Uważa się, iż zbudowanie systemu operacyjnego jest wymagającym zadaniem. To oczywiście prawda, szczególnie w sytuacji, gdy taki system piszemy od zupełnych podstaw. Mniej skomplikowanym zagadnieniem jest użycie gotowych (w znaczeniu dostępności kodu źródłowego) komponentów, natomiast ich integracja wciąż stanowi dość zaawansowaną procedurę. Trzeba jednak przyznać, iż zasady działania systemów operacyjnych to wyjątkowo interesująca tematyka. Polecam zapoznać się z teoretycznym opracowaniem z tego zakresu, dostępne są obszerne branżowe pozycje książkowe.
W tym artykule opiszę kroki prowadzące do uzyskania działającego systemu, który dodatkowo będzie posiadał możliwość hostowania podstawowych aplikacji napisanych w języku PHP. Do systemu będzie możliwy dostęp SSH oraz przez zwykłą konsolę. Zaczniemy od przedstawienia BusyBox.
BusyBox
BusyBox to pojedynczy skompilowany plik binarny o rozmiarze zbliżonym do 1 MB zawierający funkcje wielu typowych narzędzi dostępnych w systemach UNIX (nie są to oryginały, a customowe wersje przygotowane przez twórców BusyBox). Dzięki tej prostocie i pewnej uniwersalności znajduje zastosowanie w systemach wbudowanych (embedded), gdzie kluczowa jest oszczędność zasobów. Używany jest także w systemie Alpine. Bardziej rozbudowany, choć sprowadzający się do podanej tutaj definicji opis BusyBox znajdziemy w tym miejscu.
Opisywane narzędzie powinno być dostępne w zdecydowanej większości systemów Linux, jedynie wersja może nie być najbardziej aktualna. Przykładowo w systemie Ubuntu 22.04 i jego domyślnym repozytorium znajdziemy wersję 1.30, gdzie najnowszą wersją nie wymagającą kompilacji we własnym zakresie jest 1.35. Gotowe do użycia pliki BusyBox dostępne są pod adresem https://busybox.net/downloads/binaries/. Binarkę zapisujemy w katalogu /usr/bin i nadajemy jej prawo do wykonania.
Uruchomienie polecenia busybox zwróci listę dostępnych funkcji.
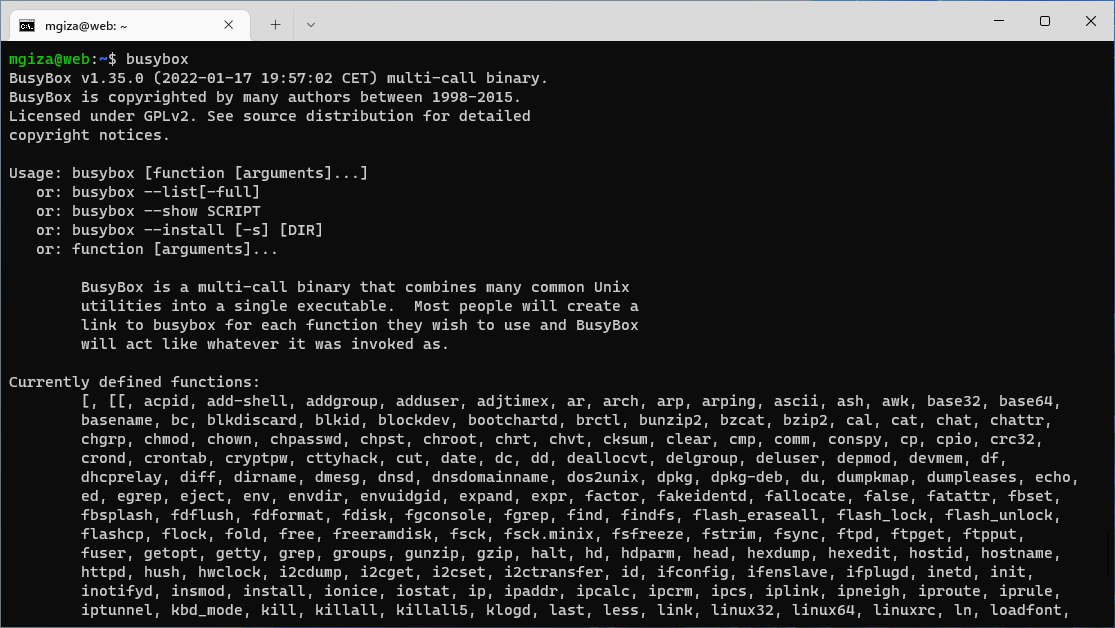
Podanie nazwy dowolnego dostępnego polecenia jako parametr umożliwi jego praktyczne wykorzystanie, co widać na poniższym zrzucie ekranu. Część wbudowanych narzędzi wymaga uprawnień root, więc próby ich uruchomienia na prawach zwykłego użytkownika nie przyniosą efektów.
