Jeśli interesują Ciebie podobne opracowana zagadnień egzaminacyjnych CompTIA Security+, to zachęcam do zapisania sią na moją listę mailingową.
Termin ten można dosłownie przetłumaczyć jako fałszerstwo żądań i opisuje pewien rodzaj ataków polegających na zmuszeniu zaatakowanej aplikacji do wykonywania żądań/zapytań (ang. requests) w imieniu atakującego (i na jego korzyść).
Zapytania często są wykonywane w kontekście użytkownika zalogowanego do systemu lub w imieniu aplikacji, która ma dostęp do innych systemów wewnętrznych – dzięki temu atakujący jest w stanie przeprowadzać operacje, do których sam nie ma uprawnień.
W ogromnej większości przypadków pod tym terminem kryją się dwa rodzaje fałszerstw, czyli Cross-Site Request Forgery (CSRF) oraz Server-Side Request Forgery (SSRF).
Cross-Site Request Forgery (CSRF)
Rodzaj ataku opierający się na zaufaniu aplikacji webowej do przeglądarki użytkownika. Wykorzystuje on mechanizm sesji (ang. session) polegający m.in. na tym, iż użytkownik nie musi się logować za każdym razem, kiedy wysyła żądanie (ang. request) do serwera, ponieważ po pierwszym poprawnym zalogowaniu, odpowiednia informacja uwierzytelniająca zostaje zapisana w ciasteczku przeglądarki (ang. cookie) i jest ona wysyłana z każdym kolejnym żądaniem do serwera.
Inne nazwy, z którymi można się jeszcze spotkać to: XSRF; Sea Surf; Session Riding.
Nakłonienie użytkownika w ten czy inny sposób do wykonania złośliwego żądania, nie jest jedynym warunkiem powodzenia ataku. Sama aplikacja, w której użytkownik się zalogował, musi być podatna na tego rodzaju działania. Innymi słowy, aplikacja webowa jest podatna na ataki CSRF, kiedy nie weryfikuje czy otrzymane żądanie HTTP(S) na pewno zostało wysłane przez prawidłowego, zalogowanego użytkownika.
W zasadzie możemy wyróżnić 4 warunki niezbędne do przeprowadzenia udanego ataku CSRF:
- Identyfikacja znaczącej akcji, którą można wywołać za sprawą żądania HTTP(S) w atakowanej aplikacji – np. zmiana hasła do konta użytkownika.
- Aplikacja pamięta zalogowanego użytkownika za sprawą sesji opartej na ciasteczkach – w żądaniach wysyłana jest odpowiednia wartość ciasteczka, potwierdzająca, iż użytkownik został już wcześniej uwierzytelniony.
- Żądanie HTTP(S) nie wymaga dodatkowych, niejawnych parametrów – taki parametr jest w gruncie rzeczy techniką zabezpieczającą przed atakami CSRF i powiemy sobie o nim za chwilę.
- W przypadku żądań XHR wywoływanych przez kod JavaScript (głównie POST), jest niemalże pewne, iż zostaną one zablokowane przez samą przeglądarkę ze względu na politykę Same-origin policy (w skrócie: blokowanie skryptów pochodzących z innego źródła). Może się jednak okazać, iż sama aplikacja webowa jawnie zezwala na wymianę danych między różnymi źródłami za sprawą mechanizmu CORS (Cross-Origin Resource Sharing).
Ataki CSRF, ze względu na swoją charakterystykę, mogą być czasami mylone z atakami typu XSS lub Man in the Browser. Ten pierwszy polega na umieszczeniu na zaatakowanej stronie złośliwego skryptu, który zostanie wykonany przez przeglądarkę ofiary w chwili odwiedzenia tejże witryny. Może on jednak zostać wykorzystany także do przeprowadzenia samego ataku CSRF – wtedy złośliwy skrypt umieszczony za sprawą XSS, zamiast wyciągać dane z przeglądarki ofiary, wykonuje w jej imieniu żądanie do docelowej aplikacji.
Drugi typ ataku (Man in the Browser) działa co prawda na podobnej zasadzie jak CSRF, ale odróżnia się tym, iż wymaga zainstalowania złośliwego systemu w systemie ofiary. Dzięki temu atakujący może wpływać na zachowanie samej przeglądarki.
 Źródło: własne
Źródło: własnePrzeanalizujmy prosty przykład zilustrowany powyżej:
- Użytkownik loguje się na stronę, która jest podatna na atak CSRF.
