To nie tylko problem samej Wikipedii, a sygnał ostrzegawczy dla całego otwartego Internetu.
Historia zaczyna się dość nieoczekiwanie – w maju zespół Wikimedia Foundation zauważył niezwykle wysoką liczbę pozornie ludzkiego ruchu pochodzącego głównie z Brazylii. Wydawało się, iż nagle miliony Brazylijczyków odkryły fascynację wolną wiedzą. Rzeczywistość okazała się jednak mniej optymistyczna.
Po dokładniejszej analizie inżynierowie odkryli coś niepokojącego: to były boty, bardzo zaawansowane boty, zaprojektowane tak, by naśladować zachowanie prawdziwych użytkowników. Interpretowały JavaScript, zmieniały rytm zapytań i maskowały wzorce automatyzacji – wszystko po to, by wyglądać jak żywi czytelnicy przeglądający artykuły o historii Brazylii czy bioróżnorodności Amazonii.
Gdy Wikimedia zaktualizowała swoje systemy wykrywania botów i zastosowała nową wsteczną logikę do danych z marca-sierpnia okazało się, iż znaczna część wzrostu ruchu była iluzją. A po usunięciu sztucznego szumu statystyki pokazały coś znacznie bardziej niepokojącego: rzeczywisty ludzki ruch spadł o około 8 proc. w porównaniu z tymi samymi miesiącami w ubiegłym roku.
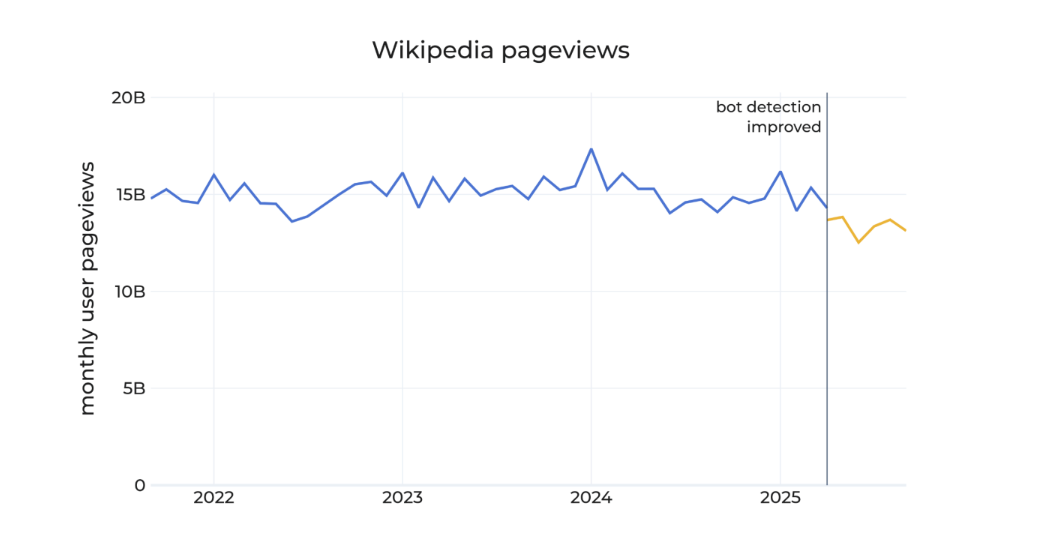 Liczba odsłon Wikipedii we wszystkich wersjach językowych od września 2021 r., ze zrewidowaną liczbą odsłon od kwietnia 2025 r.
Liczba odsłon Wikipedii we wszystkich wersjach językowych od września 2021 r., ze zrewidowaną liczbą odsłon od kwietnia 2025 r.Niemile widziani goście, którzy zjadają kolację
Senior director of product w Wikimedia Foundation, Marshall Miller, nie owija sprawy w bawełnę w oficjalnym wpisie na blogu organizacji. Przyznał wprost, iż spadki ruchu odzwierciedlają wpływ sztucznej inteligencji generatywnej i mediów społecznościowych na to, jak ludzie szukają informacji. Szczególnie wskazał na wyszukiwarki – przede wszystkim Google – które coraz częściej dostarczają odpowiedzi bezpośrednio użytkownikom, często opierając się na treściach Wikipedii, ale nie wysyłając nikogo na samą stronę.
Ironii całej sytuacji dodaje fakt, iż podczas gdy AI i wyszukiwarki powodują spadek bezpośredniego ruchu do Wikipedii tak jej dane stały się bardziej wartościowe niż kiedykolwiek. Artykuły z Wikipedii należą do najczęściej wykorzystywanych danych treningowych dla modeli AI. Praktycznie wszystkie duże modele językowe trenują na zbiorach danych właśnie z Wikipedii. Google i inne platformy od lat wydobywają artykuły tej encyklopedii, aby zasilać swoje fragmenty (Snippets) i panele wiedzy (Knowledge Panels), które odciągają ruch od samej Wikipedii.
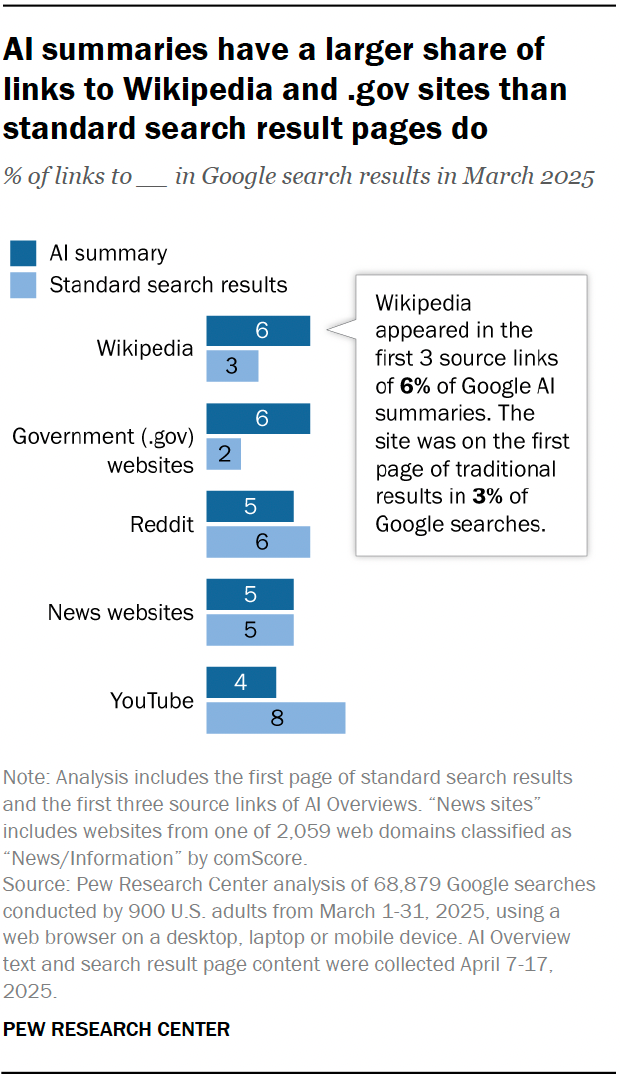 Wikipedia jest jednym z głównych źródeł danych dla AI (źródło: Pew)
Wikipedia jest jednym z głównych źródeł danych dla AI (źródło: Pew)To sytuacja, w której ktoś korzysta z twojej biblioteki, by nauczyć się wszystkiego, co wiesz, a potem staje przed drzwiami i odpowiada na pytania za ciebie. Tylko iż ta biblioteka musi zapłacić rachunki za prąd.
Zaledwie 1 proc. użytkowników klika w źródła AI. Tak, dobrze przeczytaliście
Jeśli myślicie, iż to tylko problem Wikipedii, to mam dla was złe wieści. To znacznie szersze zjawisko. Badanie Pew Research Center z lipca rzuca światło na całą skalę problemu. Gdy Google wyświetla podsumowanie AI (AI Overview) w wynikach wyszukiwania to użytkownicy klikają w tradycyjne linki wyników wyszukiwania tylko w 8 proc. przypadków – to prawie o połowę mniej niż 15 proc. przy wyszukiwaniach bez podsumowań AI.
Co więcej – i to naprawdę boli – zaledwie 1 proc. użytkowników klika w linki źródłowe zawarte w samych podsumowaniach AI. Jeden procent. To tak jakby napisać książkę, dać ją komuś do przeczytania, ten ktoś opowiedziałby jej treść innym osobom, a tylko jedna na sto faktycznie zajrzałaby do oryginału, żeby sprawdzić, czy to prawda.
Badanie Pew odkryło również, iż użytkownicy, którzy zobaczyli podsumowanie AI częściej kończyli swoją sesję przeglądania całkowicie – 26 proc. w porównaniu z 16 proc. przy tradycyjnych wynikach wyszukiwania. Innymi słowy: dostają odpowiedź i odchodzą, choćby nie odwiedzając żadnej strony internetowej.
Młode pokolenie woli TikToka od otwartego Internetu
Wyszukiwarki AI to nie jedyny problem. Marshall Miller wskazał również na kolejny niepokojący trend: młodsze pokolenia szukają informacji na platformach społecznościowego wideo, a nie w otwartym Internecie. Dane są jednoznaczne.
Badanie z ubiegłego roku wykazało, iż 64 proc. przedstawicieli pokolenia Z w Stanach Zjednoczonych używało TikToka jako wyszukiwarki internetowej. To najwyższy wskaźnik spośród wszystkich pokoleń. Według danych Google z 2022 r. prawie 40 proc. młodych ludzi używa TikToka lub Instagrama do wyszukiwania zamiast Google’a.
Dlaczego? Bo preferują wizualny charakter wyników wyszukiwania TikToka – od rekomendacji produktów przez instrukcje krok po kroku po plany podróży. Dla pokolenia wychowanego na krótkich, dynamicznych filmikach czytanie długiego artykułu na Wikipedii może wydawać się reliktowym doświadczeniem z czasów przed telefonami.
Ruch organiczny z wyszukiwarek spada o 26 proc. – to dopiero początek
Wracając do samej Wikipedii – problem nie ogranicza się tylko do bezpośrednich wizyt. Dane z Semrush pokazują, iż ruch organiczny z wyszukiwarek do Wikipedii spadł z około 5,8 mld wizyt miesięcznie w styczniu 2022 r. do 4,3 mld w marcu 2025. To spadek o 1,5 mld wizyt miesięcznie, czyli 26 proc. mniej ruchu organicznego w ciągu trzech lat.
Similarweb potwierdza ten trend, raportując 23 proc. spadek ruchu organicznego z wyszukiwarek w tym samym okresie. Co ciekawe, dane Similarweb pokazują również delikatny spadek bezpośredniego ruchu do Wikipedii – o około 12 proc. – ale absolutna wielkość tych zmian jest znacznie mniejsza. Ruch organiczny z wyszukiwarek stanowił zdecydowanie większy udział w całkowitym ruchu, więc jego spadek odpowiada za około 96 proc. całkowitego spadku ruchu Wikipedii w ciągu ostatnich trzech lat.
Inne badanie wykazało, iż między marcem 2022 a marcem 2025 dzienne wizyty w Wikipedii spadły ze 165 mln do nieco poniżej 128 mln – to spadek o 23 proc. W przeliczeniu na miesiąc to ponad 1,1 mld utraconych wizyt co miesiąc.
Wolontariusze i darowizny, czyli chwiejny fundament
Tu dochodzimy do sedna problemu – i dlaczego Wikimedia Foundation traktuje tę sytuację jako zagrożenie dla długoterminowej przyszłości Wikipedii. Ta nie jest zwykłą stroną internetową. Nie ma reklam. Nie sprzedaje subskrypcji. Finansuje się głównie z darowizn od indywidualnych czytelników na całym świecie – średnia darowizna w roku fiskalnym 2023-2024 wynosiła zaledwie 10,58 dol., ale pochodziła od ponad 8 mln darczyńców.
Model biznesowy Wikipedii opiera się na prostym założeniu: ludzie, którzy czytają Wikipedię, czasami stają się darczyńcami. A czytelnicy czasami stają się również redaktorami-wolontariuszami – osobami, które researczują, debatują, budują konsensus i wspólnie piszą największą encyklopedię, jaką ludzkość kiedykolwiek stworzyła.
Ale jeżeli ludzie przestają odwiedzać Wikipedię, bo chatbot AI lub Google już odpowiedział na ich pytanie? Miller był jasny w swojej ocenie: Przy mniejszej liczbie wizyt w Wikipedii mniej wolontariuszy może rozwijać i wzbogacać treści, a mniej indywidualnych darczyńców może wspierać tę pracę.
To nie jest hipotetyczny problem. Społeczność redaktorów Wikipedii już zgłasza, iż patrolowanie fałszywych treści generowanych przez AI sprawiło, iż ich praca stała się mniej przyjemna i bardziej wyczerpująca. To, co kiedyś było satysfakcjonującym hobby związanym z dzieleniem się wiedzą ryzykuje przekształcenie się – jak ujęli to niektórzy – w coraz bardziej śledczy i antagonistyczny proces. jeżeli współudział przestanie być zabawą lub satysfakcją to wielu po prostu odejdzie. Wielu już odeszło.
Bardziej potrzebni, mniej widoczni
Wikimedia Foundation w swoim planie rocznym na lata 2024-2025 opisała sytuację jako strategiczny paradoks. Projekty Wikimedii stają się bardziej istotne dla infrastruktury wiedzy w Internecie, a jednocześnie stają się mniej widoczne dla użytkowników Internetu.
Są bardziej istotne, ponieważ Wikipedia jest pochłaniana przez duże modele językowe, które kształtują przyszłość wyszukiwania informacji – nie tylko w wyszukiwarkach, ale także poza nimi. Według wielu szacunków angielska Wikipedia stanowi jeden z najważniejszych zbiorów danych do trenowania dużych modeli językowych i jest jednym z najwyżej ocenianych pod względem jakości.
Ogólnie rzecz biorąc, to dobra rzecz – wiarygodna AI potrzebuje wiarygodnej bazy faktów. Problem w tym, iż treści Wikimedii stają się mniej widoczne, ponieważ coraz bardziej zamknięty i pośredniczony przez AI Internet nie podaje źródła prezentowanych faktów, ani choćby nie linkuje z powrotem do Wikipedii. Umowa społeczna, która leży u podstaw wykorzystania treści przez strony trzecie, jest zagrożona.
Co Wikipedia zamierza zrobić? Polityki, partnerstwa i… TikTok
Wikimedia Foundation nie siedzi bezczynnie. Miller powiedział, iż organizacja egzekwuje polityki, opracowuje ramy dla atrybucji i rozwija nowe możliwości techniczne, aby zapewnić, iż strony trzecie odpowiedzialnie uzyskują dostęp do treści Wikipedii i je ponownie wykorzystują. Fundacja kontynuuje również wzmacnianie swoich partnerstw z wyszukiwarkami i innymi dużymi ponownymi użytkownikami.
Wikimedia ma zasady dla zewnętrznych botów, które crawlują jej treści, takie jak określanie informacji identyfikujących i przestrzeganie robots.txt oraz limity częstotliwości żądań i współbieżnych żądań. Jednak Miller przyznał, iż z oczywistych powodów nie może dzielić się publicznie szczegółami dotyczącymi dokładnych metod blokowania i wykrywania botów.
Fundacja pracuje również nad wprowadzeniem treści Wikipedii do młodszych odbiorców za pośrednictwem… YouTube’a, TikToka, Robloxa i Instagrama. jeżeli nie możesz ich pokonać, dołącz do nich – ale na swoich warunkach.
W kwietniu Wikimedia ogłosiła również nową strategię AI na kolejne trzy lata, która kładzie nacisk na wspieranie wolontariuszy, a nie zastępowanie ich. AI będzie wykorzystywane do automatyzacji żmudnych zadań, poprawy wykrywalności informacji, automatycznego tłumaczenia i wspomagania wdrażania nowych wolontariuszy – wszystko po to, by ludzie mogli skupić się na tym, w czym są naprawdę niezbędni: deliberacji, osądzie i budowaniu konsensusu.
Ale Miller wydał również wezwanie bezpośrednio do użytkowników Internetu: Kiedy szukacie informacji online, szukajcie cytatów i klikajcie na oryginalny materiał źródłowy. (…) Rozmawiajcie z ludźmi których znacie o znaczeniu zaufanej, porządkowanej przez ludzi wiedzy i pomóżcie im zrozumieć, iż treści leżące u podstaw sztucznej inteligencji generatywnej zostały stworzone przez prawdziwych ludzi, którzy zasługują na ich wsparcie. To apel o świadomość – o to, by pamiętać, iż za każdym artykułem Wikipedii stoją ludzie, którzy poświęcili swój czas, wiedzę i pasję, żeby go napisać.
I iż ci ludzie nie otrzymują pensji od OpenAI, Google czy Anthropic, mimo iż ich praca zasila miliardy odpowiedzi AI codziennie.
Czy to koniec otwartego Internetu, jaki znaliśmy?
Sytuacja Wikipedii to mikrokosmiczne odbicie znacznie większego problemu. Inni wydawcy i platformy treści również zgłaszają podobne zmiany, ponieważ użytkownicy spędzają więcej czasu w wyszukiwarkach, chatbotach AI i mediach społecznościowych, aby znaleźć informacje. Doświadczają również obciążenia, jakie te firmy nakładają na ich infrastrukturę.
W kwietniu Wikimedia zgłosiła, iż boty AI obciążyły ich przepustowość o 50 proc. i automatyczne boty poszukujące danych treningowych zagrażają stabilności projektu Wikipedia. Niektóre z tych agentów omijają polecenia robots.txt, podczas gdy inne naśladują user agenty przeglądarek, aby udawać prawdziwych użytkowników. Niektóre crawlery rotują między adresami IP rezydencjalnymi, aby uniknąć blokowania.
Czy możemy mieć jedno i drugie? Czy możemy czerpać korzyści z AI – szybkie, spersonalizowane odpowiedzi na skomplikowane pytania – zachowując jednocześnie otwartą, zrównoważoną infrastrukturę wiedzy, która zasila te systemy?
Odpowiedź nie jest prosta. Wymaga to przemyślenia umów społecznych, które rządzą Internetem. Wymaga to uznania, iż bezpłatna wiedza nie jest naprawdę bezpłatna – jest opłacana milionami godzin pracy wolontariuszy i wspierana przez darowizny miliardów użytkowników. Wymaga to atrybucji, przejrzystości i – być może najważniejsze – kultury cyfrowej, która ceni nie tylko odpowiedź, ale również źródło.
Dane Wikipedii są jasne: wolimy słuchać AI od czytania oryginałów. Co stracimy, gdy przestaniemy czytać całkowicie? I czy będziemy wiedzieć, co straciliśmy, dopóki nie będzie już za późno? Bo jedna rzecz jest pewna: nie można w nieskończoność czerpać z studni, do której nikt nie dolewa wody. A Wikipedia właśnie ostrzegła nas, iż poziom wody niebezpiecznie spada.
*Zdjęcie otwierające: DIA TV / Shutterstock








