W zeszłym miesiącu badacze cyberbezpieczeństwa zdemaskowali bardzo interesujące sztuczki, dzięki którym paru cyfrowych gigantów gromadziło dane swoich użytkowników.
Tożsamość winowajców nie jest zaskoczeniem. Koncern Meta wraz ze swoimi portalami, Facebookiem i Instagramem, to już niemal synonim naruszeń prywatności. Drugi sprawca, rosyjski Yandex, nie od dziś stara się zostać wschodnim Google’em – tak pod względem wachlarza usług, jak i śledzenia ludzi.
Zaskakiwać może natomiast trik, jakiego użyły obie firmy, niezależnie od siebie. Sprawnie obeszły bariery stawiane przez system telefonowy Android, wykorzystując localhosta – wspólną przestrzeń dostępną dla różnych aplikacji. Trochę tak, jakby szpiedzy ukrywali listy do siebie w nieużywanych szafkach na pływalni. Niemal na widoku.
Stosując to obejście, firmy mogły łączyć naszą tożsamość, znaną ich aplikacjom, z naszymi wędrówkami po sieci. Mimo iż odbywały się one wewnątrz zwykłych przeglądarek; niezależnych, a czasem wręcz trzymających stronę użytkowników.
W tym wpisie opiszę, przystępnie i krok po kroku, o co chodziło w całej tej aferze localhostowej. Pokażę również, iż wystarczyłaby zmiana paru podstawowych ustawień i trzymanie się uniwersalnych zasad, żeby ochronić swoją prywatność.
Skupię się na Mecie, bo jej śledzenie dotyka znacznie więcej osób, zwłaszcza w naszym rejonie. Będę wprowadzał rozróżnienie między firmami tam, gdzie ich metody różniły się od siebie.
Zapraszam!
![]()
Źródła: mem o kryjówce Saddama Husajna , mem o dwóch kopaczach. Przeróbki moje.
Spis treści
- Pliki cookies i klasyczne śledzenie
- Kulturalne logowanie
- Niekulturalne elementy śledzące
- Aplikacje jako utrudnienie
- Obejście barier
- WebRTC – sposób wysłania
- Localhost – sposób odbioru
- Łączenie danych
- Konsekwencje
- Co pomoże, a co nie
 Źródła
Źródła
Punktem wyjścia do wpisu była praca badaczy opisana na stronie localmess.github.io (polecam! Ciut bardziej techniczne, ale nie jest tak źle. Szczególnym atutem jest interaktywna lista stron zawierających elementy śledzące od Facebooka).
Drugim głównym źródłem było omówienie ich badań ze strony zeropartydata.es, wraz z analizą potencjalnych kar, jakimi mógłby oberwać Facebook.
Reszta to dyskusje na forach oraz wiedza własna, którą od dawna się dzielę na blogu. Będzie sporo linków do innych wpisów!
Pliki cookies i klasyczne śledzenie
Cała sprawa dotyczyła smartfonów z systemem Android, nie dotknęła iPhone’ów ani komputerów osobistych.
W przypadku komputerów nie wynika to jednak z jakiejś ich odporności, ale raczej z tego, iż już są rozpracowane przez Metę i innych łapserdaków. Pozwolę sobie na początek opisać panującą na nich anarchię i przejść stopniowo do sytuacji na telefonach, która wymaga od technogigantów pewnych forteli.
Jeśli ktoś już pewnie się czuje z wiedzą na temat trackerów i nie chce powtórki, to może przeskoczyć do sedna.
Kluczowa sprawa: na komputerach osobistych wiele rzeczy odbywa się zwykle przez ogólną przeglądarkę, jak Firefox czy Opera. To wewnątrz niej ładuje się zarówno terytorium Mety (rozciągające się na domeny takie jak instagram.com czy facebook.com), jak i całe galaktyki niezależnych stron: portale informacyjne, katalogi przepisów czy kolekcje kocich zdjęć.
Kulturalne logowanie
Załóżmy, iż ktoś odwiedza po raz pierwszy stronę Facebooka. W takim przypadku Facebook poprosi o podanie maila i hasła. Gdy je podamy, to wyświetli się zawartość naszego konta na platformie.
Taki jest obraz widoczny na zewnątrz. Ale pod spodem wygląda to inaczej – w chwili zalogowania przeglądarka otrzymała tzw. „ciasteczko”, czyli plik cookie. Krótki tekst, który w bazie danych Facebooka jest jednoznacznie przypisany do konkretnej osoby. Można powiedzieć poetycko, iż to tożsamość zapisana w bajtach.
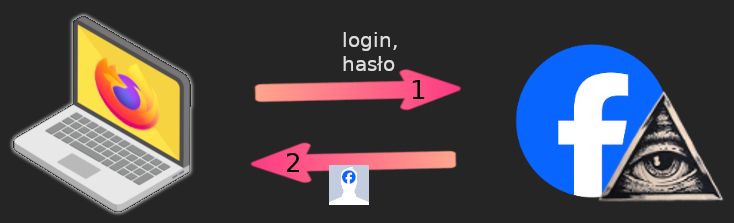
Źródła: laptop i strzałki z serwisu Flaticon; oficjalne ikony Facebooka i przeglądarki Firefox. Przeróbki moje.
