Tematyka sztucznej inteligencji zagościła na stałe w nagłówkach prasowych, głównie za sprawą ChatGPT. O ile AI oparte na języku naturalnym budzi sporo emocji, to nie sposób nie zauważyć roli sztucznej inteligencji w rozpoznawaniu obrazów. Tutaj jednym z pionierów jest Google i środowisko Vision AI.
Już ponad pięć lat temu zespół programistów z Google Cloud rozpoczął współpracę z jednym z najbardziej opiniotwórczych dzienników – The New York Times. W przepastnych, nowojorskich archiwach znajduje się, jak oszacowano, od pięciu do siedmiu milionów zdjęć wykonanych w przeciągu ostatnich 100 lat. Wiele z nich skrywa nigdy nieopowiedziane historie.
Kiedy w 2015 roku, na skutek pękniętej rury część tego archiwum znalazła się pod wodą, kierownictwo NYT postanowiło podjąć kroki mające na celu ochronę bezcennego dobytku. Wybrano chmurę Google, której usługi, takie jak Cloud Storage, Cloud Pub/Sub, Google Kubernetes Engine pozwoliły na stworzenie cyfrowej, dobrze zabezpieczonej bazy zdjęć.
Chociaż cel został spełniony i można byłoby na tym poprzestać, postanowiono pójść dalej i wykorzystać modele uczenia maszynowego w celu lepszego zrozumienia zawartości archiwum. W tym miejscu wkroczyło Google Cloud Vision API, które pozwoliło automatycznie identyfikować miejsca oraz obiekty znajdujące się na fotografiach, dzięki czemu przeszukiwanie bazy zdjęć stało się o wiele łatwiejsze.
Czym jest Vision AI?
Vision AI to środowisko, w ramach którego dostępnych jest kilka kluczowych usług Google Cloud łączących możliwości uczenia maszynowego (Vertex AI Vision) z rozpoznawaniem i wyszukiwaniem obrazów (Vision API, AutoML Vision). Skupmy się na tych dwóch ostatnich.
AutoML Vision
Rozwiązanie to umożliwia trenowanie modeli uczenia maszynowego w celu klasyfikowania obrazów zgodnie z własnymi zdefiniowanymi etykietami. Możesz dzięki niemu trenować modele na podstawie oznaczonych obrazów oceniając dokładność, z jaką zostały etykietowane.
Co więcej, możesz zastosować uczenie maszynowe do nadania etykiet pozostałym obrazom, na podstawie już stworzonych ludzką ręką oznaczeń. Ostatecznie celem jest stworzenie rejestrów przeszkolonych modeli, które mogą być udostępniane za pośrednictwem interfejsu API AutoML.
AutoML Vision w praktyce – przeglądy techniczne turbin wiatrowych
AutoML Vision jest narzędziem, które pozwala firmom na spore oszczędności czasu i pieniędzy. Jednym z przykładów jest firma AES, działający w 15 krajach dystrybutor energii odnawialnej. AES posiada osiem farm wiatrowych, a na każdej z nich znajduje się od 50 do 300 turbin.
Urządzenia te wymagają regularnych inspekcji technicznych. Wcześnie wykryte uszkodzenie łopaty wirnika może zapobiec tragedii. Tradycyjne inspekcje trwały około dwóch tygodni, dla każdej z farm. AES zdecydował się zlecić przeprowadzanie inspekcji specjalistycznej firmie korzystającej z dronów, dzięki czemu udało się skrócić ten czas do dwóch dni.
Podczas audytu wykonywanych jest choćby 30 tys. Zdjęć, które muszą następnie przejść weryfikację w celu sprawdzenia, czy na powierzchni wiatraków nie pojawiły się pęknięcia. Przed wykorzystaniem modeli AutoML Vision, cały ciężar weryfikacji spadał na wysoko wykwalifikowanych inżynierów, którzy na przejrzenie zdjęć potrzebowali czterech tygodni pracy. Dzięki wytrenowaniu modelu, narzędzie dostępne w ramach Google Cloud pozwoliło skrócić ten czas o połowę – pozostawiając do zatwierdzenia 15 tys. zdjęć.
W jaki sposób działa AutoML Vision?
W AutoML Vision, bez względu na rodzaj przetwarzanych danych, ścieżka działania jest zawsze podobna i składa się z sześciu etapów:
- Przygotowanie danych do trenowania.
- Stworzenie zbioru danych.
- Wytrenowanie modelu.
- Ewaluacja oraz prowadzenie iteracji modelu.
- Uzyskanie prognozy.
- Interpretacja rezultatów.
AutoML Vision działa na czterech typach danych: obrazach, filmach, tekstach oraz danych tabularycznych. Są to gotowe rozwiązania, ale jeżeli żadne z nich nie spełnia specyficznych wymagań w ramach projektu, możliwe jest stworzenie własnego customowego modelu dostosowanego do trenowania niestandardowych modeli w Vertex AI. Możliwości jest sporo, można skonfigurować zasoby obliczeniowe na potrzeby trenowania ML, w tym typ i liczbę maszyn wirtualnych, GPU, czy TPU.
