Wyobraź sobie, iż wystąpił problem w produkcyjnym systemie zbudowanym z sieci rozproszonych mikrousług. Błąd przekazuje zespół, który złożył żądanie do Twojego systemu i operacja zawiodła – obsługa trwała długo, a następnie został zwrócony błąd. Podają requestId oraz szczegóły żądania.
Pytanie: Czy byłbyś/byłabyś w stanie szybko odpowiedzieć, co konkretnie było przyczyną błędu?
—
Zanim przejdziemy do artykułu – mam dla Ciebie 2 ważne informacje
- Chciałbym zaprosić Ciebie na darmowe szkolenie z Monitoringu Mikroserwisów, które prowadzę online 22 listopada o godzinie 18:00 ⏰. Poniżej znajdziesz link, za pomocą którego możesz zapisać się na szkolenie:
WAŻNE! Zapisz się, choćby jeżeli nie będziesz mógł być na żywo! Roześlemy link do nagrania.
2. Szkoleniem z Monitoringu Mikroserwisów otwieramy sprzedaż drugiej edycji naszego sztandarowego szkolenia „Program Java Developer”
Tymczasem przechodzimy do artykułu 🙂
—
W tym wpisie chciałbym poruszyć problematykę Observability (obserwowalności) systemów opartych o architekturę rozproszonych mikrousług. Opowiem o:
- Log Aggregation, zbieranie logów w środowisku rozproszonym
- Distributed Tracing, czyli śledzenie konkretnego żądania
- Monitoring ogólnej kondycji systemu
- Perspektywa ogólna serwisu
- Perspektywa szczegółowa instancji
Narzędzia, które mogą Ci się przydać
Aby zdiagnozować problem możesz potrzebować kilku narzędzi, które Ci w tym pomogą:
- Log Aggregation.
Agregowanie i przechowywanie logów w jednym, centralnym miejscu pozwoli Ci na przeszukiwanie logów aplikacji, aby określić, gdzie trafiło żądanie i co się z nim działo. Nie musisz logować się na poszczególne maszyny, aby wyodrębnić te informacje – robisz to z jednego miejsca. Otrzymujesz informacje takie jak: kiedy zaszło zdarzenie, co konkretnie się działo podczas jego obsługi. - Distributed Tracing.
Przeglądanie logów w centralnym miejscu jest w porządku. Jednak gdy musisz prześledzić, jak dane żądanie było obsługiwane przez wiele aplikacji, czy gdzieś dotarło, kiedy dotarło, odejmować od siebie czasy obsługi oraz czasy spędzenia żądania w sieci, żmudne kalkulacje zabierają cenny czas. Co byś powiedział, gdybyś miał przebieg żądania przez wszystkie systemy na wykresie czasowym z wyszczególnieniem, ile czasu zajęło jego przetwarzanie przez konretne komponenty systemu? - Monitoring całego systemu.
Monitoring pozwala na uniknięcie nasilenia się awarii poprzez wygenerowanie alertu i odpowiednio szybką reakcję. Gdy monitorowane są procesy biznesowe aplikacji oraz komunikacja z zewnętrznymi zasobami, można określić, czy nie występuje problem z którymś zasobem, co może opóźniać przetwarzanie części żądań. - Monitoring konkretnej instancji.
Może jednak okazać się, iż kondycja całego systemu wygląda w porządku, ale jednak wystąpił problem. Monitorując niezagregowane dane, ale z podziałem również na konkretne instancje, można określić, czy problem jest lokalny. Może się okazać, iż maszyna, na której działa któraś z instancji ma jakiś problem, np. z dyskiem, pamięcią lub zużyciem CPU.
Mając te narzędzia, można powiedzieć, iż dość dobrze monitorujesz swój system. o ile nie, jesteś niewidomy na część problemów, które mogą się objawić.
Psst… Interesujący artykuł?
Jeżeli podoba Ci się ten artykuł i chcesz takich więcej – dołącz do newslettera. Nie ominą Cię materiały tego typu.
Dziękujemy!
Wysłaliśmy Ci mail powitalny, w którym znajdziesz link do aktywacji newslettera. Do usłyszenia!
Informacja w logach systemu
Pierwszym miejscem, w które można zajrzeć to logi aplikacji. Tam zwykle notowany jest przebieg obsługi żądania. W konfiguracji logów aplikacji można umieścić requestId jako część wpisu logu w taki sposób, aby w razie potrzeby wyodrębnić z logów wszystkie wpisy dotyczące jednego żądania. Przykładowo, wpisy logów mogą mieć format:
Wartość ce5c75b9-34bb-4dee-a74f-aaf486398f68 jako requestId jest umieszczana w każdej linijce kodu, która dotyczy obsługi tego żądania.
