Ostatnio dostałem zgłoszenie błędu w komentarzach na blogu. W skrócie: jeżeli nie zaakceptowało się ciasteczek, nie dało się dodać komentarza. Postanowiłem przyjrzeć się temu problemowi i znaleźć jakieś rozwiązanie.
Jak działają komentarze?
Na swojej stronie używam systemu Giscus. Pozwala on dodawać komentarze w formie dyskusji na GitHubie. Każdy wpis ma swoją własną dyskusję. Tak dodane komentarze są wyświetlone na dole, pod każdym wpisem:
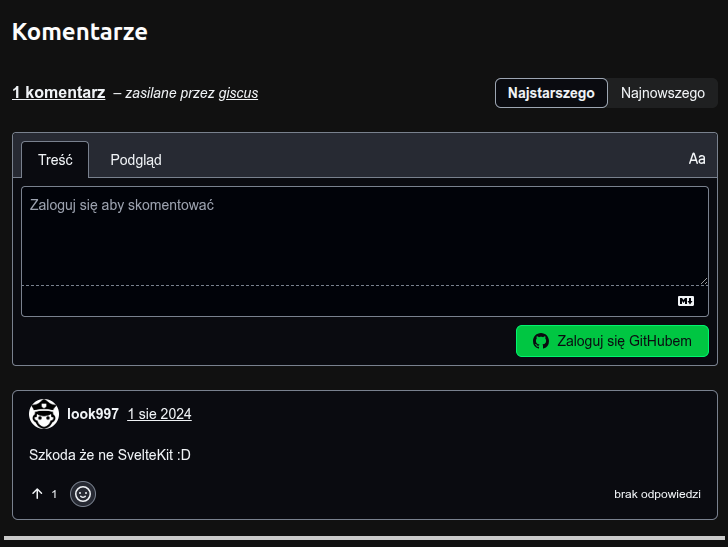
Przykład z wpisu Blog 2.0
Działa to całkiem przyzwoicie. Minusem jest wymóg, aby każda komentująca osoba miała konto na GitHubie. Wydaje mi się jednak, iż z uwagi na grupę docelową bloga jest to akceptowalny kompromis. Jest też drugi minus: Giscus wymaga zarówno JS-a, jak i zaakceptowania ciasteczek. Co się stanie, jeżeli zabraknie choć jednego z nich? Zamiast komentarzy, pojawi się link do dyskusji na GitHubie:
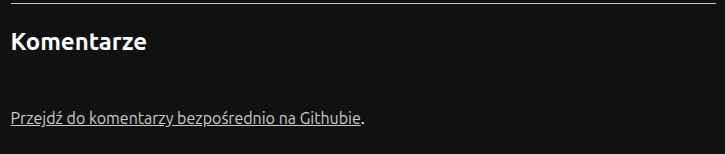
I właśnie tutaj pojawia się zgłoszony błąd! W przypadku, gdy dany post ma już jakieś komentarze, link zaprowadzi nas do istniejącej dyskusji. Jednak, gdy post dotąd nie został skomentowany, dana dyskusja nie istnieje, a komentująca osoba nie jest w stanie jej sama stworzyć. Giscus robi to automatycznie przy pierwszym komentarzu. A iż nie chcę odcinać choćby części czytających od możliwości komentowania, stwierdziłem, iż zainteresuję się problemem i postaram znaleźć jakieś rozwiązanie.
(Częściowe) rozwiązanie
Logicznie nasuwającym się rozwiązaniem jest stworzenie brakujących dyskusji – tak, aby dla wszystkich wpisu istniała jedna. Tym zajmiemy się dzisiaj! Napiszemy skrypt w Node.js, który:
- stworzy listę wszystkich wpisów,
- sprawdzi, czy istnieją dla nich dyskusje,
- stworzy wszystkie brakujące dyskusje.
