Witam w kolejnym wpisie z serii „Myszkowanie w Monitorze i kopanie w KRS-ie” :smile:
Jeśli jeszcze tej serii nie znacie: patrzę tutaj na publicznie dostępne polskie źródła informacji na temat spółek. Stopniowo rozwijając własne metody ich analizowania i dzieląc się na blogu ciekawostkami.
Dotychczas poświęcałem łamy bloga głównie Krajowemu Rejestrowi Sądowemu. To oficjalna polska baza z informacjami o spółkach (tych większych, od jawnej wzwyż, bo od mniejszych działalności jest CEIDG).
Czas na zmiany. Tym razem spojrzę na drugie ważne źródło informacji – Monitor Sądowy i Gospodarczy. Zobaczymy, w jaki sposób można zbierać Monitory i wstępnie spojrzymy do ich metadanych (ogólnych informacji na temat plików, nie wymagających ich dokładnego przetwarzania).
Spoiler: będzie w nich parę ciekawostek.
Jak zwykle stosuję język potoczny, spółki nazywam czasem firmami itd. To świadoma decyzja.
Motywacja
Dlaczego nie zewnętrzne platformy
W poprzednich wpisach nieraz podkreślałem, iż KRS się przydaje, ale pobieraniem pojedynczych odpisów nie zawojujemy świata. Bowiem nie dałyby nam pełnego obrazu powiązań między firmami. Nie zobaczymy na przykład, iż firma A, którą właśnie oglądamy, kieruje też firmami B i C.
Najszybszym sposobem na uzupełnienie tej luki byłoby skorzystanie z jakiejś strony udostępniającej informacje na temat firm. A jest ich trochę: rejestr.io, infoveriti.pl, aleo.com…
Tylko iż korzystanie z komercyjnych platform wiąże się z paroma niedogodnościami:
-
Dostęp do danych historycznych zwykle jest płatny.
Gdybyśmy chcieli zobaczyć, w jakich firmach miała swoje udziały pewna osoba – ale już nie ma – to musielibyśmy zapłacić. A wtedy zostałoby nam mniej na ziemniaczki i cebulę w tych ciężkich czasach.
-
Trzeba zaufać ich danym.
Musimy wierzyć im na słowo, iż pokazywane dane są spójne i prawdziwe.
A przecież błędy się zdarzają; format danych może się nie zgadzać, jedna spółka przez literówkę będzie traktowana jak dwie itd. Pomijając już fakt, iż niektórzy mogą się dobijać, żeby ich firmę z bazy usunąć. -
Nie mamy pełnej swobody.
Korzystając z gotowych platform, możemy jedynie korzystać z narzędzi, jakie nam udostępnili. A co, jeżeli mamy pomysł na jakąś nietuzinkową analizę albo wizualizację? Pozostaje negocjowanie dla siebie specjalnych warunków.
W ten sposób doszedłem do wniosku, iż tylko zdobycie danych u samego źródła da mi pełną wolność.
Dlaczego Monitor
„U samego źródła”… Tylko co nim jest? W Polsce informacje o spółkach są rozrzucone po kilku bazach. Główną jest KRS, ale jednak wybrałem Monitor. Dlaczego?
Najpierw krótko przypomnę różnice między dokumentami z KRS-u (odpisami) a egzemplarzami Monitora.
- Jeden odpis z KRS-u pokazuje wszystkie wydarzenia z całego okresu życia jednej konkretnej firmy.
- Jeden egzemplarz Monitora pokazuje wszystkie wydarzenia z dość krótkiego okresu czasu (do kilku dni) dla wszystkich firm w Polsce .
