W ostatnim czasie ENISA opublikowała serię raportów o wykorzystaniu AI w różnych dziedzinach życia. W tym artykule omówiony został jeden z nich – ,,Cyberbezpieczeństwo i prywatność a AI – prognozowanie popytu w sieciach elektroenergetycznych” (Cybersecurity and Privacy in AI – Forecasting Demand On Electricity Grids). Przedstawiono w nim analizę wyzwań w zakresie cyberbezpieczeństwa, które wiążą się z wykorzystaniem systemów sztucznej inteligencji przez producenta energii elektrycznej do przewidywania zapotrzebowania konsumentów na tę energię.
Opracowanie innego raportu z tej serii na temat zastosowania AI do celów medycznych można przeczytać TUTAJ.
W ramach publikacji ,,Cyberbezpieczeństwo i prywatność a AI – prognozowanie popytu w sieciach elektroenergetycznych” omówione zostały trzy główne obszary tematyczne:
- scenariusz prognozowania popytu w sieciach elektroenergetycznych z użyciem AI, w tym podstawowe założenia i opis poszczególnych etapów wdrażania modeli sztucznej inteligencji (zaangażowane podmioty i ich funkcje, niezbędne dane i procesy itp.);
- zagrożenia oraz podatności w obszarze bezpieczeństwa i prywatności, jakie wiążą się z wykorzystaniem systemów sztucznej inteligencji w sposób opisany w scenariuszu;
- środki ochrony w zakresie cyberbezpieczeństwa i prywatności, które są rekomendowane dla przeciwdziałania zidentyfikowanym zagrożeniom i podatnościom.