Taką informację możesz umieścić w kontekście MDC podczas przechwytywania żądania, a następnie użyć w formacie logu.
Czytaj więcej (o MDC):
- Logowanie aplikacji Java: Organizacja logów
- Logowanie aplikacji Java: Co, Kiedy, Gdzie i Jak?
Log Aggregation
W skalowalnych środowiskach pojawia się wyzwanie z przeglądaniem logów na wielu maszynach. o ile mikrousługi są uruchomione na wielu maszynach, nużące i nieefektywne jest logowanie sie na wiele maszyn w poszukiwaniu informacji z plików logów.
Dodatkowym wyzwaniem jest pozyskiwanie informacji z dynamicznych, auto skalowalnych środowisk uruchomieniowych o naturze efemertycznej (tymczasowej), gdzie w każdej chwili instancja może być zaalokowana, albo zwolniona. No bo jak pozyskać informacje z maszyny, która właśnie zniknęła?
Systemy Log Aggregation służą do przechwytywania i utrwalania logów z wielu źródeł w jednym, łatwo dostępnym miejscu. Gdy logi są dostępne w jednym miejscu, można w łatwy sposób je przeszukiwać. Co więcej, będąc składowane, są dostępne, choćby gdy środowisko uruchomieniowe zostało już wyłączone.
Stosując log aggregation zdiagnozuejsz:
- Nie wiem dokładnie, na jaki serwer trafiło to konkretne żądanie, ale na pewno będzie w agregatorze logów.
- Jestem ciekaw, ile było *takich* przypadków na różnych instancjach serwisu w przeciągu X do Y.
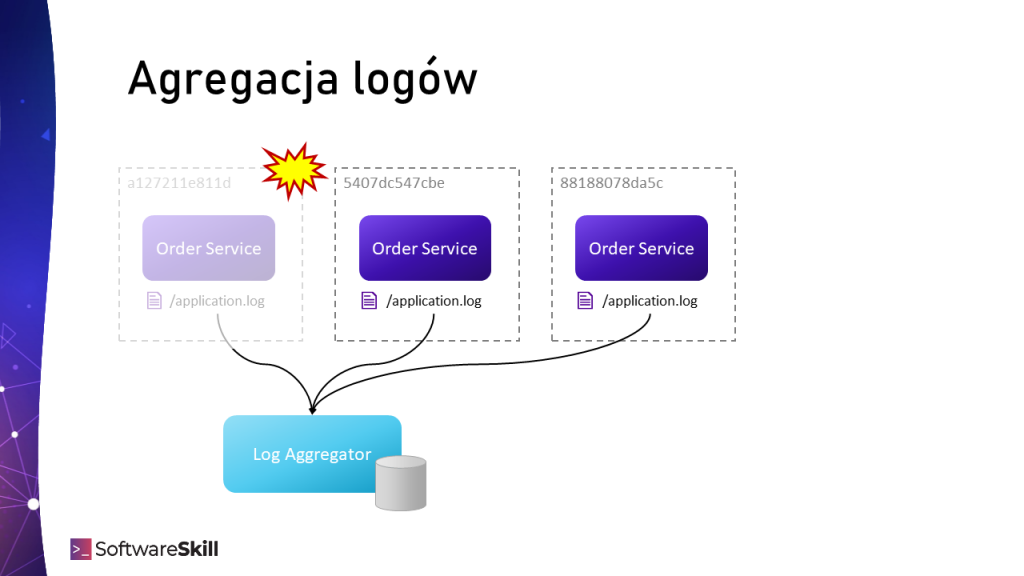 Agregowanie logów z wielu źródeł w jednym miejscu – Log Aggregatorze
Agregowanie logów z wielu źródeł w jednym miejscu – Log AggregatorzeAby logi znalazły się w systemie Log Aggregation stosuje się jedno z kilku podejść:
1. Wysyłanie logów z aplikacji
Najprostszym rozwiązaniem jest skonfigurowanie loggera w taki sposób, aby dodatkowo wysyłał logi do systemu Log Aggregation. Podczas logowania, wpis jest od razu wysyłany do systemu. Przykładowa konfiguracja Logback, która wysyła wpisy logów za pomocą Gelf (Graylog Extended Log Format) mogłaby wyglądać w następujący sposób:
To rozwiązanie wygląda na bardzo proste. Nie jest jednak pozbawione wad.