Dla wzrokowców mam nieco bidny schemat zrobiony w LibreOffice Calc:
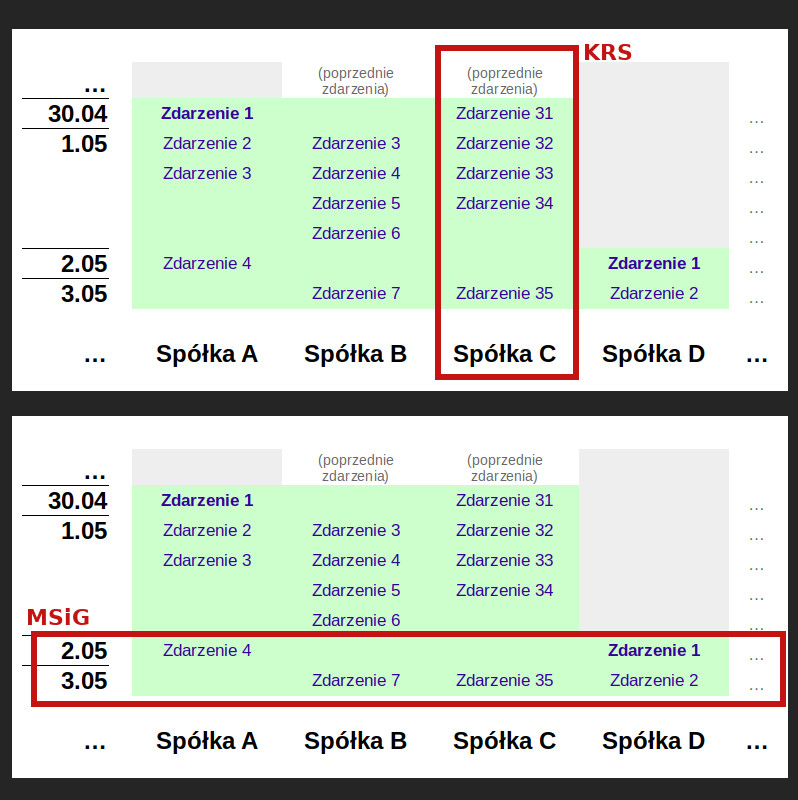
Gdybyśmy chcieli mieć wszystkie zdarzenia dla wszystkich spółek, musielibyśmy zebrać całą tabelkę. Można to zrobić na dwa sposoby:
- „kolumnami” – pobrać odpisy KRS dla wszystkich istniejących firm,
- „wierszami” – pobrać wszystkie egzemplarze Monitora.
Natomiast, gdybyśmy oprócz tego chcieli być na bieżąco, opcja z KRS-em byłaby niekończącą się walką z wiatrakami. Każdego dnia dzieje się coś nowego. Zatem każdego dnia musielibyśmy pobierać tysiące odpisów. Z których tylko niewielka część zawierałaby coś nowego.
Dlatego Monitory uznałem za lepsze rozwiązanie, jeżeli chcę trzymać rękę na pulsie (a chcę). I to na nich skupiłem uwagę.
Gdzie i jak zdobyć Monitory
Wszystkie Monitory można pobrać ze strony Ministerstwa Sprawiedliwości. Natomiast nie jest to szczególnie przyjemne.
Kiedy klikniemy na link do wybranego Monitora, pojawia się Captcha – zdjęcie tekstu, który trzeba przepisać do pola, żeby pobrać plik. Zabezpieczenie przed automatycznym pobieraniem.
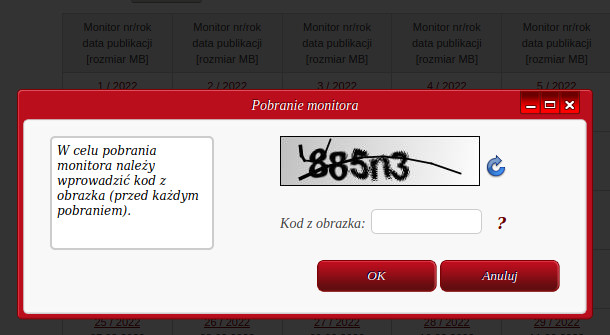
I nie byłoby tu problemu, gdyby nie kilka dość irytujących zachowań strony:
- Pole tekstowe nie skupia się automatycznie; za każdym razem trzeba je kliknąć, zanim zaczniemy wpisywać tekst.
- Okno nabiera ostrości powoli, przez kilka sekund. jeżeli klikniemy za wcześnie, zanim skończy się ta animacja, to… pobierzemy ponownie poprzedni plik zamiast tego w tej chwili klikniętego.
- Nie da się potwierdzić wpisanej Captchy naciśnięciem klawisza; trzeba wziąć myszkę i kliknąć OK.