- Użytkownik został uwierzytelniony, więc aplikacja zwraca identyfikator sesji wraz z unikalnym tokenem uwierzytelniającym. Te dane zostają zapisane w ciasteczku i wysyłane w każdym kolejnym żądaniu do strony – dzięki temu aplikacja wie, iż żądania przychodzą od tego konkretnego użytkownika.
- Atakujący podrzuca w dowolny sposób URL będący złośliwy żądaniem do aplikacji webowej, z której korzysta użytkownik. W tym konkretnym przykładzie jest to żądanie typu GET, powodujące zmianę hasła użytkownika, przemycone w tagu HTML <img>.
- Kiedy przeglądarka zaatakowanego użytkownika będzie próbowała wczytać taki obrazek, spowoduje to wysłanie żądania do aplikacji. jeżeli użytkownik jest aktualnie zalogowany na swoje konto, to przeglądarka dołączy do takiego żądania zawartość ciasteczek przypisanych dla tej domeny, sprawiając, iż aplikacja webowa uzna taką akcję za uwierzytelnioną.
Oczywiście przykład jest bardzo uproszczony i jedynie opisuje ideę ataków Cross Site Request Forgery. W rzeczywistości, większość akcji zmieniających stan aplikacji jest zaimplementowana z użyciem żądań typu POST. Co prawda spreparowanie złośliwego żądania POST jest jak najbardziej możliwe w określonych przypadkach, ale wymaga dużo więcej zachodu. Należałoby wtedy podrzucić użytkownikowi kod JavaScript, który wysyła asynchroniczne żądanie (XHR), ale choćby wtedy takie polecenie najprawdopodobniej zostanie zablokowane przez samą przeglądarkę ze względu na wspomniany już wcześniej mechanizm Same-origin policy.
Dzisiaj wykorzystanie podatności CSRF jest mocno utrudnione ze względu na szereg zabezpieczeń stosowanych zarówno w aplikacjach webowych, jak i samych przeglądarkach. Najpopularniejszą techniką obronną jest tzw. CSRF Token (nazywanym też czasami Anti-Forgery Token). Jest to tajna i unikatowa wartość (trudna do odgadnięcia) wygenerowana po stronie serwerowej aplikacji webowej (ang. server-side) i udostępniona zaufanemu klientowi (użytkownikowi). Kiedy ten chce wykonać jakąś znaczącą akcję, to oprócz danych uwierzytelniających, musi też dołączyć tę wartość do żądania HTTP(S) – wtedy aplikacja wie, iż operacja została zainicjowana przez zaufanego użytkownika. Większość dzisiejszych frameworków programistycznych dodaje taki token automatycznie do formularzy.
Inne techniki zabezpieczające warte wspomnienia to:
- SameSite cookies – zabezpieczenie na poziomie przeglądarki polegające na blokowaniu wysyłania plików cookies, jeżeli żądanie pochodzi z innej strony.
- Referer header validation – weryfikacja nagłówka Referer po stronie aplikacji, czyli sprawdzenie skąd przyszło dane żądanie. Ta technika jest jednak mniej efektywna niż wykorzystanie tokena CSRF.
Jeśli interesują Ciebie szczegóły techniczne, to zachęcam do zapoznania się z moją przykładową aplikacją webową, która w założeniu jest podatna na ataki CSRF. Okazuje się jednak, iż nowoczesne przeglądarki zawierają szereg mechanizmów prewencyjnych, które znacznie utrudniają przeprowadzenie skutecznego ataku, choćby jeżeli programiści popełniają poważne błędy projektowe.
Server-Side Request Forgery (SSRF)
Atak, którego celem są głównie aplikacje webowe. Polega na tym, iż złośliwy użytkownik jest w stanie nakłonić podatną aplikację do wykonania określonego żądania (przeważnie HTTP, ale nie tylko) do zasobów, które nie są bezpośrednio dostępne dla tego użytkownika (np. kiedy dostęp do nich jest możliwy jedynie z sieci wewnętrznej).
Podobnie jak w przypadku podatności CSRF, atak również wykorzystuje fakt, iż ofiara otrzymała kredyt zaufania od usług serwerowych, jednakże różnica polega na tym, iż to nie użytkownik zalogowany do podatnej aplikacji jest celem, ale sama aplikacja.
Jest to raczej rzadko spotykana podatność, ale kiedy już się pojawi może doprowadzić do kompromitacji całego systemu.