Po zapisaniu ciasteczka przeglądarka zmienia swoje zachowanie. od dzisiaj okazuje ten plik przy każdym kolejnym kontakcie ze stroną facebook.com, ujawniając kim jesteśmy.
Dzięki temu nie musimy się każdorazowo logować. Od razu po załadowaniu strony widzimy znajomych, wydarzenia, nowinki ze świata – ale częściej wygenerowane komputerowo bzdety – dopasowane specjalnie do siebie.
Na tym etapie ciasteczko wydaje się jeszcze praktyczne i sensowne, ułatwia życie.
Warto jednak zapamiętać, iż w takich realiach nie istnieje coś takiego jak anonimowe logowanie; co jakiś czas ktoś się nacina na braku tej wiedzy.
Problem w tym, iż przeglądarka okazuje ciasteczko przy każdym kontakcie ze stroną facebook.com. Również wówczas, gdy wcale nie odwiedzamy Facebooka, a jedynie trafiamy na mały, pochodzący od niego element gościnny na całkiem obcej stronie.
Niekulturalne elementy śledzące
Takie małe „posterunki” Facebooka również mogą odczytywać i zapisywać związane z nim ciasteczka. Elementy nazywa się trackerami, zaś związane z nimi ciasteczka to third-party cookies (ciasteczka od stron zewnętrznych). A co robią w internecie? Właściciele stron nieraz sami je dodają, skuszeni możliwościami współpracy reklamowej albo ściślejszej integracji z social mediami.
Działanie trackerów w praktyce, krok po kroku:
- nasza przeglądarka (mająca w sobie zapisany plik cookie od Fejsa) prosi o jakąś stronę, całkiem od Facebooka niezależną;
- otrzymuje ją, zwykle jako plik HTML, i odczytuje jej treść;
- widzi, iż strona pozostało niekompletna, bo brakuje elementu od Facebooka, zwanego Facebook Pixel;
-
prosi o ten element stronę facebook.com, załączając do prośby plik cookie, który nas identyfikuje.
My otrzymujemy mały, niezbyt wartościowy dla nas element. W zamian Facebook dostaje informację, iż konkretna osoba o danej porze odwiedziła stronę X. Być może portal ze zdjęciami kotów, a może (zmyśloną) leczymy-weneryczne.pl. Nie nazwałbym tej wymiany interesem życia :roll_eyes:
Wisienka na torcie? Sam element, wbrew nazwie Pixel, nie jest żadnym pikselem, ale kolekcją różnych rzeczy, w tym skryptów w języku JavaScript. Mogą kazać naszemu urządzeniu robić różne rzeczy, pozyskiwać informacje i wysyłać je Facebookowi. Warto zapamiętać ten fakt, bo jeszcze odegra istotną rolę.
Elementy od Yandeksa działają na tej samej zasadzie, ale raczej rzadziej występują w światowej sieci i mają nieco mniej mylącą nazwę Yandex Metrica.
A tutaj, dla osób lubiących obrazki, schemat całego opisanego procesu:
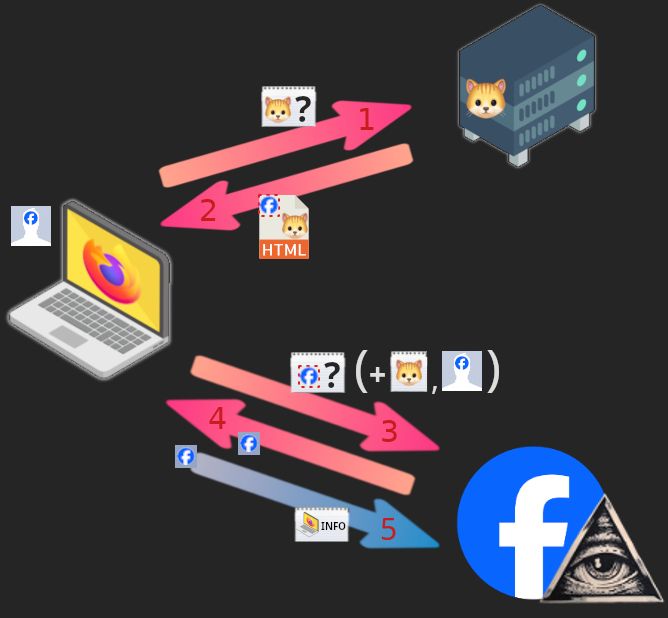
Źródła: serwer ze strony Flaticon, ikona kota z Emojipedii, reszta jak wcześniej. Przeróbki moje.
Ciasteczka od stron zewnętrznych to problem znany od dawna i poczyniono spore postępy w odchodzeniu od nich. Przeszkodą pozostaje Google, który przez cały czas staje w ich obronie.
