Wprowadzenie: czym jest predykcyjne utrzymanie ruchu i dlaczego staje się standardem
W tradycyjnym podejściu utrzymanie ruchu miało charakter reaktywny – naprawiano maszynę dopiero wtedy, gdy już doszło do awarii. W lepszym przypadku wdrażano prewencyjne przeglądy, oparte na harmonogramie (np. co 500 godzin pracy).
Dziś jednak coraz więcej zakładów przechodzi na predykcyjne utrzymanie ruchu (PdM), które wykorzystuje dane, sztuczną inteligencję i uczenie maszynowe, aby przewidywać awarie z wyprzedzeniem.
Predykcyjne utrzymanie ruchu to nie tylko analiza danych historycznych – to ciągły proces monitorowania, w którym modele ML uczą się, jak wygląda „zdrowa” praca maszyny i wykrywają odstępstwa w czasie rzeczywistym.
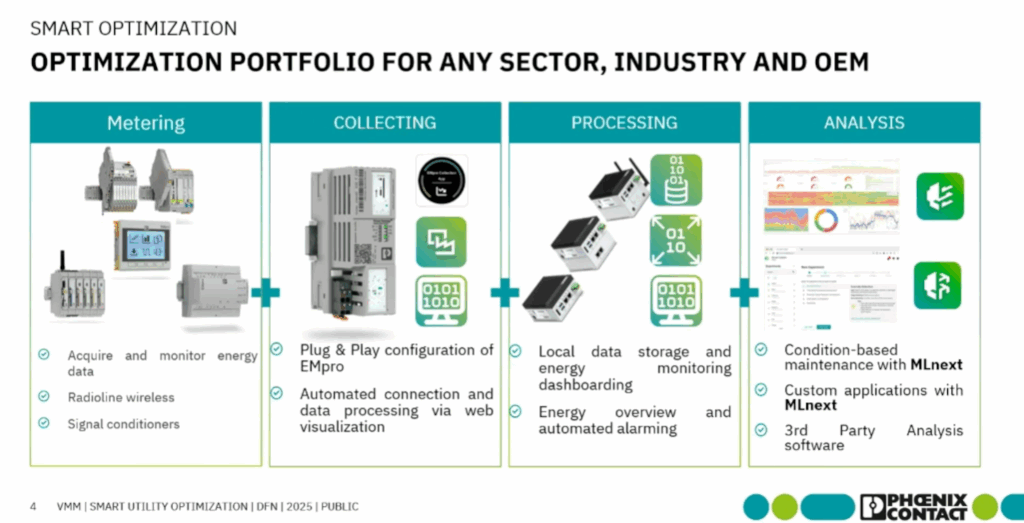
Jednym z najciekawszych i najbardziej praktycznych narzędzi do tego typu zastosowań jest MLnext – otwarte środowisko opracowane przez Phoenix Contact, które pozwala łatwo wdrożyć analitykę AI w środowisku przemysłowym (np. w maszynie lutowniczej, prasie, zgrzewarce, sprężarce itp.).