- Kiedy wysyłanie logów z jakiegoś powodu się nie powiedzie, np. system Log Aggregation jest chwilowo przeciążony, może to niekorzystanie wpłynąć na performance aplikacji. Wtedy aplikacja musi buforować wpisy i czekać, aż będzie można je wysłać, co wpływa na zużywaną pamięć, skany GC, CPU.
- Podczas chwilowej niedostępności systemu Log Aggregation, część wpisów może być utracona.
 Wysyłanie logów do centralnego systemu Log Aggregator bezpośrednio z aplikacji.
Wysyłanie logów do centralnego systemu Log Aggregator bezpośrednio z aplikacji.2. Agenty monitorujące
Powyższe problemy rozwiązuje podejście Agentów monitorujących pliki logów generowanych przez aplikacje. Agent instalowany jest na tej samej maszynie, gdzie aplikacja i obserwuje pliki logów przez nią generowane. Nie obciążą to w żaden sposób samej aplikacji. Produkuje ona wpisy logów jak dotychczas i dzieje się to niezależnie od działania pracy agenta oraz Log Agregatora.
 Śledzenie plików logów z aplikacji przez agenta i wysyłanie ich do systemu Log Aggregation
Śledzenie plików logów z aplikacji przez agenta i wysyłanie ich do systemu Log AggregationDodatkowo agenty podczas śledzenia wpisów w logu, agenty mogą dodatkowo analizować strukturę linijek i wyciągać z nich dodatkowe metadane pozwalające na lepsze wyszukiwanie treści logów.
3. Sidecar
W systemie uruchamianym w kontenerach agenta, zamiast instalować w systmie hosta, można uruchomić jako dodatkowy kontener – Sidecar – zaraz obok działającego kontenera z aplikacją. Wtedy agent uruchomiony jest w dodatkowym kontenerze, który współdzieli z aplikacją katalog z logami.
 Uruchomienie agenta jako Sidecar container obok działającego kontenera z aplikacją.
Uruchomienie agenta jako Sidecar container obok działającego kontenera z aplikacją.Konkretne systemy Log Aggregator
Jakie systemy Log Aggregator możesz wykorzystać?
- ELK – popularny stos oparty o ElasticSearch (storage) + Logstash & Beats (log forwarding) + Kibana (dashboard)
- Graylog – system centralnego monitoringu, przyjmuje wiele rodzajów inputów, oparty o MongoDB (config), ElasticSearch (storage) i rozproszone konfiguracje agentów.
- Fluentd – data collector z wielu źródeł danych przesyłających dane do różnych baz (np. ElasticSearch, MongoDB, Hadoop, rozwiązań chmurowych).
- Splunk – kompleksowe rozwiązanie do analizy danych, w tym przesyłanie logów aplikacji (przez agenty) do centralnego serwera.
- Oferowane przez Twoją chmurę, np:
- GCP Cloud Logging,
- Amazon CloudWatch Logs,
- Azure Monitor Logs.
Psst… Interesujący artykuł?
Jeżeli podoba Ci się ten artykuł i chcesz takich więcej – dołącz do newslettera. Nie ominą Cię materiały tego typu.
Dziękujemy!
Wysłaliśmy Ci mail powitalny, w którym znajdziesz link do aktywacji newslettera. Do usłyszenia!
Tracing, czyli śledzenie konkretnego żądania
Distributed Tracing to śledzenie żądania w kontekście całego systemu. Analizując tracing zdiagnozujesz na przykład:
- W tym konkretnym przypadku, żądanie do serwisu X spowodowało znaczne opóźnienie.
- W tym przypadku coś stało się z przepustowością sieci, zanim żądanie trafiło z serwisu A do B, wystąpiło opóźnienie.
Gdy żądanie trafia do systemu, generowany jest jego identyfikator TraceId jako identyfikator ścieżki.
Wywoływanie fragmentów kodu mierzone jest w ramach Span-ów, czyli zakresów i określa ono SpanId (z referencją do TraceId), czas początku i czas zakończenia operacji. Mogą być to wywołania serwisów, metod, zapytania do bazy danych.
Span’y mogą być również zagnieżdzane, np. zagnieżdżone wywołania metod, dlatego Span oprócz SpanId posiada również referencję do ParentSpanId.
