Wstęp
W poprzednim wpisie „Wprowadzenie do Kubernetes” przyjrzeliśmy się, czym jest Kubernetes, jakie problemy rozwiązuje i jak wygląda jego architektura z lotu ptaka. Teraz pora przejść od teorii do praktyki.
W tym wpisie zakładam, iż masz już zainstalowanego Kubernetesa (np. na Docker Desktop – jeżeli nie to w poprzednim wpisie opisywałem jak skonfigurować lokalnie), to czas na kolejny krok – uruchomienie pierwszej aplikacji w klastrze.
Nie będzie to nic skomplikowanego – pokażę Ci, jak wdrożyć pierwszą aplikację, używając lokalnego środowiska Kubernetesa. Wykorzystamy obraz Nginx, czyli lekki i wydajny serwer WWW, który idealnie nadaje się do naszych pierwszych eksperymentów. Krok po kroku przejdziemy przez cały proces: od postawienia lokalnego klastra, przez konfigurację i wdrożenie aplikacji, aż po jej usunięcie. Na końcu podam też listę przydatnych komend, które ułatwią Ci codzienną pracę.
Uruchomienie lokalnego klastra
Zaczynamy od uruchomienia lokalnego klastra, co jest niezbędne do wdrożenia naszej aplikacji. Zakładam, iż masz już zainstalowanego Dockera i Kubernetesa na swoim komputerze, zgodnie ze wskazówkami z poprzedniego wpisu.
Natomiast przed rozpoczęciem dobrze jest sprawdzić czy wszystko nam działa.
Do weryfikacji statusu klastra warto sprawdzić podstawowe informacje o klastrze:
kubectl cluster-infoPo wykonaniu tej komendy powinieneś uzyskać wynik podobny do poniższego:

Jeśli wszystko działa prawidłowo, powinieneś zobaczyć informacje o klastrze, w tym adres Control Plane i CoreDNS (wewnętrzny serwer DNS Kubernetesa). To znak, iż kubectl poprawnie komunikuje się z naszym lokalnym klastrem.
Dodatkowo możesz sprawdzić, jakie węzły (nodes) masz dostępne:
kubectl get nodesW naszym przypadku zobaczysz prawdopodobnie jeden węzeł o nazwie docker-control-plane, który pełni rolę zarówno Control Plane, jak i Worker Node. To typowa konfiguracja dla środowiska deweloperskiego. Natomiast ważne jest tutaj pole STATUS – jeżeli widzisz Ready, to znaczy, iż Twój węzeł jest gotowy do uruchamiania Podów (czyli naszych aplikacji).

Pliki YAML
W Kubernetesie rzadko kiedy robimy coś „ręcznie”. Zamiast wydawać serię poleceń w stylu „stwórz to, a potem tamto”, preferujemy podejście deklaratywne. Oznacza to, iż opisujemy w pliku konfiguracyjnym, jaki stan końcowy chcemy osiągnąć, a Kubernetes sam dba o to, by ten stan zrealizować.
Te pliki konfiguracyjne, nazywane manifestami, pisane są w formacie YAML. To właśnie w nich definiujemy wszystkie obiekty, które mają istnieć w naszym klastrze – aplikacje, sieci, wolumeny danych i wiele innych.
Deklaratywne podejście
W Kubernetesie pracujemy w modelu deklaratywnym.
Zamiast mówić „uruchom mi ten kontener”, mówisz: „chcę, żeby zawsze działała aplikacja z obrazem nginx:latest w jednej replice”. Kubernetes sam dba o to, aby ten stan był utrzymany.
To podejście daje ogromne korzyści:
- automatyzacja – narzędzia CI/CD mogą wdrażać aplikacje na podstawie manifestów.
- powtarzalność – masz plik, który możesz wrzucić do repozytorium i uruchomić na dowolnym klastrze,
- kontrola wersji – każda zmiana w konfiguracji aplikacji może być śledzona w Gicie,
Najczęściej spotykane obiekty
W YAML-ach definiujemy różne obiekty Kubernetesa, m.in.:
- Pod – najmniejsza jednostka w K8s, która uruchamia jeden lub więcej kontenerów,
- Deployment – zarządza Podami i dba o ich replikację oraz aktualizacje,
- Service – zapewnia stabilny adres IP i DNS dla grupy Podów,
- ConfigMap / Secret przechowują konfigurację i wrażliwe dane,
- Ingress – umożliwia dostęp do aplikacji z zewnątrz (np. przez domenę).