Poniżej streszczona została każda z tych części.
Scenariusz prognozowania popytu w sieciach elektroenergetycznych z użyciem AI
Ogólne założenia
Na potrzeby scenariusza przyjęto, iż producent energii priorytetowo traktuje pozyskiwanie energii z odnawialnych źródeł. Produkcja energii z tego typu źródeł jest jednak zmienna – jej poziom może różnić się pomiędzy poszczególnymi dniami ze względu na np. warunki pogodowe. Jednocześnie, zapotrzebowanie konsumentów na energię również nie jest stałe i ulega wahaniom w różnych okresach, np. w okresie wakacyjnym. Z tego powodu producent decyduje się na wykorzystanie systemów AI, które pomogą mu jak najprecyzyjniej przewidzieć poziom popytu na energię w danym dniu oraz możliwą do wyprodukowania ilość energii ze źródeł odnawialnych. Dzięki temu będzie on mógł porównać obydwa poziomy i w przypadku, gdy pierwszy z nich będzie przekraczał drugi, zadecydować o uzupełnieniu ilości dostarczanej energii produkcją ze źródeł nieodnawialnych.
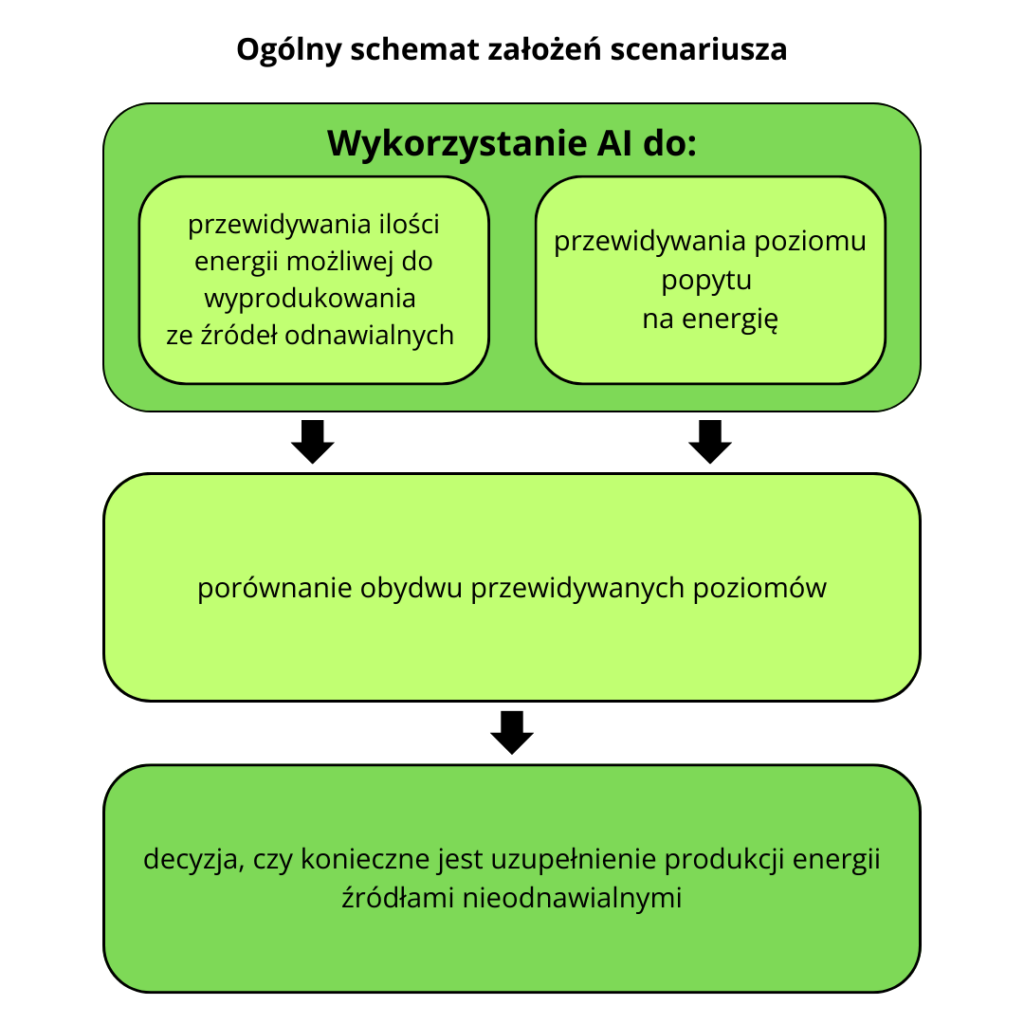
Budowa modeli sztucznej inteligencji
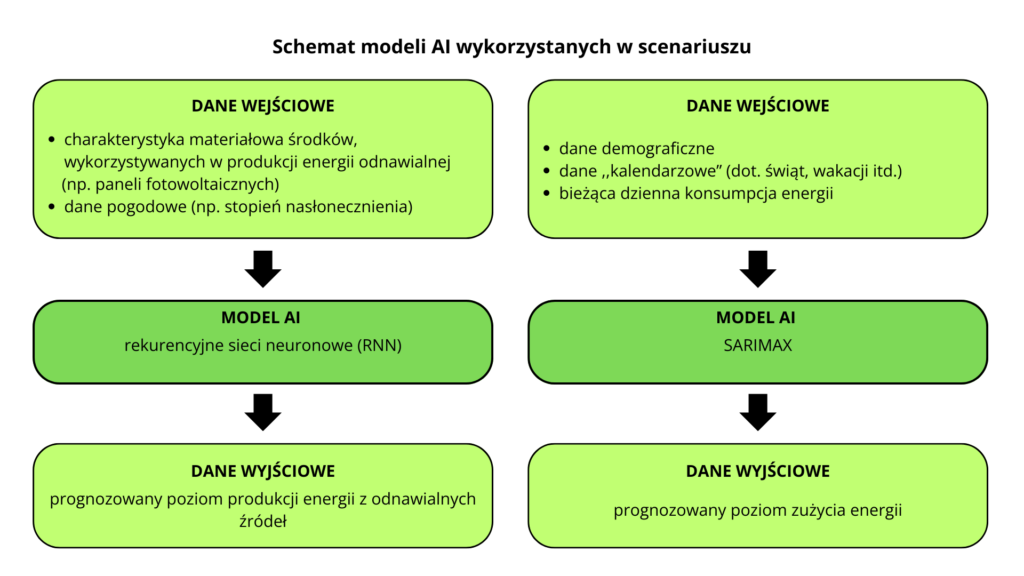
Do prognozowania opisanych wyżej poziomów dziennego popytu i podaży niezbędne będzie wykorzystanie dwóch osobnych modeli sztucznej inteligencji. W scenariuszu opisano, jak producent może krok po kroku zaprojektować, przygotować i wdrożyć takie systemy, z uwzględnieniem koniecznych do zaangażowania zasobów ludzkich i narzędzi.