…Ale choćby gdyby nikt od nich nie planował odchodzić, w tej chwili wiele firm mogłoby nie czerpać z nich takiej wartości jak kiedyś. Częściowo dlatego, iż internet przejmują urządzenia mobilne, na których przeglądarka nie stanowi centrum świata.
Aplikacje jako utrudnienie
Cała powyższa sytuacja to norma na komputerach osobistych, bo tam wszystko dzieje się w obrębie jednej przeglądarki. Jest jedna i ta sama przegródka na ciastka Mety, które są okazywane zarówno ich serwisom, jak i pomniejszym elementom-wartownikom na stronkach nienależących do firmy.
…Ale na telefonach Meta ma utrudnione zadanie. Z dwóch przyczyn:
-
Użytkownicy często korzystają z jej własnych aplikacji, jak Facebook czy Instagram, zamiast otwierać w przeglądarce facebook.com lub instagram.com.
Wprawdzie wersje mobilne też są dostępne, np. pod adresem m.facebook.com, ale apka Facebooka bywa nieraz domyślnie zainstalowana na telefonie, do tego sama strona nakłania na apkę. Dlatego to ona zgarnia ludzi.
Ma to sens, bo aplikacja ma większy wgląd w system i dane użytkowników (w szczególności do listy kontaktów). Ale stawiając na to rozwiązanie, Facebook zamyka sobie inną opcję, o czym za sekundę. -
Dane z przeglądarki są osłonięte podwójną barierą.
Po pierwsze: zabezpieczenia samego systemu Android. Jego twórcy chyba się czegoś nauczyli z historii komputerów osobistych i tego, do czego prowadziły nieograniczone możliwości ingerowania jednych programów w drugie.
Na Androidze każda apka ma własną, prywatną przestrzeń i nie może zaglądać do innych aplikacji. Możliwy powinien być tylko wgląd we wspólne przestrzenie. Ten podział to tak zwany sandboxing.
Po drugie: przeglądarkom zależy na reputacji szczelnych, więc są ostrożne i m.in. unikają zapisywania plików do wspólnej przestrzeni. choćby Chrome, szorujący po prywatnościowym dnie, przynajmniej dba o to, żeby tylko Google mógł żłopać informacje, a cudze apki były od nich odcięte.
Efekt? przez cały czas zachodzi pięć etapów ze wcześniejszego schematu. Tyle iż Meta nie dostaje ciasteczka-tożsamości w pakiecie z danymi stron internetowych. Ciastka identyfikujące leżą jedynie wewnątrz ich apki (Facebooka lub Instagrama). Historie wędrówek po internecie gromadzą się zaś w przeglądarce, która nie zamierza ich wręczyć gigantowi.
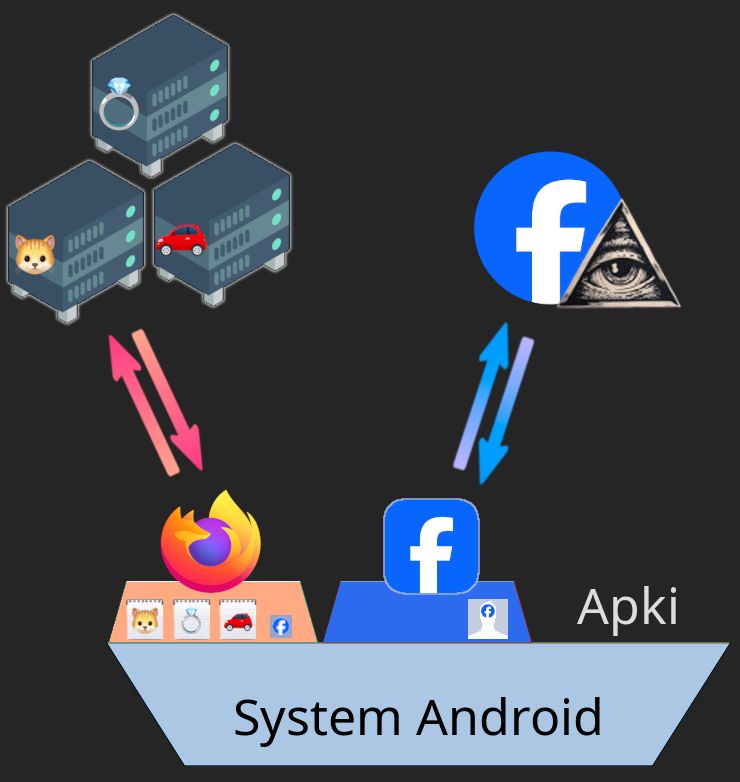
Źródła: pierścień w wersji Google’a oraz samochodzik w wersji JoyPixels z Emojipedii, reszta jak wcześniej.
Z punktu widzenia naszego korpo był to niekorzystny impas. Choć mieli inne metody (o nich niżej, w rozwijanej ciekawostce), nic nie pobiłoby unikalnego identyfikatora. Dlatego mocno szukali sposobu na powiązanie ze sobą obu źródeł danych.
