Już od dawna nie tworzyłem nowych wpisów z serii „Internetowa inwigilacja”. Aż się za nią nieco stęskniłem :smile:
Dlatego teraz, gdy ulewa pokrzyżowała mi weekendowe plany, postanowiłem trochę nadgonić.
W tym wpisie skupimy się na metodach, które nazywam umownie „śledzeniem przez obrazki”. Polegają na proponowaniu naszej przeglądarce kilku różnych wariantów obrazków albo na umieszczaniu ich w taktycznych miejscach.
Na podstawie tego, jakie obrazki ostatecznie pobierze przeglądarka, można wywnioskować o nas parę rzeczy.
Co istotne, te metody wykorzystują najprostsze, standardowe elementy. Pozwalają wyciągnąć informacje choćby od tej garstki osób, która szczególnie dba o prywatność i wyłącza interaktywne funkcje (kod JavaScript).
Zapraszam do lektury! Będzie przystępnie, choćby dla osób nieznających poprzednich wpisów z serii.

Spis treści
- Kto tym razem nas śledzi?
- Etapy pobierania strony
- Obrazki jako narzędzie śledzenia
- Obrazki leniwie ładowane
- Element <picture>
- Style CSS
- Jak się chronić
Kto tym razem nas śledzi?
Zacznijmy od tego, iż w tej serii pokazywałem dotąd trzy główne rodzaje przeciwników, mogących zbierać o nas informacje:
- Właściciele stronek, które odwiedzamy;
-
Organizacje, których drobne elementy „goszczą” na odwiedzanych przez nas stronach.
To autorzy trackerów takich jak Google Analytics, Facebook Pixel oraz innych małych elementów, które można umieścić na swojej stronie.
-
Właściciele infrastruktury internetowej.
To na przykład firmy telekomunikacyjne dające nam łączność z siecią, właściciele publicznych hotspotów itp.
Tym razem głównym zagrożeniem jest dla nas przypadek pierwszy – właściciele bezpośrednio odwiedzanych stron.
Gdyby strona nie miała włączonego szyfrowania (HTTPS-a), to przeciwnik numer 3 również mógłby zdobyć te same informacje co właściciel strony.
Ale bardzo możliwe, iż nie umiałby ich zinterpretować. Nie wiedziałby na przykład, iż fakt pobrania przez nas obrazka img157.jpg ma szczególne znaczenie. Dlatego zignorujemy ten przypadek.
Etapy pobierania strony
Przypomnijmy sobie teraz, etap po etapie, kulisy typowych interakcji podczas przeglądania stron internetowych. Po jednej stronie jesteśmy my i nasza przeglądarka. Po drugiej cudzy komputer (serwer), przechowujący interesującą nas stronę.
Etap pierwszy – prośba o stronkę
Najpierw nasza przeglądarka wysyła cudzemu serwerowi prośbę o stronę.
We współczesnym internecie, gdzie powszechna jest szyfrowana komunikacja, dochodzi jeszcze ustalanie szyfrów. Ale to bez znaczenia dla wpisu, więc to pominę.
Ta prośba zawiera parę podstawowych informacji o nas. Jak swego rodzaju wizytówka. Jest tam nasz adres IP, ustawiony język, rodzaj i wersja przeglądarki, może pliki cookies otrzymane wcześniej od odwiedzanej strony…
Nasza prośba dociera do serwera. O ile nie postanowi nas dyskryminować (na przykład na podstawie tego, iż mamy europejski adres IP), to otrzymamy stronkę, o którą prosiliśmy. A nasze dane tak czy siak może sobie zapisać.