Bardziej szczegółowo elementy Kubernetsa opisywałem w poprzednim wpisie.
Podobieństwa i różnice do Docker Compose
Jeśli pracowałeś z Docker Compose, struktura manifestów Kubernetesa będzie Ci znajoma. Oba wykorzystują YAML do opisania aplikacji, ale różnią się poziomem szczegółowości:
Docker Compose skupia się na prostocie – definiujesz services, networks i volumes. Kubernetes jest bardziej rozbity – masz Pody, Deploymenty, Services, ConfigMapy i dziesiątki innych obiektów.
W Docker Compose jeden plik opisuje całą aplikację. W Kubernetesie często rozdzielasz obiekty na osobne pliki lub sekcje tego samego pliku, oddzielone ---.
Twój pierwszy manifest Deploymentu
Skoro już wiemy, iż w Kubernetesie wszystko opiera się o pliki YAML, czas przygotować naszą pierwszą prawdziwą aplikację.
Zamiast Pod-a (który jest pojedynczą instancją), użyjemy od razu Deploymentu. Dzięki niemu Kubernetes będzie mógł automatycznie zarządzać Podami – tworzyć je, restartować w razie awarii i skalować w górę lub w dół.
Przygotowanie pliku deployment.yaml
Stwórzmy teraz nasz pierwszy manifest dla serwera Nginx – prostej aplikacji webowej, która posłuży nam jako przykład. W dowolnym katalogu na swoim komputerze utwórz plik o nazwie deployment.yaml i wklej do niego poniższą zawartość:
apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deployment spec: replicas: 2 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nginx-container image: nginx:latest ports: - containerPort: 80Analiza pliku deployment.yaml
Tak, więc przyjrzymy się teraz poszczególnym elementom tego pliku:
- apiVersion: apps/v1 – Każdy obiekt w Kubernetesie należy do jakiejś grupy API. Deployment znajduje się w grupie apps w wersji v1. To informacja dla Kubernetesa, jak interpretować ten plik.
- kind: Deployment – To rodzaj obiektu, który chcemy stworzyć. Deployment to jeden z najważniejszych obiektów – jego zadaniem jest zarządzanie naszą aplikacją. Dba o to, by działała określona liczba jej kopii i umożliwia bezprzerwowe aktualizacje.
- metadata – Tutaj umieszczamy metadane obiektu, czyli informacje o nim. Najważniejsza z nich to name, czyli unikalna nazwa naszego Deploymentu: nginx-deployment.
- spec – Serce naszego manifestu. W sekcji spec (od specyfikacji) opisujemy pożądany stan.
- replicas: 2 – Chcemy, aby nasza aplikacja Nginx działała w dwóch identycznych kopiach (replikach). jeżeli jedna z nich ulegnie awarii, Kubernetes automatycznie uruchomi nową, aby utrzymać stan dwóch działających instancji.
- selector – To najważniejszy element. Deployment musi wiedzieć, którymi Podami (czyli instancjami naszej aplikacji) ma zarządzać. matchLabels mówi: „Interesują mnie wszystkie Pody, które mają etykietę app: nginx”.
- template – To jest szablon Poda, który Deployment będzie tworzył. To właśnie na podstawie tego szablonu powstaną nasze dwie repliki.
- metadata.labels – Nadajemy etykietę naszemu Podowi. Krytycznie ważne jest, aby etykiety tutaj (app: nginx) pasowały do selector.matchLabels zdefiniowanego wyżej! W ten sposób Deployment odnajduje swoje Pody.
- spec.containers – Każdy Pod uruchamia co najmniej jeden kontener. Tutaj definiujemy, jak ten kontener ma wyglądać.
- name: nginx-container – Nazwa kontenera wewnątrz Poda.
- image: nginx:latest – Obraz kontenera, który ma zostać użyty. Kubernetes pobierze najnowszą wersję obrazu nginx z Docker Huba.
- ports.containerPort: 80 – Informujemy Kubernetesa, iż nasza aplikacja wewnątrz kontenera nasłuchuje na porcie 80.
I to wszystko! W tym jednym pliku opisaliśmy całą naszą aplikację. Teraz czas ją wdrożyć.
Wdrożenie aplikacji
Mając gotowy manifest, wdrożenie aplikacji sprowadza się do jednej komendy. W terminalu, będąc w katalogu z plikiem deployment.yaml, wykonaj:
kubectl apply -f deployment.yamlPolecenie apply mówi Kubernetesowi: „Weź ten plik i upewnij się, iż stan klastra zgadza się z jego zawartością”. Ponieważ w klastrze nie było wcześniej naszego Deploymentu, Kubernetes go stworzy.