Jakie metody śledzenia pozostają Facebookowi (dla zainteresowanych)Warto wiedzieć, iż sytuacja, wbrew pozorom, wcale nie jest dla Mety/Facebooka taka beznadziejna. Opisana tu metoda przez localhosta mogła być dla nich najwygodniejsza, ale mają też inne sposoby na śledzenie ludzi.
Zacznę od rzeczy pewnych. Cała opisana wyżej rozdzielność między apką a przeglądarką ma zastosowanie tylko wtedy, gdy faktycznie korzystamy z przeglądarki. Brzmi banalnie? Ale Facebook nabrał wiele osób, imitując przeglądarkę.
Jeśli klikniemy link do jakiejś zewnętrznej strony wewnątrz jednej z aplikacji Mety (Facebook albo Messenger; Instagrama i WhatsAppa nie sprawdzałem), to tak naprawdę nie opuszczamy ich terenu. To, co się otwiera, ma wprawdzie górny pasek z adresem i wygląd zwykłej przeglądarki, ale jest jedynie imitacją wbudowaną w Facebooka/Messengera. Pozostając w niej, pozostajemy na oku Mety.
Ciekawostka
Swoją drogą linki z Facebooka nie są bezpieczne również w standardowej przeglądarce. W chwili kliknięcia są dyskretnie podmieniane na przekierowania.
Kiedy je klikamy, to nie trafiamy prosto na stronę docelowej, tylko przechodzimy najpierw przez „śluzę” – małą stronkę między terytorium Facebooka a zewnętrznym internetem. Platforma widzi, dokąd idziemy i może to sobie zapisywać. Zaś z parametrów, czyli tekstu dodawanego do linków, może odczytać jeszcze więcej informacji, niż ujawniałby sam link.
A co z rzeczami, które niekoniecznie są dla Facebooka kluczowe, ale mogłyby im ułatwić identyfikację?
Przede wszystkim mają do dyspozycji adres IP, siłą rzeczy otrzymywany przez strony Facebooka podczas każdej interakcji. Pozwala on (zwłaszcza w krótszym okresie) trafnie łączyć aktywność internetową z aplikacjową.
„Z tego adresu odwiedziła nas Barbara P. Kilka minut później ten sam adres aktywował naszego trackera na stronie koty-nieloty.pl (zmyśliłem). Hipoteza: to Barbara P. odwiedziła stronę”.
Adres ma jednak różne swoje słabości. jeżeli jest nadawany przez sieć mobilną, to co pewien czas się zmienia. Może go również współdzielić wiele osób – przykładem router w rodzinnym mieszkaniu albo publiczny hotspot. No i ktoś może celowo użyć pośrednika, takiego jak VPN, żeby ten adres zamaskować. Nie dziwota, iż Facebook wolał pewniejszy sposób identyfikacji.
Inną metodą jest profilowanie, czyli fingerprinting. Jak pokazuje wcześniejszy schemat, elementy od Facebooka mogą w kroku 5 uruchamiać kod JavaScript. A za jego pomocą można odczytać bardzo szczegółowe informacje na temat systemu, a choćby sprzętu fizycznego (zainstalowane czcionki, możliwości karty graficznej, charakterystyczny wygląd pikseli po rysowaniu wskazanych elementów…).
Takie informacje mogą umożliwić jednoznaczną identyfikację urządzenia. Apka Facebooka wykonuje jedno profilowanie, zaś elementy na stronach zewnętrznych – kolejne. jeżeli wyniki się pokryją, to mogą przyjąć, iż rozpoznali konkretną osobę. Wadą metody może być jej inwazyjność, spowalniająca nieco urządzenia i czyniąca metodę względnie łatwą do wykrycia, zwłaszcza dla badaczy. Ale pokusa może być silniejsza.
W każdym razie dwie metody wyżej to gdybanie. Czas wrócić do pewniaka, czyli naszego localhosta.
Obejście barier
Podsumujmy sobie to, co dotychczas wiemy. Facebook ma:
- jedną lub więcej aplikacji, w całości pod swoją kontrolą, zawierających czyjąś tożsamość;
- swój mały element załadowany w przeglądarce, który może z nią rozmawiać i ma dane na temat aktywności na stronie;
- barierę między tymi dwoma światami, którą chciałby przekroczyć.
Żeby nie było nudno i technicznie, spróbujmy się wczuć w Facebooka. A konkretniej – w jakiegoś (zmyślonego, fikcyjnego) klepacza kodu zatrudnionego w tej firmie.
Być może menedżer kazał mu znaleźć sposób na powiązanie aktywności internetowej z apką. Oczywiście wątpię, żeby w rozmowie użył słowa „śledzenie”. Prędzej frazesu w stylu „bridge app and website experiences”. Bo w końcu w korporealiach zawsze są „przeżycia”, rzadziej konkrety.
I teraz ten biedny pracownik stuka w klawiaturę, jak w perkusję z filmu Whiplash (uwaga: YouTube), wyobrażając sobie w głowie, iż właśnie dąży do perfekcji i Czyni Dobro™. Buduje rzeczy wielkie. Rozwój, postęp. Postęp, rozwój.
