Najsłabszym ogniwem większości aplikacji jest baza danych. Praca na domyślnej konfiguracji Doctrine tylko pogłębia ten problem. Znajomość podstawowych procesów optymalizacji oraz zasady ich działania powinny być wiedzą ogólnodostępną. Dlatego dziś poruszymy klasyka, jakim jest Doctrine Eager fetch mode, czy jak kto woli – Doctrine Eager loading.
Klasyka problemu N+1
W poprzednim wpisie poruszyłem temat Lazy Loadingu. Jest to opcja domyślnie stosowana w Doctrine, która, będąc nadużywaną, prowadzi do kolosalnej liczby zapytań wysyłanych do bazy danych. Tzw. opóźnione ładowanie relacji powoduje, iż Doctrine uruchamia sporo zapytań w pętlach. Traci on wtedy kontekst, za pomocą którego mógłby – zamiast wielu zapytań o dane – wysłać jedno, bardziej zbiorowe zapytanie.
Osobiście znany jest mi przypadek, kiedy pod jednym endpointem uruchamianych było prawie 3.500 zapytań bazowanowych (pic rel.)
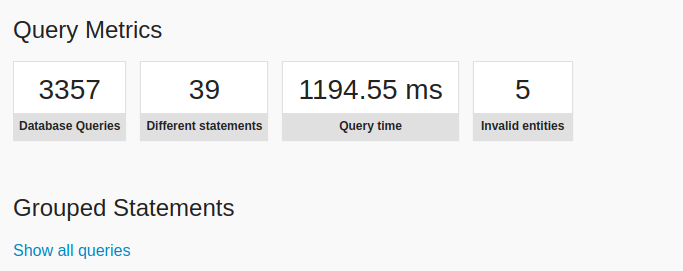
Problem, który uwieczniłem na powyższym zrzucie, jest właśnie spowodowany opóźnionym ładowaniem relacji dla względnie niewielkiego (wbrew pozorom) zestawu danych. Jednym z rozwiązań tego problemu jest możliwa praca nad zapytaniami, aby te, uruchamiane w pętlach, wynieść niejako poza te pętle oraz połączyć w jedno zapytanie.
Do gry wchodzi on: fetch=”EAGER”
Eager Loading jest konfiguracją, która pozwala na załączenie danych relacji w momencie tworzenia pobieranej przez nas encji. Kiedy pobieramy więcej niż jedną encję z repozytorium, to dzięki jednego dodatkowego zapytania, Doctrine dociąga nam skonfigurowaną relację do każdego obiektu.
Wyobraźmy sobie, iż w bazie danych mamy dwa blog posty, napisane przez dwóch różnych autorów. Relacja pomiędzy blog postem oraz autorem jest domyślnie skonfigurowana w trybie Lazy Loading. W momencie, kiedy będziemy chcieli wyświetlić post wraz z informacjami o autorze, to zostaną wywołane trzy zapytania:
// Pobieranie blog postów... SELECT b0_.name AS name_0, b0_.id AS id_1, b0_.author_id AS author_id_2, b0_.blog_id AS blog_id_3 FROM blog_post b0_ // Pobieranie autora dla postu ID 1 SELECT t0.name AS name_1, t0.id AS id_2 FROM author t0 WHERE t0.id = 1 // Pobieranie autora dla postu ID 2 SELECT t0.name AS name_1, t0.id AS id_2 FROM author t0 WHERE t0.id = 2Im więcej postów na blogu, tym więcej zapytań leci do bazy danych. Skonfigurowanie relacji jako fetch="EAGER spowoduje, iż już przed po pobraniu blog postów, a przed ich konstrukcją, zostanie wysłane jedno dodatkowe zapytanie do bazy danych o dane dla relacji:
// Pobieranie blog postów... SELECT b0_.name AS name_0, b0_.id AS id_1, b0_.author_id AS author_id_2, b0_.blog_id AS blog_id_3 FROM blog_post b0_ // Pobieranie autora dla wszystkich zwróconych postów SELECT t0.name AS name_1, t0.id AS id_2 FROM author t0 WHERE t0.id IN (1, 2)Jakby nie patrzeć – jedno zapytanie po indeksie kontra wiele – sztos. Baza danych na pewno lubi to
Gdzie możemy ustawić Eager Loading?
Doctrine zostawia nam dwa miejsca, w których możemy skonfigurować tą opcję.
Pierwsza opcja to mapowanie encji, a konkretniej – definicja relacji. Kiedy zmienimy tą opcję tutaj, to będzie ona działała w całej aplikacji:
<?xml version="1.0" encoding="UTF-8"?> <doctrine-mapping xmlns="http://doctrine-project.org/schemas/orm/doctrine-mapping" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://doctrine-project.org/schemas/orm/doctrine-mapping http://doctrine-project.org/schemas/orm/doctrine-mapping.xsd"> <entity name="App\Entity\BlogPost" table="blog_post"> <id name="id" type="integer"> <generator strategy="AUTO" /> </id> <one-to-one field="author" target-entity="App\Entity\Author" fetch="EAGER" /> </entity> </doctrine-mapping>Druga możliwość to konfiguracja w Query Builderze, która nadpisze powyższą definicję dla tego jednego zapytania:
final class BlogPostRepository extends ServiceEntityRepository { // ... public function findWithEagerAuthor(): array { return $this->createQueryBuilder('o') ->getQuery() ->setFetchMode(BlogPost::class, "author", ClassMetadata::FETCH_EAGER) ->getResult(); } }Dostępne opcje dają nam pełną elastyczność, z której moim zdaniem powinniśmy korzystać z głową. o ile poustawiamy wszystkie relacje w tryb Eager, to będziemy rzeźbić bazę danych dodatkowymi zapytaniami choćby w sytuacjach, w których nie potrzebujemy tych wszystkich danych. A to też źle.