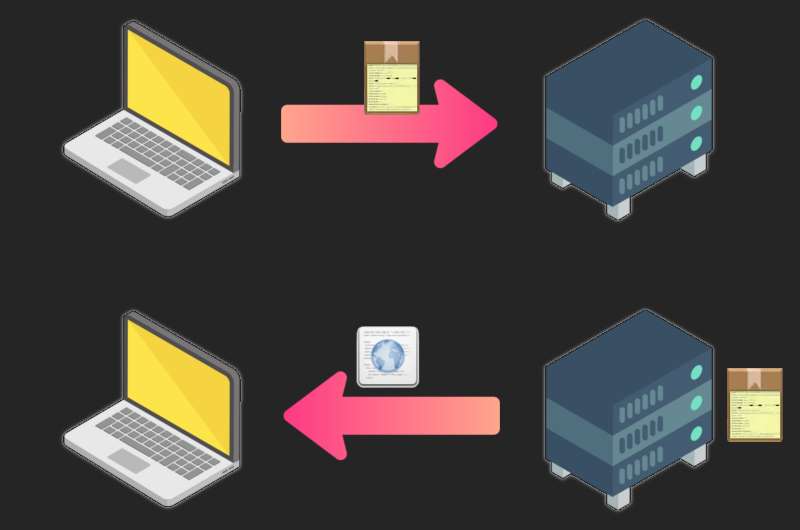
Etap drugi – pobranie brakujących elementów
Nasza przeglądarka zapoznaje się z otrzymanym plikiem. Często jest raczej niewielki, to sam „szkielet” strony. Zawiera tylko podstawową treść i odniesienia do innych elementów. Takich jak:
- obrazki,
- niestandardowe czcionki,
- arkusze styli (nadające stronie wygląd),
- elementy interaktywne w języku JavaScript,
- …i wiele innych możliwych rzeczy.
W źródle strony wygląda to na przykład tak:
Element obrazkowy w kodzie HTML. Mówi przeglądarce, iż w danym miejscu powinien być obrazek kot1.jpg. Do pobrania z tego samego źródła, co zdradza ukośnik na początku.
Przeglądarka zaczyna wysyłać serwerowi osobne prośby o każdy z takich elementów.
„Wyślesz mi arkusz stylowka.css?„. „I jeszcze obrazek kot.jpg?”. „Aha, i jeszcze kot2.jpg?”.
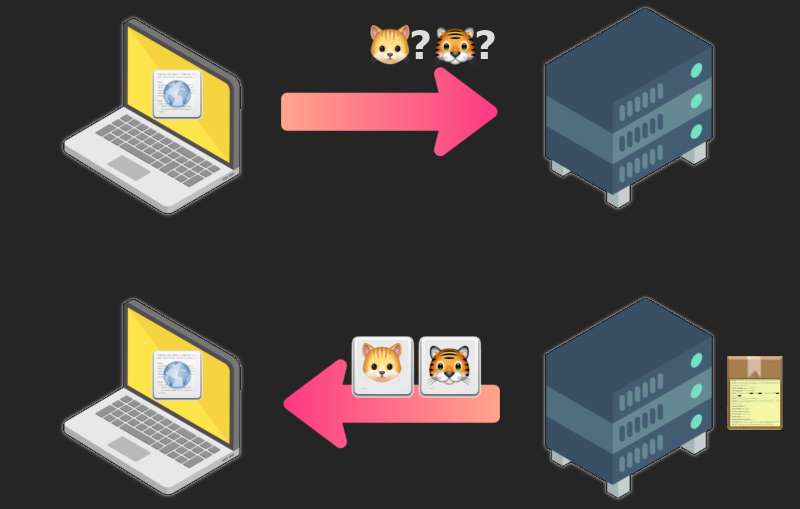
Etap trzeci (opcjonalny) – komunikacja przez JavaScript
Gdybyśmy mieli stronkę złożoną z samego tekstu i obrazków – „stronkę martwą” – to po pobraniu wszystkich jej elementów nic więcej by się nie działo. Ot, czytalibyśmy sobie.