Architektura systemu MLnext (Docker)
MLnext składa się z lekkiego zestawu kontenerów Docker, które tworzą kompletny pipeline AI:
- MySQL – baza danych pomiarów i wyników AI
- Adminer – interfejs www do przeglądania danych
- Grafana – wizualizacja trendów i alerty
- Generator – symulacja danych (jeśli brak realnego źródła)
- MLnext Execution – silnik AI odpowiedzialny za trenowanie i predykcję
- CodeMeter – zarządzanie licencją
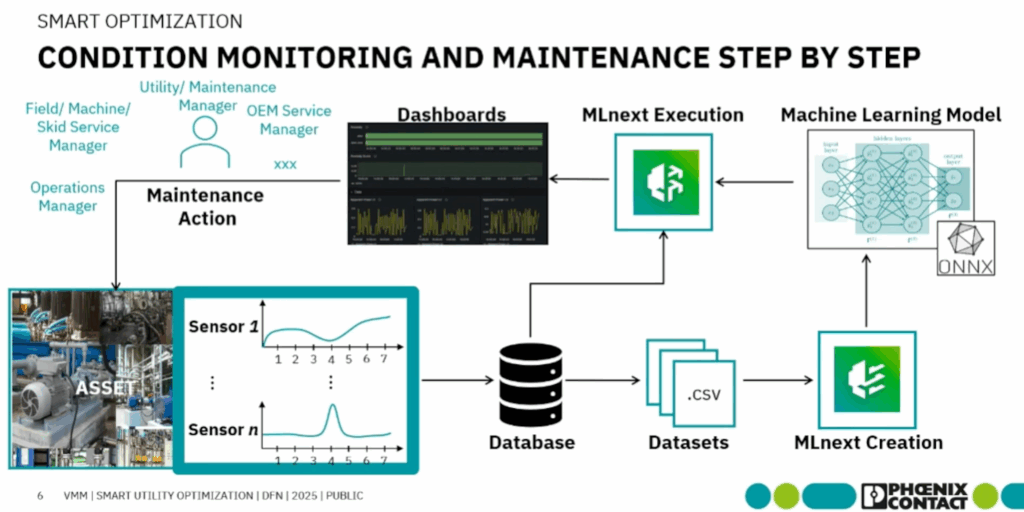
Dane z maszyn (np. przez MQTT, Modbus, OPC UA) trafiają do bazy MySQL. MLnext przetwarza je, a Grafana pokazuje wyniki w czasie rzeczywistym.
Jak MLnext przewiduje awarie
Silnik MLnext uruchamia cyklicznie tzw. Periodic Job. Co kilka sekund pobiera nowe dane, przetwarza je i wykonuje predykcję.
W modelu typu Variational Autoencoder (VAE) uczony jest wzorzec poprawnej pracy maszyny. Następnie porównywane są wartości rzeczywiste z przewidywanymi – im większa różnica (tzw. błąd rekonstrukcji), tym większe prawdopodobieństwo anomalii.
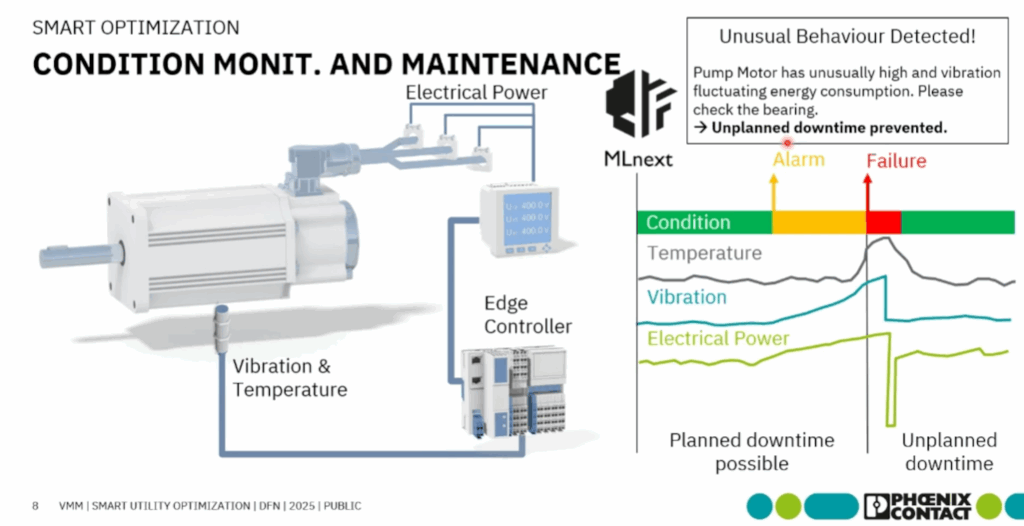
Ten mechanizm działa jak cyfrowy stetoskop:
- mały błąd rekonstrukcji → maszyna pracuje normalnie,
- rosnący błąd → proces zaczyna się zmieniać (np. zużycie komponentu),
- nagły skok błędu → potencjalna awaria lub zakłócenie.