To rozwiązanie jednak naprawia tylko część problemu. Dyskusje powstaną bowiem dla już istniejących wpisów. Musiałbym regularnie odpalać ten skrypt, żeby wykrywać nowe wpisy i dodawać do nich dyskusje. Wygodniejszym rozwiązaniem byłoby automatyczne tworzenie dyskusji w momencie, gdy nowy wpis zostaje wypchany do repozytorium. Tym zajmiemy się kiedy indziej. Na razie skupimy się na naprawieniu dyskusji dla już istniejących wpisów.
Stworzenie listy wpisów
Struktura plików bloga jest w miarę uporządkowana. Wszystkie wpisy znajdują się w katalogu src/_posts, w podkatalogu odpowiedniej kategorii. Same wpisy to pliki .md. Zatem wyciągnięcie listy wpisów w dużej mierze sprowadza się do wyszukania wszystkich plików .md w katalogu src/_posts. Dokładnie do takich zadań został stworzony glob! W Node.js od wersji 22 istnieje odpowiednia funkcja od tego. Wystarczy ją wykorzystać do wyciągnięcia listy plików .md:
import { glob } from 'node:fs/promises'; // 1 const postsDirPath = '[ciach]blog/src/_posts'; // 4 const postFiles = glob( '**/*.md', { // 2 cwd: postsDirPath // 3 } ); for await ( const postFile of postFiles ) { // 5 console.log( postFile ); // 6 }Na początku importujemy funkcję glob() z wbudowanego modułu node:fs (1). Następnie wywołujemy ją ze wzorcem **/*.md (2) oraz katalogiem (3) ustawionym na absolutną ścieżkę do katalogu z wpisami bloga (4). Następnie w pętli (5) wyświetlamy wszystkie pliki (6). Powinniśmy uzyskać mniej więcej taką listę:
standardy-sieciowe/2017-03-19-drzewko-dostepnosci-udostepnione.md standardy-sieciowe/2017-04-02-web-components-koszmar-minionego-lata.md standardy-sieciowe/2017-04-09-potrzebujemy-zachowan-nie-dziedziczenia.md standardy-sieciowe/2018-01-05-pyrrusowe-zwyciestwo.md standardy-sieciowe/2018-01-23-zawieszenie-broni.md […]Jak widać, uzyskaliśmy ścieżki do plików względem katalogu z wpisami. Wróćmy jeszcze na chwilę do samego wzorca:
**/*.mdNie będę wchodził tutaj w szczegóły składni globa, ale ten wzorzec oznacza “wszystkie pliki z rozszerzeniem .md, w dowolnym podkatalogu obecnego katalogu”. Gdybyśmy ograniczyli się tylko do *.md, glob nic by nie znalazł (nie wszedłby do żadnego z podkatalogów kategorii).
No dobrze, ale surowa lista plików to jedynie połowa sukcesu. Zobaczmy, jak wygląda przykładowa dyskusja stworzona przez Giscusa:
Dyskusja dla wpisu Blog 2.0
Tak naprawdę potrzebujemy pomrowa…! Czyli sluga, a więc – ostatnią część URL-a wpisu:
https://blog.comandeer.pl/blog-2.0W przypadku mojego bloga slugiem jest wszystko to, co następuje po domenie, a więc – ścieżka.
Tę możemy uzyskać z tzw. front matter (strony tytułowej). To sekcja na początku pliku .md, wydzielona przy pomocy --- i zawierająca metadane wpisu w formacie YAML. W przypadku mojego bloga jedną z metadanych jest permalink, a więc – ostateczna nazwa wynikowego pliku HTML:
permalink: /blog-2.0.htmlA stąd już prosta droga do ścieżki, która – dzięki konfiguracji backendu – pomija rozszerzenie .html. Wystarczy zatem… sparsować YAML-a, wyciągnąć z niego wartość danej permalink i obciąć z niej .html! A jak już to będziemy robić, to warto przy okazji zainteresować się inną metadaną, comments, która określa, czy dany wpis powinien mieć komentarze, czy nie. Jak na razie tylko jeden wpis nie ma komentarzy, ale nie wykluczam, iż pojawią się kolejne w przyszłości. Możemy też od razu wyciągnąć daną description, czyli opis wpisu, który przyda nam się przy tworzeniu dyskusji.
