branchami. Występuje w momencie gdy kod gałęzi bazowej – main, która była źródłem dla nowej gałęzi – feature, nie zmienił się. Podsumowując, kod z gałęzi main przez cały czas znajduje się w feature, przez co wskaźnik HEAD może „przesunąć się” do najnowszego commita. W rezultacie uzyskujemy liniową historię projektu, a cała operacja jest „bezbolesna” i nie pozostawia po sobie śladu.
3-ways merge
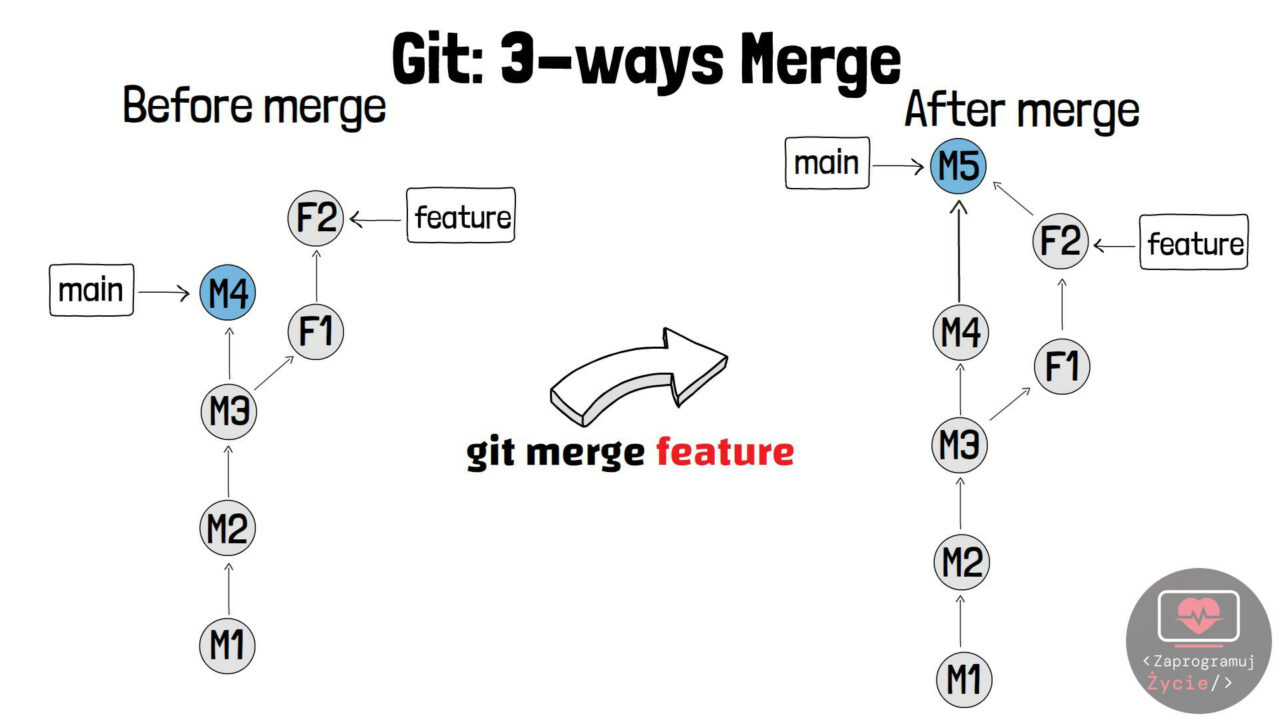
Przypadek bardziej „skomplikowany”, w którym zwykłe przejście wskaźnika HEAD do najnowszego commita nie jest możliwe, gdyż stan bazowej gałęzi main zmienił się od momentu powstania gałęzi feature (commit M4). Git w jakiś sposób musi uzupełnić brakujące informacje, dlatego tworzy tzw. merge commit = commit pomocniczy, w którym łączy zmiany z obu gałęzi (M5 = F1 + F2 + M4).
WAŻNE! o ile na obu gałęziach kod projektu był modyfikowany w tym samym obszarze pliku, mogą pojawić się konflikty, które należy rozwiązać. Dlaczego? Ponieważ git nie wie, która wersja kodu jest aktualna i konieczne jest manualne wskazanie zmian nadających się do przeniesienia – z gałęzi main, feature, a może z obu?
Jak działa git rebase?
Dodatkowy commit, który powstaje przy operacji merge nie zawsze jest mile widziany w historii projektu. Są osoby/zespoły, którym zależy aby po połączeniu zmian zachować nieprzerwaną liniowość w historii, która może dawać większe możliwości w zakresie analizy, testów czu debuggowania błędów. W takiej sytuacji bardzo często jako alternatywa dla merge używany jest właśnie rebase. Dzięki niemu kod na gałęzi jest wyrównywany do „wspólnej bazy”, a nowe commity trafiają na samą górę drzewa. Niestety… jest tutaj pewien haczyk, na który trzeba bardzo uważać!