Obydwa modele AI będą opierać się na określonym rodzaju algorytmu uczenia maszynowego. W przypadku systemu służącego do przewidywania dziennej produkcji energii wykorzystane zostaną rekurencyjne sieci neuronowe (RNN, recurrent neural network). To rodzaj sztucznych sieci neuronowych, w których sygnał otrzymany na wyjściu powtórnie trafia na ich wejście (występuje ,,sprzężenie zwrotne”). Ten typ AI został wybrany do potrzeb scenariusza ze względu na wysoką skuteczność w przewidywaniu danych sekwencyjnych.
W modelu, który ma służyć do prognozowania zapotrzebowania konsumentów na energię w danym dniu, użyty zostanie algorytm SARIMAX (A Seasonal AutoRegressive Integrated Moving Average with eXogenous variables). Pozwala on zrozumieć i przewidzieć przyszłe wartości w szeregu czasowym.
Aby obydwa modele sztucznej inteligencji mogły spełniać swoją funkcję, niezbędne będzie wprowadzenie do nich odpowiednio zebranych i przetworzonych danych. Każdy z systemów będzie wymagał odmiennego rodzaju danych wejściowych – czyli tych, które posłużą mu do dokonywania prognozy. Schemat danych wejściowych i wyjściowych charakterystycznych dla wszystkich z modeli AI przedstawiają poniższe grafiki.
Wymagania wobec modeli AI z punku widzenia prywatności i cyberbezpieczeństwa
W dalszej części scenariusza przedstawiono wymagania, które opisywane modele sztucznej inteligencji powinny spełniać z punktu widzenia cyberbezpieczeństwa oraz prywatności. Należy do nich przede wszystkim konieczność zapewnienia odpowiedniego poziomu dostępności do danych, ich integralności i poufności, a także możliwości śledzenia działań i zmian dokonywanych w danych i algorytmie. Ponadto, wskazano na obowiązki producenta energii w zakresie ochrony danych osobowych, wynikające z RODO i przykładowych zaleceń krajowych organów ochrony danych osobowych.
Zagrożenia oraz podatności w obszarze bezpieczeństwa i prywatności
W drugiej części raportu przeanalizowane zostały podatności i zagrożenia dla cyberbezpieczeństwa oraz prywatności, które powinien wziąć pod uwagę producent energii zamierzający zastosować opisane w scenariuszu systemy sztucznej inteligencji. Szczególny nacisk został położony na dwa możliwe obszary zagrożeń:
Utrata integralności danych
Jeżeli dane wprowadzone do modelu AI lub stanowiące wynik jego pracy zostaną zmanipulowane, może to doprowadzić do zakłóceń w produkcji energii, z których najpoważniejszym w skutkach będzie wytworzenie niedostatecznej ilości energii w stosunku do zapotrzebowania. Wpływ tego zagrożenia będzie ograniczony, w przypadku gdy dostarczane przez system wyniki będą pełnić jedynie funkcję pomocniczą przy podejmowaniu decyzji o wielkości produkcji energii na dany dzień.
Utrata poufności danych o zużyciu energii elektrycznej przez poszczególnych mieszkańców.
W przypadku gdy dane o zużyciu energii przez poszczególnych mieszkańców trafią do osób nieupoważnionych, może to spowodować zagrożenie dla ich prywatności i bezpieczeństwa. Dane te mogą posłużyć do poznania zwyczajów poszczególnych osób (np. kiedy zużywają mało energii, więc prawdopodobnie wychodzą z domu lub śpią), co może nieść za sobą wiele negatywnych konsekwencji – od prób włamań po zakłócenia w prywatnym życiu rodzinnym. Dla producenta energii taka sytuacja wiązać się będzie z poważnym kryzysem PR-owym i spadkiem zaufania ze strony konsumentów.
W raporcie wskazano również szereg innych zagrożeń dla cyberbezpieczeństwa i prywatności wiążących się z wykorzystaniem systemów sztucznej inteligencji, takich jak np. możliwość popełnienia poważnego w skutkach błędu przez osoby obsługujące modele AI, zatrucie wykorzystywanych przez nie danych lub zbieranie i przetwarzanie przez producenta danych osobowych konsumentów bez spełnienia wymaganych prawem warunków.
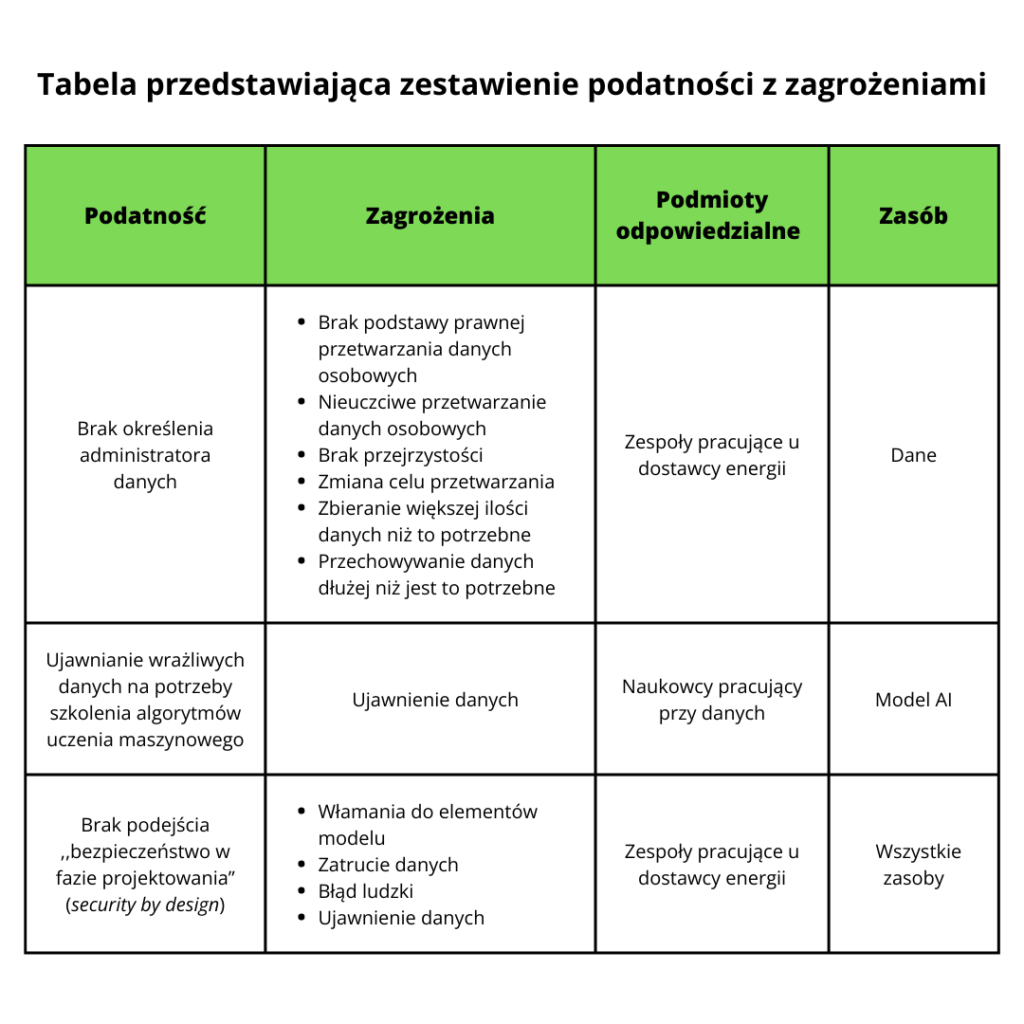
Podatności powiązane z zagrożeniami i zasoby, których dotyczą
Drugi element tej części publikacji stanowi tabela, w której opisano 36 przykładów podatności wraz ze wskazaniem, do którego zagrożenia może doprowadzić ich występowanie oraz jakich podmiotów odpowiedzialnych i zasobów one dotyczą.
Poniżej przedstawiono przykładowe, przetłumaczone wiersze z tej tabeli.
Środki ochrony w zakresie cyberbezpieczeństwa i prywatności
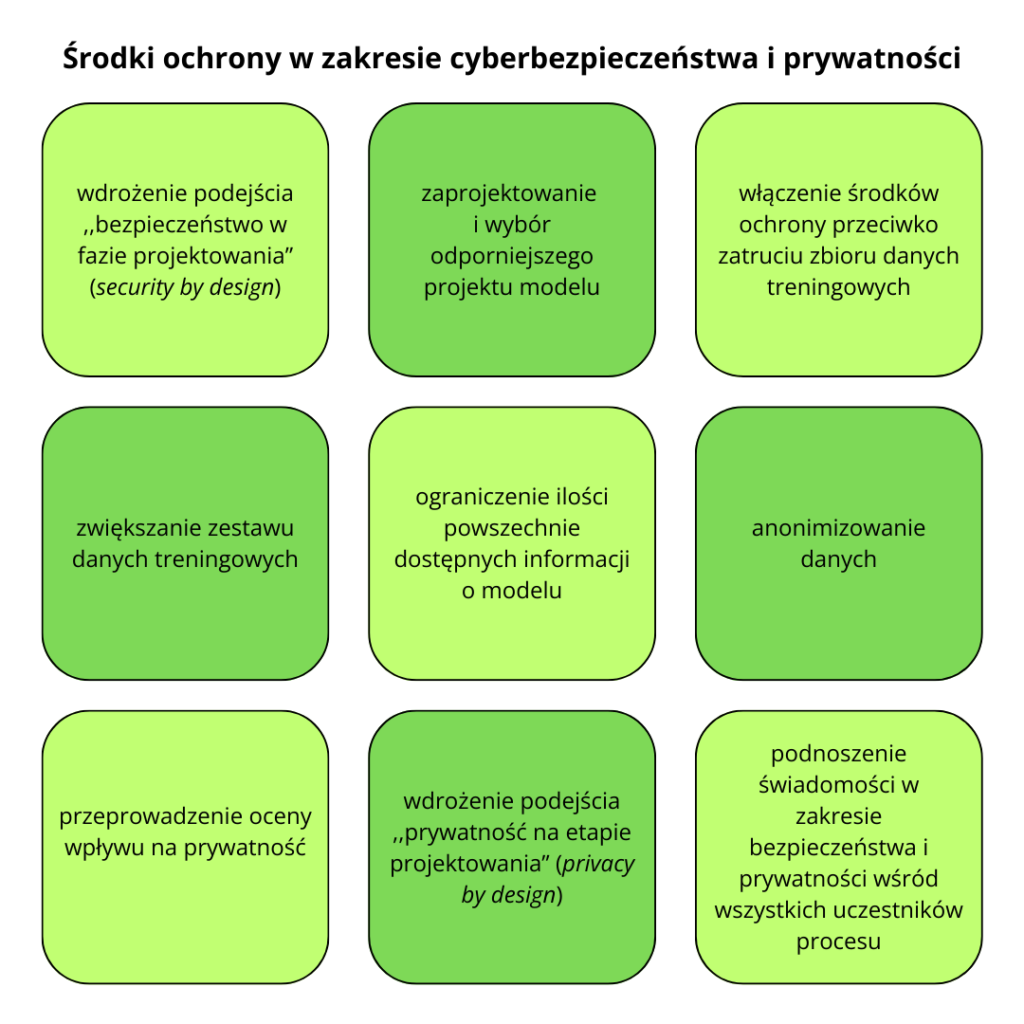
W trzeciej części raportu omówiono 23 przykłady środków ochrony, których podjęcie może pozwolić na zwiększenie bezpieczeństwa korzystania z systemów sztucznej inteligencji przez producenta energii w sposób przedstawiony w scenariuszu. Poniżej przedstawiono kilka wybranych środków wraz z działaniami, które powinny zostać w ramach nich podjęte:
- wdrożenie podejścia ,,bezpieczeństwo w fazie projektowania” (security by design)
Działania: przeprowadzanie generalnej oceny ryzyka już na etapie tworzenia modeli AI, zmniejszanie powierzchni potencjalnego ataku (np. poprzez ciągłe aktualizowanie systemu operacyjnego inteligentnych liczników), stosowanie zasady najmniejszego uprzywilejowania (poprzez wdrożenie zarządzania prawami dostępu), dbanie o poufność i integralność gromadzonych danych (poprzez szyfrowanie danych o zużyciu energii przez użytkowników).
- zaprojektowanie i wybór odporniejszego projektu modelu AI
Działania: wykorzystanie techniki ,,Bagging” (bootstrap aggregating) – stworzenia meta-algorytmu, który łączy kilka wersji modeli uczenia maszynowego (np. trenowanych na różnych zestawach danych) i pozwala ograniczyć skutki zatrucia danych wykorzystywanych przez jeden z nich.
- włączenie środków ochrony przeciwko zatruciu zbioru danych treningowych
Działania: wykorzystanie techniki STRIP do sprawdzenia, czy dane zostały zatrute – polega na zakłócaniu danych wejściowych i obserwacji losowości przewidywań. o ile rozbieżność między wynikami przewidywań opartych o zakłócone dane a wynikami bez zakłóceń jest niska, może to oznaczać, iż dane są zatrute.
- zwiększanie zestawu danych treningowych
Działania: wykorzystanie zestawów danych pogodowych/dotyczących konsumpcji energii z wielu lat.
- ograniczenie ilości powszechnie dostępnych informacji o modelu
Działania: ochrona dokumentacji na temat modelu, przechowywanie jej na serwerze o ściśle ograniczonym dostępie, wprowadzenie zabezpieczeń fizycznego dostępu do stanowisk pracy umożliwiających dostęp do dokumentacji.
- anonimizowanie danych
Działania: zapobieganie możliwości rozpoznania, kogo dane dotyczą, na najwcześniejszej możliwej fazie przetwarzania.
- przeprowadzenie oceny wpływu na prywatność
Działania: badanie wpływu przetwarzania danych na prywatność użytkowników, zgodności z RODO oraz czy przyjęte środki są adekwatne do ryzyk, sprawdzanie, czy cel przetwarzania został adekwatnie zdefiniowany oraz czy mieści się w nim rzeczywiste wykorzystanie danych.
- wdrożenie podejścia ,,prywatność na etapie projektowania” (privacy by design)
Działania: przeprowadzenie badania zgodności i analizy wpływu na prywatność (Privacy Impact Anlysis), przygotowanie na ich podstawie planu działania przed rozpoczęciem tworzenia modelu.
- podnoszenie świadomości w zakresie bezpieczeństwa i prywatności wśród wszystkich uczestników procesu
Działania: zapewnienie, aby wszystkie zespoły były świadome zagrożeń i ryzyk w obszarze cyberbezpieczeństwa i prywatności, przygotowanie sesji treningowych i szkoleń.
Na samym końcu raportu umieszczono tabelę podsumowującą III część, w której zestawione zostały podatności, zagrożenia oraz wymagania w zakresie prywatności i bezpieczeństwa ze środkami kontroli, które stanowią na nie odpowiedź.
Podsumowanie
- Raport ENISA zawiera podstawowe wytyczne w zakresie ochrony bezpieczeństwa i prywatności dla producentów energii, którzy planują wykorzystywać systemy AI do prognozowania dziennych poziomów popytu i podaży energii elektrycznej.
- Publikacja składa się z trzech zasadniczych części: opisu scenariusza zastosowania modeli AI w produkcji energii, analizy potencjalnych zagrożeń i podatności oraz propozycji środków ochrony, adresujących te zagrożenia i podatności.
- W opisie scenariusza przedstawiono jak, krok po kroku, wdrażać systemy sztucznej inteligencji do prognozowania popytu i podaży energii elektrycznej, podczas gdy w następnych częściach zwrócono uwagę na zagrożenia dla prywatności i bezpieczeństwa, jakie się z tym wiążą.