Sparsujmy zatem YAML-a! Na całe szczęście nie musimy dokładnie parsować całej strony tytułowej, wystarczy nam wyszukanie w niej trzech danych. A do tego wykorzystać możemy wyrażenia regularne. Przystąpmy do pracy:
import { glob, readFile } from 'node:fs/promises'; // 1 import { resolve as resolvePath } from 'node:path'; // 2 […] const posts = []; // 3 for await ( const postFile of postFiles ) { const postFilePath = resolvePath( postsDirPath, postFile ); // 4 const postContent = await readFile( postFilePath, 'utf-8' ); // 5 const postMetadata = getMetadata( postContent ); // 6 if ( postMetadata.comments ) { // 7 posts.push( postMetadata ); // 8 } }Na początku importujemy dwie dodatkowe funkcje: readFile() (1) do odczytywania zawartości plików oraz resolve() (2) do rozwiązywania pełnych ścieżek do plików. Następnie tworzymy tablicę posts (3), w której będziemy przechowywać metadane wpisów zezwalających na komentarze. Z kolei w pętli rozwiązujemy pełną ścieżkę pliku wpisu względem katalogu z wpisami (4), a następnie używamy jej do odczytania zawartości pliku (5). Tę zawartość przekazujemy funkcji getMetadata() (6), której zadaniem jest wyciągnięcie metadanych ze strony tytułowej. jeżeli w metadanych jest informacja, iż wpis zezwala na komentarze (7), metadane są umieszczane w tablicy posts (8).
Z kolei funkcja getMetadata() prezentuje się następująco:
[…] const FRONT_MATTER_REGEX = /^---\n(?<content>(?:.|\n)+)\n---/u; // 2 […] function getMetadata( content ) { const frontMatter = content.match( FRONT_MATTER_REGEX ); // 1 const lines = frontMatter.groups.content.split( '\n' ); // 3 return lines.reduce( ( metadata, line ) => { // 4 […] return metadata; }, {} ); }Na początku wyszukujemy stronę tytułową w treści wpisu (1) przy pomocy wyrażenia regularnego (2). Szuka ono ciągu, który zaczyna się od trzech myślników (-), po których następuje znak nowej linii (\n), po niej interesująca nas treść, którą zapisujemy do grupy content, a po treści następuje znowu znak nowej linii (\n) oraz ponownie trzy myślniki. Następnie treść strony tytułowej dzielimy na poszczególne linie (3). Tak uzyskaną tablicę z treścią każdej linii przekształcamy na obiekt z metadanymi (4).
Z kolei same przekształcenia zależą od tego, jaką linię akurat parsujemy. Rozpoznamy to poprzez sprawdzenie, czy jej treść zaczyna się od nazwy poszukiwanej przez nas metadanej:
if ( line.startsWith( '<nazwa metadanej>') ) { // zrób coś }Dla metadanej permalink kod wygląda następująco:
const PERMALINK_TRIM_REGEX = /\.html$/gu; // 5 […] if ( line.startsWith( 'permalink' ) ) { // 1 const [ , lineContent ] = line.split( ':' ); // 2 return { ...metadata, // 3 slug: lineContent.trim().replace( PERMALINK_TRIM_REGEX, '' ) // 4 } }Sprawdzamy, czy mamy do czynienia z odpowiednią daną (1). Następnie dzielimy linię na dwie części (2): niepotrzebną nam nazwę metadanej oraz jej wartość. Dzielenie jest robione na znaku dwukropka (:). Następnie zwracamy obiekt z metadanymi. Kopiujemy już istniejące (3), po czym dodajemy własność slug (4). Jej wartością jest wartość metadanej, pozbawiona białych znaków z początku i końca, oraz z usuniętym niepotrzebnym rozszerzeniem .html z końca. Usunięcia dokonaliśmy przez zastąpienie rozszerzenia, wyszukanego wyrażeniem regularnym (5), przez pusty ciąg.
