Sztuczna inteligencja i uczenie maszynowe to pojęcia niezwykle popularne w ostatnim czasie. Stąd nic dziwnego, iż jest coraz więcej przypadków wykorzystania ich możliwości bezpośrednio na urządzeniach mobilnych. Wśród bibliotek umożliwiających wykorzystanie modeli uczenia maszynowego w aplikacjach React Native, możemy znaleść, m.in.
- Tensorflow.js for React Native
- PyTorch Live
Uczenie maszynowe może zostać w tym przypadku użyte do różnorodnych zadań związanych z rozpoznawaniem obrazów, analizą tekstu czy predykcją zdarzeń i wartości. Przeniesienie takich funkcjonalności bezpośrednio do aplikacji mobilnych, potrafi znacznie uprościć architekturę systemów poprzez przeniesienie części obliczeń bezpośrednio do urządzenia użytkownika końcowego.
 Analiza semantyczna w React Native z wykorzystaniem Tensorflow.
Analiza semantyczna w React Native z wykorzystaniem Tensorflow.
Analiza semantyczna
Wśród zadań dotyczących przetwarzania tekstów języka naturalnego (ang. Natural language processing, NLP), możemy wyróżnić między innymi klasyfikację. Model uczenia maszynowego (wykorzystujący, np. sztuczną sieć neuronową) może dopasować swoje wyniki w zależności od danych wejściowych (tzw. uczenie przez doświadczanie). Klasyfikacja musi przebiegać wg. pewnych reguł, które algorytm sam poznaje podczas procesu szkolenia.
Przyjrzyjmy się następującemu problemowi. W serwisie z recenzjami filmowymi, chcemy odpowiednio oznaczyć w sposób automatyczny opinie użytkowników, tj. czy dana opinia jest pozytywna czy negatywna. Jest to przykład klasyfikacji binarnej – tekst może mieć albo pozytywny albo negatywny wydźwięk, stąd możemy przypisać mu pewną klasę.
Aby jednak możliwe było pełne poznanie kontekstu oraz znaczenie słów, konieczne jest przeprowadzenie analizy semantycznej (kontekstowej). W przypadku nas samych, jesteśmy w stanie wyciągnąć sens słów bazując na własnych metodach poznawczych. W przypadku algorytmów uczenia maszynowego, konieczne jest natomiast wskazanie jakie konotacje dany tekst może zawierać, np. istotną informacją staje się otoczenie danego słowa (tj. w otoczeniu jakich słów znajduje się ono najczęściej).
Aby w praktyce rozwiązać ten problem, możemy użyć wcześniej wyszkolonego modelu konwolucyjnej sieci neuronowej bezpośrednio ze stron biblioteki Tensorflow. Model ten został wyszkolony w oparciu o opinie użytkowników z serwisu IMDB. Aby tekstowe dane wejściowe zostały zrozumiane przez algorytm, muszą zostać zapisane w odpowiedniej strukturze.
Konwolucyjne sieci neuronowe
Artykuł ten nie tłumaczy sposobu działania warstw konwolucyjnych czy algorytmów uczenia maszynowego. Więcej o sztucznych sieciach neuronowych możesz dowiedzieć się w świetnej książce autorstwa Auréliena Géron: Hands-on Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems.
Przygotowanie modelu
Pierwszym krokiem będzie wczytanie modelu oraz metadanych potrzebnych do przygotowania danych wejściowych. Przygotujmy nowy projekt React Native oraz zainstalujmy i zaimportujmy Tensorflow do dowolnego komponentu.
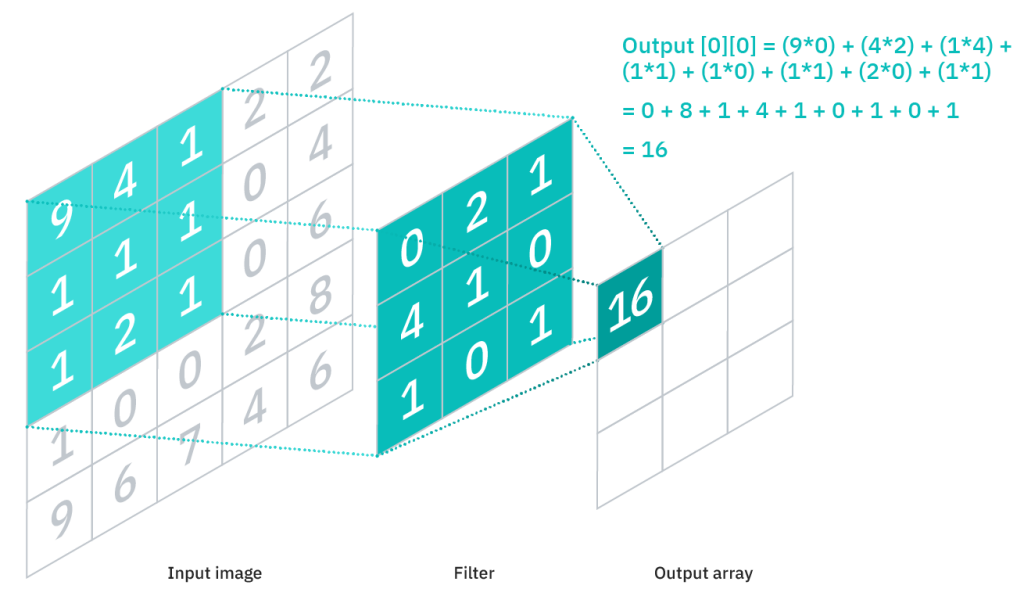 Przykładowe działanie warstw konwolucyjnych w sieci neuronowej. Źródło: https://www.ibm.com/cloud/learn/convolutional-neural-networks
Przykładowe działanie warstw konwolucyjnych w sieci neuronowej. Źródło: https://www.ibm.com/cloud/learn/convolutional-neural-networks
Model jest dostępny pod następującymi linkami:
Następnie możemy załadować potrzebne dane do pamięci (używając hooków useRef oraz useEffect).
Przygotowanie danych
Przyjmijmy, iż chcemy ocenić czy zdanie: „This film is bad” jest opinią pozytywną czy negatywną. Ważne jest najpierw przeprowadzenie na nim procesu wstępnego przetworzenia tekstu. Aby uprościć obliczenia, tekst powinien zostać zapisany małymi znakami, a znaki interpunkcyjne powinny zostać usunięte. Aby to zrobić możemy użyć gotowej biblioteki Tokenizr, umożliwiającej wykonanie procesu tokenizacji.
Po wykonaniu funkcji z powyższym zdaniem jako parametrem otrzymamy tablicę tokenów:
[„this”, „film”, „is”, „bad”]
Dla algorytmu same słowa tak naprawdę nie mają znaczenia – muszą zostać uprzednio zakodowane w postaci liczb, w taki sposób, aby łatwiejsze było ich przetworzenie. Możemy to zrobić z użyciem notacji Bag of Words, TF-IDF czy zastosować osadzanie słów w przestrzeni wektorowej. Wyszkolony model ze zbioru przykładów został przygotowany z użyciem algorytmu word2vec (szczegóły można znaleźć tutaj: link). W celu przedstawienia słów w formie liczb musimy użyć wcześniej przygotowanej struktury metadata, która zawiera zbiór słów wraz z przypisanymi im indeksami.
OOV_INDEX jest tutaj indeksem słowa nieznanego, które nie było użyte przy szkoleniu algorytmu. Każdemu słowu które pojawi się w opinii, a którego nie było w korpusie słów, zostanie przypisana właśnie wartość OOV_INDEX.
Po tym procesie nasze zakodowane zdanie będzie miało postać:
[14, 22, 9, 78]
Wejście dla sieci neuronowej musi mieć stałą wielkość (tzw. rozmiar ramki). W przypadku modelu z przykładu, wartość ta jest równa 100. Stąd musimy dodatkowo zapisać powyższe zdanie w formie stu-elementowej tablicy liczb. Aby to zrobić możemy użyć uproszczonej funkcji padSequences, która uzupełni brakujące miejsca zerami lub w przypadku tekstu większego niż sto słów, podzieli je na stosowne stu elementowe ramki.
Następnie funkcja musi zostać wywołana:
Po wykonaniu funkcji, dane będą wyglądały następująco:
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 14, 22, 9, 78]
Tensory
Tensorflow to biblioteka, która wykorzystuje grafy przepływu danych (grafy skierowane), w których wierzchołach przechowywana jest informacja o operacjach matematycznych lub wymianie danych, a krawędzie służą do przedstawienia przepływu tych danych (relacje wyjścia-wejścia).
Przedstawiane są one jako wielowymiarowe macierze danych, czyli inaczej tensory. Każdy tensor może być aktywowany w sposób asynchroniczny, równolegle do aktywacji innych tensorów.
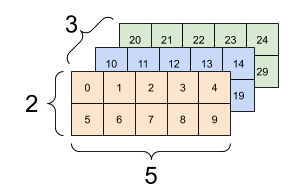 Przykładowa reprezentacja tensora 3-wymiarowego, źródło: https://www.tensorflow.org/guide/tensor
Przykładowa reprezentacja tensora 3-wymiarowego, źródło: https://www.tensorflow.org/guide/tensor
Aby dane mogłyby wejściem dla sieci neuronowej, muszą zostać zapisane w formie dwuwymiarowego tensora:
Predykcja
Tak przygotowane dane mogą już stanowić wejście dla konwolucyjnej sieci neuronowej (tj. wyszkolonego wcześniej modelu). Po procesie klasyfikacji otrzymamy wartość prawdopodobieństwa przynależności naszego zdania do wybranej klasy (będzie ona w przedziale [0,1]). Im większa wartość, tym większe prawdopodobieństwo, iż zdanie będzie miało pozytywny wydźwięk. Możemy przyjąć więc, iż o ile wartość score będzie w przedziale [0.5, 1], to tekst będzie miał charakter pozytywny, a w innym przypadku negatywny.
Po poznaniu wartości końcowej, aby oszczędzić pamięć, wcześniej zbudowany tensor powinien zostać usunięty, dlatego używamy metody dispose().
Przyjrzyjmy się teraz w jaki sposób działa to w naszej aplikacji.
 Widok aplikacji.
Widok aplikacji.
Podsumowanie
Tak jak widać na powyższym przykładzie, zastosowanie modeli uczenia maszynowego bezpośrednio w aplikacji mobilnej nie jest skomplikowanym zadaniem. Możliwość przeniesienia wcześniej wyszkolonego modelu na urządzenie, pozwala sprawnie korzystać z dobrodziejstw ML do wyszukanych i niebanalnych zadań.
- https://www.tensorflow.org/js
- https://blog.tensorflow.org/2020/02/tensorflowjs-for-react-native-is-here.html
- https://github.com/rse/tokenizr