Cloud Vision API
Google Cloud Vision API daje nam dostęp do zaawansowanych, wstępnie wytrenowanych modeli uczenia maszynowego. Dzieje się to za pośrednictwem interfejsów REST API oraz RPC API. Dzięki Vision API można przypisywać etykiety do obrazów i bardzo gwałtownie klasyfikować je w milionach predefiniowanych kategorii. W ramach szerokich możliwości dostępne jest wykrywanie obiektów, odczytywanie tekstów, zarówno drukowanych, jak i pisanych odręcznie oraz budowanie metadanych w katalogu obrazów.
Cloud Vision API pozwala uruchomić nowe aplikacje do analizy obrazów oraz filmów w ciągu zaledwie kilku minut. Możliwe jest też trenowanie modeli uczenia maszynowego klasyfikujących obrazy zarówno przy użyciu AutoML Vision jak i modeli niestandardowych. Warto też pamiętać o łatwości integracji Cloud Vision API z BigQuery czy Cloud Functions powiększając zakres działania.
Połączenie Vision API z AutoML Vision
Aby jeszcze lepiej wykorzystać uczenie maszynowe i sztuczną inteligencję, warto łączyć działanie AutoML Vision z Vision API. Poniższy schemat pokazuje przykładowy, często wykorzystywany model.
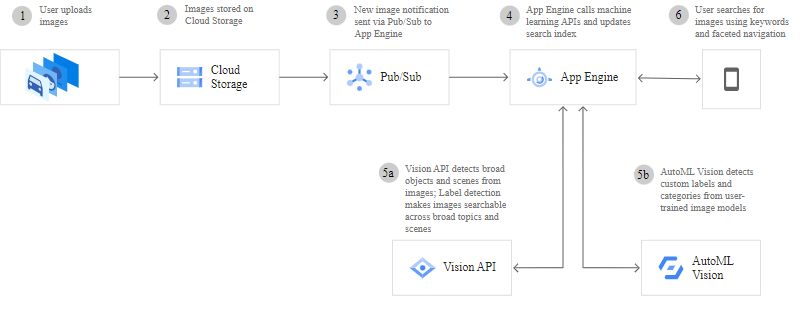
W pierwszym kroku użytkownik wgrywa obrazy, które trafiają do Cloud Storage. Za każdym razem, gdy pojawi się nowy obraz, notyfikacja o tym trafia do App Engine za pośrednictwem Pub/Sub. W kolejnym kroku App Engine wywołuje API uczenia maszynowego. Możliwe są dwie drogi.
W pierwszej z nich Vision API rozpoznaje zgrubnie obiekty i sceny ze zdjęć. Przydaje się przy tym rozpoznawanie etykiet, co sprawia, iż zdjęcia można później przeszukiwać pod kątem konkretnych elementów.
W drugiej ścieżce AutoML Vision rozpoznaje niestandardowe etykiety na podstawie wytrenowanych uprzednio modeli.
W obu przypadkach wyniki wracają do App Engine, a użytkownik może teraz odnaleźć zadany obraz na podstawie słów kluczowych.
Benefity płynące z Vision AI w Google Cloud
Wiemy już, iż trenowanie modeli do rozpoznawania obrazów ma swój efekt w skracaniu czasu pracy, a co za tym idzie, w sporej oszczędności finansowej. Ma to również wpływ na jakość podejmowanych decyzji biznesowych. Możemy wszak odnieść się do pełnych danych, a nie tylko wnioskować na podstawie reprezentatywnego przykładu. Modele są ciągle udoskonalane, oprócz rozpoznawania konkretnych obiektów, mogą też analizować nastrój, czy emocje widoczne na twarzach.
Dzięki narzędziom Vision AI służącym do odczytywania tekstu (OCR) ze zdjęć, jesteśmy w stanie szybciej tworzyć i przeszukiwać bogate zbiory danych. Ma to znaczenie zarówno przy archiwizacji, jak i organizacji treści.
Poznaj możliwości Vision AI
Dowiedz się, jak wykorzystać Vision API i AutoML Vision w Twoim projekcie
Jak skorzystać z AutoML Vision i Vision API w praktyce?
Aby lepiej wykorzystać potencjał narzędzi stojących za Vision AI od Google, warto skorzystać z pomocy partnera Google Cloud. Czasami kilka minut rozmowy z certyfikowanym architektem chmurowym (Cloud Architect) pomoże w podjęciu decyzji, czy dane narzędzie sprawdzi się w Twoim przypadku. Przy okazji poznasz koszty i sposoby ich optymalizacji, a o ile jeszcze nie współpracowałeś z oficjalnym partnerem, takim jak FOTC, to czeka na Ciebie voucher na kwotę 500 dolarów, który możesz wykorzystać na dowolne usługi w obrębie chmury Google Cloud, więc tym bardziej warto.