Jeśli na stronie znajduje się interaktywny kod JavaScript, to może on zapytać o więcej, znacznie więcej informacji. Takich jak parametry naszej karty graficznej, karty dźwiękowej, wymiary ekranu, naciśnięte klawisze oraz położenie kursora myszki…
Co więcej, może kontynuować komunikację z serwerem, od którego mamy stronę. I wysyłać mu na bieżąco różne informacje:
„Przesyłam dokładne parametry karty graficznej użytkownika”.
„Użytkownik właśnie przewinął stronę do połowy”.
„Użytkownik nacisnął klawisze Ctrl+P, możliwe iż próbuje wydrukować stronę”.

Brzmi groźnie? JavaScript może mocno naruszać prywatność, dlatego osoby wyczulone go wyłączają – poprzez dodatki do przeglądarki, jak NoScript albo uBlock Origin.
Obrazki jako narzędzie śledzenia
Ale, jak się okazuje, istnieje szereg metod śledzenia dotyczących etapu drugiego, czyli pobierania elementów brakujących.
Pozwalają uzyskać więcej informacji, niż da się odczytać z samej „wizytówki” z kroku pierwszego. Dużo mniej niż JS. Ale za to działają również na te osoby, które JS-a wyłączą.
Nie wiem, czy takie metody mają swoją oficjalną nazwę. Nazywam je umownie „śledzeniem przez obrazki”. Albo „śledzeniem przez decyzje przeglądarki”.
Ich uniwersalna zasada działania jest prosta i opiera się na dwóch fundamentach:
-
Prosząc stronę o obrazki, nasza przeglądarka wysyła swoje podstawowe dane.
Właściwie mógłby tu wystarczyć sam adres IP, reszta to uzupełnienie.
Dzięki temu faktowi właściciel strony może jasno ustalić – osoba, która odwiedziła konkretny wpis i pobrała obrazek 1-mobile.jpg to ta sama osoba, która pobrała chwilę później 14-mobile.jpg. I tak dalej. -
Da się, bez użycia JavaScriptu, nakłonić przeglądarkę do wybrania obrazków zgodnych z jej ustawieniami.
Stronka, zamiast narzucać przeglądarce konkretny obrazek, może jej podsunąć kilka opcji. „Jeśli twój ekran jest duży, pobierz obrazek 1-large. jeżeli mniejszy, pobierz 1-mobile”. A przeglądarka posłucha sugestii.
 Ciekawostka
Ciekawostka
Choć mówimy tu o obrazkach, nie muszą one przedstawiać niczego konkretnego ani zrozumiałego dla użytkowników.
Jeśli jedynym celem obrazka jest sprawienie, żeby przeglądarka o niego poprosiła i zostawiła przy tym dane, to można użyć wariantu minimum. Obrazka o wymiarach 1x1, czyli pojedynczego piksela. A do tego wystylizować go w taki sposób, żeby był niewidzialny.
Stąd zresztą wzięła się nazwa piksel śledzący.
Niektóre metody z tego wpisu (nie wszystkie) działałyby w przypadku różnorodnych elementów, niekoniecznie obrazków. Ale obrazki są najprostszym przykładem, więc to na nich się skupimy. Spójrzmy teraz na różne przykłady nadużyć.
Obrazki leniwie ładowane
Obrazki to elementy stosunkowo ciężkie (u mnie nieraz pojedynczy ma 50-100 kB, mimo iż wszystkie mocno kompresuję; na niektórych stronach mają wielomegabajtowe).
A czasem się przecież zdarza, iż ktoś wejdzie na jakąś stronkę przypadkiem. choćby nie przewinie ekranu w dół, tylko od razu naciśnie Wstecz.
Gdyby na tej stronie było kilkanaście obrazków, to po co je pobierać? Zbędne obciążenie i dla czytelnika (bo np. zużywa dane mobilne), i dla serwera właścicieli.