Podstawową zasadą, o której należy pamiętać jest fakt, iż rebase modyfikuje historię projektu. Commity, które są tymczasowo odłączane i finalnie trafiają na górę drzewa otrzymują zupełnie nowe identyfikatory, gdyż zmieniają się ich „rodzice”. o ile gałęzie są „prywatne” – tylko do własnego użytku, nie stanowi to większego problemu. Ale w sytuacji gdy branche są „publiczne” i inni developerzy z nich korzystają, może to wygenerować sporo problemów…
Jak nie korzystać z rebase?
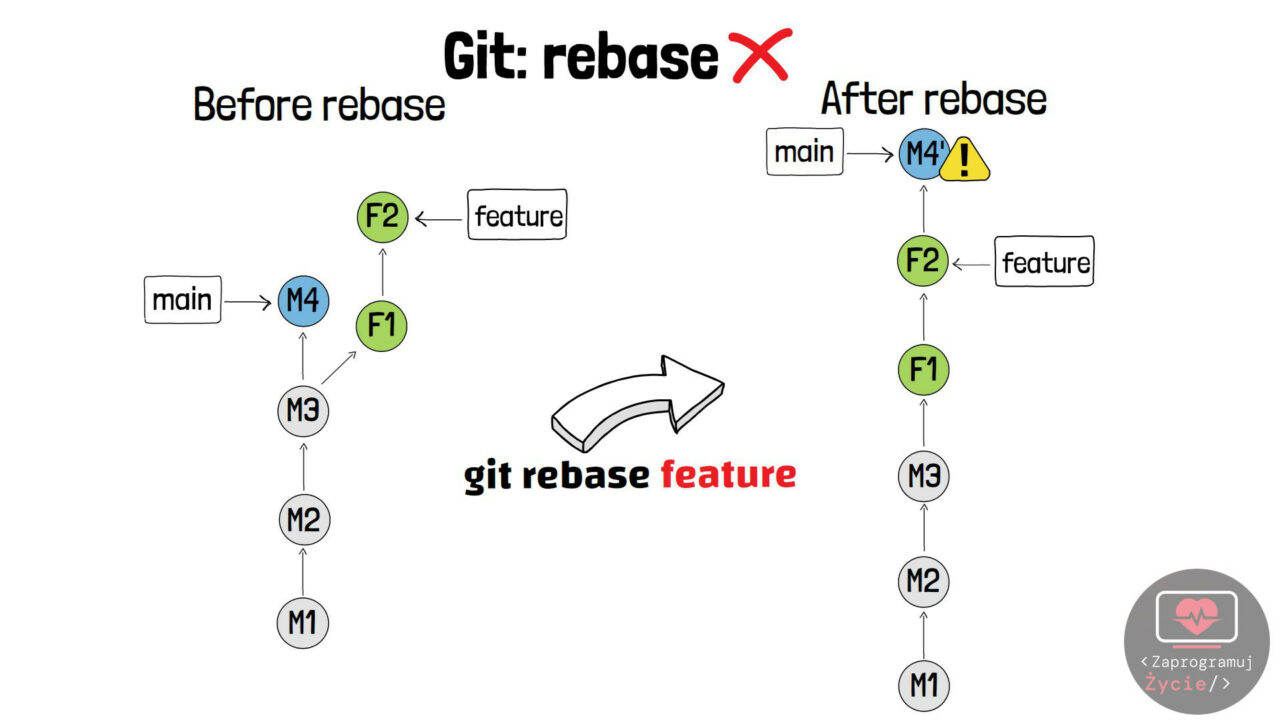
Powyższy przykład obrazuje sytuację, której powinniśmy unikać, tzn. wykonywać rebase na gałęziach publicznych – w tym przypadku main. Na grafice widzimy, iż polecenie sprowadza do „wspólnej bazy” kod z gałęzi main na podstawie feature. Commit M4 zostaje chwilowo odłączony, F1 oraz F2 trafiają do main z tymi samymi ID, a na końcu do historii ponownie zostaje dołączony commit M4. Niestety… tym razem z nowym ID, ponieważ jego rodzicem nie jest już commit M3, tylko F2. o ile ktoś z zespołu bazował na commicie M4 przed wykonaniem polecenia rebase, myślę iż po tej operacji przeżyje mini zawał
Lepsze rozwiązanie
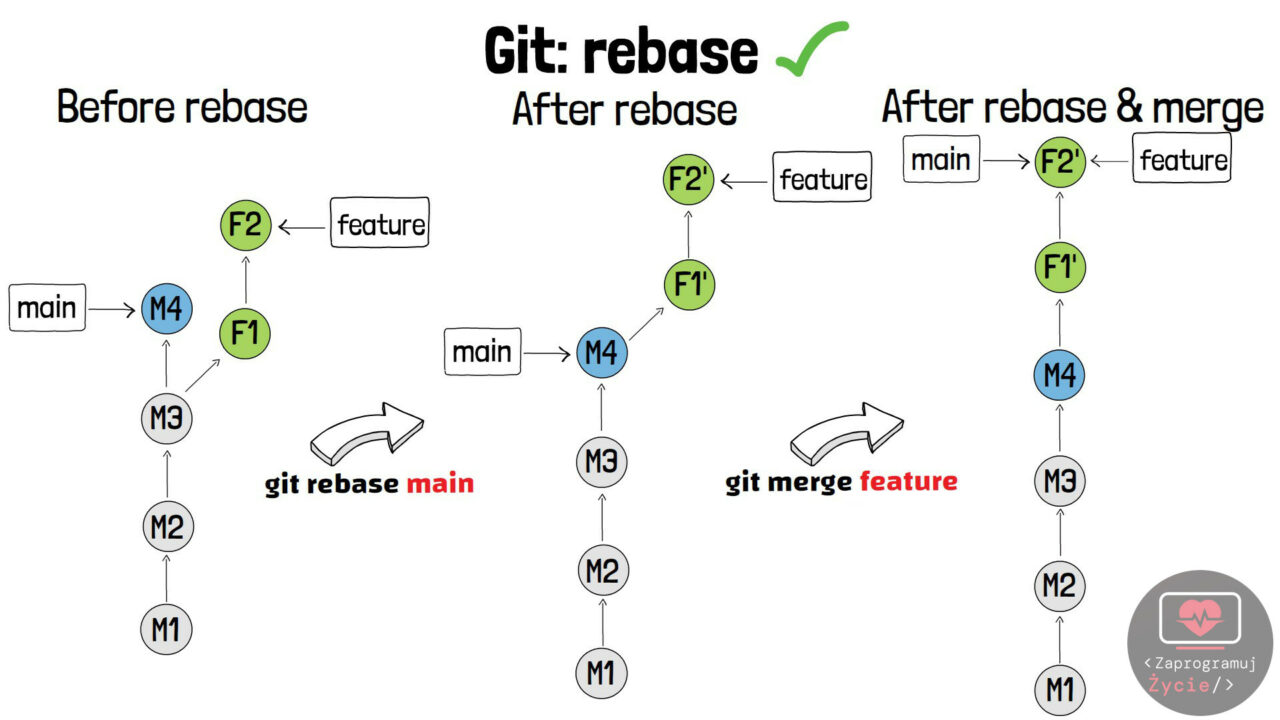
To jak można poradzić sobie z tym problemem? Wykonywać rebase na gałęziach prywatnych! Musimy odwrócić sytuację i to gałąź feature (prywatna) sprowadzić do wspólnej bazy z main. Dzięki temu, publiczne commity nie zmienią swoich ID, a commity z gałęzi feature trafią na górę drzewa z nowymi identyfikatorami.