Dodajmy do tego sam fakt, iż każdego roku wydawanych jest ponad 200 Monitorów. Chcąc zebrać kolekcję z wielu lat, mamy przed sobą strasznie dużo klikaniny.
Być może osoba kontaktowa mogłaby napisać prośbę o przesłanie wszystkich Monitorów, z pominięciem Captchy? Powołując się na przykład na prawo dostępu do informacji publicznej?
To jednak wymagałoby kontaktu z ludźmi. Rozwiązanie dość sprzeczne z etosem piwniczaków.
Ktoś skryptowy mógłby z kolei użyć biblioteki pynput, napisanej w Pythonie i pozwalającej kontrolować mysz oraz klawiaturę.
W ten sposób dałoby się rozwiązać problemy 1 i 3 – podpiąć ruchy i kliknięcia myszki pod klawiaturę. Osoba pobierająca tylko by przepisywała tekst i naciskała ustalony klawisz, a mysz sama by przeskakiwała i klikała co trzeba.
Jest też rozwiązanie dla przodowników pracy. Cierpliwie klikać nazwę Monitora, pole tekstowe, wpisywać kod, klikać OK. I tak setki albo tysiące razy. Żeby nie oszaleć, można sobie puścić w tle muzykę.
Którą opcję wybrałem? Tajemnica :wink: W każdym razie zdobyłem interesujące mnie Monitory. Od egzemplarza nr 1 z 2014 roku do egzemplarza nr 73 z roku 2022. Dałoby się więcej, ale nie czułem potrzeby. Poza tym starsze egzemplarze mają problemy, o których kiedyś wspomnę.
Łącznie 2066 plików. Zobaczmy teraz, co można z nich odczytać.
Myszkowanie w metadanych
Metoda
Aby zajrzeć do informacji zawartych w plikach, użyłem niezawodnego programiku konsolowego pdfinfo. To część Popplera, większego zbioru programów do pracy z plikami PDF.
Kiedy użyjemy pdfinfo na jakimś pliku, wyświetli nam jego metadane. Zestaw ogólnych informacji, takich jak autor, program użyty do stworzenia pliku, data stworzenia, data modyfikacji:
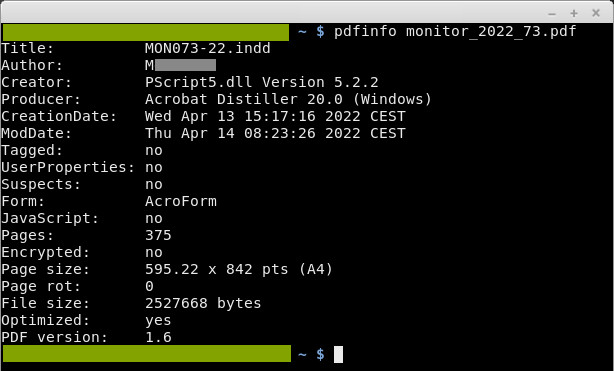
Wyniki z pdfinfo. Format NazwaPola: Wartość.
Druga sprawa: liczenie tych informacji, żeby znaleźć jakieś ogólne trendy. W tym celu stworzyłem sobie skrypt Pythona, odwołujący się do pdfinfo za kulisami. A że bardzo lubię ideę open source – proszę bardzo, oto on.
- instalowanie Pythona i używanie skryptów
Skrypt wymaga zainstalowania Popplera, a przynajmniej programu pdfinfo. W razie czego: to kwestia dosłownie pobrania jednego pliku i umieszczenia go w odpowiednim folderze.
Skrypt sam wyświetla instrukcje, więc mam nadzieję, iż każdy by sobie poradził ![]()
Instrukcja korzystania: umieszczamy w tym samym folderze co pliki PDF, odpalamy (podwójnym kliknięciem / przez IDLE / przez konsolę...). Gdyby coś nie działało, to powinien nas poinformać.
Niektóre możliwości są dopasowane do Monitorów i bezużyteczne poza nimi (między innymi ustalanie daty rocznej na podstawie nazwy pliku). Natomiast sam program może się sprawdzić jako ogólne narzędzie do przeglądania i liczenia metadanych z PDF-ów.