Zacznijmy od krótkiego wprowadzenia w kontekst. Kiedy odwiedzamy jakąś stronę internetową, która jest czymś więcej niż tylko wizytówką, istnieje duża szansa, iż oglądamy jedynie webowy interfejs użytkownika (UI = User Interface), będący niewielką częścią bardziej złożonego systemu. Dzisiejsze systemy, choćby te proste, często składają się z przynajmniej kilku elementów – na przykład:
 Źródło: własne
Źródło: własne- Użytkownicy za pośrednictwem przeglądarki internetowej uzyskują dostęp do aplikacji webowej dostępnej pod adresem https://vilya.pl. Jak widać, jest to jedyny serwer całego systemu, dostępny dla świata zewnętrznego i tylko z nim użytkownicy mogą się komunikować bezpośrednio.
- W naszym przykładzie, w sieci wewnętrznej działa inny serwer HTTP, dostępny pod adresem http://192.168.1.10 – przyjmijmy, iż odpowiada on za uwierzytelnienie i autoryzację użytkowników serwisu vilya.pl. Dlaczego ruch odbywa się przez nieszyfrowany protokół HTTP? Otóż zdarza się, iż niefrasobliwy administrator wyjdzie z założenia, iż skoro dostęp do serwera uwierzytelniającego można uzyskać jedynie z zabezpieczonej sieci wewnętrznej, to po co dodatkowe zabezpieczenia, instalowanie certyfikatów SSL/TLS i cała ta zabawa. W końcu, cóż złego może się stać?
- Aplikacja webowa korzysta z bazy danych, która również jest dostępna jedynie z poziomu sieci wewnętrznej.
- Dla urozmaicenia przyjmijmy, iż nasza aplikacja korzysta również z zewnętrznej usługi Amazon S3 do składowania plików wysyłanych (ang. upload) przez użytkowników.
Teraz wyobraźmy sobie następującą sytuację: użytkownik aplikacji webowej vilya.pl wysłał jakiś plik, który zostaje zapisany w chmurze S3, a następnie bezpośredni link do tego pliku jest jemu zwrócony w odpowiedzi. Kiedy wspomniany użytkownik chce pobrać plik, to w żądaniu GET https://vilya.pl/file?url=... wysyłany jest ponownie URL do tego pliku, a serwer, bez żadnej weryfikacji, wykonuje dalsze żądanie (ang. request) na otrzymany adres URL i wynik zwraca użytkownikowi. Dokładnie w tym momencie pojawia się podatność SSRF!
Skoro URL jest w całości wysyłany z aplikacji klienckiej, a następnie odwiedzany przez podatną aplikację bez sprawdzenia jego poprawności, to złośliwy użytkownik może w zapytaniu o plik podmienić adres na ciekawszy, na przykład na: http://192.168.1.10/admin/users. Ponieważ wspomniany serwer wewnętrzny ufa aplikacji webowej (w końcu tylko ona powinna mieć do niego dostęp), to bez wahania zwróci listę użytkowników, a ta zostanie później zwrócona w odpowiedzi (ang. response) atakującemu.
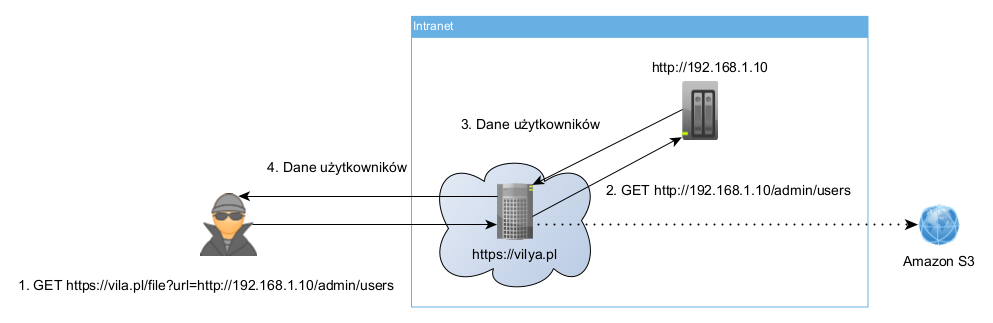 Źródło: własne
Źródło: własneW powyższym przykładzie założyliśmy, iż złośliwy użytkownik (bad actor) poznał infrastrukturę sieci wewnętrznej i znał adres serwera, z którym komunikuje się podatna aplikacja webowa (192.168.1.10). W rzeczywistości architektura całego systemu rzadko kiedy jest znana atakującemu, ale kiedy obecność podatności SSRF zostanie potwierdzona, może on sobie dalej eksperymentować.
Jak wynika z powyższego przykładu, skuteczny atak może doprowadzić do wycieku poufnych informacji, a w niektórych przypadkach choćby do wykonania żądań zmieniających stan systemu.
Zauważmy, iż niechciane żądania (odczytujące dane lub zmieniające stan) mogą trafić do różnych punktów naszego systemu:
- Aplikacja webowa z podatnością SSRF – atakujący może sfingować URL w taki sposób, żeby żądanie trafiło z powrotem do aplikacji, ale tym razem do zasobów, do których normalnie nie ma dostępu – na przykład: http://127.0.0.1/admin/users. Istnieje szansa, iż mechanizmy kontroli dostępu zezwolą na połączenia lokalne bez dodatkowej weryfikacji – w końcu dostęp do maszyny produkcyjnej powinni mieć tylko zaufani użytkownicy.
- Inne systemy backendowe, dostępne jedynie z poziomu sieci wewnętrznej atakowanej organizacji. Mogą to być różnego rodzaju microservice’y, które komunikują się ze sobą przez REST API, a choćby serwery baz danych udostępniające interfejs HTTP (np. MongoDB).
- Zewnętrzne usługi chmurowe, znajdujące się poza siecią organizacji (np. wspomniany już wcześniej Amazon S3). Przypadek jest o tyle ciekawy, iż źródłem takich złośliwych żądań jest zaatakowana organizacja. Warto przy okazji wspomnieć, iż niektóre usługi chmurowe udostępniają interfejsy API (przez protokół HTTP(S)), służące do pobierania metadanych.
- Na przykład, usługa Azure Instance Metadata Service (IMDS) umożliwia wgląd do informacji o aktualnie uruchomionych instancjach maszyn wirtualnych (VMs), a także pozwala na ich konfigurację. Dostęp do REST API jest możliwy tylko lokalnie, z poziomu maszyny wirtualnej, pod adresem 169.254.169.254. jeżeli publiczna aplikacja z podatnością SSRF działa na takiej maszynie wirtualnej, złośliwy użytkownik może wykorzystać IMDS do własnych celów.
W powyższych rozważaniach przyjęliśmy, iż złośliwy użytkownik otrzymuje pożądaną informację zwrotną w odpowiedzi HTTP(S) zaraz po udanym ataku SSRF. Nie zawsze jednak jest tak kolorowo (a adekwatnie to stosunkowo rzadko) i pomimo obecności podatności, brak bezpośredniej odpowiedzi znacząco utrudnia jej wykrycie. Mamy wtedy do czynienia z wariantem blind SSRF, czyli aplikacja umożliwia atak SSRF, ale odpowiedź z backendowych usług nie jest w żaden sposób zwracana użytkownikowi.
Najpopularniejszym sposobem wykrycia i ewentualnego wykorzystania takiej podatności jest zastosowanie technik typu out-of-band, które polegają na tym, iż podatna aplikacja wykonuje zapytanie do zewnętrznego systemu kontrolowanego przez atakującego. W tym przypadku atakujący będzie widział w logach swojego serwera połączenia przychodzące z badanej aplikacji – oznacza to, iż podatność SSRF jest obecna.
Niewykluczone, iż próby połączeń do zewnętrznych serwerów zostaną zablokowane przez firewall atakowanej organizacji, ale i na to znajdzie się sposób.
Jedną z możliwości jest monitorowanie zapytań DNS o domenę będącą w posiadaniu atakującego. jeżeli uda się przemycić URL wskazujący na kontrolowaną domenę istnieje duża szansa na powodzenie, ponieważ rzadko kiedy zapytania do serwerów DNS są blokowane.
Do tej pory skupiliśmy się na protokole HTTP, ale nie tylko on może zostać wykorzystany. Przeważnie pierwsze żądanie zawierające ładunek (ang. payload), czyli niechciany URL, jest wysłane przez HTTP, ale już kolejne żądanie (wykonane przez podatną aplikację) może wykorzystywać inne protokoły. Na przykład, jeżeli przekażemy podatnej aplikacji URL w postaci http://192.168.1.10:21 (port 21 jest domyślny dla usługi FTP), to istnieje szansa, iż żądanie zostanie przekazane do serwera FTP działającego na tej maszynie i ten odpowie.
Posługując się różnymi numerami portów możemy teoretycznie dowiedzieć się, które usługi są dostępne na danym serwerze. Odpowiedzi z działających usług będą przeważnie różniły się czasem odpowiedzi lub samą odpowiedzią (np. komunikatem błędu, jeżeli atakujący ma szczęście).
Innym ciekawym przykładem może być użycie adresu URL ze schematem (ang. scheme) file://, wskazującym na plik znajdujący się w systemie, w którym znajduje się podatna aplikacja.
Temat odpytywania różnych protokołów jest oczywiście dużo bardziej rozbudowany, ale nie będziemy wchodzić w szczegóły, ponieważ jego znajomość dalece wykracza poza zakres materiału obowiązującego na egzaminie.
Identyfikacja podatności
Przyjrzyjmy się sytuacjom, które mogą wskazywać na obecność podatności SSRF w badanej aplikacji:
- W żądaniach (ang. requests) HTTP(S) wysyłane są pełne adresy URL lub ich fragmenty – jest to najprostsza do znalezienia i weryfikacji przesłanka. W przypadku, gdy przesyłana jest tylko część adresu, możliwości wykorzystania podatności mogą być mocno ograniczone.
- Aplikacja przetwarza dane w formacie XML – istnieje szansa, iż parser działający po stronie serwera aplikacji pozwala na umieszczanie zewnętrznych encji (ang. external entities) w dokumencie, co może prowadzić do ataku XXE injection (zdefiniowana przez złośliwego użytkownika encja wskazuje na zasób zawierający wrażliwe dane, a źle skonfigurowany interpreter języka XML dodaje zawartość takiego zasobu do przetwarzanego dokumentu).
- Aplikacja przetwarza zawartość nagłówka HTTP Referer – niektóre aplikacje analizują źródło ruchu, który pojawił się na stronie internetowej i czasami robią to poprzez sprawdzenie zawartości nagłówka Referer, zawierający adres strony internetowej, z której użytkownik został przekierowany do nas. W niektórych przypadkach, ten adres może zostać odwiedzony przez aplikację celem zdobycia bardziej szczegółowych informacji o źródle. Atakujący ma więc sposobność na spreparowanie takiego nagłówka, podając określony adres URL, choć miejmy na uwadze, iż jest to raczej przykład wariantu blind SSRF.
- W aplikacji występuje podatność open redirect – w wielu aplikacjach webowych użytkownik jest automatycznie przekierowywany na określone podstrony po wykonaniu jakiejś akcji (np. automatyczne przekierowanie na stronę z informacjami profilowymi po poprawnym zalogowaniu). jeżeli użytkownik może kontrolować docelowy adres przekierowania (np. w sytuacji gdy ten jest umieszczany jawnie w parametrze URL: /product/nextProduct?currentProductId=6&redirect_url=http://evil-user.net), to mamy do czynienia ze wspomnianą podatnością open redirect.
Obrona
Najpopularniejsze metody zapobiegania i ograniczania skutków ataku SSRF:
- Input sanitization – innymi słowy, dokładne sprawdzanie danych, które przychodzą od użytkownika, szczególnie jeżeli aplikacja przetwarza je w szerszym zakresie niż tylko zapisanie ich w bazie danych. Przede wszystkim należy unikać sytuacji, gdzie aplikacja otrzymuje na wejściu adresy URL, na podstawie których wykonuje dalsze żądania.
- Stosowanie rozwiązań typu WAF (Web Application Firewall), które są w stanie wykryć żądania HTTP z podejrzanymi lub niechcianymi danymi i je zablokować, zanim jeszcze dotrą do naszej aplikacji.
- Sama aplikacja webowa powinna mieć ograniczone uprawnienia, jeżeli chodzi o komunikowanie się z innymi usługami w sieci organizacji. Dodatkowo, firewall sieciowy powinien zezwalać jedynie na ruch z i do określonych serwerów, czyli tam gdzie komunikacja jest spodziewana.
Generalnie, zalecanym podejściem jest defence in depth, czyli koncept wywodzący się ze strategii militarnej i polegający na zapewnieniu bezpieczeństwa na poziomie wszystkich warstw systemu IT organizacji, a nie tylko tej na styku ze światem zewnętrznym.
Warto również wspomnieć, iż bardziej zaleca się podejście allow list (co nie jest dozwolone, to jest zabronione) niż block list (co nie jest zabronione, jest dozwolone). Wynika to z faktu, iż bardzo łatwo jest przeoczyć jakiś scenariusz podczas definiowania listy niedozwolonych działań.
Istnieją różne sposoby obchodzenia wspomnianych zabezpieczeń i filtrów m.in. poprzez wykorzystywanie technik URL encoding (np. spacja w URL jest zapisywana jako %20), ale jest to temat wykraczający poza to opracowanie. Mimo wszystko, chciałbym przedstawić jeden interesujący przykład. Załóżmy, iż jeden z filtrów blokuje żądania, która zawierają URL z adresem pętli zwrotnej (ang. loopback), czyli 127.0.0.1. Okazuje się jednak, iż taki adres IPv4 może mieć kilka reprezentacji i wszystkie są prawidłowe:
- 127.0.0.1
- 0177.0.0.1
- 0x7f.0.0.1
- 127.0.1
- 127.1
- 2130706433
- 017700000001
- 0x7f000001