Jest to bardzo dobra sytuacja! Można w ten sposób przetestować całość przed wysłaniem kodu na publiczną gałąź – zyskaliśmy tym samym dodatkową formę zabezpieczenia i utrzymania stabilności projektu.
Pamiętasz początek tego wpisu? Zerknij jeszcze raz na drzewo „After rebase”, przypomina Ci coś? Bardzo podobna sytuacja była w pierwszej grafice. o ile w gałęzi feature jest aktualny stan gałęzi bazowej (main), po wykonaniu polecenia merge zadziała algorytm fast-forward, który zachowa liniowość w historii projektu i nie pozostawi po sobie śladu w formie dodatkowych commitów.
Słowem końca, jakie są różnice?
- merge nie modyfikuje historii projektu, rebase tak – nadaje zupełnie nowe ID commitom
- merge przesuwa wskaźnik HEAD lub tworzy dodatkowy commit wynikowy, rebase tymczasowo odłącza nadmiarowe commity -> wyrównuje kod do wspólnej bazy -> przywraca odłączone commity
- rebase w trybie interactive posiada szerszy wachlarz możliwości
- nieuważne użycie rebase może wygenerować sporo problemów
- merge jest bardzo dobrym uzupełnieniem polecenia rebase
Więcej informacji wraz z przykładami znajdziesz w poniższym video na moim kanale YT
Daj lajka i czytaj dalej!
Jeżeli chcesz być na bieżąco z artykułami i jesteś interesujący co będzie dalej, daj lajka na moim profilu FB, a przede wszystkim zapisz się do newslettera! Spodobał Ci się artykuł? Z pewnością zaciekawią Cię inne wpisy na blogu lub filmy na kanale YT!
Dzięki za Twój czas, widzimy się niebawem!
git merge vs git rebase
Mateusz Michalski