Wszystkie te informacje:
- TraceId
- SpanId
- ParentSpanId
- (opcjonalnie) tagi, dodatkowe informacje key-value
tworzą tzw. Tracing Context, czyli kontekst wywołania kodu w ramach którego jest mierzony czas wykonywania.
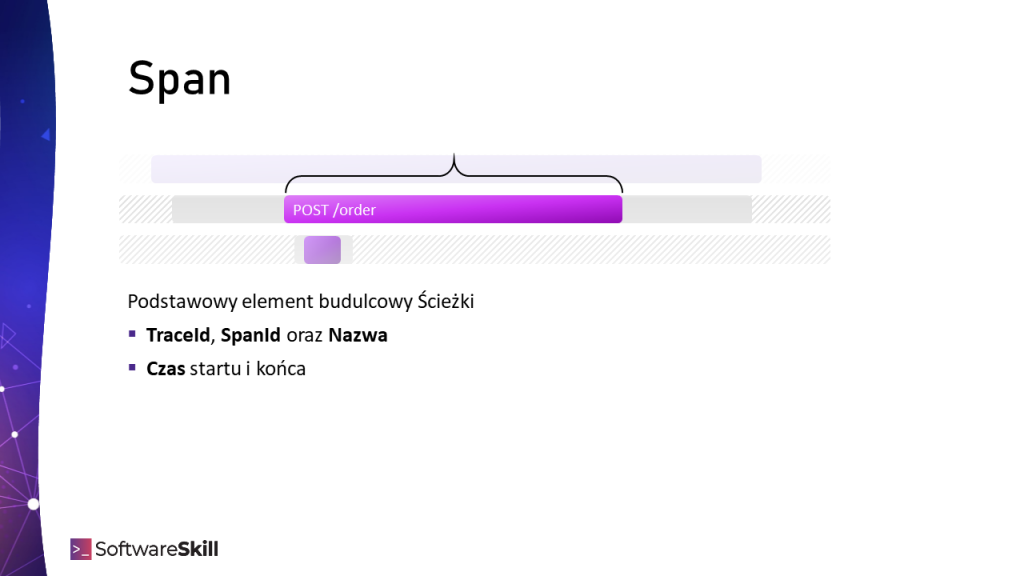 Span (zakres) to podstawowy element budulcowy Trace (ścieżki)
Span (zakres) to podstawowy element budulcowy Trace (ścieżki)Distributed Tracing od zwykłych timerów różni się tym, iż te informacje są wysyłane do centralnego rejestru. Za ich pomocą można wygenerować przebieg czasowy z informacją gdzie dane żądanie (TraceId) oraz jak dużo czasu spędziło w systemie. Przykładowy przebieg w systemie Zipkin:

Na pierwszy rzut oka można stwierdzić:
- Jaki jest przebieg żadania, przez które mikrousługi ono zostało obsługiwane
- Ile czasu żądanie zostało obsługiwane i gdzie
- Ile czasu żądanie spędziło na komunikacji
Aby zmierzyć czas działania danego fragmentu kodu, należy udekorować jego wywoływania startując i zatrzymując Span.
Instrumentacja kodu
Jeżeli w projekcie wykorzystujesz Spring, bardzo dużo pracy zaoszczędzi Ci użycie Spring Cloud Sleuth, który zapewnia wsparcie dla adnotacji @NewSpan, wpiera wykonywanie zadań zaplanowanych @Scheduled, daje wsparcie dla wywołań asynchronicznych @Async (dekorowanie ExecutorService) oraz szereg innych instrumentacji.
Gdy obsługa kodu jest wykonywana przez biblioteki (np. HttpClient, driver bazy danych, itd), należy wykorzystać mechanizm interceptorów, listenerów i innych mechanizmów, które dają biblioteki, aby wpiąć się ze swoim kodem przed i po wywołaniu jakiejś operacji. A czasem choćby nie istnieje taka możliwość i trzeba napisać klasę Proxy, dekorując wywołania przeciążając oryginalne metody.
Tę część pracy wykonali autorzy biblioteki Brave. Zaimplementowali instrumentację kodu wielu popularnych bibliotek w świecie Java, umożliwiając śledzenie wywołań.
Przekazywanie kontekstu śledzenia
Kontekst śledzenia tworzony jest w aplikacji wywołującej dany kod. o ile natomiast chcielibyśmy śledzić zdalne wywołania innego serwisu, kontekst ten będzie niedostępny w pamięci zdalnego procesu.