„Uczestnicy chcą być widziani. Chcą czuć nas przy sobie. A te złe bariery nas od nich dzielą!”. Czy takie coś słyszy w swojej głowie?
Dodatkowo może go motywować fakt, iż w razie niepowodzenia straci wizę pracowniczą i Ameryczka odeśle go do kraju urodzenia, wróci stara bida. Ale nie będę psuł przyziemnością górnolotnej motywacji.
Pracownik myśli, główkuje. Jakie są punkty wspólne między aplikacjami na systemie Android? Jak mogą ze sobą rozmawiać?
Pomysł 1: można zapisać jakiś tekstowy identyfikator przez przeglądarkę we wspólnej przestrzeni telefona. Potem aplikacje od Mety mogłyby go odczytać.
Owszem, można. Tylko iż przy próbie zapisu w przeglądarce wyświetli się wtedy okno wprost pytające użytkownika, czy chce coś pobrać z sieci. Takie jak np. przy pobieraniu PDF-a. I takie coś działoby się często. Zero szans na dyskrecję, odpada.
Pomysł 2: schowek (znany jako „kopiuj-wklej”). Strona internetowa skopiuje do niego dane, a apka Facebooka je odczyta.
Tylko iż to by, po pierwsze, nadpisywało dane użytkowników już obecne w schowku, wywołując chaos. Po drugie: nie byłoby dyskrecji, bo Android wyświetla systemowy komunikat, gdy apka sięga po dane ze schowka. Ten pomysł też odpadał.
Zdesperowany pracownik oblewa się zimnym potem. Już widzi w wyobraźni, jak menedżer nazywa go non-performant i wyznacza mu za karę obóz reedukacyjny Performance Improvement Plan. Zdalnie, bezdusznie, podczas wideokonferencji.
…I w tym momencie doznaje olśnienia. Wideokonferencja. I obsługujący ją protokół, WebRTC.
WebRTC – sposób wysłania
WebRTC ma parę ogromnych zalet z punktu widzenia śledzenia.
Działa w tle, w sposób niewidoczny dla użytkowników. Pozwala nawiązać bezpośredni kontakt z dowolnym adresem. Może go uruchomić każdy element stron internetowych, który wykorzystuje kod JavaScript.
A ten kod jest wszechobecny i choćby wspomniane już Pixele, małe elementy gościnne od Mety, mogą go używać. Jak coś odsyłam do schematu z plikami cookies. Chanel Strzałka numer 5.
Protokół WebRTC to bestia złożona i pełna niuansów, adekwatnie cały parasol pomniejszych protokołów. Zainteresowane osoby znajdą więcej na stronce webrtcHacks. Moja znajomość WebRTC jest gorzej niż pobieżna… Ale hej! I tak się wypowiem, bo w naszej historii protokół został użyty w równie pobieżny sposób.
Nikomu ze śledzących nie zależy na pełnoprawnej komunikacji. WebRTC w tym wypadku ma być tylko pretekstem, żeby wysłać dane. Wykorzystany zostaje jedynie jeden z prostszych protokołów z parasola, SDP (Session Description Protocol), służący do wynegocjowania między dwoma urządzeniami sposobu komunikacji.
Samo zapoznawanie ze sobą dwóch urządzeń miałem już okazję opisać, nazywając je swataniem. Pokazałem też ciemną stronę takiego swatania – złe strony mogą udawać, iż chcą rozpocząć połączenie przez WebRTC, żeby dorwać nasz prawdziwy adres IP.
W ramach SDP wysyłanych jest sporo różnych informacji. Jedna z nich nazywa się ice-ufrag i powinna zawierać nazwę użytkownika. Zamiast niej Facebook Pixel upychał tu identyfikator tymczasowy użytkownika, nazwany _fbp (nazwa całkowicie dowolna, wybrana przez twórców).
Upychanie to nazywa się oficjalnie SDP munging i polega na bezpośrednim edytowaniu informacji związanych z SDP, tuż przed ich wysłaniem (ogólnie za WebRTC odpowiada przeglądarka, a skrypty mają ograniczoną kontrolę, ale na początku mogą trochę gmerać).
Analogia
SDP z założenia jest trochę jak napisanie komuś na komunikatorze: „może przejdziemy z tym na maila? Mój adres to romek@zmyslona-strona.pl, możesz tam załączyć obrazki”. Taka próba utworzenia nowego kanału komunikacji, opis jego możliwości.
SDP munging w wydaniu Mety byłby natomiast jak nadużycie tego formatu rozmowy i podanie, zamiast swojej nazwy użytkownika, pseudonimu jakiegoś nieszczęśnika odwiedzającego sklep internetowy: „mój adres to uzytkownik-strony-xyz-19821370@zmyslona-strona.pl”.
