Wszystkie funkcjonalności związane z wytwarzaniem usług ML w chmurze AWS zostały upakowany w jednej usłudze – Sagemaker. Obejmuje ona cały cykl życia projektów ML – od interaktywnego środowiska, śledzenie eksperymentów przez trenowanie i wdrażanie modeli po A/B testy czy interpretację predykcji.
Sagemaker (przynajmniej w czerwcu 2023) to najbardziej dojrzały i bogaty zestaw usług wspomagających tworzenie rozwiązań opartych na uczeniu maszynowym w publicznej chmurze.
Wgryzienie się w tą usługę może przytłaczać na początku, nie jest to tak prosta usługa jak S3 gdzie poznając kilka, może kilkanascie komend obsłużymy 80% naszych potrzeb. Co więcej, łatwo o powierzchowną ocenę (co z resztą sam uczyniłem kilka lat temu), iż Sagemaker to Jupyter Notebook na sterydach w chmurze .
Nic dziwnego, co przecież przyciąga uwagę adeptów data science i ML bardziej niż interaktywne środowisko które jest katalizatorem szybkich szkiców i eksperymentów? Sagemaker oferuje rozbudowane interaktywnego środowisko choćby dostarczając coś na wzór IDE dostępnego z przeglądarki, sęk jednak w tym, iż cała idea i moc Sagemakera kryje się w zdalnym trenowaniu modeli. Pozwala to bowiem rozdzielić środowiska na których konfigurujemy i uruchamiamy trenowanie, od środowiska na którym trenowanie się odbywa.
Seria artykułów
Artykuł ten otwiera również nową serię na blogu gdzie krok po kroku będziemy poznawać Sagemaker, skupiając się na praktycznych aspektach i całym cyklu życia projektów ML.
Również inna pobudka towarzyszyła mi kiedy postanowiłem podzielić się wiedzą z tego obszaru. Poznanie MLOps w AWS i skupienie się na produkcjonalizacji rozwiązań ML było dla mnie trampoliną zawodową.
Przemysł szuka szybkich rozwiązań, krótkiej pętli zwrotnej, a nie modelu który ma 0,0004 mniejszy błąd średniokwadratowy. Korzystając z Sagemakera skracamy czas dostarczenia rozwiązań ML.
Jako iż efektywna nauka celebruje zasadę “od ogółu do szczegółu”, w tym pierwszym artykule z całego cyklu, zapoznasz się z ogólną charakterystyką i powierzchownym opisem poszczególnych funkcjonalności. Pozwoli Ci to na głębsze zrozumienie poszczególnych elementów kiedy będziemy je omawiać w kolejnych wpisach.
Pod tym linkiem znajdziesz mapę myśli którą pomoże nam w nawigacji do kolejnych przystani Sagemakera.
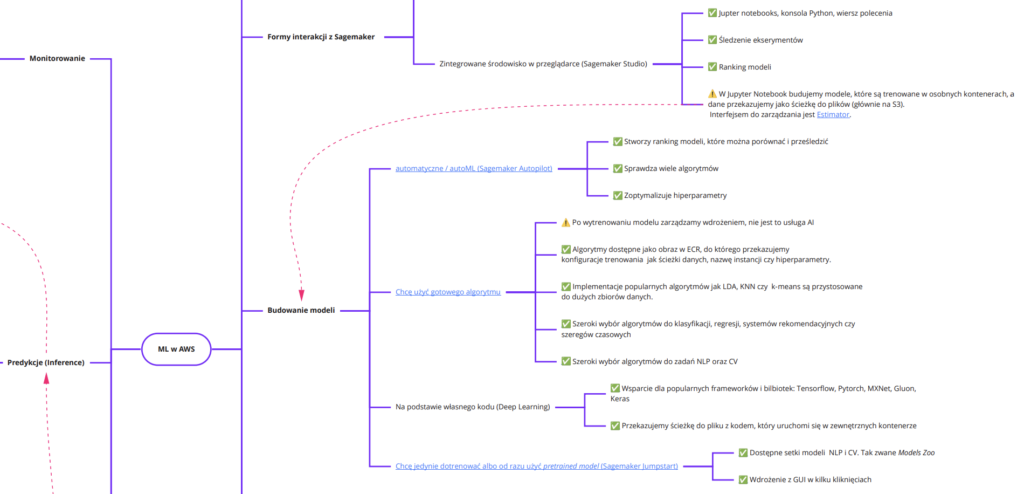 Wycinek mapy myśli ekosystemu ML w AWS
Wycinek mapy myśli ekosystemu ML w AWS - Dlaczego powstał Sagemaker?
- AI vs ML
- Informacje podstawowe
Dlaczego powstał Sagemaker?
Zastanówmy się jeszcze na wstępie, dlaczego w ogóle powstała dedykowana usługa do uczenia maszynowego? Ponieważ tradycyjny soft różni się od MLowego. Trenowanie modeli musi odbywać się na zdalnym środowisku, potrzebujemy śledzić eksperymenty, wersjonować modele, interpretować predykcje w czasie rzeczywistym. Pisałem o tym szczegółowo tutaj.
Oczywiście, firmy typu ZosiaSamosia uważają iż wdrażanie oprogramowanie self-hosted na przykład do zarządzania modelami jest lepszym pomysłem. W praktyce okazuje się jednak w większości przypadków nie ma sensu wymyślać koła na nowo.
AI vs ML
Zanim jeszcze do samego Sagemakera, chciałbym Ci wyjaśnić jak terminy “ML” i “AI” rozumie AWS. W zależności od kontekstu AI i ML są różnie traktowane. Czasem to synonimy, czasem ML to podzbiór AI. Całe szczęście, Amazon ma jasny podział w swojej taksonomii.
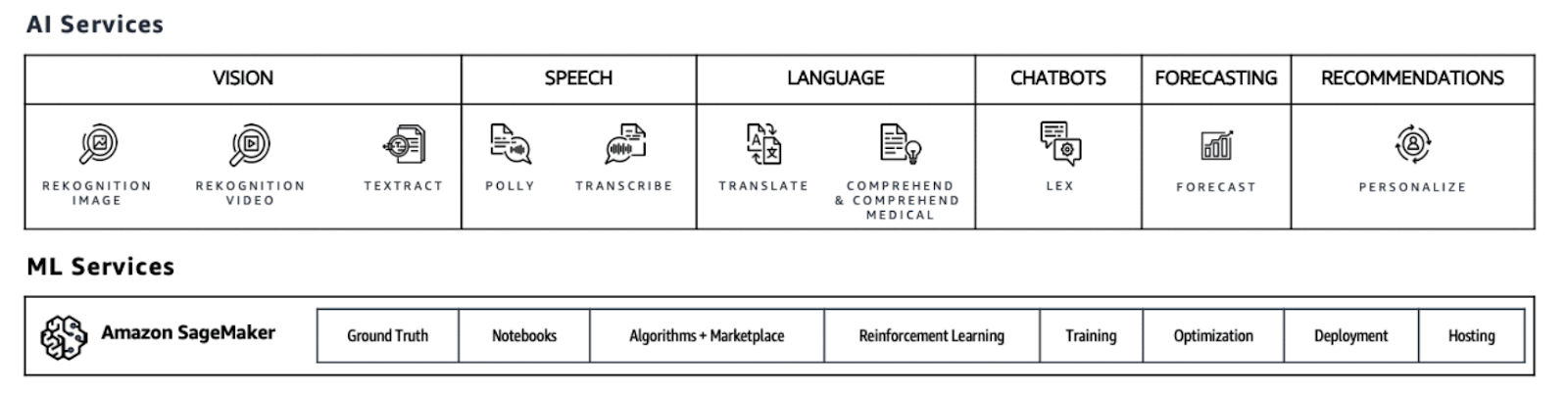
Usługi AI realizują typowe zadania sztucznej inteligencji poprzez komunikację z API. Wystarczy wysłać zapytanie sieciowe, aby zidentyfikować emocje osoby na zdjęciu czy wideo, przetłumaczyć esej, czy transkrybować mowę na tekst. Aby korzystać z tych usług, nie jest wymagana żadna wiedza związana z uczeniem maszynowym.
Usługi ML to narzędzia do budowania, trenowania, strojenia, wdrażania i monitorowania modeli “at scale”, czyli to do czego Sagemaker został stworzony. To nie wszystko, Sagemaker oferuje pomoc na jeszcze niższym poziomie abstrakcji. Ułatwia pracę związaną z infrastrukturą i frameworkami głębokiego uczenia maszynowe. Rozwiązuje takie problemy jak optymalizacja procesu trenowania poprzez szeroki wybór instancji obliczeniowych, udostępnia interfejs pozwalający dostarczyć własny algorytm, czy wdrażać na urządzenia brzegowe.
Informacje podstawowe
Sagemaker powstał pod koniec 2017 roku, więc to stosunkowa młoda usługa na tle ponad dwustu pozostałych w AWS.
Można się z nim komunikować na cztery sposoby. Oprócz trzech podstawowych dostępnych dla każdej usługi, jak konsola webowa, pakiet CLI i AWS SDK dostępnego w wielu językach, mamy jeszcze do wyboru dedykowane SDK Sagemeker, ale wyłącznie w języku Python.
W kolejnych artykułach, będziemy korzystać ze wszystkich możliwości, głównie natomiast z SDK Sagemaker.
Sagemaker nieodłącznie jest związany z innymi usługami.
S3 – poza kilkoma wyjątkami, to miejsce składowania danych dane treningowych. Również same modele, jako wynik trenowania również zapisywane są tutaj.
ECR (Elastic Container Registry) to kolejna usługa z którą Sagemaker jest ściśle powiązany, bowiem każde żądanie o uruchomienie trenowania wymaga podania nazwy obrazu który zawiera w sobie między innymi implementację algorytmu uczenia maszynowego, czy serwer uruchamiany na etapie predykcji.
Sagemaker (jak z resztą jego odpowiedniki w GCP i Azure) został zaprojektowany z myślą o MaaS (model-as-a-service) . Oznacza to iż model jest opakowany w usługę, która może być wdrożona niezależnie od aplikacji konsumujących. Przeciwnym podejściem jest model wbudowany (embedded model), w którym traktujesz artefakt modelu jako zależność, która jest budowana i pakowana w ramach aplikacji konsumujące. Więcej rozważań na ten temat poruszymy podczas omawiania metod wdrożenia modeli.
Czas aby opisać możliwości Sagemakera. W miarę możliwości, są one uporządkowane według cyklu życia modelu.
Nasz rekonesans zaczniemy od interaktywnego środowiska, ale tylko dlatego iż jest wykorzystywane na pierwszych etapach projektu ML. Jak się później przekonasz, inne funkcjonalności są bardziej spektakularne.
Udostępnij ten wpis
Dobrnąłeś do końca. jeżeli ten artykuł był dla Ciebie wartościowy i chcesz otrzymywać informacje o kolejnych, to zapraszam Cię do zapisania się do listy mailingowej. Gwarantuję zero spamu.
Radek.
Inne artykuły
FastAPI background task – nie przeciągaj czasu odpowiedzi

Rozwijasz czy produkujesz oprogramowanie?

Lean software development – eliminacja strat

CD4ML: Continuous delivery for machine learning

Dlaczego warto pisać? Jak pisać?