4W poprzednich wpisach zrobiłem przegląd istniejących algorytmów/systemów służących do wykrywania plagiatów w kodach źródłowych. W tym wpisie przedstawię ogólny zarys algorytmu, który wybrałem.
PlagDetector – algorytm
Głównym podejściem, wokół którego będzie koncentrował się mój system został opisany przeze mnie w tym wpisie. Chodzi o wykrywanie plagiatów przy użyciu aproksymacji złożoności Kołmogorowa.
Aplikacja będzie składała się z trzech głównych etapów.
Tokenizacja
Pierwszym etapem algorytmu jest poddanie kodu źródłowego tokenizacji.
Bardzo istotną rzeczą, jest dobranie odpowiedniego zestawu tokenów. Ztokenizowany kod programu powinien dobrze oddawać strukturę i logikę programu. Zbyt dokładne tokenizowanie może doprowadzić do pominięcia wykrycia plagiatu z powodu sprawdzania i porównywania nieistotnych informacji. Z drugiej strony, niewystarczająco dokładna tokenizacja może doprowadzić to fałszywych wskazań. Zestaw tokenów oraz sama tokenizacja jest przeprowadzona pod kątem danego języka programowa. Dzięki temu uzyskany ciąg tokenów powinien dobrze oddać strukturę programu. W Listingu poniżej znajduje się fragment przykładowego kodu i odpowiadający mu przykładowy ciąg tokenów.
String var; VARIABLE_DECLARATION int i; VARIABLE_DECLARATION i = 3; IDENTIFIER ASSIGN IDENTIFIER if (i > 2) { IF_SWITCH_STATEMENT_BEGIN OPEN_PARENTHESIS IDENTIFIER CONDITION IDENTIFIER CLOSE_PARENTHESIS var = "more than 2"; IDENTIFIER ASSIGN STRING } IF_SWITCH_STATEMENT_END else { IF_SWITCH_STATEMENT_BEGIN var = "less than 2"; IDENTIFIER ASSIGN STRING } IF_SWITCH_STATEMENT_ENDKompresja tokenów
Główną rzeczą przy wyborze algorytmu kompresji była konieczność wyboru takiego algorytmu, który będzie bezstratny, ale jego stopień kompresji będzie możliwie duży. Na podstawie testów i doświadczeń autorów systemu SID (opisanego w poprzednim wpisie) wybór padł na algorytm LZ77.
Najważniejszą modyfikacją, którą wprowadzę do implementowanego algorytmu kompresji w stosunku do oryginalnego algorytmu LZ77 jest nieograniczony bufor słownika oraz nieograniczony bufor wejściowy. Dzięki takiemu podejściu stopień kompresji danych będzie większy niż w przypadku, gdy bufory słownika i wejściowy są ograniczone. Podejście to w oczywisty sposób powoduje wydłużenie działania algorytmu, ale taki zabieg jest konieczny, aby uzyskać jak najbardziej dokładnie wyniki. Poniżej przedstawiłem pseudokod zmodyfikowanego algorytmu kodowania LZ77.
Require: Input while(Input nie jest pusty) do znajdz najdluzszy prefiks z Input znajdujacy sie w slowniku if (znaleziono dopasowanie) then dodaj do slownika trojke (left_shift, length, mismatch_token) // gdzie: // left_shift - przesuniece w lewo // length - dlugosc dopasowanego ciagu // mismatch_token - pierwszy niepasujacy token przesun wskaznik o length + 1 else dodaj do slownika trojke (0, 0, mismatch_token) // gdzie: // mismatch_token - pierwszy token na wejsciu przesun wskaznik o 1 end if end whileWielkością skompresowanego ciągu jest ilość wpisów w słowniku pomnożona przez (shift_size + length_size + token_size), gdzie:
- shift_size – wielkość w bajtach potrzebna do zakodowania przesunięcia w lewo;
- length_size – wielkość w bajtach potrzebna do zakodowania długości;
- token_size – wielkość w bajtach potrzebna do zakodowania jednego tokena.
Aproksymacja złożoności Kołmogorowa
Wartość aproksymacji Kołmogorowa jest przybliżana przy pomocy wzoru:
 .
.
Przez 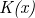 w przypadku konstruowanego algorytmu będzie rozumiana wielkość (w bajtach) skompresowanego programu i będzie oznaczana jako
w przypadku konstruowanego algorytmu będzie rozumiana wielkość (w bajtach) skompresowanego programu i będzie oznaczana jako  . W związku z tym wzór na przybliżenie aproksymacji Kołmogorowa przyjmie postać:
. W związku z tym wzór na przybliżenie aproksymacji Kołmogorowa przyjmie postać:
 .
.
Wartość  zostanie przybliżona w następujący sposób:
zostanie przybliżona w następujący sposób:
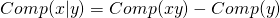 .
.
Zatem ostatecznie wartość aproksymacji Kołmogorowa zostanie obliczone ze wzoru:
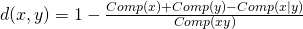 .
.
Tak obliczona wartość aproksymacji złożoności Kołmogorowa jest przeliczana na współczynnik R według wzoru:
 .
.
Wskaźnik ten służy za wskaźnik prawdopodobieństwa zajścia plagiatu. Im wartość 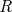 jest większa, tym prawdopodobieństwo plagiatu jest większe.
jest większa, tym prawdopodobieństwo plagiatu jest większe.
Dodatkowo dla każdej pary programów obliczane są wartości  oraz
oraz  . Wartości te przedstawiają procentową zawartość informacji z jednego ciągu zawartych w drugim. Wartości te obliczane są w sposób następujący:
. Wartości te przedstawiają procentową zawartość informacji z jednego ciągu zawartych w drugim. Wartości te obliczane są w sposób następujący:
 ,
,
 , gdzie:
, gdzie:
 .
.
Wskaźniki i służą jako dodatkowa informacja, wskazująca na zawartość jednego ciągu w drugim. Wartości te mogą wykazać zajście plagiatu, w przypadku gdy jeden z programów zawiera w sobie kod drugiego, ale sam program jest o wiele bardziej rozbudowany i wartość współczynnika R może nie wskazać zajścia plagiatu.
Podsumowanie
W tym wpisie omówiłem algorytm, który planuję zaimplementować. Składa się on z 3 głównych kroków – tokenizacji, kompresji i aproksymacji złożoności Kołmogorowa. W kolejnych wpisach postaram się bardziej przybliżyć każdy z tych etapów.
.jpg)