Pierwsza trudność (jak wysłać niepostrzeżenie dane użytkownika) została rozwiązana. Pozostała kolejna: dokąd to wysłać? Trzeba było wskazać jakieś miejsce docelowe, żeby WebRTC zadziałało.
Localhost – sposób odbioru
Wcześniej zmyśliłem sobie biednego pracownika, który wpadł na pomysł wysłania danych przez WebRTC, kojarząc z tym słowo „wideokonferencja”. W podobny sposób mógłby wpaść na pomysł ich odebrania przez interfejs localhost, przypominając sobie, jak to swego czasu aplikacja konferencyjna Zoom dość kreatywnie go (nad-)użyła.
…A czym adekwatnie jest localhost?
Najpierw wyobraźmy sobie interfejs sieciowy, czyli miejsce, z którego wysyła się i odbiera rzeczy wymieniane z szerszym światem. To taki wielki paczkomat – rząd szafek, z których każda ma własny numer i jest nazywana portem.
„Paczkomat” z małej, bo traktuję to jak rzeczownik powszechny – inaczej, niż by chcieli prawnicy InPostu :smiling_imp:
Ciekawostka
Szafek możliwych do wykorzystania jest bardzo wiele. Dokładniej rzecz biorąc: zwykle 65 536. Ta liczba, choć wydaje się z czapy, nie jest przypadkowa. Dokładnie tyle możliwości da się wyrazić w 16 bitach (gdzie każdy bit to jedno zero albo jedynka), a kiedyś umownie przyjęto za numer portu liczbę 16-bitową. I tak w wielu systemach zostało do dziś.
Niektóre szafki/porty są używane bardzo często, inne rzadko. Przykładowo port numer 443 obsługuje ruch przez HTTPS, czyli większość aktywności związanej z surfowaniem po sieci. Wiele innych portów jest z kolei nieużywanych.
Dokładna kopia tego paczkomatu, przeznaczonego do kontaktu ze światem, stoi również wewnątrz systemu. Jest przeznaczona wyłącznie do użytku wewnętrznego. Na przykład symulowania na własnym urządzeniu działania serwera. I takim właśnie wewnętrznym paczkomatem jest bohater afery, localhost.
Nie jest to żadna egzotyka. Sam na przykład każdorazowo czytam wpis z bloga przez localhosta, żeby móc wiernie ocenić jego wygląd przed publikacją. Tym niemniej zaskoczyło mnie, iż na Androidzie tak wiele aplikacji mogło tutaj sięgnąć.
Żeby coś wysłać do localhosta, wystarczy wskazać jako cel specjalny adres IP, 127.0.0.1. Zawsze odnosi się on do aktywnego urządzenia, a nie czegoś zewnętrznego. Oprócz adresu należy wskazać port docelowy (numer szafki).
Oba wścibinosy, Meta i Yandex, kazały swoim aplikacjom nasłuchiwać portów dużo rzadziej odwiedzanych. Meta upodobała sobie porty o numerach 12387, 12388 oraz zakres od 12580 do 12585. Yandex wybrał numery 29009, 29010, 30102 i 30103.
Można powiedzieć, iż firmowe aplikacje co pewien czas otwierały szafki o odpowiednich numerach i patrzyły, czy w środku znajdują się jakieś nowe informacje.
Łączenie danych
Dzięki localhostowi Facebook i Yandex zyskały możliwość komunikacji między swoim elementem śledzącym a kontrolowanymi przez siebie aplikacjami. Do tego zarówno elementy ze stron, jak i aplikacje, mogły swobodnie kontaktować się z serwerami firmy.
W takich warunkach łączenie danych w jeden profil stało się formalnością. Metody przyjęte przez obie firmy minimalnie się od siebie różniły, ale trzon działania był ten sam.
W przypadku Mety:
- Po krótkiej sesji siedzenia w apce użytkownik z niej wychodzi; apka przechodzi w tryb działania w tle i obserwuje interesujące ją porty localhosta.
- Użytkownik odwiedza w przeglądarce stronę zawierającą element od Facebooka. Ten go nie poznaje, więc przypisuje mu „pseudonim” – identyfikator tymczasowy.
- Pseudonim, wzbogacony o informacje na temat odwiedzonej strony, etapu zakupów itd., wysyła Mecie (pseudonim = aktywność-na-stronie).
- Ten sam pseudonim, ale bez dodatkowych danych, śle w opisany już sposób do localhosta.
- Czuwająca tam aplikacja odbiera pseudonim i przypisuje go do tożsamości zapisanej w swoim wnętrzu (pseudonim = tożsamość). Wysyła to powiązanie Mecie.
- Na serwerach Mety następuje łączenie danych w ostateczną postać, znacznie bardziej użyteczną dla cybergiganta: tożsamość = aktywność-na-stronie.
Yandex podszedł do sprawy nieco inaczej. Być może dlatego, iż nie miał takiej popularności w sieci jak Meta, więc tożsamość odczytana z jego własnych aplikacji nie byłaby tak uniwersalnym, globalnym identyfikatorem jak inne opcje.