Z tego względu stworzono dość przydatną funkcję tak zwanego leniwego ładowania obrazków (ang. lazy loading). „Leniwego”, bo przeglądarka pobiera obrazek dopiero wtedy, gdy ten zbliży się do naszego pola widzenia. Nie wcześniej, bo nie ma co się przemęczać.
Obecnie nie potrzeba JavaScriptu, żeby włączyć leniwe ładowanie. Wystarczy dodać prostą instrukcję.
Obrazek numer jeden zacznie się ładować od razu.
Ten pod nim – dopiero po tym, jak się do niego zbliżymy.
Ale pamiętajmy, iż to serwer daje nam obrazki na życzenie. Może być wścibski i przypisywać do nas pobrane rzeczy. Po tym, jak pobierzemy jedną z jego stron, zaczyna nam liczyć powiązane obrazki.
- Nasz adres IP pobrał jeden lub dwa obrazki? Czyli tylko wyświetlił stronę i z niej wyszedł.
Bo jeden obrazek jest zawsze w banerze strony, a drugi u góry, tuż pod nagłówkiem. - Pobrał trzy? Czyli przeczytał jakieś 20% artykułu
(na tej wysokości był kolejny obrazek). - Pobrał cztery? Przeczytał 50% artykułu.
- Pobrał pięć? 90% artykułu.
Co do ostatnich 10% trudno wnioskować, bo więcej obrazków tam nie ma. Ale powyższe informacje wystarczą, żeby ustalić, na ile dany czytelnik się wciągnął.
Osobiście eksperymentowałem z leniwym ładowaniem w paru wpisach. Ale bez obaw, nie w celu śledzenia (i tak nie mam dostępu do serwera ani jego historii) :smile:
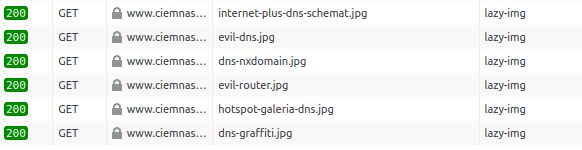
Obrazki leniwie ładowane z mojego wpisu na temat cenzury stron internetowych.
Źródło: narzędzia przeglądarki Firefox, zakładka Sieć.
Osoby wścibskie mogłyby celowo rozmieścić na swojej stronie leniwie ładowane obrazki. Albo choćby dodać je do wysłanego nam maila. I na tej podstawie mierzyć nasz stopień przeczytania tekstu.
Co więcej, serwer z obrazkami pozna również dokładny czas wysłania próśb. W ten sposób jego właściciele zdobędą informację, iż np. jakiś artykuł czytaliśmy równym tempem 15 minut. Albo zatrzymaliśmy się na dłużej gdzieś między trzecim a czwartym obrazkiem i dopiero potem doczytaliśmy.
W ten sposób serwer może też wykrywać anomalie. Poprosiliśmy o stronę i parę plików uzupełniających, ale o ani jeden obrazek? choćby te z samej góry, które każdemu powinny się pobrać?
Możliwe, iż używamy dodatku blokującego multimedia powyżej pewnego rozmiaru. Takiego jak uBlock Origin. Stronka doda informację o tym do naszej kartoteki.
Scenariusz przykładowy
Wyobraźmy sobie, w jakiej sytuacji ktoś może użyć tej metody. Przedstawiam dwa warianty:
-
Stalkerski.
Znajoma osoba ma własną stronę internetową i dostęp do jej serwera. Podsyła nam link do konkretnego artykułu na stronie. I chce kontrolować, czy go przeczytamy.
-
Korporacyjny.
Bardzo podobny, tyle iż informacje zbierane są od wielu osób. Zbieracz to na przykład komercyjny blog dostępny online. Mamy u nich konto czytelnika, wysyłają nam newslettery na maila.
Przede wszystkim strona śledząca musi ustalić, iż jakiś odwiedzający ją czytelnik X to my. Ale to łatwe. Zwłaszcza jeżeli jesteśmy zalogowani na konto.