Case study: maszyna lutownicza
Dla przykładu przyjrzyjmy się maszynie lutowniczej, w której MLnext monitoruje 18 parametrów w czasie rzeczywistym:
| Grupa pomiarowa | Parametry |
| Napięcie | Voltage L1, L2, L3 |
| Prąd | Current L1, L2, L3 |
| Moc czynna/bierna/pozorna | Real, Reactive, Apparent Power (L1–L3) |
| Współczynnik mocy | Power Factor L1, L2, L3 |
Na tej podstawie MLnext tworzy model normalnej pracy lutownicy i zapisuje pary: np. Current_L1 oraz Current_L1_recon. W Grafanie użytkownik widzi oba wykresy i może natychmiast zauważyć, gdy rekonstrukcja (czyli przewidywanie) znacząco odbiega od rzeczywistego pomiaru.
Co oznaczają konkretne odchylenia
| Obserwacja | Możliwa przyczyna | Działanie prewencyjne |
| Wahania napięcia L2 > ą5% | Luźne styki / zasilacz fazowy | Sprawdź połączenia i przewody |
| Spadek współczynnika mocy | Zwiększona indukcyjność obciążenia | Weryfikacja kompensacji mocy |
| Różnice między prądami L1/L2/L3 | Nierównomierne obciążenie / uszkodzenie grzałki | Inspekcja grzałki lub grotu |
| Nagłe piki prądu | Zatarcie mechaniczne lub zanieczyszczenie | Czyszczenie i smarowanie układu |
| Stopniowy wzrost błędu MSE | Postępujące zużycie komponentu | Zaplanować przegląd prewencyjny |
Analiza i alerty w Grafanie
MLnext zapisuje dane w bazie MySQL, z której Grafana pobiera je w postaci zapytań SQL.
Przykładowe obliczenie błędu (Mean Squared Error) dla trzech faz:
Jeżeli mse > 0.5 przez dłuższy czas – system generuje alert w Grafanie.
Alert można wysłać:
- e-mailem (SMTP),
- SMS-em (np. przez webhook API),
- na komunikator (Teams, Slack, Telegram).
Integracja z utrzymaniem ruchu
Predykcyjne utrzymanie ruchu z MLnext pozwala nie tylko unikać awarii, ale też planować serwis w sposób optymalny.
Zamiast wymieniać komponent „na wszelki wypadek”, można to zrobić w momencie, gdy model zauważy rzeczywiste oznaki zużycia.
To zmniejsza:
- liczbę nieplanowanych przestojów choćby o 30–50%,
- koszty części i serwisu o 20–30%,
- liczbę interwencji awaryjnych.
Dodatkowo – wszystkie dane są zapisywane w jednym miejscu (MySQL) i wizualizowane w Grafanie, co ułatwia analizę trendów i raportowanie.
Dlaczego AI i Machine Learning zmieniają utrzymanie ruchu
W erze Przemysłu 4.0 dane z czujników nie mogą być tylko archiwizowane — muszą pracować dla nas.
AI i uczenie maszynowe pozwalają wykrywać mikro-odchylenia, których człowiek nie zauważy, oraz łączyć korelacje pomiędzy setkami sygnałów.
Dzięki takim rozwiązaniom:
- operatorzy reagują zanim wystąpi awaria,
- planista UR otrzymuje rekomendacje oparte na danych,
- kierownictwo ma mierzalny ROI z inwestycji w AI.
Właśnie dlatego predykcyjne utrzymanie ruchu i narzędzia takie jak MLnext będą jednym z kluczowych trendów przemysłowych w tej dekadzie.
Podsumowanie
MLnext to gotowa platforma do wdrożenia predykcyjnego utrzymania ruchu w praktyce.
Dzięki prostemu wdrożeniu (Docker), otwartym narzędziom (Grafana, MySQL) i wbudowanym modelom AI (VAE), pozwala firmom przemysłowym:
- monitorować najważniejsze parametry maszyn,
- przewidywać awarie,
- automatycznie generować alerty i raporty,
- planować konserwacje na podstawie danych, a nie kalendarza.
To realny krok w stronę inteligentnej fabryki i utrzymania ruchu 5.0.
Chcesz wiedzieć więcej odnośnie Machine Learning oraz technologii MLnext?
Sprawdź nasz Kurs Automatyki i Programowania PLC ze Sztuczną Inteligencją AI