W odpowiedzi powinieneś zobaczyć:

Tym sposobem Twoja pierwsza aplikacja została właśnie wdrożona. Gdzieś w czeluściach klastra Kubernetes powołuje do życia dwa Pody z serwerem Nginx. Zobaczmy, czy faktycznie tak się stało.
Zaglądamy do środka – co się dzieje z moim Podem?
Samo wdrożenie to jedno, ale prawdziwa zabawa zaczyna się, gdy chcemy sprawdzić, co tak naprawdę dzieje się w klastrze. Do tego służy cała gama komend kubectl. To właśnie dzięki niemu możemy sprawdzić, jakie obiekty istnieją w klastrze, podejrzeć ich szczegóły, logi czy choćby wejść bezpośrednio do działającego kontenera.
get deployments – sprawdzamy nasze wdrożenia
Na początek komenda, która pozwala nam sprawdzić listę wdrożonym aplikacji:
kubectl get deploymentsW wyniku powinieneś dostać coś zbliżonego do poniższego:

Co oznaczają poszczególne sekcje:
- READY 2/2 – oznacza, iż 2 Pody działają i są gotowe.
- UP-TO-DATE – ile replik zostało zaktualizowanych do bieżącej wersji.
- AVAILABLE – ile Podów jest faktycznie dostępnych w klastrze.
get pods – sprawdzamy co działa
Teraz możemy sprawdzić listę podów dostępnych na naszym klastrze:
kubectl get podsPowinieneś zobaczyć 2 Pody (wynika to z tego, iż ustawiliśmy parametr replicas: 2) z nazwami zaczynającymi się od nginx-deployment-. jeżeli ich status to Running, wszystko działa prawidłowo!

Możesz też sprawdzić więcej szczegółów:
kubectl get pods -o wideTa wersja pokaże dodatkowe informacje, jak węzeł, na którym działa Pod czy jego adres IP.

describe pod – szczegóły poda
W następnej kolejności chcielibyśmy się więcej dowiedzieć o jednym konkretnym podzie. W takim wypadku możemy wykonać poniższą komende:
kubectl describe pod <nazwa-poda>Wykonajmy ją zatem dla jednego z podów:
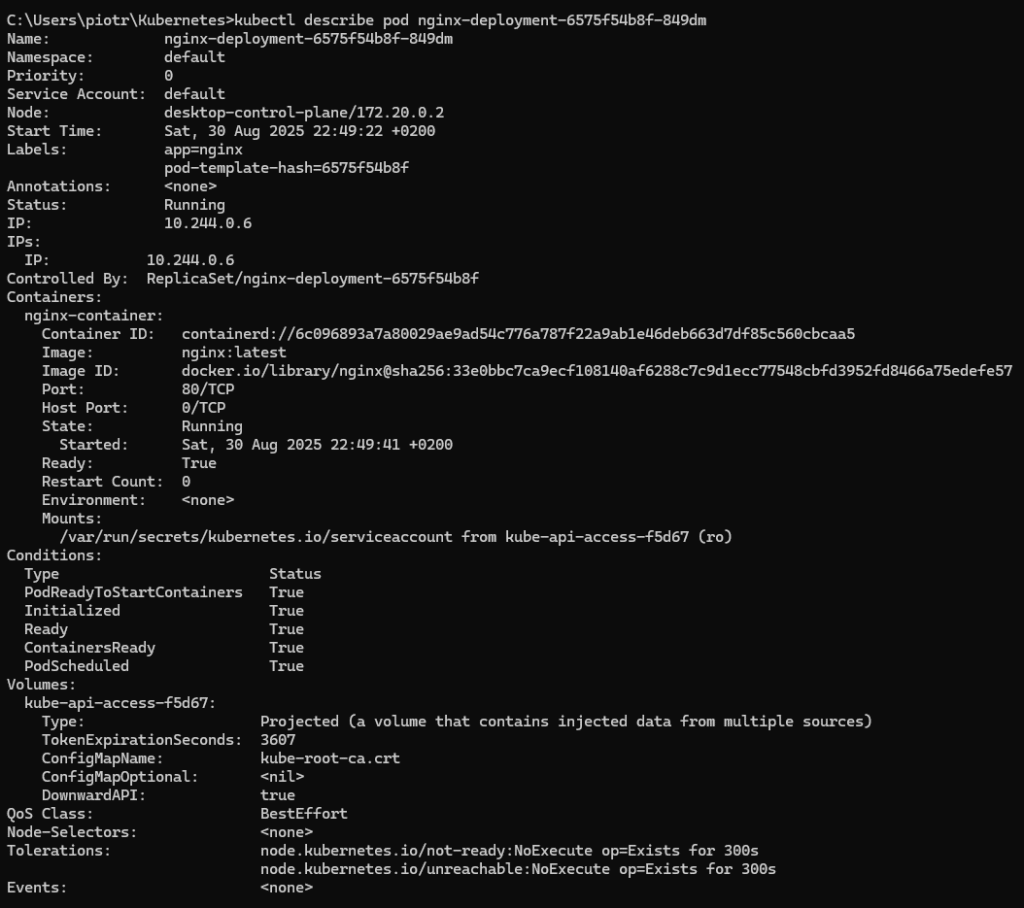
Ta komenda pokazuje pełne informacje o podzie:
- Specyfikację i konfigurację
- Status kontenera i Poda
- Eventy związane z cyklem życia Poda
- Użycie zasobów (CPU, pamięć)
- Szczegóły sieciowe
To świetne narzędzie do debugowania. Jak coś nie gra, describe zwykle pokaże Ci gdzie szukać problemu.
kubectl logs – jak czytać logi aplikacji
Jeszcze dość często przydaje się sprawdzenia logów naszej aplikacji. Do tego celu korzystamy z poniższej komendy:
kubectl logs <nazwa-poda>A jak odpalimy dla naszego serwera nginx, dostaniemy:
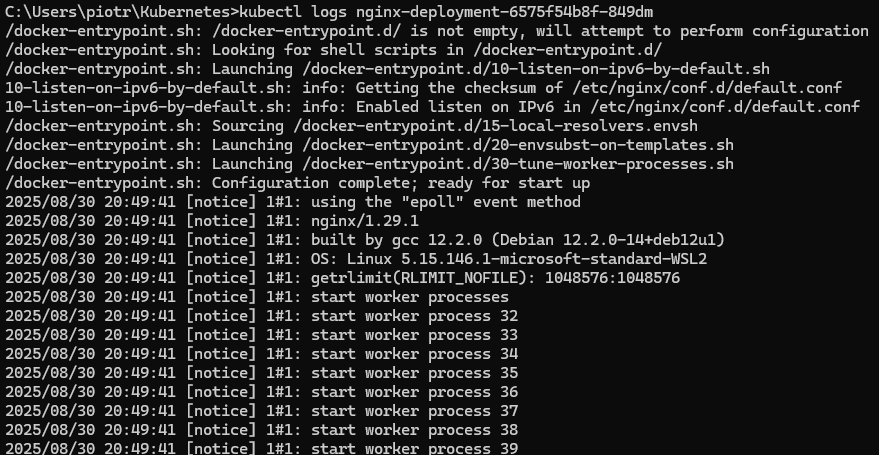
Dla świeżo uruchomionego Nginxa logi nie będą zbyt fascynujące, ale umiejętność ich podglądania przydaje się w codziennej pracy.
Jak dostać się do naszej aplikacji?
Nasza aplikacja Nginx działa wewnątrz klastra. Domyślnie nie jest dostępna z zewnątrz, czyli z naszej maszyny (hosta). Aby to zmienić, musimy ją w jakiś sposób „wystawić”. W produkcyjnych systemach używa się do tego obiektów Service i Ingress, ale to temat na osobny wpis.
Na potrzeby deweloperskie istnieje znacznie prostszy sposób: kubectl port-forward. Komenda ta tworzy bezpieczny tunel między Twoim komputerem a konkretnym Podem w klastrze.
Uruchommy tunel dla naszego Deploymentu. Przekierujemy ruch z portu 8080 na naszej maszynie do portu 80 w kontenerach Nginx.
kubectl port-forward deployment/nginx-deployment 8080:80Terminal zostanie „zablokowany” przez to polecenie, co oznacza, iż tunel jest aktywny. Zobaczysz komunikat podobny do tego:

Teraz otwórz przeglądarkę internetową i wejdź pod adres http://localhost:8080. Powinieneś zobaczyć stronę powitalną Nginx: „Welcome to nginx!”.
Istnieje też drugi mechanizm do dostania się do naszej aplikacji: kubectl proxy. Czym się różni? port-forward tworzy tunel do konkretnego Poda/Deploymentu. Z kolei kubectl proxy uruchamia serwer proxy, który daje Ci dostęp do całego API serwera Kubernetesa. Jest to narzędzie bardziej zaawansowane, przydatne, gdy chcesz eksplorować API Kubernetesa, a niekoniecznie dostać się do samej aplikacji. Na tym etapie port-forward jest tym, czego potrzebujesz.
Sprzątanie po sobie (kubectl delete)
Po skończonej zabawie dobrze jest posprzątać. Usunięcie wszystkich zasobów, które stworzyliśmy, jest równie proste, jak ich utworzenie. Wystarczy użyć komendy kubectl delete i wskazać ten sam plik manifestu.
kubectl delete -f deployment.yamlKubernetes odczyta plik, zidentyfikuje obiekt nginx-deployment i usunie go wraz ze wszystkimi Podami, którymi zarządzał. Otrzymasz potwierdzenie:

Możesz to zweryfikować, wpisując ponownie kubectl get pods. Tym razem lista powinna być pusta lub Pody będą w stanie Terminating. Po chwili znikną całkowicie.
Lista przydatnych komend
Poniżej spisałem listę podstawowych komend, które przy pracy z Kubernetesem używa się najcześciej.
Podstawowe informacje:
- kubectl cluster-info – informacje o klastrze i jego komponentach
- kubectl version – wersja kubectl i klastra Kubernetes
- kubectl config current-context – aktualny kontekst (klaster), z którym pracujesz
Zarządzanie obiektami:
- kubectl apply -f plik.yaml – tworzenie lub aktualizacja obiektów z pliku
- kubectl delete -f plik.yaml – usuwanie obiektów opisanych w pliku
- kubectl get <typ-obiektu> – wyświetlanie listy obiektów danego typu np. pods, services
- kubectl describe <typ> <nazwa> – szczegółowe informacje o konkretnym obiekcie
- kubectl edit <typ> <nazwa> – edycja obiektu bezpośrednio w klastrze
Praca z Podami:
- kubectl logs <pod> – wyświetlanie logów z poda
- kubectl exec -it <pod> -- /bin/bash – wejście do kontenera w trybie interaktywnym
- kubectl port-forward <pod> 8080:80 – przekierowanie portu z lokalnej maszyny do poda
- kubectl top pods – aktualne użycie zasobów (CPU, pamięć) przez pody
Debugowanie i monitorowanie:
- kubectl get events – eventy zachodzące w klastrze (przydatne przy problemach)
- kubectl describe node <node> – szczegóły węzła i jego zasobów
- kubectl get all – przegląd wszystkich głównych obiektów w namespace
Skróty ułatwiające pracę
Kubectl obsługuje skróty nazw typów obiektów, które znacznie przyspieszają pracę:
- po zamiast pods – szybszy dostęp do podów
- deploy zamiast deployments – zarządzanie wdrożeniami
- svc zamiast services – praca z serwisami
- ns zamiast namespaces – przełączanie między przestrzeniami nazw
Przykłady użycia skrótów:
- kubectl get po – to samo co kubectl get pods
- kubectl describe deploy nginx – to samo co kubectl describe deployment nginx
- kubectl get svc – lista wszystkich serwisów
Podsumowanie
W tym wpisie przeszliśmy od pustego klastra Kubernetesa do uruchomionej aplikacji. Najpierw wyjaśniliśmy, czym są pliki YAML i dlaczego to one są fundamentem pracy z Kubernetesem. Następnie przygotowaliśmy prosty Deployment dla obrazu Nginx, wdrożyliśmy go do klastra i sprawdziliśmy, iż Pod faktycznie działa. Na koniec przyjrzeliśmy się podstawowym komendą kubectl, podejrzeliśmy logi i uzyskaliśmy dostęp do aplikacji przez port-forward.
Kubernetes to potężne narzędzie, a ten wpis to dopiero wierzchołek góry lodowej. Teraz, gdy masz już za sobą pierwsze wdrożenie, możesz zacząć eksperymentować z bardziej zaawansowanymi funkcjami, takimi jak Service, Ingress, Volumes czy ConfigMaps.
W przyszłych wpisach z pewnością poruszymy te tematy bardziej szczegółowo. Daj znać, czy chciałbyś więcej wpisów w temacie Kubernetes, lub masz inne pytania.