Nawet jeżeli nie mamy konta, to mogą nam wysłać nieco inny link niż innym osobom (chociażby przez dodanie do niego parametru, np. ?a=123; dowolnego, byle nie miała takiego żadna inna osoba).
W każdym razie wchodzimy na stronkę, a ta wie, iż to my. Czytamy treść. A po stronie serwera gromadzą się informacje:
„Użytkownik nr 123 pobrał obrazek na wysokości 20% treści”.
„Użytkownik nr 123 pobrał obrazek na wysokości 50% treści”.
Skupmy się na przykładzie stalkerskim. Mówimy wścibskiej osobie, iż przeczytaliśmy wszystko. Ale ta na swoim serwerze widzi, iż nasza przeglądarka pobrała tylko elementy z samej góry… Czyli raczej wciskamy kit :wink:
Przewinęliśmy gwałtownie na sam dół i opuściliśmy stronę? Też się dowie. Po tym, iż prośby o obrazki zostały wysłane w krótkich odstępach czasu (ale we adekwatnej kolejności).
Stalker(-ka) nie dowie się natomiast, czy po wstępnym przewinięciu tekstu wróciliśmy i go czytaliśmy na spokojnie. Bo obrazki już zostały pobrane, więc strona wystrzelała się z możliwości śledzenia tą metodą.
Element <picture>
Element <picture> to część współczesnego formatu HTML. Oficjalna i standaryzowana.
W praktyce: możemy dodać do swojej strony taki element, a każda współczesna przeglądarka już będzie wiedziała, co z nim zrobić. Jak fani na pewnym koncercie rapowym.
A co zrobi konkretnie z tym? Spojrzy na zawartą w nim listę obrazków. Przy każdym z nich znajdą się wytyczne mówiące, jaki obrazek załadować w zależności od cech przeglądarki.
„Jeśli ta przeglądarka wspiera format AVIF, pobierz kot.avif”.
„Jeśli wspiera AVIF, a szerokość okna jest większa niż 1000, pobierz kot-large.avif”.
…I tak dalej. Będzie tam również klasyczny obrazek (<img>), czyli wariant na wszystkie inne przypadki.
To przydatna funkcja, bo rzeczy czytelne na komputerach mogą się prezentować gorzej na telefonach. jeżeli chcemy dać telefoniarzom bardziej „pionowe”, ściśnięte wersje jakichś schematów, to taki element będzie idealny.
Co nie zmienia faktu, iż daje możliwość rozdzielania użytkowników na podgrupy. A to nie sprzyja anonimowości. Dostając informację, iż użytkownik X pobrał taki plik, a nie inny, strona czegoś się o nim dowie.
Korzystając z elementu <picture>, można na przykład:
-
Określić wymiary naszego ekranu.
Tutaj mamy spory potencjał do nadużyć. W normalnych warunkach taką informację dałoby się zdobyć tylko przez JavaScript.
Wścibska strona może dodać wiele opcji. Obrazek 1.jpg, dla okna o szerokości 1000; 2.jpg, dla szerokości 800. A serwer tylko patrzy, który z plików pobierzemy, i na tej podstawie poznaje wymiary naszego ekranu.Ta informacja nie jest może bezcenna. Ale w połączeniu z innymi (język, rodzaj przeglądarki) może pomóc nas potem rozpoznać. choćby gdy zmienimy adres IP.
-
Ustalić, iż jakaś przeglądarka przedstawia się jako inna.
Mamy na przykład nowego Firefoksa, ale w swojej wizytówce przedstawiamy się jako stary Chrome.
Ale nasza przeglądarka poprosiła o obrazek w formacie AVIF. A to coś nowszego, stary Chrome by wybrał inną opcję. Jest anomalia w zachowaniu, a to może budzić podejrzenia. -
Ustalić gęstość pikseli naszego ekranu.
Można podsunąć inne obrazki ludziom z tak zwanymi ekranami High-DPI (HiDPI). zwykle to cecha nieco nowszego sprzętu, więc może pośrednio coś ujawniać o naszej zamożności. Zwłaszcza w połączeniu z wymiarami ekranu – ultraszerokie High-DPI są rzadkie i drogie.
Style CSS
Wyżej mieliśmy przykład podsuwania przeglądarce kilku opcji w najzwyklejszym kodzie HTML. Jeszcze więcej śledzenia można upchnąć w arkuszach styli CSS.
To popularny format, obecny niemal na każdej stronie. Zawiera regułki mówiące, jak powinny wyglądać różne elementy strony. Przykładowo: wszystkie linki powinny być zielone, a nie niebieskie; odstępy między akapitami mają mieć zawsze 3 linijki… I tak dalej.
Pamiętamy fundamenty śledzenia przez obrazki? Po pierwsze, musimy być w stanie kazać przeglądarce pobrać obrazek. CSS jak najbardziej na to pozwala, przez regułkę url:
Po drugie, musimy być w stanie dać przeglądarce kilka opcji, żeby wybrała najbardziej odpowiednią dla siebie.
Też da się zrobić! W plikach CSS możemy umieszczać tak zwane zapytania dotyczące mediów (ang. media queries). Przeglądarka wybierze tylko te reguły, które do niej pasują:
Tutaj przykład użycia zapytania do wyciągnięcia szczegółów na temat użytkownika; obrazek pobierze się wtedy i tylko wtedy, kiedy okno przeglądarki mieści się w określonych wymiarach.
Same obrazki podsuwane przeglądarce mogą być zupełnie identyczne z wyglądu; dla stron śledzących liczy się tylko to, żeby były to różne pliki, o różnych nazwach. A serwer już sobie będzie notował, o co poprosił użytkownik.
W ten sposób można wykryć różne rzeczy dotyczące trybów działania urządzenia. Za listą Mozilli:
- czy mamy włączony systemowy tryb ciemny,
- czy mamy tryb kolorów kontrastowych,
- czy mamy urządzenie bez kursora (np. dotykowe),
- czy używamy ekranu monochromatycznego,
- czy urządzenie wspiera szybkie odświeżanie (np. animacje),
- …i jeszcze więcej.
Pod każdą z opcji typu ON/OFF można podpiąć dwa obrazki – osobny dla włączonej, osobny dla wyłączonej. Gdy możliwości są trzy, to podsuwa się trzy obrazki. I tak dalej. Serwer będzie sobie patrzył, które z nich pobraliśmy. Dowie się trochę na temat urządzenia.
Wyróżnimy się, zwłaszcza jeżeli używamy czegoś niestandardowego.
Nietypowe ustawienie wynikające np. z problemów ze wzrokiem? Stronka łatwo nas rozpozna spośród tłumu. I może jeszcze podsunie reklamy laserowej korekty.
A to nie koniec! Oprócz prostego wykrywania typu ON/OFF można również tworzyć bardziej złożone reguły, pozwalające np. ustalić dokładne wymiary okna. Jak wspomniany wcześniej element <picture>. Śledzące zastosowania CSS-a fajnie opisali na fingerprint.com.
Drukowanie
Co więcej, arkusze CSS mogą zawierać regułę @print. Odnosi się do przypadku, kiedy coś drukujemy (do pliku PDF albo na papierze). Czasem się przydaje, choćby na tym blogu. Ciemne tło i jasna czcionka nie sprzyjają drukarkom.
A czy może służyć śledzeniu? Postanowiłem to zbadać.
W stylach testowego bloga dodałem link do obrazka, mającego stanowić tło w wersji drukowanej. I uruchomiłem narzędzia przeglądarki (Ctrl+Shift+I, potem zakładka Sieć), żeby patrzeć co się pobiera.