Zamiast czerpać tożsamość z wnętrza własnych aplikacji, sięgali do identyfikatora reklamowego wbudowanego w telefony. Google domyślnie umieszcza to dziadostwo na typowych telefonach z Androidem. Każda aplikacja może o nie zapytać i dostaje w odpowiedzi ciąg znaków, który powinien odpowiadać konkretnemu urządzeniu.
Następnie wysyłali ID reklamowe swojemu elementowi śledzącemu, który wciąż miał aktywną komunikację przez WebRTC. Element odczytywał je, tworzył komplet unikalne-ID = aktywność-na-stronie i wysyłał do Yandeksa.
Streszczając: w przypadku Yandeksa komunikacja przez WebRTC była dwustronna, w roli tożsamości używano identyfikatora reklamowego, a wysyłanie danych na serwery Yandeksa należało wyłącznie do elementów śledzących ze stronek internetowych. Ale ogólna koncepcja obchodzenia ograniczeń przez localhosta była taka sama.
Konsekwencje
Facebook i Yandex nie mają wymówek. To nie jakaś drobna zmiana czy wyciek informacji, który dałoby się usprawiedliwiać gafą. Działali celowo, obchodząc zabezpieczenia, zostali złapani na gorącym uczynku.
Obie firmy tuż po wykryciu gwałtownie przestały korzystać ze swojego triku. Teraz będą czekały na kary. Sprawa wywołała również techniczne dyskusje nad uszczelnieniem dostępu do localhosta. Możliwe, iż dostęp do niego będzie np. wymagał udzielenia zgody przez użytkowników. W każdym razie metoda raczej przestanie być dyskretna.
W związku z całą sytuacją przeciwko Mecie w USA złożono pozew zbiorowy, którego twarzą jest Devin Rose z Kalifornii (w której obowiązują ściślejsze przepisy chroniące prywatność, bliższe poziomowi unijnemu).
Szczególne możliwości ma jednak Unia Europejska. Jak analizuje autor strony zeropartydata.es, Meta mogłaby oberwać skumulowanym efektem kilku różnych kar – związanych z przepisami GDPR (w Polsce znanymi jako RODO), Digital Markets Act oraz Digital Services Act.
Przepisy te nie opierają się na stałych kwotach, ale na procencie od przychodów. Autor wylicza, iż Facebook mógłby oberwać teoretyczną karą do 32 mld dolarów.
Od razu zaznaczę, iż nie znam przepisów na tyle, żeby wiedzieć czy to realne; ale autor podaje źródła, a jego stwierdzenia na temat przepisów są zbieżne z tym, co sam o nich wyczytałem. Dlatego daję jego słowom kredyt zaufania, choć wątpię w pełen wymiar kary.
Mam nadzieję, iż wreszcie się doigrają, bo z ich strony naruszanie prywatności to już regularna recydywa. Zaś w międzyczasie, zamiast czekać na prawodawców, można wziąć sprawy we własne ręce.
Co pomoże, a co nie
Metoda z tego wpisu nie tylko pozwala łączyć światy apek i przeglądarek, które od początku powinny być rozłączne, ale również obchodzi kilka najprostszych (i przez to najpopularniejszych) sposobów na ochronę prywatności.
Korzystasz z pośrednika, takiego jak VPN? Może cię to nie chronić.
Prośba o zainicjowanie WebRTC po prostu sobie przejdzie przez cały łańcuszek pośredników, a twoje dane trafią do odpowiedniej przegródki localhosta. Stamtąd odbierze je nasłuchująca apka, połączy z tożsamością i wyśle swoim twórcom.
Często usuwasz pliki cookies? Dobry zwyczaj, często pomaga. Ale nie w tym wypadku.
Ciasteczko identyfikujące tkwi wewnątrz apki Facebooka (albo uprzywilejowanych Usług Google’a, jeżeli to ID reklamowe używane przez Yandeksa). Żadne czyszczenie przeglądarki nie ma na nie wpływu.
Na czas wrażliwszego wyszukiwania korzystasz z innej przeglądarki? Na przykład używasz Firefoksa zamiast swojej codziennej Opery?
Dobry zwyczaj. Ale tutaj, o ile któraś z przeglądarek A i B nie jest dodatkowo zabezpieczona, dane z nich tak czy siak trafią do wspólnej szafki w localhoście. Stamtąd odbierze je apka i przypisze do konkretnego profilu.
Promyk nadziei
Sprawa z nadużywaniem localhosta może być kubłem zimnej wody i sugerować, iż giganci zawsze przechytrzą starania o szczyptę prywatności. To woda na młyn defetystów piszących lekceważąco, iż „prywatność już nie istnieje, czas się poddać”.
Proponuję jednak spojrzeć na to inaczej. Ten wyciek istotnie był unikalny i nieco zniuansowany, ale możliwy jedynie dzięki splotowi kilku czynników. Gdyby choć jeden z nich nie zachodził, to Facebook i Yandex nie miałyby możliwości zebrania danych.
