Wykres ridgeline (czasami nazywany wykresem joyplot) przedstawia rozkład wartości liczbowej dla kilku grup. Rozkład można przedstawić dzięki histogramów lub wykresów gęstości wyrównanych do tej samej skali poziomej. Wykresy są lekko nałożone na siebie, aby pokazać wyraźniejszy kontrast zmian.

Inaczej mówiąc, to po prostu wykresy gęstości lub histogramy narysowane na tej samej osi OX z lekkim przesunięciem na osi OY.
Zalety
Riedgeline plot posiada wiele zalet, które przyczyniają się do jego popularności jako narzędzia wizualizacji:
- oferuje czytelny i intuicyjny sposób prezentacji danych,
- umożliwia porównywanie rozkładów między różnymi grupami lub kategoriami; dzięki temu można łatwo zidentyfikować różnice lub podobieństwa w rozkładach i wyciągnąć wnioski na temat badanych zmiennych,
- działa dla większej liczby grup, gdzie tradycyjne pojedyncze wykresy gęstości mogą stać się nieczytelne lub zajmują zbyt wiele miejsca,
- ma estetyczny wygląd, który przyciąga uwagę i sprawia, iż dane są bardziej atrakcyjne dla oka; nakładające się krzywe gęstościowe tworzą unikalny wzór, który wyróżnia się na tle innych typów wykresów.
Wady
Jak większość technik wizualizacji danych, riedgeline ma również pewne wady i ograniczenia, które warto wziąć pod uwagę:
- w przypadku zbyt wielu grup, ilość nakładających się krzywych gęstościowych może sprawić, iż wykres stanie się nieczytelny i trudny do interpretacji,
- riedgeline świetnie wizualizuje różnice w rozkładzie normalnym lub podobnym do niego; w przypadku danych o nieregularnym rozkładzie (takich jak skośne czy wielomodalne), interpretacja może być utrudniona lub prowadzić do błędnych wniosków,
- wykres w dużym stopniu uzależniony jest od dostosowania parametrów dla rysowania gęstości, które mają wpływ na wygląd krzywych.
Historyczna ciekawostka
Ciekawostką jest, iż pierwotnie ta technika wizualizacji danych nazywała się joy plot. Termin ten został zaczerpnięty od nazwy brytyjskiego zespołu muzycznego Joy Division działającego w latach 1976-1980. Duże uznanie zdobyła okładka albumu tego zespołu „Unknown Pleasures” zawierająca bardzo charakterystyczną czarno-białą grafikę nieco przypominającą wykres ridgeline.

Jednak nazwa ta została zmieniona, ponieważ okazało się, iż określenie „Joy Division” odnosiło się do sekcji kobiecej w niemieckich obozach koncentracyjnych z czasów II wojny światowej, gdzie przymusowe prostytutki służyły żołnierzom. Mimo tragicznej przeszłości nazwa ta została wybrana przez członków zespołu jako wyraz ich fascynacji historią i jako wyraz kontrastu między euforią (ang. joy) a mrocznymi tematami, które poruszali w swojej muzyce.
Ta mroczna historia związana z pochodzeniem nazwy zespołu, a później także wykresu spowodowała, iż postanowiono ją zmienić na neutralną.
Ta ciekawostka pokazuje jak kontekst historyczny może wpływać na odbiór danego terminu. Pomimo początkowej inspiracji okładką zespołu Joy Division, decyzja o zmianie nazwy była koniecza, aby oddzielić technikę wizualizacji danych od tragicznych wydarzeń, które legły u podstaw pierwotnej nazwy związanej z zespołem.
Kod w Python
Można podejść do tego na kilka sposobów. Można samemu stworzyć wykres w matplotlib czy plotly. Jednak my idziemy na łatwiznę i wykorzystamy bibliotekę dla tego wykresu joypy.

Wczytajmy najpierw potrzebne biblioteki:

Znalazłem interesujące dane, które mogą nam się przydać do tego zestawienia. Zawierają dzienne informacje o temperaturze dla różnych miast na świecie. Możesz je pobrać po zalogowaniu się (darmowa rejestracja, jeżeli jeszcze nie masz konta) ze strony Kaggle TUTAJ.
Wczytajmy dane:
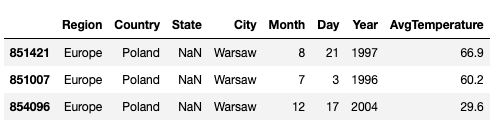
Jak widzisz usunąłem rekordy z wartością -99, ponieważ takie wartości odstające zaburzałyby analizę.
Warto zwrócić uwagę, iż temperatura została zapisana w Fahrenheitach, zatem dodajmy jeszcze kolumnę ze skalą w stopniach Celsjusza, do której jesteśmy przyzwyczajeni w Polsce.

Jeszcze zerknijmy na histogram temperatur, czy wszystko jest ok
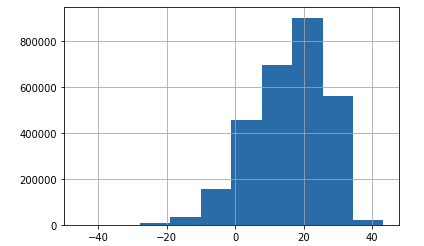
i możemy ruszać dalej.
Ridgeline dla jednej kolumny
Narysujmy, jak wyglądają rozkłady temperatur dla wszystkich państw w poszczególnych miesiącach okresu, kiedy zbierane były dane (lata 1995 – 2020). Składnia jest bardzo prosta i przejrzysta:

Ridgeline dla grupowania
Wybierzmy kilka krajów, które chcemy ze sobą zestawić. Kolejne kolumny przekazujemy jako lista, dlatego warto jeszcze zmodyfikować odrobinę nasz zbiór korzystajac z funkcji pivot.

Na wykresie możemy zaobserwować m.in. zróżnicowanie temperatury w Polsce pomiędzy zimowymi miesiącami a letnimi oraz to, iż w Australii lipiec jest zimniejszy niż styczeń!
Mam nadzieję, iż teraz wiesz już wszystko na temat wykresu warstwowego!
Pozdrawiam z całego serducha,