Podobnie wygląda to w przypadku metadanej description:
[…] const DESCRIPTION_TRIM_REGEX = /^"|"$/gu; // 1 […] if ( line.startsWith( 'description' ) ) { const [ , lineContent ] = line.split( ':' ); return { ...metadata, description: lineContent.trim().replace( DESCRIPTION_TRIM_REGEX, '' ) }; }Jedyna różnica polega na tym, iż w tym przypadku zamiast rozszerzenia .html usuwamy cudzysłowy (1), którymi otoczona jest większość opisów.
Do tego jeszcze dorzucamy obsługę metadanej comments:
if ( line.startsWith( 'comments' ) ) { const [ , lineContent ] = line.split( ':' ); return { ...metadata, comments: lineContent.trim() === 'true' ? true : false // 1 }; }W tym przypadku zamiast zawartości metadanej, zwracamy true albo false – w zależności od tego, czy metadana miała wartość true lub false (1). Z racji tego, iż parsujemy YAML-a manualnie, cała zawartość strony tytułowej jest tekstem, więc musimy tę konwersję zrobić sami.
Dygresja
Niestety, proste Boolean( wartoscMetadanej ) nie wystarczy, bo każdy niepusty ciąg tekstowy (w tym 'false') zwraca true.
I w końcu mamy listę wszystkich wpisów, które mają mieć komentarze! Teraz pora przystąpić do drugiej części zadania.
Sprawdzenie, czy dla wpisów istnieją dyskusje
Sprawdzenie, jakie dyskusje istnieją w repozytorium bloga, wymaga użycia API GitHuba. Na całe szczęście, dla Node.js istnieje biblioteka Octokit.js, która zdecydowanie to ułatwia. Wypada ją zatem zainstalować:
npm install octokitŻeby jednak móc ją użyć do połączenia się z API, trzeba stworzyć nowy token dostępowy. Najlepiej, żeby miał jak najmniejsze uprawnienia. W tym przypadku: dostęp tylko do repozytorium bloga, a w nim – tylko do dyskusji.
Mimo minimalnych uprawnień, taki token najlepiej trzymać poza kodem, np. w pliku .env. Jest to na tyle popularna technika, iż Node od wersji 20.12 ma wbudowane funkcje w celu jej wspierania. Zacznijmy od stworzenia pliku .env:
GITHUB_TOKEN="[ciach]" # 1 POSTS_DIR_PATH="[ciach]/blog/src/_posts" # 2 REPO_OWNER="Comandeer" # 3 REPO_NAME="blog" # 4 CATEGORY_ID="[ciach]" # 5Stworzyliśmy w nim sześć zmiennych:
- GITHUB_TOKEN – token dostępowy GitHuba,
- POST_DIR_PATH – ścieżkę do katalogu z postami,
- REPO_OWNER – nazwę właściciela repozytorium na GitHubie,
- REPO_NAME – nazwę repozytorium na GitHubie,
- CATEGORY_ID – ID kategorii na GitHub Discussions (można użyć Giscusa, żeby je uzyskać),
- BLOG_URL – adres bloga (bez / na końcu).
Dzięki temu całość konfiguracji skryptu jest poza skryptem i nie trzeba będzie dłużej zmieniać kodu, żeby np. zaktualizować ścieżkę. A i trzymanie tego w zewnętrznym pliku sprawia, iż jest zdecydowanie mniejsza szansa, iż przez przypadek wypchamy do repo token.
Pora wczytać zawartość pliku .env do zmiennych środowiskowych:
import { loadEnvFile, env } from 'node:process'; // 1 import { Ocktokit } from 'octokit'; // 4 loadEnvFile(); // 2 […] const postsDirPath = env.POSTS_DIR_PATH; // 3Najpierw importujemy funkcję loadEnvFile() oraz zmienną env z node:process (1). Następnie wywołujemy loadEnvFile() (2), żeby stworzyć zmienne środowiskowe na podstawie pliku .env. Na końcu używamy tak wczytanej zmiennej środowiskowej do określenia położenia katalogu z wpisami (3). Przy okazji możemy też od razu zaimportować bibliotekę octokit (4).