Oto lista rzeczy (nieraz bardzo szybkich i łatwych), dzięki którym cała metoda śledzenia straciłaby rację bytu. Ułożyłem je od najistotniejszych do pobocznych.
-
Korzystanie z dodatku blokującego śledzenie, takiego jak uBlock Origin (albo z przeglądarki z wbudowanym blokerem).
Rozwiązanie kwestii elementów śledzących na logikę wydaje się proste. „Kiedy jestem na stronie, która nie jest Facebookiem, to nie chcę mu niczego wysyłać”. I taką regułę wdrażają dodatki blokujące, z których w szczególności polecam uBlock Origin. Skuteczny, darmowy, o otwartym kodzie źródłowym. Już nieraz o nim pisałem na blogu.
Bloker w ogóle nie pobierałby elementów śledzących od Facebooka, dzięki czemu platforma nie dostałaby żadnych, choćby najprostszych informacji o użytkownikach (w ogóle nie zaszłyby etapy 3-5 z początkowego schematu).
Niestety nie każda przeglądarka mobilna daje możliwość instalowania dodatków. Żeby cieszyć się mocami uBO, należy zainstalować mobilnego Firefoksa.
Inną opcją jest mobilna przeglądarka Brave. Nie ma uBO, ale zawiera własnego, wbudowanego blokera reklam – o mniejszych możliwościach, ale działającego z miejsca.Przeglądarek stawiających na prywatność jest więcej – choćby DuckDuckGo Browser czy Mullvad Browser – ale nie miałem okazji ich dokładniej przetestować. Polecam to, co sam sprawdziłem.
-
Wyłączenie ID reklamowego
Ten krok pomógłby w przypadku Yandeksa, ale nie Facebooka. Ale ogólnie to rzecz tak prosta i pozbawiona efektów ubocznych, iż polecam ją absolutnie wszystkim. Dałaby ochronę przed wieloma innymi nadużyciami, jak choćby afera Gravy Analytics opisana w podlinkowanym wpisie.
-
Wyłączenie kodu JavaScript na stronach internetowych.
Bez niego w ogóle by nie zadziałał etap 5 z pierwotnego schematu. Czyli w przypadku elementów od Mety i Yandeksa: włączenie WebRTC i wysłanie danych.
To metoda nie dla wszystkich, bo od JS-a zależy działanie wielu stron internetowych, zwłaszcza większych. Niektóre osoby stykają się z takimi stronami często, inne rzadziej.
Moja sugestia? Zainstalować na mobilnym Firefoksie uBO, który i tak by się przydał. Na próbę wyłączyć JS-a w jego opcjach i w razie czego reaktywować go paroma kliknięciami na kłopotliwych stronach. Ocenić, czy rozwiązanie nam pasuje. -
Wyłączenie WebRTC w przeglądarce.
Na każdej działa to nieco inaczej, więc zachęcam do zerknięcia w link. Uprzedzam, iż po zablokowaniu nie będą działały niektóre programydo wideokonferencji, więc warto sobie zapisać sposób na odblokowanie.
W przeglądarce anonimizującej Tor Browser ta funkcja jest domyślnie wyłączona, dzięki czemu domyślnie chroni użytkowników przed powiązaniem tożsamości – nie trzeba uruchamiać dodatkowych funkcji, jak blokada JavaScriptu, mimo iż też by pomogły. Tylko pozazdrościć twórcom intuicji do wykrywania zagrożeń :wink: -
Wyłączanie aplikacji, kiedy z nich nie korzystamy
Nieraz widziałem, jak ktoś pyta w sieci o sposób na pełne wyłączenie aplikacji, żeby nie zjadały baterii. Inni odpisywali często, iż to bzdet, iż Android sam dobrze zarządza pamięcią.
…A teraz się okazuje, iż osoby ubijające aplikacje byłyby lepiej chronione. Nie działając w tle, apki nie są w stanie warować przy portach. Jakie to życie przewrotne :wink:
Aby wyłączyć konkretną aplikację, można wejść w Ustawienia, potem Aplikacje, wybrać ją z listy i kliknąć opcję Wymuś zatrzymanie. Pojawi się ostrzeżenie, proponuję zignorować.
Proponuję, żebyśmy z całej sytuacji wynieśli taką lekcję: ochrona prywatności jest wprawdzie pełna niuansów i stale wypływają nowe zagrożenia, ale zadbanie o parę prywatnościowych podstaw konsekwentnie chroni tyłek.
Tu i teraz zmień swój świat. Wyłącz ID reklamowe (zajmnie to mniej niż minutę). Zainstaluj Firefoksa, na nim zainstaluj uBlock Origin (kilka minut plus czas na pobranie). Nie musisz od razu przeskakiwać na ten zestaw, możesz się z nim stopniowo oswajać. Wszystkie instrukcje w linkach wyżej.
Te proste zmiany wystarczą, żeby zrobić symboliczny krok ku niezależności i odejść od świata, w którym jest się strzyżonym na łyso przez różnych chytrusów. I takiego lepszego świata nam życzę! :smile: