Wykorzystywanie wiedzy zawartej w zbiorze danych, umożliwia nam wykonywanie prognoz (ang. forecasting), czyli przewidywań wartości w oparciu o pewne cechy oraz wzorce występujące w danych.
Wykorzystywanie wiedzy zawartej w zbiorze danych, umożliwia nam wykonywanie prognoz (ang. forecasting), czyli przewidywań wartości w oparciu o pewne cechy oraz wzorce występujące w danych.
W poniższym artykule przyjrzymy się sposobom tworzenia prognoz w oparciu o algorytmy regresji liniowej.
Przy przetwarzaniu danych i wykorzystywaniu algorytmów uczenia maszynowego, mamy możliwość korzystania z wielu narzędzi dostępnych dla wybranych języków programowania.
Popularność takich rozwiązań, na przykład w Pythonie, dostarcza nam prostych metod na budowanie modeli, dostosowanych do rozwiązywania naszych bieżących problemów predykcyjnych.
W języku Javascript również możemy korzystać z takich mechanizmów czy bibliotek i to w całkiem optymalny sposób.
Zmienia to sposób postrzegania języka Javascript oraz pokazuje, iż możliwość wykorzystania algorytmów uczenia maszynowego nie zależy od środowiska czy języka programowania, a dowolne mechanizmy mogą zostać bez przeszkód zaimplementowane na różnych platformach.
Regresja a klasyfikacja
Klasyfikacja jest zadaniem, którego celem jest dopasowanie próbki danych do jednej z predefiniowanych etykiet.
Podczas wykorzystania klasyfikacji, możemy obliczyć więc z jakim prawdopodobieństwem etykieta wyznaczona przez algorytm, będzie pasowała do wybranych danych.
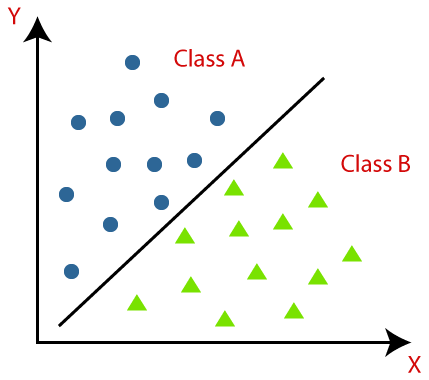 Klasyfikacja binarna zbioru punktów [Źródło].
Klasyfikacja binarna zbioru punktów [Źródło].
W przypadku regresji, mówimy o wyznaczaniu konkretnej wartości w oparciu o dane wejściowe.
Wynik taki, czyli prognoza, będzie liczbą rzeczywistą, a nie wartością predefiniowanej klasy (jak w przypadku klasyfikacji). Na przykład, gdy bierzemy pod uwagę ceny mieszkań, możemy w oparciu o wybrane cechy (takie jak liczba pokoi czy wiek mieszkania) opracować prognozę ich cen (które będą liczbami rzeczywistymi).
W przypadku klasyfikacji, możemy w prosty sposób ocenić poprawność działania modelu w oparciu o etykietę klasy. Gdy jest ona poprawna, przykładowa próbka danych zostanie oceniona pozytywnie, a w odwrotnym przypadku – negatywnie.
W sytuacji wartości ciągłych, będących wynikiem regresji, nie możemy weryfikować poprawności modelu w ten sposób. Konieczne jest więc, wykorzystanie pewnych miar, jak na przykład różnica między przewidzianą wartością a wartością faktyczną.
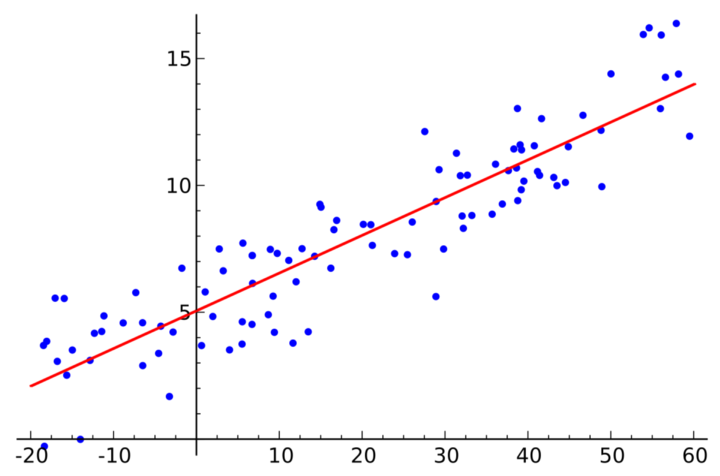 Przykład wyniku algorytmu regresji liniowej [Źródło].
Przykład wyniku algorytmu regresji liniowej [Źródło].
