Apache Kafka jest coraz bardziej popularnym brokerem wiadomości. Wystarczy spojrzeć na oferty pracy dla programistów Java, a gwałtownie przekonamy się, iż w większości nowoczesnych projektów, w architekturze mikroserwisów jest jakaś forma komunikacji po systemie kolejkowym. Bardzo prawdopodobne, iż będzie to właśnie Apache Kafka. Czemu Kafka zawdzięcza taką popularność? Otóż jest to sprawdzony w boju system kolejkowy, w modelu publish-subscribe, zdolny obsłużyć dziesiątki milionów komunikatów na sekundę. Do tego jest praktycznie bezawaryjny (dzięki replikacji i odpowiedniemu projektowi klastra) i bardzo wydajny.
Korzystając z okazji chciałbym Ciebie zaprosić na darmowe, bardzo obszerne szkolenie z Apache Kafka (będzie DEMO w Spring Boot), które odbędzie się online 3 października 2022r o godzinie 18:00 (zapisz się choćby jak nie będziesz mógł / mogła – roześlę nagranie) – więcej szczegółów znajdziesz na stronie do zapisów.
W tym artykule dowiesz się o:
- Czym jest Schema Registry?
- Jak działa rejestr schematów Avro?
- Jakie formaty wiadomości obsługuje Apache Kafka?
- Czym są Magic Bytes?
- Jak ustawić nagłówki w Apache Kafka?
- Jak odczytać nagłówki w Apache Kafka?
Format wiadomości w Apache Kafka
Sama Kafka nie dba o typ wysyłanych wiadomości. Dla Kafki liczy się tylko to, iż wiadomość przyjmuję formę tablicy bajtów. Pod wiadomością może kryć się zwykły String, Json, ProtoBuf, Avro albo wiele innych mniej znanych formatów wiadomości. Dokładnie tak jak na rysunku poniżej.
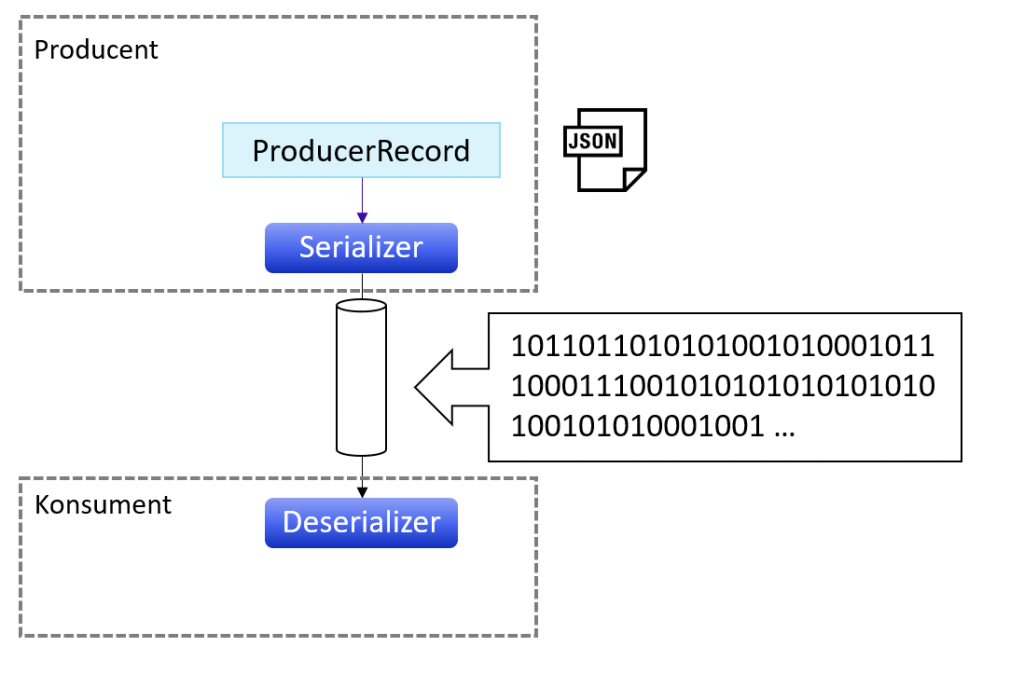
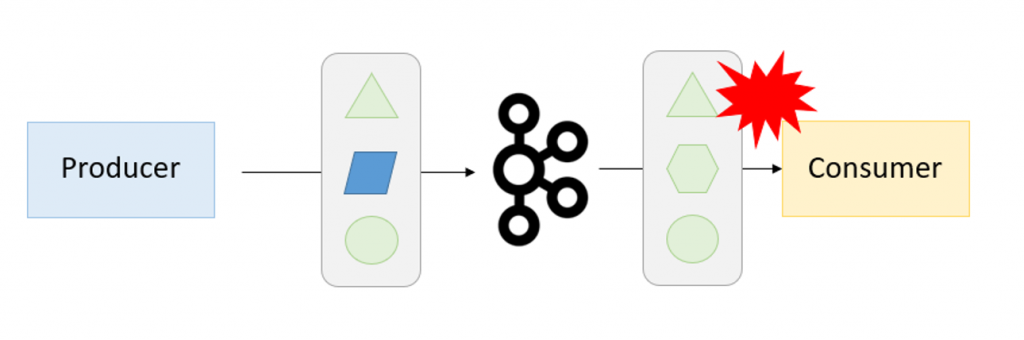
Zastanówmy się, co może pójść nie tak, jeżeli jako nasz komunikat wyślemy np. czysty Json. jeżeli nie pilnujemy struktury komunikatu, może się ona zmienić i wysypać nam konsumenta na produkcji. Jak to się dzieje? Otóż konsument musi w jakiś sposób zdeserializować odebrany komunikat (bo przecież po topicu Kafkowym wysyłane są same bajty). Deserializacja to proces przekształcania tablicy bajtów odebranego komunikatu na jakiś obiekt Javy. I tak po procesie derserializacji mamy uzupełniony kontenerek z danymi, czyli zwykły obiekt Javy. W tym procesie jest jedno grube ALE. Co się stanie, jeżeli deserializator oczekuje pewnej struktury danych, a my wyślemy mu coś innego, zmieniając typ danych albo np. dodając nowe pole? Spójrz na obrazek poniżej i chwilę się zastanów.

Przez brak wspólnego kontraktu pomiędzy producentem a konsumentem wiadomości, konsument nie jest w stanie odczytać komunikatu i zgłasza błąd w procesie deserializacji. Dokładnie tak jak na obrazku poniżej.
Avro
I tutaj pojawia się Avro, które ostatnimi czasy zyskało bardzo na popularności. Avro opisuje strukturę naszego komunikatu, przechowując definicję schematu w formacie Json. W tym wpisie nie będę wprowadzać Ciebie w temat Avro, bo zrobiłem to tutaj – Apache Avro (bardzo zachęcam do przeczytania artykułu)
Wiemy już, iż dane wysyłane po Kafce możemy serializować i deserializować dzięki schematów Avro. Zarówno producent, jak i konsument muszą znać ten sam schemat Avro, który umożliwi im najpierw serializację komunikatu, a potem jego deserializację. Spójrz na obrazek poniżej, gdzie razem z danymi dostarczany jest kontrakt, czyli schema Avro, która posłuży do deserializacji komunikatu.
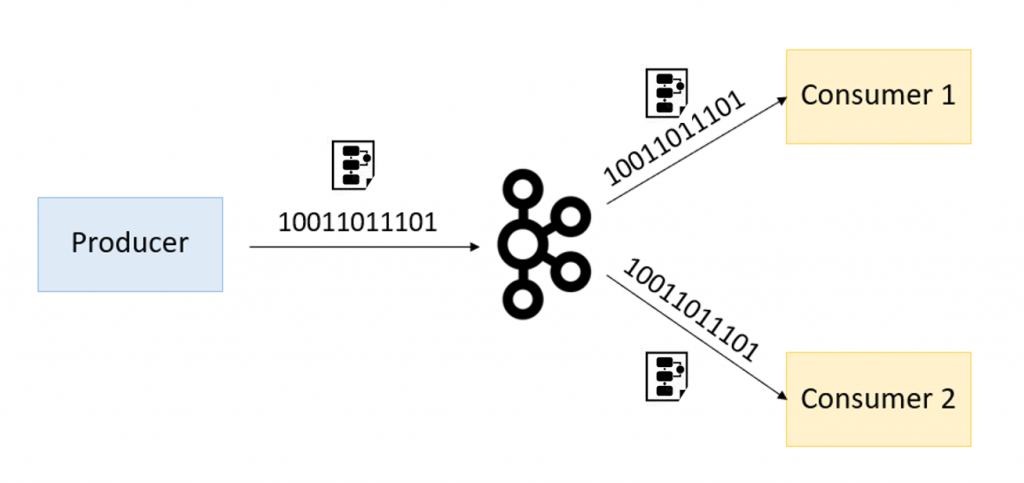
Sam komunikat wysyłany po Kafce może zawierać schemat potrzebny do deserializacji oraz sam kontent danych. Dzięki temu konsument za każdym razem wie w jaki sposób zderserializować dane, ponieważ z każdym komunikatem przychodzi schemat opisujący, w jaki sposób zmapować konkretne bajty wiadomości na konkretne pola w naszym obiekcie. Strukturę komunikatu przedstawia poniższy obrazek.