Relacje nieprzyjazne Eager Loadingowi
Niestety, świat nie jest idealny. Oznacza to, iż Eager Loading nie wszędzie zadziała. Dokładniej, to problematyczne będą tutaj relacje jeden do wielu oraz wiele do wielu.
Powodem tego problemu jest to, iż klucz do relacji znajduje się w innym miejscu, niż tabelka, do której podłączona jest odpytywana przez nas encja. W relacji jeden do wielu klucz relacji znajduje się zawsze w tabelce po drugiej stronie. W relacji wiele do wielu klucz relacji znajduje się w osobnej tabeli, nazywanej tabelą krzyżową (eng. join table). Z tego powodu Doctrine nie może po prostu zebrać wszystkich identyfikatorów obiektów objętych relacją, w celu wysłania tylko jednego zapytania po obiekty z drugiej strony.
Alternatywne rozwiązanie dla pozostałych opcji
Gdyby przyjrzeć się bliżej temu, dlaczego interesujemy się Eager Loadingowi, to chodzi nam o to, abyśmy jak najmniejszym kosztem pobrali dane znajdujące się po drugiej stronie relacji. Eager fetch mode załatwia to przez dodatkowe zapytanie typu WHERE id IN(...). Ale nie jest to jedyna opcja, na pobranie danych relacji.
Innym, na pewno znanym wielu z Was, rozwiązaniem jest zrobienie joina oraz dodatkowy select na załączone dane. Rozważmy sobie poniższy przykład:
// src/Repository/PostBlogRepository.php public function findWithComments(): array { return $this->createQueryBuilder('o') ->addSelect('comments') ->leftJoin('o.comments', 'comments') ->getQuery() ->getResult(); }W takiej sytuacji Doctrine zauważy, iż ma odpowiednie dane, którymi może wypełnić komentarze i… zrobi to. Wszystko odbędzie się poprzez wysłanie tylko jednego zapytania, które będzie wyglądało podobnie do tego poniżej:
// Zapytanie wygenerowane przez Doctrine SELECT b0_.name AS name_0, b0_.id AS id_1, c1_.content AS content_2, c1_.id AS id_3, b0_.author_id AS author_id_4, b0_.blog_id AS blog_id_5, c1_.blog_post_id AS blog_post_id_6 FROM blog_post b0_ LEFT JOIN comment c1_ ON b0_.id = c1_.blog_post_idCzyli ostatecznie wychodzi na to, iż jest lepiej niż gdyby miało być przy włączonym Eager Loadingu. Niestety, w przeciwieństwie do wspomnianego, tego typu optymalizację jesteśmy w stanie zrobić tylko po stronie Query Buildera / DQL.
Uwaga na inner joiny!
Rozważmy dwa różne przypadki relacji jeden do wielu: produkty posiadające <1, N> wariantów oraz sprzedawcy posiadający <0, N> produktów.
Z obydwu stron mamy ten sam typ relacji. Gdybyśmy chcieli wraz z produktami pobrać ich wszystkie warianty, to możemy skorzystać zarówno z metody innerJoin jak i leftJoin. Niestety, kiedy planujemy pobrać sprzedawców wraz z ich produktami, to tutaj już nie możemy myśleć o stosowaniu tych metod zamiennie. Stosowanie innerJoin wykluczy z wyniku sprzedawców, którzy nie posiadają żadnych produktów. Z jednej strony, jest to normalne – różnice pomiędzy inner oraz left joinem. Z drugiej strony – nie zawsze się o tym pamięta; zwłaszcza, kiedy pracuje się z ORM, którego długotrwałe stosowanie może nas wybić z rytmu pracy z SQL.
Przekonajmy się w praktyce!
Po przeczytaniu tego wpisu większość z Was chciałaby sobie popróbować, poeksperymentować… pobawić się tym tematem. Mam dla Was dobrą wiadomość – napisałem kodzik, który pozwoli Wam na własną analizę tego tematu. Repozytorium znajdziecie na GitHubie pod linkiem: DoctrineAssociationFetching.
W całym projekcie skupić powinniśmy się na encji BlogPost, od której wychodzą 4 różnego rodzaju relacje. W repozytorium BlogPostRepository znajdują się cztery metody, które wyciągają encje BlogPost wraz z relacjami kolejno, w sposób zoptymalizowany.
Dodatkowo, do dyspozycji mamy trzy endpointy, dzięki których możemy załadować fixturki, czyli dane testowe aplikacji:
- /fixtures/all – dla każdej relacji blog postu ładujemy stałą liczbę elementów w relacjach
- /fixtures/zero – ładujemy blog posty z zerową liczbą elementów w relacjach
- /fixtures/random – dla każdej relacji blog postu ładujemy losową liczbę elementów w relacjach
Oprócz tego, mamy jeden endpoint /, dzięki którego możemy uruchomić poszczególne metody repozytorium oraz poiterować po wynikach.
Polecam zajrzeć do kontrolera PostsController i pobawić się trochę. Oczywiście, w parze z regularnymi wizytami pod endpointem /_profiler