Pora stworzyć funkcję, która pobierze dla nas wszystkie dyskusje z kategorii przeznaczonej na komentarze:
const octokit = new Octokit( { // 9 auth: process.env.GITHUB_TOKEN // 10 } ); async function getExistingDiscussions( options ) { /* 1 */ const query = ` query($owner: String!, $repo: String!, $categoryId: ID!, $cursor: String) { repository(owner: $owner, name: $repo) { discussions( first: 100, after: $cursor, categoryId: $categoryId ) { nodes { title } pageInfo { hasNextPage endCursor } } } }`; const discussions = []; let hasNextPage = false; // 4 let cursor; // 7 do { // 2 const result = await octokit.graphql( query, { // 8 ...options, cursor }); const { nodes, pageInfo } = result.repository.discussions; // 11 discussions.push( ...nodes ); // 12 hasNextPage = pageInfo.hasNextPage; // 5 cursor = pageInfo.endCursor; // 6 } while ( hasNextPage ); // 3 return discussions; // 13 }Funkcja wygląda dość przerażająco – ale to głównie z uwagi na spore zapytanie GraphQL (1). Nie będę wchodził w szczegóły tego języka. W dużym skrócie: to zapytanie pobierze nam wszystkie dyskusje, które są w podanej kategorii dyskusji. Reszta funkcji to obsługa tego zapytania. Tworzymy pętlę do/while (2), która wykona się co najmniej raz, a kolejne wywołania zależeć będą od tego, czy zmienna hasNextPage jest równa true (3). Ta zmienna (4) przechowuje informacje o paginacji. W przypadku bowiem, gdy dyskusji będzie odpowiednio dużo, jedno zapytanie nie zwróci ich wszystkich. Wówczas wynik będzie zawierał informację o tym, iż jeszcze są inne dyskusje, które trzeba pobrać (5). W tym celu wynik zawiera także kursor (6), który sobie zapisujemy (7), aby użyć go w kolejnym zapytaniu. Kursor to wskaźnik, który pokazuje, gdzie zakończyliśmy pobieranie dyskusji i pozwala kontynuować od tego miejsca. Samo zapytanie wykonujemy przy pomocy metody #graphl() z biblioteki octokit (8). Najpierw jednak musimy stworzyć klienta Ocktokit (9), przekazując mu token dostępowy (10). Gdy już wykonamy zapytanie, wyciągamy z wyniku dwie własności (11): nodes (zwrócone dyskusje) oraz pageInfo (informacje o paginacji). Zwrócone dyskusje dodajemy do tablicy discussions (12), którą na końcu zwracamy (13).
Teraz trzeba dodać wywołanie funkcji getExistingDiscussions() do istniejącej logiki:
const existingDiscussions = await getExistingDiscussions( { // 1 owner: env.REPO_OWNER, // 2 repo: env.REPO_NAME, // 3 categoryId: env.CATEGORY_ID // 4 } ); const missingPosts = posts.filter( ( { slug } ) => { // 5 return existingDiscussions.findIndex( ( { title } ) => { // 6 return title === slug; // 7 } ) === -1; } ); console.log( 'Brakujących dyskusji:', missingPosts.length ); // 8Umieszczamy ten kod po pętli pobierającej metadane wpisów. Do zmiennej existingDiscussions zapisujemy wynik funkcji getExistingDiscussions() (1). Do jej wywołania przekazujemy zmienne środowiskowe z nazwą właściciela repozytorium (2), nazwą repozytorium (3) oraz ID kategorii dyskusji (4). Następnie tworzymy tablicę (5) wpisów, dla których nie ma jeszcze dyskusji. Robimy to przy pomocy przefiltrowania tablicy wszystkich wpisów przy pomocy metody Array#findIndex(), sprawdzającej (6), czy tablica istniejących dyskusji posiada wpis dla danego sluga (7). Na końcu wyświetlamy informację, ile dyskusji brakuje (8).
Drugi etap pracy za nami, pora na trzeci!
