W poprzednim wpisie dotyczącym PlagDetectora zajmowaliśmy się kompresją tokenów. Dzisiaj zajmiemy się trzecim i zarazem ostatnim krokiem naszego algorytmu, a mianowicie wyliczaniem podobieństwa pomiędzy kodami źródłowymi.
Mała powtórka
Na początku wróćmy do wpisu gdzie omawialiśmy cały algorytm i przypomnijmy sobie kilka wzorów.
Wartość aproksymacji Kołmogorowa będziemy przybliżać przy pomocy poniższego wzoru.
 .
.
Przez 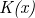 będziemy rozumieć wielkość (w bajtach) skompresowanego kodu źródłowego i będziemy oznaczać jako
będziemy rozumieć wielkość (w bajtach) skompresowanego kodu źródłowego i będziemy oznaczać jako  . W związku z tym wzór na przybliżenie aproksymacji Kołmogorowa przyjmie postać:
. W związku z tym wzór na przybliżenie aproksymacji Kołmogorowa przyjmie postać:
 .
.
Wartość  obliczymy w następujący sposób:
obliczymy w następujący sposób:
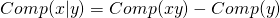 .
.
Zatem ostatecznie wartość aproksymacji Kołmogorowa obliczymy z następującego wzoru:
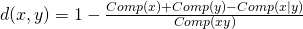 .
.
Tak obliczona wartość aproksymacji złożoności Kołmogorowa przeliczymy na współczynnik  według wzoru:
według wzoru:
 .
.
I ten właśnie wskaźnik będzie naszym głównym wyznacznikiem, którego będziemy używać do oceny prawdopodobieństwa zajścia plagiatu. Im wartość jest większa, tym prawdopodobieństwo plagiatu jest większe.
Dodatkowo dla każdej pary programów obliczymy wartości  oraz
oraz  . Wartości te będą przedstawiać procentową zawartość informacji z jednego kodu źródłowego zawartych w drugim. Wartości te obliczymy używając następujących wzorów:
. Wartości te będą przedstawiać procentową zawartość informacji z jednego kodu źródłowego zawartych w drugim. Wartości te obliczymy używając następujących wzorów:
 ,
,
 , gdzie:
, gdzie:
 .
.
Wskaźniki i posłużą nam jako dodatkowa informacja, wskazująca na zawartość jednego ciągu w drugim. Wartości te pomogą nam wskazać zajście plagiatu, w przypadku gdy jeden z programów zawiera w sobie kod drugiego, ale sam program jest o wiele bardziej rozbudowany i wartość współczynnika może nie wskazać zajścia plagiatu.
I teraz kodowanie!
Zacznijmy od klasy, która przechowa nasze wyniki.
package pl.lantkowiak.plagdetector.algorithm.kolmogorov data class KolmogorovCalculationResult(val d: Double, val px: Double, val py: Double)Podobnie jak przy tworzeniu klasy do przechowywania wyników kompresji – banał
Teraz pora na obliczenia!
class KolmogorovCalculator { fun calculate(encodedData1Size: Int, encodedData2Size: Int, encodedData1_2Size: Int): KolmogorovCalculationResult { val d = calculateD(encodedData1Size, encodedData2Size, encodedData1_2Size) val px = calculateP(d, encodedData1Size, encodedData2Size) val py = calculateP(d, encodedData2Size, encodedData1Size) return KolmogorovCalculationResult(d, px, py) } private fun calculateD(encodedData1Size: Int, encodedData2Size: Int, encodedData1_2Size: Int): Double { return (encodedData1Size + encodedData2Size - encodedData1_2Size) / (1.0 * encodedData1_2Size) } private fun calculateP(d: Double, size1: Int, size2: Int): Double { val a = size2 / (1.0 * size1) return d * (a + 1) / (d + 1.0) } }Tym razem nie zobaczymy żadnej magii w kodzie. Mamy tylko zwykłe przepisanie wzoru na Kotlina
Podsumowanie
Dzisiaj zajęliśmy się ostatnim krokiem algorytmu, a mianowicie aproksymacją złożoności Kołmogorowa. Przypomnieliśmy sobie wzory potrzebne do obliczeń, a następnie zaadoptowaliśmy te wzory do naszego kodu. W następnym wpisie wykonamy w końcu nasze 3 kroki razem i przetestujemy działanie algorytmu




.jpg)