Obrazka testowego nie pobrało po zwykłym odwiedzeniu strony z bloga. Ale po naciśnięciu Ctrl+P, skrótu od drukowania, już się znalazł na liście pobranych plików.
Wniosek? Dzięki użyciu tej regułki strony mogą ustalić, czy drukowaliśmy ich treść.
Jak się chronić
Przede wszystkim pamiętajmy, iż jeśli mamy włączony JavaScript, to metody z tego wpisu są bez znaczenia.
JS jest w stanie odczytać wszystkie opisane informacje (o stopniu przeczytania strony, o wymiarach ekranu, o innych rzeczach). I wiele innych. Jest w stanie je na bieżąco wysyłać wścibskiej stronce.
Jest zatem dużo, dużo groźniejszy. Skupianie się na rzeczach egzotycznych, kiedy JS hula w przeglądarce, nie ma najmniejszego sensu.
Ale jeżeli już go wyłączyliśmy? W takim razie nie zaszkodzi dodać parę szlifów przeciw metodom na bazie HTML-a i CSS-a. Tak dla sportu.
Odkrywanie cech przeglądarki
Można trzymać u siebie jedną „nudną” przeglądarkę do surfowania po mniej zaufanej, reklamowej sieci. Bez trybu ciemnego, bez nietypowych bajerów. Konfiguracja domyślna.
Jeśli chodzi o zabezpieczenie przed ujawnianiem wymiarów ekranu – przeglądarka Tor Browser rządzi.
Korzysta jedynie z kilku standardowych wymiarów okna, odpowiadających najczęstszym urządzeniom. jeżeli nasze aktualne okno jest większe niż standardowe, to zapycha różnicę pustą białą przestrzenią.
Nie mamy Tora albo nie możemy go użyć (bo np. strona wykrywa i nie wpuszcza)? Albo nie chcemy?
Pozostaje używanie przeglądarki w trybie pełnego ekranu. No i warto, żeby sam ekran był czymś względnie standardowym. Odepnijmy ultraszeroki monitor-potwora, zostawmy sobie laptopa. Chyba iż chcemy się pochwalić podglądaczom.
Leniwe ładowanie
Przy leniwie ładowanych obrazkach może nam pomóc Firefox, który wyłącza tę funkcję, gdy mamy wyłączony JavaScript. Wprost przy tym piszą o ochronie przed śledzeniem.
Obrazki w mailach? Tutaj pomoże odpowiedni program lub strona od maili. Tutanota, z której korzystam, automatycznie blokuje pobieranie obrazków z zewnątrz i robi to tylko na moje życzenie. Włączam je, gdy ufam nadawcy.
A jeżeli nasza przeglądarka/mail nas nie chroni i musimy się narazić na obrazki ładowane na raty?
Osobiście uważam, iż najprostszym, niewyróżniającym nas sposobem byłoby przewinięcie strony. Choć raz, żeby wszystko się pobrało, a „obrazkowe pole minowe” zostało rozbrojone.
Możemy niby korzystać z przeglądarki, która wszystko ładuje od razu i olewa atrybut lazy. Albo jest stara i go nie wspiera. Albo ustawić w dodatku uBlock Origin, żeby nie pobierało elementów większych niż pewna wartość (czyli zwykle: żadnych obrazków).
Tyle iż wszystkie te rozwiązania są w obecnych czasach nietypowe i tylko by nas wyróżniły. A przejechanie wzrokiem po stronie to zachowanie względnie typowe.
Na tym skończę. Jak widzimy, nie potrzeba JavaScriptu do budowania naszego cyfrowego profilu. Wystarczy podsuwanie wielu obrazków i analizowanie, co wybrała nasza przeglądarka.
Życzę, żebyście jeszcze niejedne obrazki zobaczyli w internecie. Śmieszne, memiczne albo dające do myślenia… Ale jak najmniej śledzących.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}