Regresja liniowa
Zadaniem algorytmu regresji liniowej jest odnalezienie prostej, która będzie pasować do danych uczących, a w przyszłości, umożliwi nam dokonywanie prognoz.
Z lekcji matematyki w szkole, znamy równanie prostej wyrażonej wzorem:
f(x) = ax + b
gdzie a, określa nam nachylenie,
a b jest wartością stałą.
Zadaniem regresji jest więc znalezienie najlepszych współczynników a oraz b dla danego zbioru danych. Wartości te nie są wybierane przypadkowo, muszą minimalizować błąd funkcji kosztu. Więcej o funkcji kosztu znajdziesz w linkowanym poradniku.
W przypadku modelu regresji liniowej najczęściej stosowaną funkcją kosztu jest błąd średniokwadratowy (ang. Sum of Squared Error, SSE), wyrażony wzorem:
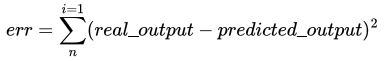
Z użyciem algorytmu gradientu prostego, odnajdujemy wartości parametrów a i b, które w najlepszy sposób minimalizują błąd algorytmu.
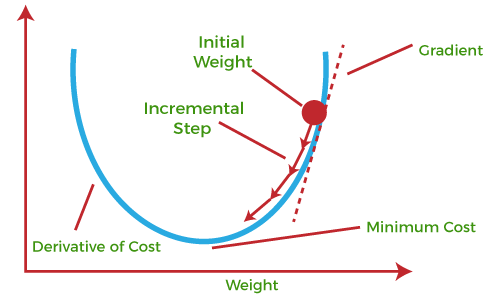 Algorytm gradientu prostego [źródło].
Algorytm gradientu prostego [źródło].
- Więcej informacji o algorytmie regresji liniowej.
- Więcej informacji o algorytmie gradientu prostego.
Przykład użycia
Zajmijmy się więc wykorzystaniem algorytmu regresji liniowej w praktyce, na przykładzie dokonywania prognozy cen mieszkań.
Zbiór danych
Na samym początku, przygotujmy zbiór danych, na których będziemy używać algorytmu regresji. Gotowy zbiór danych dotyczący prognoz cen nieruchomości znajdziemy tutaj: https://www.kaggle.com/
Zbiór ten przedstawia dane dotyczące cen nieruchomości oraz ich parametrów, jak wiek, odległość od stacji metra czy położenie.
Aby zaimportować dane w postaci pliku CSV do skryptu Javascript, możemy skorzystac z biblioteki csvtojson.
Zainstalujemy ją poleceniem:
Na potrzeby projektu, będziemy prognozować cenę mieszkania w oparciu o jego wiek. Podczas importu danych, wybierzemy więc tylko te cechy, które będą nam potrzebne.
Będą to więc kolumny:
X2 house age – czyli wiek mieszkania,
Y house price of unit area – czyli jego cena.
Wartości te możemy przedstawić na wykresie:
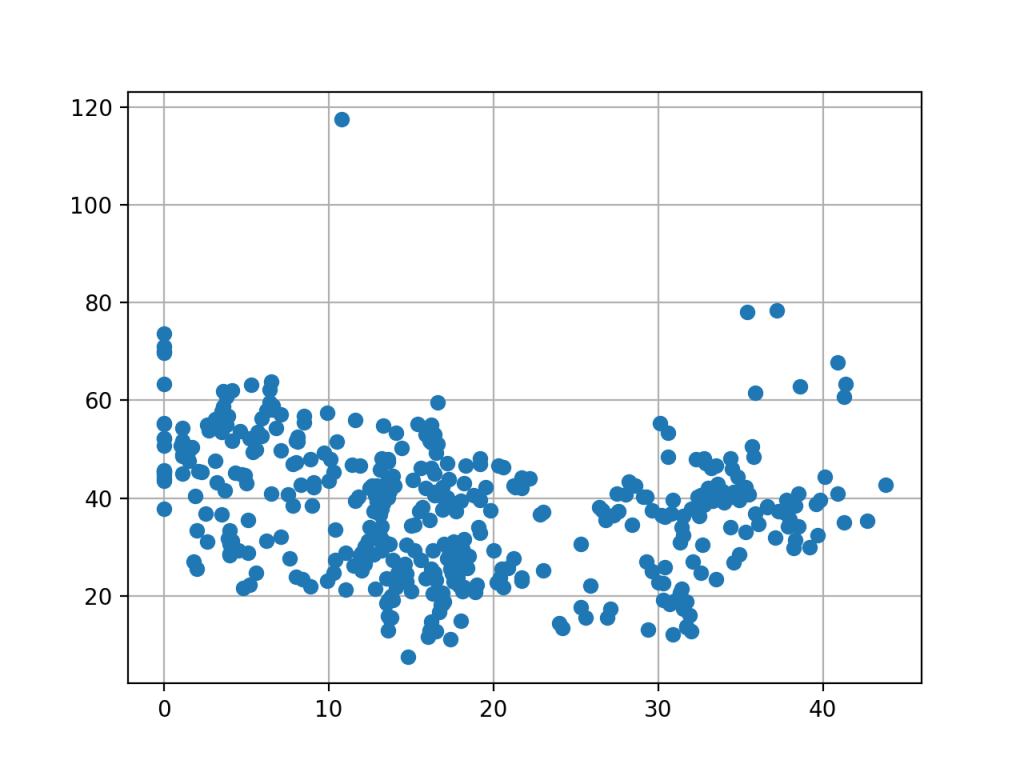 Porównanie wartości wieku do ceny mieszkania. Oś X przedstawia wiek mieszkania, a oś Y jego wartość.