Odsiew
Nie wszystkie informacje z pdfinfo były dla mnie cenne. Niektóre z nich były identyczne dla wszystkich plików, więc je odsiałem.
Były wśród nich pola takie jak:
-
JavaScript
(niektórych może zaskoczyć, ale tak, w plikach PDF można osadzać interaktywny kod. W Monitorach go na szczęście nie było). -
Form
(dla każdego wartość AcroForm, czyli domyślny standard od firmy Adobe). -
Tagged
(czy plik zawiera również dane na temat struktury; żaden z Monitorów ich nie ma, co jest złą wieścią dla szperaczy, archiwistów lub niewidomych korzystających z opcji czytania tekstu).
Kolejna sprawa – ignorowałem informacje, które dla niemal każdego pliku były inne. Pola: Pages, File size, CreationDate, ModDate.
Daty mogłyby być źródłem ciekawych informacji (na przykład na temat odstępów między pierwszą a ostatnią edycją; godzin pracy), ale na chwilę obecną odpuściłem. jeżeli kiedyś do nich wrócę, edytuję wpis.
Zostaliśmy z polami, których wartości były urozmaicone, ale nie do przesady. Natomiast niektóre z nich były dla mnie mniej ciekawe.
Oto one. Kolejno mamy tu wartość, liczbę jej wystąpień w naszych PDF-ach, pierwszy i ostatni rok wystąpienia.
Pole Optimized:
"no": 448 (lata 2014-2021)
Pole PDF version:
"1.5": 432 (lata 2014-2017)
Na podstawie tych pól można przypuszczać, iż pliki były tworzone przy użyciu różnych programów i ustawień – wersja i optymalizacja to zwykle coś raz włączonego lub nie, przy czym się nie gmera.
Dałbym plusika twórcom Monitorów za trzymanie się jednej wersji formatu PDF (1.6) od roku 2017 oraz wyłącznie zoptymalizowanych PDF-ów od 2021.
Nawet jeżeli to małe różnice dla czytelnika, to przynajmniej świadczą o nieco bardziej jednolitym zapleczu technicznym.
Wyłapywanie trendów
Patrząc na dane z dwóch kategorii – Author i Producer (program użyty do stworzenia pliku) – można wyłapać pewne trwalsze zmiany za kulisami. Pokazujące, iż do roku X było tak, a od roku X – inaczej.
Spójrzmy na pole Producer (wartości częstsze):
"AD 20.0 (Windows)": 273 (lata 2020-2022)
"AD 21.0 (Windows)": 245 (lata 2021-2022)
"AD 19.0 (Windows)": 145 (lata 2018-2020)
"AD 18.0 (Windows)": 72 (w roku 2018)
"AD 9.0.0 (Windows); modified using iText 2.1.7 by 1T3XT": 27 (lata 2014-2016)
"AD 22.0 (Windows)": 5 (w roku 2022)
Miażdżącą większość mają w tej kategorii różne wersje programu Acrobat Distiller (skróciłem go do AD):
Możliwe, iż sam Distiller nie był programem, w którym pracowano, ale wyłącznie tym użytym do stworzenia pliku – a głównym mógł być np. InDesign, używający AD za kulisami.
Liczba po AD to każdorazowo wersja programu. Można zauważyć, iż przez długi czas korzystano tylko ze starej wersji 9.0.0. Pierwsze próby korzystania z nowszych wersji widzimy w 2018 roku, a dopiero w 2020 ostatecznie z nią skończono.
Wersja 9.0.0 przetrwała w Ministerstwie całkiem długo, patrząc na to, iż to program najpóźniej z 2009 roku. Ustalenie dokładnych dat dla różnych wersji AD zostawiam bardziej wytrwałym czytelnikom.
Kolejna sprawa: obecność w niektórych polach tekstu modified using iText 2.1.7 by 1T3XT. iText jest całkiem niezależną biblioteką do obróbki PDF-ów. Może to sugerować, iż w plikach stworzonych narzędziami Adobe coś trzeba było poprawić i użyto właśnie iT.
Wnioski płynące z używanych wersji są raczej na plus – jeżeli uznamy korzystanie z nowszych wersji za oznakę bycia na bieżąco, to od okolic 2020 roku się za to wzięli.