Pytanie, czy takie rozwiązanie jest dobre? Cóż, schematy potrafią być olbrzymie, co za tym idzie – zajmują sporo miejsca. jeżeli wysyłamy bardzo dużo wiadomości, wydaje się nadmiarowym dodawanie „ciężkiego” schematu deserializacji do każdego komunikatu. Pomyśl chwilę, jak można by rozwiązać ten problem?! Mnie przychodzi na myśl łączenie tabel bazodanowych. Po co w każdym wierszu klienta, dodawać pola adresowe, jeżeli możemy wyciągnąć dane adresowe do dedykowanej tabeli CustomerAddress a w tabeli klienta łączyć dane dzięki identyfikatora wiersza adresu. Podobnie możemy podejść do tego przypadku. Co by było, gdybyśmy schemat Avro umieścili na jakimś serwerze, a w komunikacie przesyłali tylko identyfikator tego schematu? I tak konsument przed podjęciem procesu deserializacji najpierw „wyłuskałby” id schemy z komunikatu, następnie pobrał schemę z jakiegoś serwera (np. po RestAPI), aby w końcu zdeserializować dane dzięki pobranej schemy. I w tym momencie pojawia się Schema Registry.
Czym jest Schema Registry?
Schema Registry to aplikacja, która znajduje się poza klastrem Apache Kafka. Aplikacja ta przechowuje informację o schematach Avro opisujących strukturę danych komunikatów. Co więcej, rejestr ten może przechowywać różne wersje schematów, bo przecież w realnym programowaniu czasami modyfikujemy kontrakty pomiędzy producentem a konsumentem. Dostęp do schematów odbywa się poprzez RestAPI. Schema Registry to nie tylko zwykły „kontenerek” na nasze schematy. Dodatkowo oferuje sprawdzanie kompatybilności różnych wersji schematów (backward / forward / full compability)
Architektura Schema Registry
Producent przed wysłaniem wiadomości do klastra Kafki musi w pierwszej kolejności zserializować komunikat. Producent komunikuje się ze Schema Registry i sprawdza, czy schema jest w rejestrze. jeżeli schemy nie ma, to ją wgrywa. Ta schema posłuży do zamiany komunikatu na ciąg bajtów w odpowiedniej strukturze (proces serializacji) i do deserializacji komunikatu, czyli procesu odwrotnego. Taki ciąg bajtów (z zaszytym identyfikatorem schemy i numerem wersji) jest wysyłany na topic Kafki.
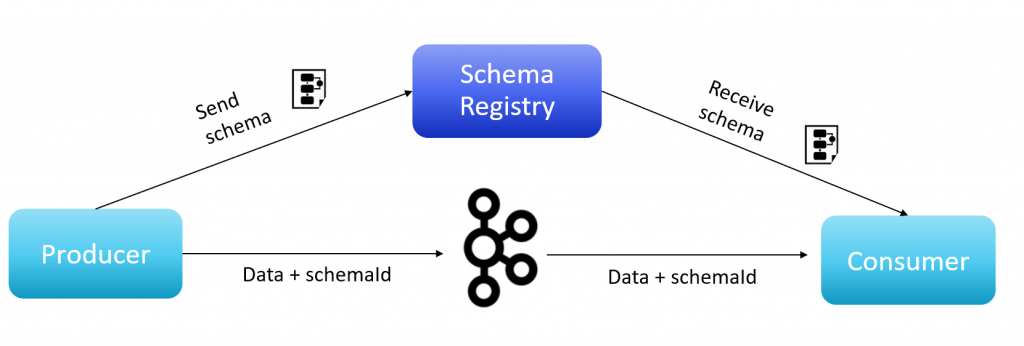
Kiedy konsument odbierze komunikat, w pierwszej kolejności musi odkryć identyfikator schemy i jego wersję. W tym momencie może pojawić się pytanie – w jaki sposób przekazać id schemy i nr wersji w bajtowym komunikacie, skoro nie wiemy jeszcze jak te bajty zdeserializować, no bo przecież nie pobraliśmy jeszcze schematu deserializacji. I tutaj pojawiają się dwa popularne rozwiązania, w jaki sposób możemy to osiągnąć.
Magic Bytes
Cały komunikat (w formie tablicy bajtów) jest przesuwany o kilka bajtów do przodu, tak aby na samym początku zrobić „okienko” o wielkości potrzebnej na zaszycie identyfikatora schemy oraz numeru wersji. Tutaj producent jest umówiony z konsumentem, iż pierwszy bajt opisuje numer wersji schemy, kolejne 4 bajty to id schemy, reszta wiadomości to content w postaci zserializowanego Avro. Dokładnie tak jak na poniższym rysunku.
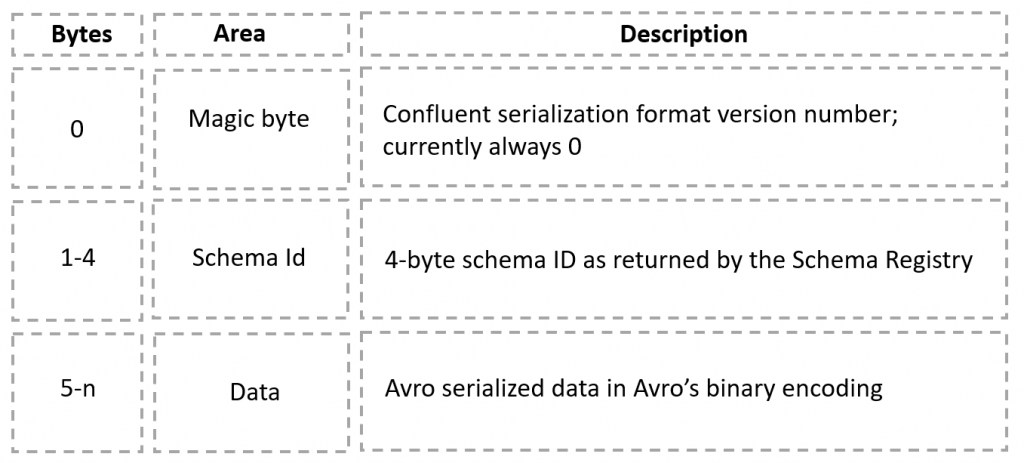
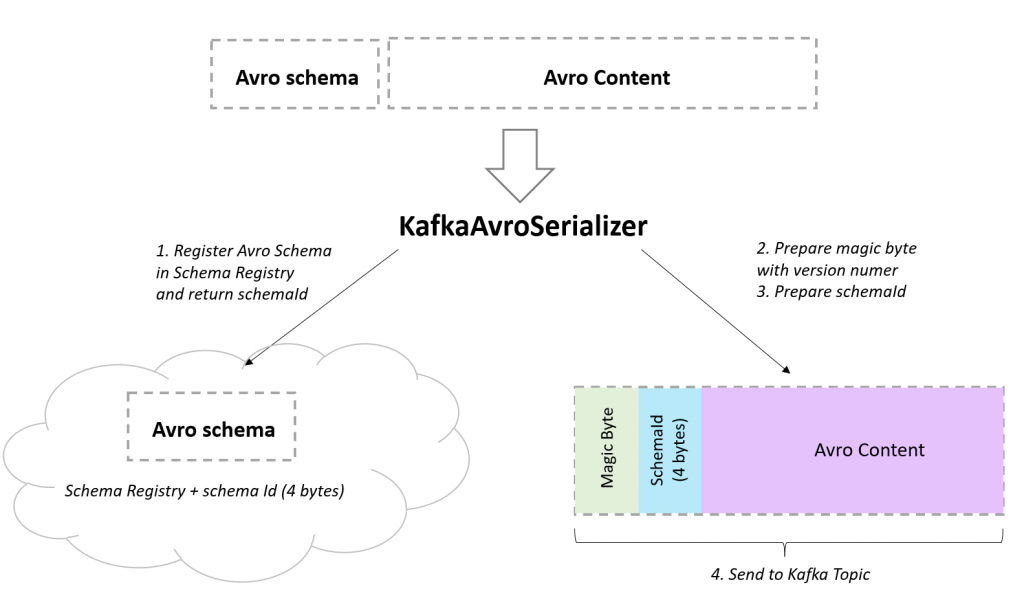
W tym przypadku, po odczytaniu komunikatu, konsument najpierw czyta pierwsze x bajtów, odkrywając id schemy oraz jego wersję. Dokładnie tak do tematu podchodzi Confluent, który opiekuje aplikację Schema Registry. Kiedy w kodzie użyjemy Confluentowego KafkaAvroSerializer oraz KafkaAvroDeserializer, cały proces jest dla nas przeźroczysty – wystarczy podać configi do schema registry. Spójrz na obrazek poniżej, a wszystko stanie się bardziej zrozumiałe.
Nagłówki wiadomości / Kafka headers
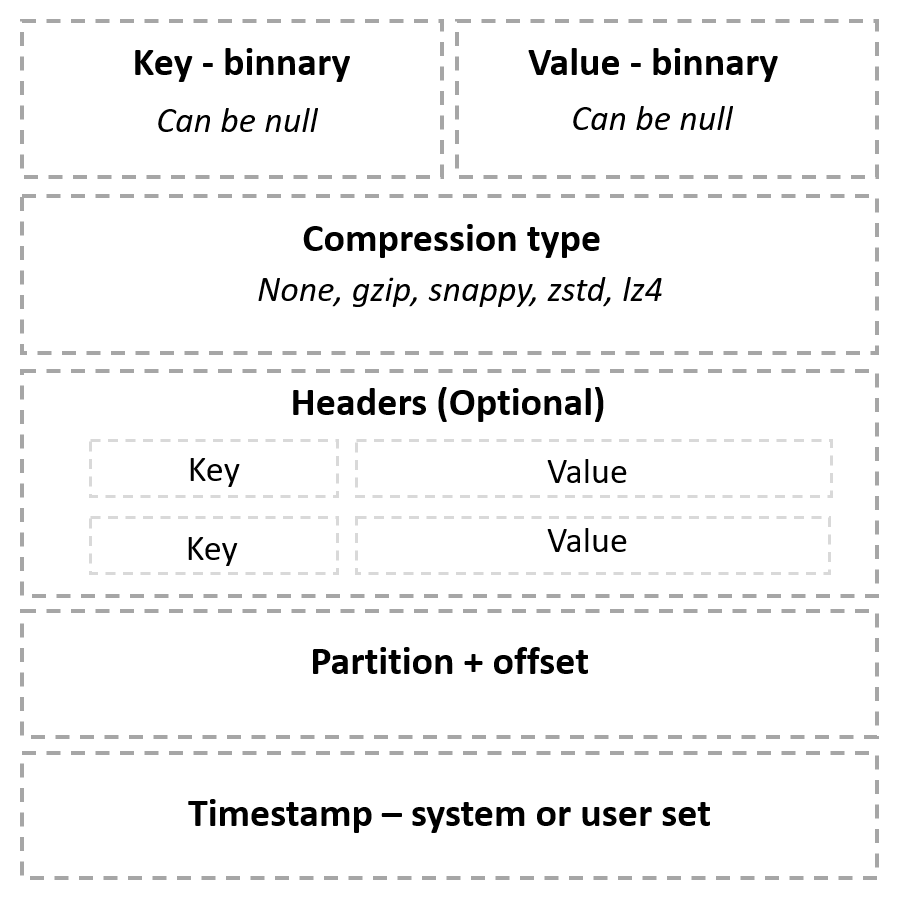
Czasami dochodzi do takich sytuacji, iż nie możemy użyć KafkaAvroSerializer / KafkaAvroDeserializer, np. kiedy nasz proces serializacji / deserializacji danych musimy uzupełnić o jakieś dodatkowe wymagania techniczno – biznesowe i sami musimy zaimplementować serializatory czy deserializatory. Jak możemy podejść do tematu w tym przypadku? Oczywiście moglibyśmy sami zaimplementować przesunięcia bajtowe korzystając z funkcji seek, ale jest prostsze i czystsze rozwiązanie. Tym rozwiązaniem są nagłówki. Zupełnie jak w przypadku protokołu HTTP, w Apache Kafka możemy posłużyć się dodatkowymi informacjami zaszytymi w nagłówkach wiadomości. Jest to prostsza forma przekazania id schemy, bo nie musimy edytować zserializowanej wiadomości. Struktura komunikatu Kafkowego wygląda następująco.
Tutaj wystarczy, iż przy definiowaniu ProducerRecord podamy customowe nagłówki, jak w przykładzie poniżej:
ProducerRecord<String, Message> producerRecord = new ProducerRecord<>(topic, messageKey, messageValue); producerRecord.headers() .add("value-schema-id", schemaId); kafkaTemplate.send(producerRecord);Od strony konsumenta musimy zaimplementować własny deserializator, który odczyta nagłówek, wykona strzał po RestApi do Schema Registry, a następnie użyje pobranego schematu. Kod może wyglądać następująco:
class CustomDeserializer<T> implements Deserializer<T> { private final String VALUE_SCHEMA_ID_HEADER = "value-schema-id"; @Override public T deserialize(String topic, byte[] data) { throw new UnsupportedOperationException("Deserialization of message without headers is not supported"); } @Override public T deserialize(String topic, Headers headers, byte[] data) { if (headersNotContainSchemaId(headers)) { throw new SerializationException("No schema id present"); } final var schemaId = getSchemaId(headers); final var schema = getSchema(schemaId); return deserializePayload(schema, data); } private boolean headersNotContainSchemaId(Headers headers) { return headers.lastHeader(VALUE_SCHEMA_ID_HEADER) == null; } private Integer getSchemaId(Headers headers) { return Optional.ofNullable(headers.lastHeader(VALUE_SCHEMA_ID_HEADER)) .map(Header::value) .map(String::new) .map(Integer::parseInt) .orElseThrow(() -> new SerializationException("Error while get value schema id from headers")); } private Schema getSchema(Integer schemaId) { // call to Schema Registry RestAPI by webClient or something else return null; } private T deserializePayload(Schema writerSchema, final byte[] payload) { final var datumReader = getDatumReader(writerSchema); final var decoder = DecoderFactory.get().binaryDecoder(payload, null); try { return datumReader.read(null, decoder); } catch (IOException e) { throw new SerializationException("Unable to deserialize record"); } } private DatumReader<T> getDatumReader(Schema writerSchema) { final var readerClass = SpecificData.get().getClass(writerSchema); final var readerSchema = SpecificData.get().getSchema(readerClass); return new SpecificDatumReader<>(writerSchema, readerSchema); } }Tak więc wiesz już czym jest Schema Registry, w jaki sposób można przekazywać identyfikatory schemy w komunikatach. Pora uruchomić aplikację Schema Registry! Dokonamy tego w następnym wpisie, gdzie pokażę Tobie przykładowe aplikacje producenta i konsumenta w Spring Boot, z obsługą Apache Avro oraz Schema Registry. Aby nie pominą Ciebie żaden wpis, zachęcam do zapisania się na naszą listę mailową 🙂
Podsumowanie
Schema Registy to prosta aplikacja, ale potężne rozwiązanie umożliwiające kontraktową pracę konsumentów i producentów komunikatów na klaster Apache Kafka. Schema Registy jest punktem krytycznym, bo w przypadku awarii tej aplikacji, wysiada nam cała komunikacja po systemie kolejkowym. Dlatego należy pilnować wysokiej dostępności Schemy Registry. Warto pokusić się również o mechanizm lokalnego cache schematów.
Ten artykuł był wstępem do tematu Schema Registry, w następnym artykule spróbujemy zaimplementować obsługę Schema Registy w aplikacji Spring Boot
Schema Registry przechowuje i wersjonuje schematy potrzebne do deserializacji i serializacji komunikatów w formacie Avro.