Porównanie wartości wieku do ceny mieszkania. Oś X przedstawia wiek mieszkania, a oś Y jego wartość.
Algorytmy regresji
Aby użyć algorytmów regresji, możemy użyć biblioteki regressionjs: GitHub – Tom-Alexander/regression-js: Curve Fitting in JavaScript.
1. Aby ją zainstalować w naszym projekcie, możemy wykonać polecenie:
2. Aby odpowiednio przygotować dane, możemy użyć następującego kodu:
Biblioteka ta, przyjmuje dane w postaci tablicy tablic, w których trzymane są wartości poszczególnych cech.
3. Aby użyć algorytmu, wykonajmy następujący kod:
Wynikiem tej funkcji będzie równanie prostej:
y = -0.25x + 42.41
Taka funkcja będzie wyglądała następująco:
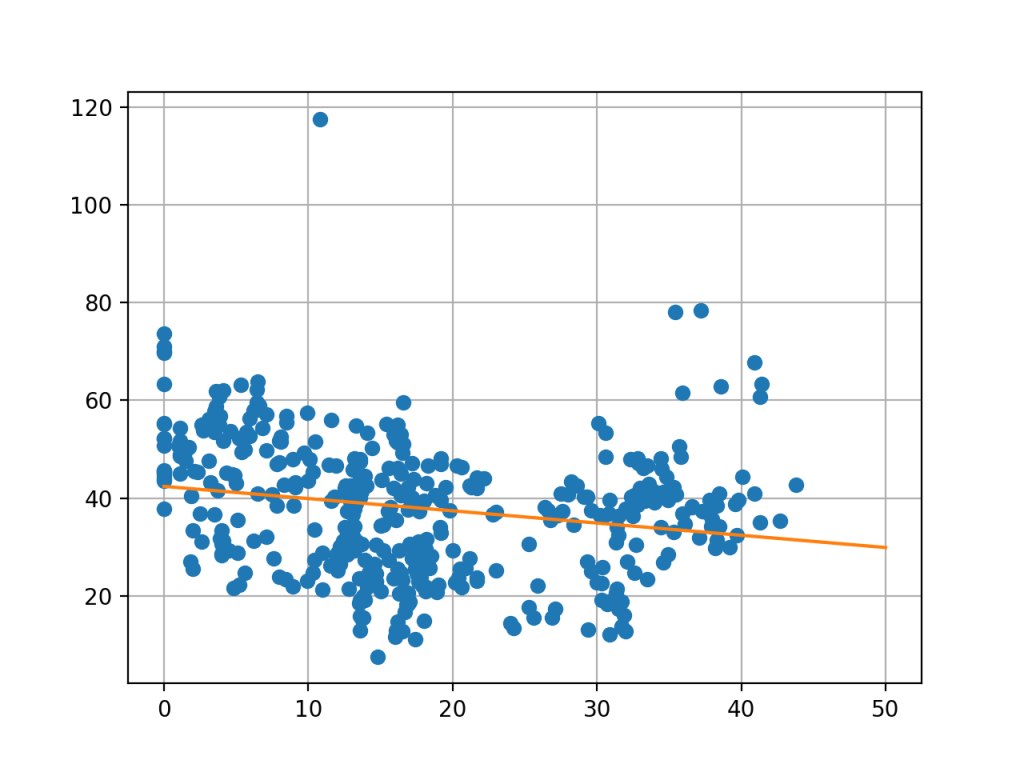 Funkcja liniowa prognozy dla zbioru danych.
Funkcja liniowa prognozy dla zbioru danych.
Możemy teraz użyć również obliczenia prognozy dla wybranej wartości wieku mieszkania (przyjmijmy, iż będzie to wartość równa 11).
4. Aby to zrobić wykonajmy funkcję:
Wynikiem będzie cena o wartości 39.66.
Regresja wielomianowa
Często aby poprawić wyniki prognozy, zamiast wyznaczania klasycznej funkcji liniowej, możemy użyć funkcji wygkładniczej, logarytmicznej czy wielomianowej. Wybór ten zależy bezpośrednio od typu danych wejściowych.
Funkcja wielomianowa to taka funkcja, którą możemy wyrazić wzorem:
f(x) = a n x n + a x – 1 x x – 1 + … + a 1 x + b
Naszym zadaniem jest więc wyznaczenie grupy parametrów an, an-1, … a1, b w taki sposób, aby jak najlepiej minimalizowały funkcję kosztu.
W bibliotece regressionjs, możemy użyć funkcji polynomial:
Wynikiem takiego algorytmu, będzie funkcja paraboliczna:
y = 0.04×2 + -1.93x + 53.45
Wygląda ona w następujący sposób:
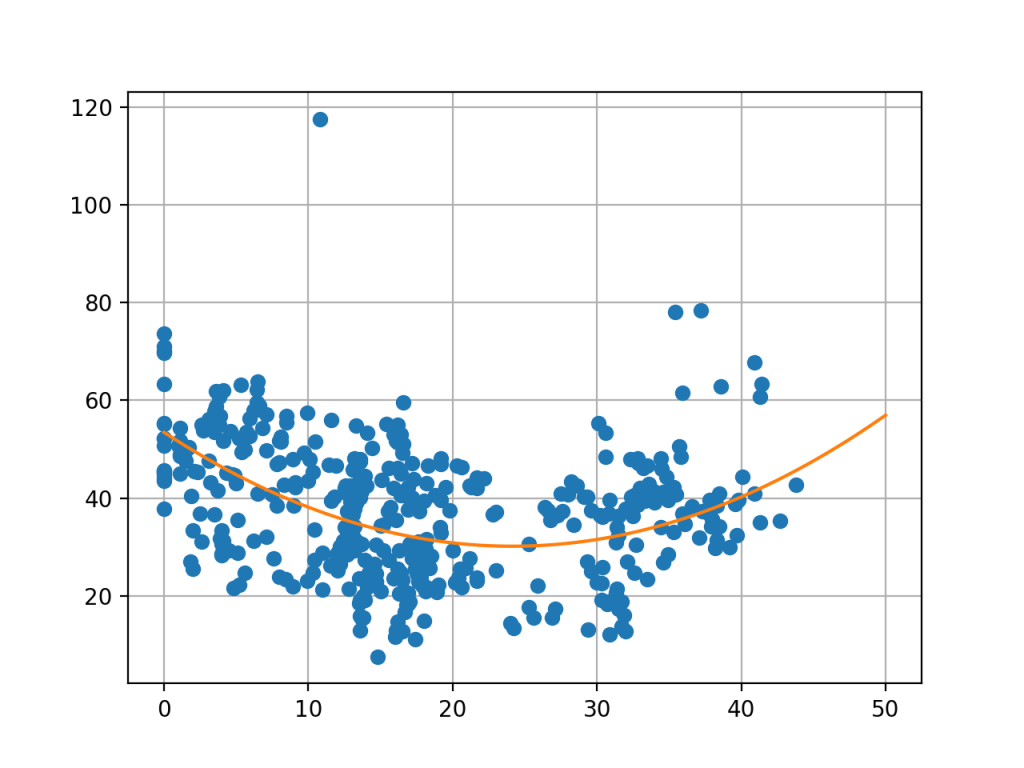 Jak widać, w lepszy sposób reprezentuje ona realne ułożenie danych.
Jak widać, w lepszy sposób reprezentuje ona realne ułożenie danych.
Wartością prognozy dla 11 lat będzie tutaj: 37.06.
Podsumowanie
Używanie algorytmów uczenia maszynowego nie jest zarezerwowane wyłącznie dla języków takich jak Python. Z powodzeniem możemy korzystać z niektórych rozwiązań w innych technologiach. Tworzenie prognoz z użyciem algorytmów regresji, jest więc bardzo proste w implementacji zwłaszcza z użyciem gotowych bibliotek języka Javascript.
Interesują Cię praktyczne zastosowania uczenia maszynowego i sztucznej inteligencji? Sprawdź resztę naszych poradników:
- Analiza semantyczna w React Native z wykorzystaniem Tensorflow
- Tworzenie natywnych procesorów klatek dla Vision Camera w React Native z użyciem OpenCV
- Detekcja pozy w czasie rzeczywistym w React Native z użyciem MLKit
- Burak Kanber: Hands-on Machine Learning with JavaScript, Packt Publishing: (https://github.com/Tom-Alexander/regression-js).
- Estate price dataset: (https://www.kaggle.com/datasets/quantbruce/real-estate-price-prediction?resource=download).
- Sandeep Khurana: Linear regression with example (2017) (https://towardsdatascience.com/linear-regression-with-example-8daf6205bd49).