Kolejne pole – Author (wartości częstsze):
"M█████████": 759 (lata 2014-2022)
"Agnieszka.J█████████": 171 (lata 2020-2022)
"T█████████": 164 (lata 2020-2022)
Nazwiska zakryte przez mnie; liczbę liter pod zakrytymi prostokątami nieco zmieniłem.
Jeśli komuś się robi nieswojo na widok tych danych, spieszę uspokoić. Samo Ministerstwo wydaje się nie robić z nazwisk tajemnicy.
W niektórych Monitorach znajdziemy informacje o tym, kto podpisał cyfrowo dany plik. Wskazujące tę osobę z imienia i nazwiska. Bezpośrednio na stronach dokumentu.
Co nie zmienia faktu, iż lekko by mnie mroziła wizja, iż jakiś nawiedzony byznesmen ustali moje dane i będzie się dobijał na moją prywatną skrzynkę, żebym nie publikował informacji o jego upadłości. No ale przyjmijmy, iż w Ministerstwie wiedzą co robią.
A teraz popatrzmy na daty przy poszczególnych osobach. Mówią nam sporo.
Jedna z osób, na M., ma bardzo długi staż przy tworzeniu Monitorów, trwający do teraz.
Z kolei na miejsce osoby o nazwisku R., która opracowała ich najwięcej ze wszystkich, w 2020 roku weszły dwie nowe osoby. Pracują mniej więcej po równo, jeżeli patrzeć na liczbę Monitorów.
Metadane w roli komunikatów o zmianach kadrowych? Zdziwiłbym się, ale lata czytania o różnych cyfrowych sprawach mnie znieczuliły :wink:
Wyłapywanie anomalii
Oprócz opisanych wyżej poszlak zdradzających nam, co się na zapleczu działo, mamy trochę informacji odstających od reszty. I to w całkiem różnych kategoriach.
Niektóre wartości zaznaczyłem kolorem; wrócimy do nich jeszcze.
Page Size:
"595.22 x 842 pts (A4)": 742 (lata 2017-2022)
"595.276 x 841.89 pts (A4)": 3 (w roku 2020)
Creator:
"Adobe InDesign CS6 (Windows)": 2 (w roku 2020)
"Adobe InDesign 15.0 (Windows)": 1 (w roku 2020)
Author (wartości rzadsze):
"r█████████": 2 (lata 2017-2019)
"Mateusz.R█████████": 1 (w roku 2022)
"K█████████": 1 (w roku 2017)
Pole BRAK DANYCH oznacza, iż w wynikach z pdfinfo w ogóle nie było takiego pola.
Producer (wartości rzadsze):
"Adobe Acrobat Pro DC 19.21.20061": 1 (w roku 2020)
"Adobe PDF Library 15.0": 1 (w roku 2020)
"Acrobat Distiller 10.1.16 (Windows)": 1 (w roku 2017)
 Ciekawostka
Ciekawostka
Jeśli spojrzymy na najczęstszą wartość pola Creator, zobaczymy PScript(…).dll.
Pierwsze słowo odnosi się prawdopodobnie do PostScriptu, czyli języka złożonego z krótkich komend opisujących jak stworzyć dokument. Zwykle ukrytego za kulisami.
Rozszerzenie dll sugeruje z kolei, iż to nie jakiś program graficzny, w którym sobie pracujemy, tylko bardziej narzędzie wykorzystywane przez inne programy. Trochę jak pdfinfo przez mój skrypt.
Wniosek: skróty i nazwy potrafią wiele ujawniać, jeżeli poświęci się czas na ich poznanie.
Niektóre wiersze oznaczyłem czerwonym kolorem. A to dlatego, iż anomalie chodzą grupami – wszystkie te nietypowe wartości pochodzą z trzech plików:
- monitor_2020_22.pdf
-
monitor_2020_23.pdf
(oba stworzono przy użyciu kombinacji Adobe InDesign CS6 + Adobe PDF Library 10.0.1)
-
monitor_2020_59.pdf
(stworzony kombinacją Adobe InDesign 15.0 + Adobe PDF Library 15.0)
W żadnym z tych trzech plików nie było w ogóle pola Author, a ich strony miały wymiary 595,276 x 841,89 jednostek.
Widzimy tu interesujący detal – zdarza się, iż jeden atrybut (tu: liczba po przecinku w rozmiarze stron) jest mocno sprzężony z konkretnym programem. Na podstawie jego wartości dałoby się zawęzić listę programów, jakie mogły posłużyć do stworzenia pliku.
Jeśli chodzi o pozostałe anomalie:
-
monitor_2020_28.pdf
Był jedynym monitorem stworzonym przy użyciu programu Adobe Acrobat Pro DC 19.21.20061. Wyróżniał się też pustym polem Title, który zwykle zawiera nazwę dokumentu źródłowego. Wszystko inne dość typowe – autorem osoba na M., z najdłuższym stażem w tworzeniu.
-
monitor_2017_244.pdf
Jedyny, którego autorem była osoba na K., zaś programem użytym do stworzenia – Acrobat Distiller 10.1.16. Zwykle wersje Distillerów były bardziej „okrągłe”.
-
monitor_2022_69.pdf
Jedyny, którego autorem był Mateusz R. Reszta danych typowa.
To względnie nowy Monitor, więc możliwe, iż to wcale nie anomalia, a pan M.R. jeszcze zagości wśród autorów.
Wśród autorów dwa razy pojawia się również osoba na r (z małej litery).
To dokładnie to samo nazwisko, które odpowiada za największą liczbę Monitorów. Tylko iż zapisane małymi literami.
Nie mam doświadczenia z programami od Adobe, ale jeżeli są dość podobne do innych biurowych, to nazwą autora jest zwykle nazwa użytkownika ustawiona w komputerze – jak admin, Gość albo chociaż Tata, jak u jednego mojego wykładowcy.
Jeśli przyjmiemy, iż tak jest też w Ministerstwie, zaś autorzy nie uzupełniają pola Autor samodzielnie, to oznaczałoby, iż te dwa dokumenty mogły zostać stworzone przez panią R. na innym komputerze niż zwykle. Były nimi:
W ten sposób otrzymaliśmy listę ośmiu nietypowych PDF-ów, z których aż połowę stworzono w 2020 roku. Czyżby pandemia zasiała mały chaos?
Na razie nie wiem, czy ta wiedza mi się do czegokolwiek przyda. Ale kolejnym etapem będzie zaglądanie do treści Monitorów. Być może nietypowe pliki wyróżnią się także pod innymi względami.
Podsumowanie
Dane to potęga. Metadane mogą być jeszcze większą – bo mało kto o nich wie. Ludzie beztrosko przenoszą pliki między komputerami, edytują, wysyłają.
A metadane się gromadzą – gotowe zdradzić, kto i w jakich godzinach pracował nad plikiem, ilu autorów ma organizacja, jakiego używa sprzętu.
W przypadku Monitorów dane są nieszkodliwe. Raczej.
Zebrałbym się wręcz na odrobinę optymizmu i powiedział, iż trochę im się za kulisami poprawiło. Mają coraz nowsze programy, od pewnego czasu aktualizują wersje na bieżąco.
Na plus również to, iż wydają się korzystać z tradycyjnych, nieinternetowych wersji programów. Dzięki temu, gdyby Adobe kiedyś odcięło Polskę od swoich usług (jak Wenezuelę), to przez cały czas moglibyśmy tworzyć nasze piękne Monitory.
A my, jako osoby fizyczne? Też możemy z tego wpisu wyciągnąć nauczkę.
Warto o metadanych wiedzieć i je czyścić. Chyba iż chcemy, żeby nasze korpo zobaczyło na przykład, iż ich ściśle tajny raport opracowaliśmy w środku nocy, parę godzin przed terminem, na komputerze osoby o nicku Dżagusiaaa albo Alvaro Caliente :smile:
Życzę sprytu i unikania takich wpadek! A Monitory jeszcze zobaczymy w kolejnym, raczej nieodległym wpisie.



![[VIDEO] Przez cztery dni robili zakupy obok bomby. Nikt nie wiedział.](https://dzikizachod.eu/wp-content/uploads/2026/04/IMG_7010_compressed_2026_04_10_094123.webp)







