Jak wspomniałem w pierwszym wpisie w ramach Daj Się Poznać 2017, aplikacja, którą piszę będzie odpowiedzialna za wykrywanie plagiatów w kodach źródłowych programów.
W tym i w kilku (0, 1 lub 2 :P) kolejnych wpisach postaram się przedstawić kilka istniejących podejść do tego problemu.
Systemy bazujące na zliczaniu atrybutów
Pierwszymi automatycznymi systemami do wykrywania plagiatów w kodach źródłowych programów były systemy polegające za zliczaniu i porównywaniu atrybutów programów.
Miara złożoności Halstead’a
Pierwszym automatycznym systemem służącym do automatycznego porównywania stopnia podobieństwa między kodami źródłowymi programów był system zaproponowany przez Halsted’a w 1977 roku. System ten do mierzenia podobieństwa programów używał czterech statystyk programu:
 – liczba unikalnych operatorów
– liczba unikalnych operatorów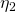 – liczba unikalnych operandów
– liczba unikalnych operandów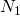 – liczba wystąpień operatorów
– liczba wystąpień operatorów – liczba wystąpień operandów
– liczba wystąpień operandów
Pary programów, u których powyższe wartości były identyczne były dalej przeglądane przez człowieka w celu stwierdzenia lub odrzucenie zajścia plagiatu (spora wada tego systemu ;)).
Powyższy system miał bardzo ograniczone możliwości. Statystyki takie jak liczba wystąpień operatorów czy ilość unikalnych operatorów są wartościami, które można w bardzo łatwy sposób zmienić, a co za tym idzie oszukać opisany wyżej system.
System Accuse Grier’a
System Accuse, stworzony przez Grier’a, powstał na bazie wcześniej opisanego systemu. Grier w swoim systemie do badania podobieństw między programami używa następujących statystyk:
- liczba unikalnych operatorów
- liczba unikalnych operandów
- liczba wystąpień operatorów
- liczba wystąpień operandów
- liczba linii kodu
- liczba zmiennych zadeklarowanych i użytych
- liczba wszystkich instrukcji kontrolnych
W pierwszej fazie system Accuse zliczał dla wszystkich programu wyżej wymienione parametry. W drugiej fazie jest obliczania korelacja pomiędzy parami programów. Przy obliczaniu korelacji używane są dwa stałe parametry:
- rozmiar okna (window) – określa maksymalną różnicę pomiędzy zliczonymi statystykami dwóch programów
- wartość ważności (importance) – waga danego parametru przy obliczaniu korelacji
Następnie korelacja jest obliczana w następujący sposób:
- wartość korelacji jest ustawiana na 0
- dla każdej metryki wykonywane jest:
- jeżeli
 jest wartością i-tej metryki programu A i
jest wartością i-tej metryki programu A i 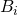 jest korenspondującą metryką w programie B wtedy
jest korenspondującą metryką w programie B wtedy 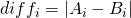 .
. - jeżeli
 wtedy
wtedy 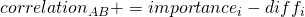 .
.
- jeżeli
Przy parach programów z dużą wartością obliczonej korelacji zachodzi prawdopodobieństwo plagiatu i programy te powinny zostać przejrzane przez człowieka (tym razem jest o tyle lepiej, iż nie wszystkie porównania muszą zostać przejrzane ;)).
System Faidhi-Robinson
Faidhi i Robinson stworzyli listę metryk służącą do wykrywania plagiatów. Metryki te według nich miały być lepsze od metryk opisanych w systemie Accuse. Metryki te, nie korelują ze sobą, a dodatkowo w tych metrykach są ukryte dodatkowe miary, które powinny być ciężkie do zmiany przynajmniej przez programistę (a przynajmniej początkującego ;).
Pierwsze dziesięć metryk Faidhi i Robinson zakwalifikowali do grupy metryk, które według nich może bez większego problemu zmienić choćby początkujący programista.
- średnia ilość znaków na linię
- liczba linii z komentarzami
- liczba linii z wcięciami
- liczba pustych linii
- średnia długość procedury lub funkcji
- liczba słów kluczowych
- średnia długość identyfikatora
- średnia ilość spacji na linię
- liczba etykiet i poleceń goto
- liczba unikalnych identyfikatorów
Kolejne 14 metryk zostało wybranych jako metryki mierzące strukturę programu, które są trudne do zmodyfikowania przez programistę.
- liczba etapów programów – przy pomocy algorytmu Cocke’a i Allen’a jest tworzony graf przepływu
- liczba kolorów wierzchołków o kolorach 1 i 2 w pokolorowanym grafie przepływu
- liczba wierzchołków mających kolor 3
- liczba wierzchołków mających kolor 4
- procentowa ilość wyrażeń w programie
- procentowa ilość prostych wyrażeń w programie
- procentowa ilość termów w programie
- procentowa ilość współczynników w programie
- liczba zbędnych rzeczy w programie – np. zbędne średniki lub pary BEGIN/END
- liczba linii wewnątrz funkcji i procedur
- liczba funkcji i procedur
- procentowa ilość wyrażeń warunkowych
- procentowa ilość powtarzających się wyrażeń
- liczba instrukcji w programie
W systemie Faidhi-Robinson, podobnie jak w poprzednim systemie, do obliczania podobieństwa użyto dwóch stałych parametrów:
- rozmiar okna (window)
- wartość ważności (importance)
Algorytm obliczania podobieństwa wygląda następująca:
- dla każdej metryki:

Całkowita korelacja wynosi zatem:
 .
.
Im otrzymana korelacja miała większą wartość tym zachodziło większe prawdopodobieństwo plagiatu.
Krótkie podsumowanie
W tym wpisie przedstawiłem kilka pierwszych systemów do wykrywania plagiatów w kodach źródłowych. Niestety nie były one zbyt efektywne.
W kolejnych wpisach opiszę kilka innych podejść do wykrywania plagiatów, które charakteryzują się większą skutecznością.