Tworzenie brakujących dyskusji
Żeby stworzyć brakujące dyskusje, napiszemy nową funkcję, createMissingDiscussions():
async function createMissingDiscussions( options ) { const repositoryId = await getRepositoryId( options.owner, options.repo ); // 1 for ( const post of options.posts ) { // 2 await createDiscussion( { // 3 repositoryId, // 4 categoryId: options.categoryId, // 5 title: post.slug, // 6 body: createDiscussionBody( post, options.blogUrl ) // 7 } ); const randomSleepTime = Math.floor( Math.random() * 6 ) + 1; // 9 await sleep( randomSleepTime ); // 8 } }Na początku pobieramy ID repozytorium na podstawie jego właściciela i nazwy (1). Następnie dla wszystkich z przekazanych wpisów (2) wywołujemy funkcję createDiscussion() (3), której przekazujemy ID repozytorium (4), ID kategorii dyskusji (5), tytuł dyskusji, czyli w naszym wypadku sluga (6), oraz treść dyskusji, którą tworzymy przy pomocy funkcji createDiscussionBody() (7). Zanim przejdziemy do dodawania kolejnej dyskusji, odczekujemy losową liczbę sekund (8), a dokładniej – między 1 a 6 (9). Robimy to, żeby nie natknąć się na ograniczenia po stronie GitHubowego API.
Funkcja getRepositoryId() prezentuje się następująco:
async function getRepositoryId( owner, name ) { /* 1 */ const query = ` query($owner: String!, $name: String!) { repository(owner: $owner, name: $name) { id } }`; const result = await octokit.graphql( query, { // 2 owner, // 3 name // 4 } ); return result.repository.id; // 5 }Zawiera ono zapytanie GraphQL (1), które pobiera ID repozytorium. Wykonujemy je (2), przekazując właściciela (3) oraz nazwę repozytorium (4), a następnie zwracamy pobrane ID (5).
Funkcja createDiscussion() z kolei wygląda tak:
async function createDiscussion( options ) { const query = ` mutation($input: CreateDiscussionInput!) { createDiscussion(input: $input) { discussion { title } } }`; const response = await octokit.graphql( query, { // 2 input: options // 3 } ); console.log( `Created discussion`, response.createDiscussion.discussion.title ); // 4 }Ona również ma w sobie zapytanie GraphQL (1) – z tym, iż typu mutation zamiast query. Wykonujemy je (2), przekazując obiekt z danymi nowej dyskusji jako input (3). Na końcu wyświetlamy informację o dodanej dyskusji (4).
Dwie pomocnicze funkcje, createDiscussionBody() i sleep() prezentują się jak poniżej:
function createDiscussionBody( { slug, description }, blogUrl ) { const link = `${ blogUrl }${ slug }`; /* 1 */ return `# ${ slug } ${ description } ${ link }`; } async function sleep( seconds ) { return new Promise( ( resolve ) => { setTimeout( resolve, seconds * 1000 ); } ); }Jeśli chodzi o funkcję sleep(), to bardzo podobną funkcję tworzyliśmy dla czasomierzy. Natomiast funkcja createDiscussionBody() tworzy tekst w formacie Markdown (1) na podstawie przekazanych jej danych, a następnie go zwraca.
Ostatnim krokiem jest dodanie wywołania funkcji createMissingDiscussions() na koniec głównej logiki skryptu:
await createMissingDiscussions( { owner: env.REPO_OWNER, // 1 repo: env.REPO_NAME, // 2 categoryId: env.CATEGORY_ID, // 3 posts: missingPosts, // 4 blogUrl: env.BLOG_URL // 5 } );Do wywołania przekazujemy:
- właściciela repozytorium,
- nazwę repozytorium,
- ID kategorii dyskusji,
- listę wpisów, dla których chcemy stworzyć dyskusje,
- URL bloga, żeby móc stworzyć ładne linki w dyskusjach.
Jeśli wszystko poszło dobrze i odpalimy teraz nasz skrypt, powinien wykryć, ile wpisów nie ma swoich dyskusji i zacząć je sukcesywnie dodawać!
Całość kodu, z dodatkową dokumentacją, znaleźć można w repozytorium Comandeer/fix-discussions.
I to tyle. Zgłoszony błąd powinien zostać naprawiony!