Dlatego wywołując zdalną procedurę (RPC), składając żądania HTTP lub komunikując się poprzez system kolejkowy, należy przekazać Tracing Context (informację o TraceId, SpanId, ParentSpanId), aby był dostępny w aplikacji, w której śledzenie ma zostać kontynuowane.
Odbywa się to dzięki nagłówków (np. HTTP, JMS). Ich nazwy oraz wartości zostały zdefiniowane przez B3 Propagation Specification.
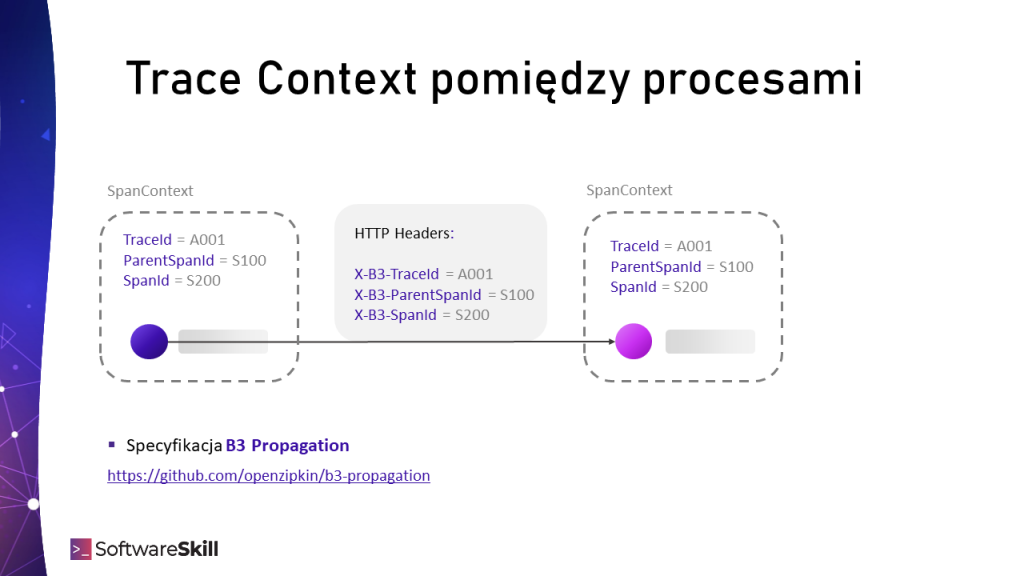 Przekazywanie Trace Context (kontekstu śledzenia) pomiędzy procesami z wykorzystaniem B3 Propagation.
Przekazywanie Trace Context (kontekstu śledzenia) pomiędzy procesami z wykorzystaniem B3 Propagation.Monitoring ogólnej kondycji systemu
Agregowanie logów i Tracing skupia się na pojedynczych wywołaniach systemu. Wartościową informacją jest również dashboard prezentujący ogólną kondycję systemu. Z niego zauważysz, jaki jest zagregowany w danej metryce (średnia, median, percentyl) czas przetwarzania żądań.
Przydatne będą dwa rodzaje dashboardów: ogólny, prezentujący ogólną kondycję systemu (liczba żądań, czasy obsługi, czasy dostępów do zależności) oraz szczegółowy (kondycja danych instancji usługi).
Te dwie perspektywy pozwolą na ewentualną ocenę, czy problem jest globalny, czy z daną instancją.
Używając monitoringu zdiagnozujesz na przykład:
- Od czasu X do Y mieliśmy znacznie pogorszone czasy odpowiedzi z powodu dostępu do bazy danych.
- Przez chwilę odnotowaliśmy większy czas odpowiedzi z serwisu X.
- Od wczorajszego wdrożenia spadły nam czasy odpowiedzi. Musimy zajrzeć, co konkretnie się stało.
- Ta konkretna instancja serwisu odpowiada wolniej, bo maszyna, na której działa ma wysoką utylizację CPU.
Monitoring serwisu – perspektywa ogólna
Perspektywa ogólna powinna zawierać następujące metryki w zagregowanej formie, czyli wartość metryki w przedziale czasowym na podstawie wielu próbek:
- Liczba działających instancji
- Liczba napływających żądań oraz czasy odpowiedzi z danego serwisu (ms)
- Czasy odpowiedzi z zależności, z których korzysta, np. bazy danych, innych serwisów (ms) oraz liczba złożonych żądań do tych zależności (iops)
- Cache hit/miss ratio (%)
Czasy odpowiedzi mogą być wyszczególnione na konkretne instancje, aby móc dotrzeć do wadliwych.
Monitoring instancji – perspektywa szczegółowa
W perspektywie pojedynczej instancji warto umieścić następujące metryki:
- Liczba napływających żądań oraz czasy odpowiedzi z danego serwisu (ms)
- Monitoring środowiska uruchomieniowego:
- % CPU na maszynie i % zużycia przez naszą aplikację
- Zużycie pamięci na maszynie
- Zużycie pamięci przez aplikację z podziałem na generacje pamięci
Czytaj więcej: Obszary pamięci Maszyny Wirtualnej Javy (JVM) - Momenty działania i czasy działania Garbage Collector.
Czytaj więcej: Jak działa Garbage Collector – zarządzanie pamięcią JVM
Metryki mają znaczenie
Stosowane metryki mają znaczenie. Statystyką możesz pokazać prawdę, abo zakłamać rzeczywistość.
- Dla liczby operacji stosuj jednostkę iops (I/O operations per second). Jest to metryka mówiąca ile żądań występuje w jednosce czasu, np. 100/s.
- Dla czasów odpowiedzi staraj się analizować rozkład statystyczny.
- Staraj się nie stosować średniej lub mediany. Te metryki skutecznie ukrywają najgorsze czasy przetwarzania nieco podwyższając średnią ze standardowych wywołąń. Zatem ani nie znasz najgorszych czasów, ani typowych, bo wypłaszcza je średnia.
- Zamiast tego stosuj percentyle. Kwantyle 95, 99, 999 rzędu szeregują wartości roznąco i eksponują najgorsze wartości w zadanym kwantylu.
Podsumowanie
Stosując monitoring na wielu poziomach możesz diagnozować problemy różnej klasy. Daje Ci to szerszą perspektywę na sposób działania systemu, a staje się to szczególnie ważne w dynamicznym, efemerycznym środowisku mikrousług.
- Log Aggregation umożliwi Ci zebranie wszystkich logów w jedno miejsce oraz wygodne ich przeszukiwanie.
- Distributed Tracing pomoże Ci prześledzić, gdzie i jak długo żądanie spędziło czas.
- Monitoring pozwoli Ci na ogólną ocenę kondycji systemu eksponując zagregowane statystyki.
Wpis który czytasz to zaledwie fragment wiedzy zawartej w Programie szkoleniowym Java Developera od SoftwareSkill. Mamy do przekazania sporo usystematyzowanej wiedzy z zakresu kluczowych kompetencji i umiejętności Java Developera. Program składa się z kilku modułów w cotygodniowych dawkach wiedzy w formie video.
Podoba Ci się ten artykuł? Weź więcej.
Jeżeli uważasz ten materiał za wartościowy i chcesz więcej treści tego typu – nie przegap ich i otrzymuj je prosto na swoją skrzynkę. Nawiążmy kontakt.
Dziękujemy!
Wysłaliśmy Ci mail powitalny, w którym znajdziesz link do aktywacji newslettera. Do usłyszenia!
Gdybyś potrzebował jeszcze więcej:
Jesteś Java Developerem?
Przejdź na wyższy poziom wiedzy
„Droga do Seniora” 🔥💪
Jesteś Team Leaderem? Masz zespół?
Podnieś efektywność i wiedzę swojego zespołu 👌
Gdybyś potrzebował jeszcze więcej:
Jesteś Java Developerem?
Przejdź na wyższy poziom wiedzy
„Droga do Seniora” 🔥💪
Jesteś Team Leaderem? Masz zespół?
Podnieś efektywność i wiedzę swojego zespołu 👌
Systemy Log Aggregation służą do przechwytywania i utrwalania logów z wielu źródeł w jednym, łatwo dostępnym miejscu. Gdy logi są dostępne w jednym miejscu, można w łatwy sposób je przeszukiwać. Co więcej, będąc składowane, są dostępne, choćby gdy środowisko uruchomieniowe zostało już wyłączone.
Distributed Tracing to śledzenie żądania i czasu jego wyonywania w kontekście całego systemu. Informacje są wysyłane do centralnego rejestru. Za ich pomocą można wygenerować przebieg czasowy. Gdy żądanie trafia do systemu, generowany jest jego identyfikator TraceId jako identyfikator ścieżki. Span’y mogą być również zagnieżdżone (referencja do ParentSpanId)