Sam BusyBox (niezależny od pliku z /usr/bin) został zawarty również w plikach initrd, które w środowiskach Linux odpowiadają za wykonanie kroków przedstartowych. Jest ładowany w przypadku niepowodzenia rozruchu systemu operacyjnego.
Plik initrd.img z katalogu /boot to najczęściej link symboliczny do określonej wersji initial ramdisk powiązanej z aktualnym kernelem. Warto spróbować przeprowadzić modyfikację tego pliku. Do wypakowania służy polecenie unmkinitramfs, w którym oprócz nazwy pliku initrd należy podać nazwę katalogu wynikowego.
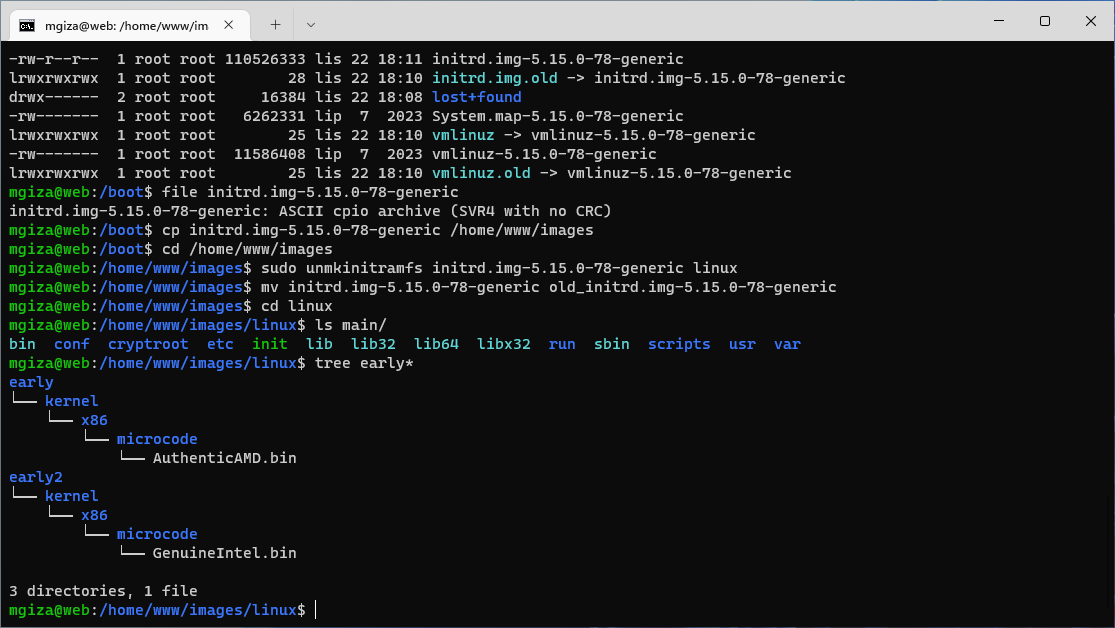
Od razu można zauważyć, iż adekwatna struktura katalogów znajduje się w main. Zapisałem w tym katalogu plik tekstowy, który następnie odczytamy z poziomu initramfs. Sposób ponownego zbudowania initrd z tych trzech katalogów niestety nie jest zbyt oczywisty. Należy wykonać poniższe polecenia.
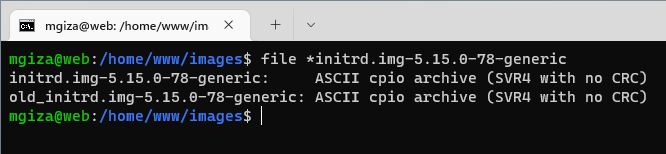
Typ oryginalnego pliku jak i utworzonego przez nas jest taki sam, więc można się spodziewać, iż initrd.img zostanie prawidłowo wykonany. Nazwa nowego pliku jest zgodna z pierwotną, dzięki czemu nie musimy wprowadzać żadnych dodatkowych zmian w grub.cfg.
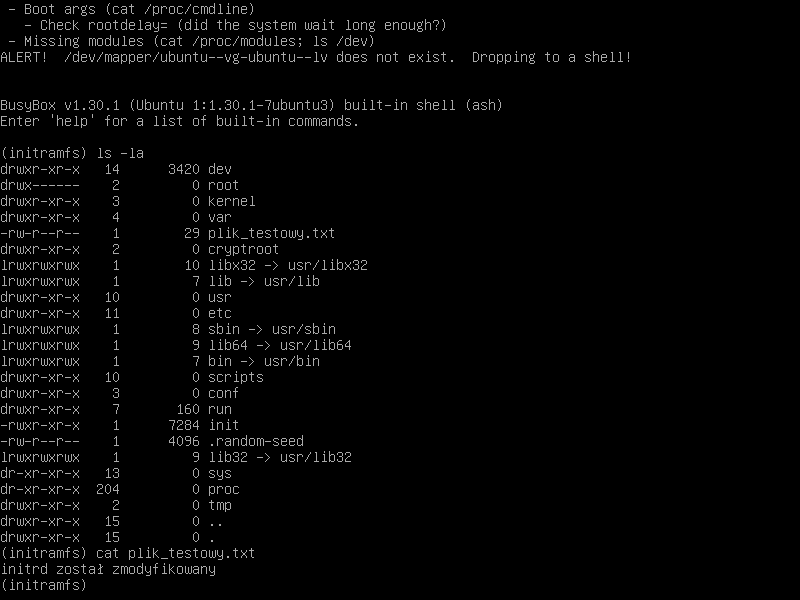
Podmieniamy plik w katalogu /boot. Przy kolejnym niepowodzeniu rozruchu zobaczymy utworzony przez nas plik tekstowy.
BusyBox jako kontener Docker
BusyBox można uruchomić w formie kontenera (oficjalny obraz ma ponad miliard pobrań) i sprawdza się to w niektórych procesach CI/CD (więcej o automatyzacji wdrożeń z użyciem GitLab CI/CD pisałem tutaj). W AVLab.pl wykorzystywany jest autorski system do gromadzenia i analizowania złośliwych adresów URL. W jednym ze stage’y CI/CD dla tego projektu przez pewien czas używałem obrazu BusyBox do utworzenia archiwum TGZ z kodem aplikacji, które następnie z użyciem bardziej złożonego obrazu było odpowiednio wysyłane na docelowy serwer. Po dodaniu funkcjonalności skanowania i związanej z tym konieczności zastosowania innego obrazu dalsze utrzymywanie pojedynczego stage’a z BusyBox przestało być zasadne. Natomiast zawsze powinniśmy używać jak najmniejszych obrazów do zadań, które nie wymagają specjalnych zasobów.
Na Stack Overflow znalazłem całkiem zabawne pytanie, w którym autor wyraził przekonanie, iż rzekomo rozumiał zastosowanie Docker’a do czasu, aż nie natknął się na obraz BusyBox.
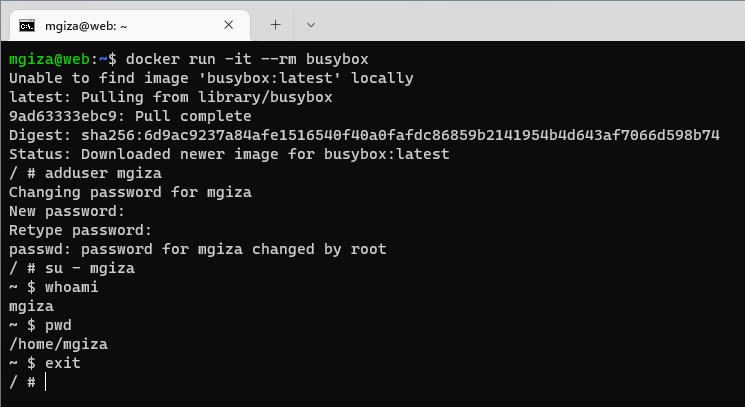
Przykładowy start kontenera można zainicjować w ten sposób:
Nie dodaliśmy parametru -d, przez co kontener nie uruchomił się w tle i uzyskaliśmy bezpośrednio dostęp do jego powłoki SH.
BusyBox zawiera serwer WWW httpd. Nazwa kojarzy się z serwerem Apache, ale tutaj zastosowano własne rozwiązanie, którego kod źródłowy (jeden plik C) i jednocześnie dokumentacja znajduje się w repozytorium projektu. Możemy uruchomić nowy kontener z serwerem httpd działającym w trybie foreground (właściwym dla kontenerów).
Dodaliśmy przekierowanie z lokalnego portu 8090 na port 80 w kontenerze. Po wejściu na ten port zobaczymy stronę z kodem błędu 404, ponieważ w katalogu /var/www nie ma żadnego pliku index.
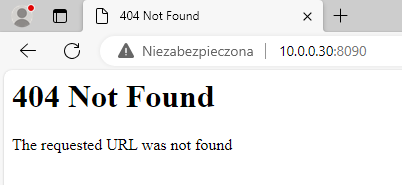
Jedynym edytorem tekstu zawartym w BusyBox jest vi, dlatego nie pozostaje nam nic innego, jak utworzyć plik /var/www/index.html z dowolną zawartością.
Przeładowanie strony spowoduje teraz wyświetlenie tego pliku.
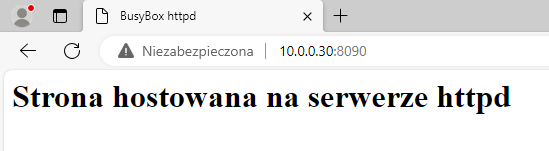
Serwer httpd w odpowiedzi wysyła standardowe nagłówki HTTP.
mgiza@web:~$ curl -I 10.0.0.30:8090
HTTP/1.1 200 OK
Date: Sun, 21 Jan 2024 19:58:49 GMT
Connection: close
Content-type: text/html
Accept-Ranges: bytes
Last-Modified: Sun, 21 Jan 2024 19:57:02 GMT
ETag: „65ad770e-a3”
Content-Length: 163
httpd posiada możliwość wykonania skryptów PHP (jako CGI). Obraz BusyBox jest przystosowany do uruchamiania polecenia php (zawiera pewne biblioteki systemowe), natomiast i tak konieczna jest kompilacja. Sugeruję zbudowanie własnego obrazu zawierającego pliki i katalogi utworzone po kompilacji. Oprócz tego niezbędne jest dodanie konfiguracji httpd, stąd użycie docker-compose wydaje się najlepszym rozwiązaniem.
Tworzymy plik httpd.conf z poniższą zawartością:
W katalogu strona umieszczamy przykładową witrynę. W moim przypadku do pliku index.html dodałem odnośnik do pliku info.php zawierającego kod:
Dzięki temu będziemy mieć potwierdzenie, iż PHP jest poprawnie obsługiwany przez httpd. Do kompilacji potrzebne będą pewne pakiety:
make i gcc od zawsze są związane z procesami kompilacji, pozostałe trzy są wymagane do kompilacji PHP na Ubuntu. W przypadku innych dystrybucji istnieje szansa, iż brakuje nam większej ilości pakietów. Wtedy skrypt configure zwróci błąd informujący o potrzebie doinstalowania danej biblioteki (ich nazwy niestety nie zawsze wskazują jednoznacznie pakiety dostarczające daną bibliotekę).
Kod źródłowy PHP znajdziemy na stronie https://www.php.net/downloads, w tej chwili najnowsze wydanie to 8.3.2. Musimy wprowadzić niewielką zmianę w kodzie, która zapobiegnie otrzymywaniu błędu Security Alert! The PHP CGI cannot be accessed directly przy próbie wykonania skryptów PHP z poziomu przeglądarki. Interesuje nas plik sapi/cgi/cgi_main.c i linie:
w których wartości 1 zamieniamy na 0.
Kod jest przygotowany, więc następnie wykonujemy skrypt configure z tymi parametrami:
–enable-static wymusi zbudowanie bibliotek statycznych, co jest istotne w minimalnych środowiskach. Ta opcja powinna być aktywna domyślnie. –prefix określa katalog, do którego zostaną skopiowane dane wynikowe po wykonaniu polecenia make install (podana ścieżka musi być bezwzględna). Z kolei –disable-all sprawi, iż kompilacja obejmie wyłącznie rozszerzenia niezbędne do działania PHP (co zmniejsza rozmiar danych wynikowych oraz znacznie skraca czas kompilacji).
Wykonanie poleceń make i make install spowoduje skompilowanie kodu oraz skopiowanie danych wynikowych do podanego katalogu.
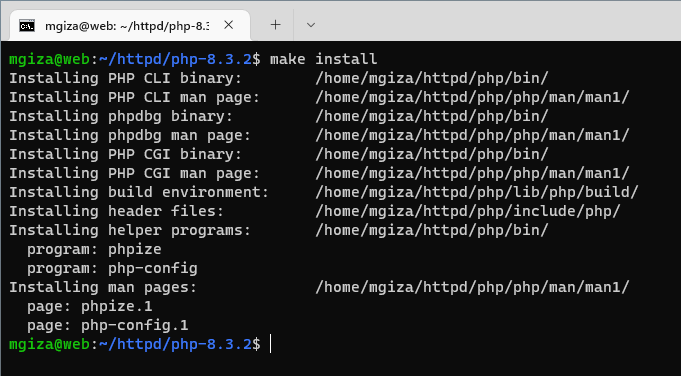
Tworzymy pliki Dockerfile i docker-compose.yml.
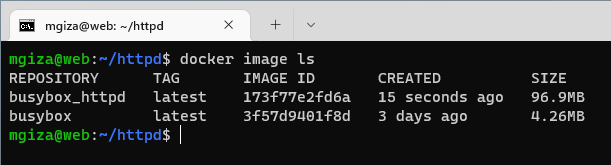
Możemy porównać rozmiar zbudowanego obrazu z “czystym” obrazem BusyBox.
Ostatecznie po uruchomieniu kontenera kod PHP jest interpretowany, co potwierdza poniższy zrzut ekranu.
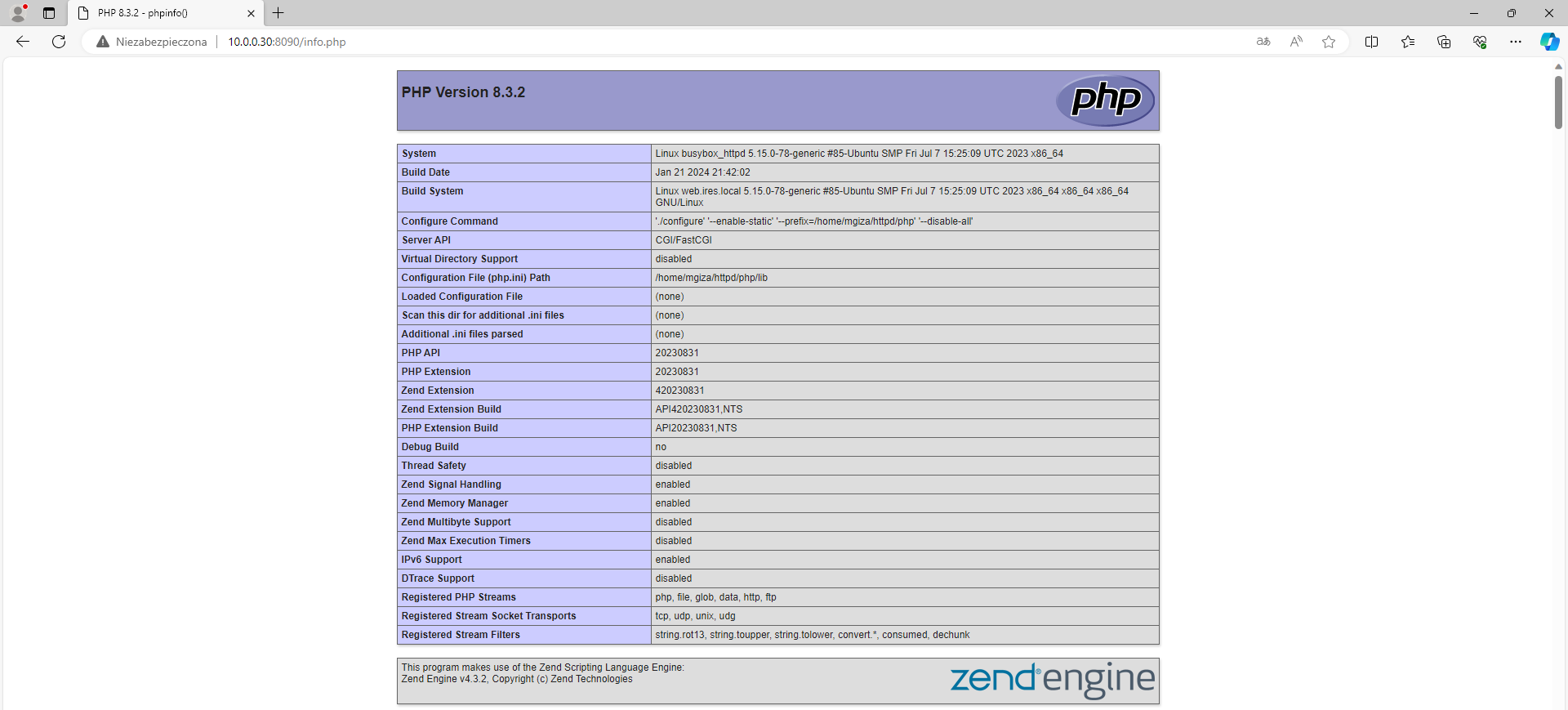
Poprawnie działa ponadto polecenie php wykonane w kontenerze.
Kompilowanie składników systemu
Zajmiemy się teraz adekwatnym procesem tworzenia systemu operacyjnego. Najpierw utworzymy zwykły bootowalny plik ISO (Live CD), który będzie wykorzystywany do testów działania systemu. Systemy Live CD mogą być również użyteczne celem przeprowadzenia podstawowej diagnostyki i ewentualnej naprawy (czy choćby skopiowania danych), gdy nasz główny system operacyjny z jakiegoś powodu ulega awarii przy próbie uruchomienia.
Zanim jednak przystąpimy do tego zadania, to w pierwszej kolejności wymagana jest kompilacja kluczowych części tworzonego systemu. Oprócz PHP potrzebujemy serwera SSH, pakietu do obsługi LVM (niezbędny w przypadku operacji na partycjach LVM) i samego BusyBox (wraz z pewną ilością dodatkowych plików) jako narzędzia dostarczającego polecenia systemowe. Nie można też zapomnieć o kompilacji kernela, który jest najważniejszym elementem każdego systemu, wraz z modułami (dla naszego zastosowania jedynie podstawowe — ext4 i ntfs). Dodatkowo pojawi się konieczność napisania własnego pliku init, służącego do początkowej inicjalizacji systemu.
Nasz system operacyjny nie będzie przeznaczony do standardowej instalacji. Absolutnie nie można określić tego ograniczeniem. Przy użyciu prostej składni polecenia grep ustalimy na podstawie zawartości pliku /etc/shadow, czy użytkownik root ma ustawione hasło, a jeżeli nie, to zostanie ustawione hasło domyślne, np. root1234. Tę logikę zaimplementujemy właśnie w /init.
BusyBox zapewnia gotowy plik /sbin/init, natomiast większą wartość ma jednak przygotowanie autorskiego rozwiązania. Skorzystamy oczywiście z /sbin/init, ponieważ do wykonania pewnych operacji (załadowanie procesów działających w tle, przeprowadzenie konfiguracji sieci itd.) zwyczajnie sprawdza się lepiej.
Dropbear
Dropbear to serwer SSH, który w zastosowaniach embedded jest adekwatnie bezkonkurencyjny. Nie wymaga żadnych dodatkowych bibliotek, a wielkość pliku wykonywalnego potrafi być zaskakująco niewielka. Przed kompilacją należy doinstalować pakiety autoconf i zlib1g-dev.
Archiwum z najnowszą wersją widoczne jest zawsze pod adresem https://matt.ucc.asn.au/dropbear/. Wykonujemy polecenia:
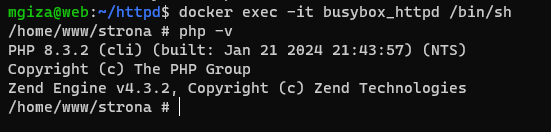
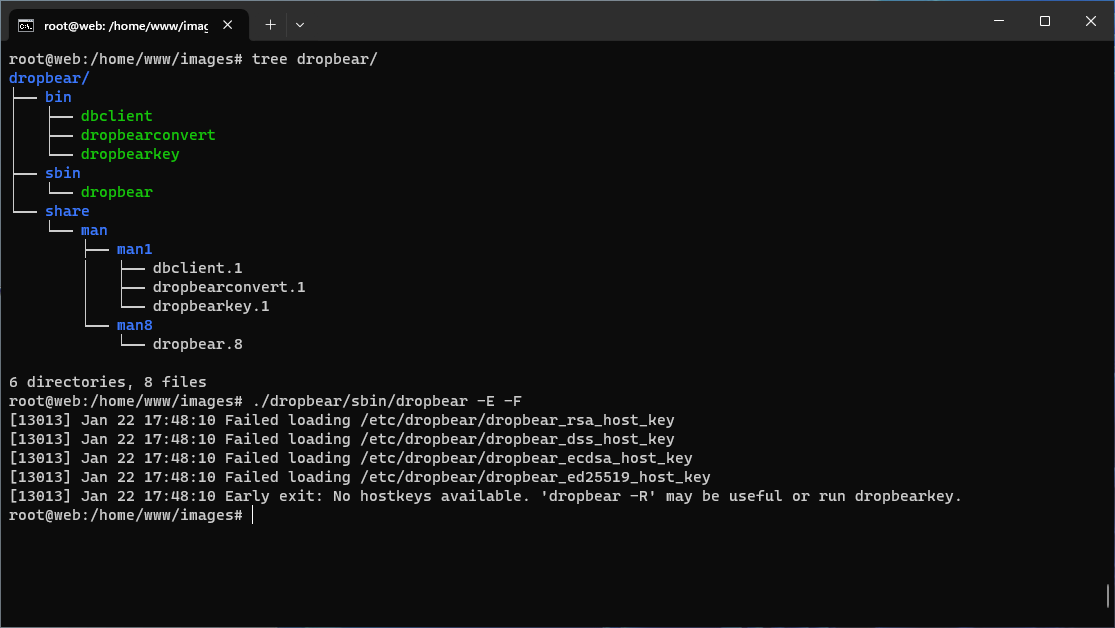
Pojawi się informacja configure: Now edit localoptions.h to choose features. Kopiujemy plik default_options.h jako localoptions.h, nie ma potrzeby edycji domyślnych ustawień. Jak zawsze wykonujemy następnie polecenia make i make install, natomiast przy make ważne jest określenie plików binarnych, które zamierzamy otrzymać:
Można zauważyć, iż kompilacja się powiodła, a dropbear ma możliwość uruchomienia.
LVM
Wspólne archiwum zawierające źródła wszelkich pakietów odpowiadających za obsługę LVM w systemie znajdziemy na stronie https://sourceware.org/ftp/lvm2/. Przed kompilacją musimy zainstalować pakiet libaio-dev, a sama procedura nie wymaga żadnych nietypowych czynności. Standardowo wykonujemy skrypt configure podając –prefix, a dalej make i make install.
BusyBox
Kody źródłowe zostały umieszczone w tym miejscu: https://busybox.net/downloads/. Aktualnie najnowsza wersja znajduje się w archiwum busybox-1.36.0.tar.bz2. Potrzebny będzie pakiet libncurses-dev. Po wypakowaniu katalogu wykonujemy w nim w zasadzie analogiczne polecenia, jednak z dwoma dodatkowymi na samym początku:
Zostanie wyświetlony „interaktywny” prompt, z którego poziomu przechodzimy do Settings i klawiszem spacji zaznaczamy checkbox znajdujący się przy opcji Build static binary (no shared libs) w sekcji Build Options.
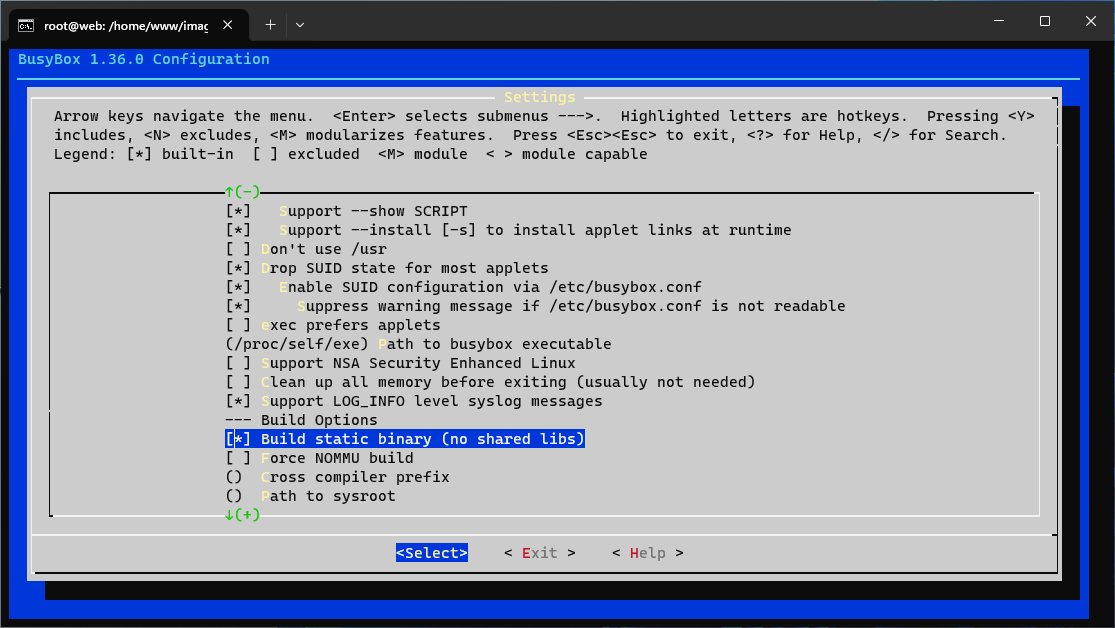
Dalej wybieramy dwukrotnie Exit z dolnego paska i przy pytaniu Do you wish to save your new configuration? wybieramy, co oczywiste, Yes. Możemy teraz wykonać make i make install. W katalogu _install zostaną utworzone symlinki do pliku /bin/busybox odpowiadające nazwom dostępnych poleceń. To oczekiwany rezultat. W tym momencie posiadamy wszystkie najważniejsze z punktu widzenia użyteczności elementy.
Wstępne przygotowanie
Do katalogu _install kopiujemy całą zawartość skompilowanego katalogu z PHP, katalog z witryną (home/www/strona) oraz konfigurację serwera WWW, czyli plik httpd.conf. Wszystkie konfiguracje najlepiej przechowywać w katalogu etc, to tradycyjna praktyka w systemach Linux.
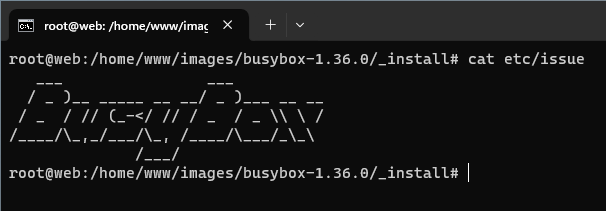
Dalej w pliku etc/hostname zapisujemy dowolnie wybraną nazwę hosta (w moim przypadku linux). Z kolei w pliku etc/issue możemy umieścić komunikat „powitalny”, który będzie wyświetlany przed każdym logowaniem w konsoli. Zwykły tekst nie wygląda może świetnie, dlatego proponuję wygenerować tzw. ASCII art z dowolną frazą. Trzeba mieć świadomość, iż w małej konsoli nie wszystkie napisy zostaną wyświetlone w całości. Widoczny poniżej ASCII art stanowi pewnego rodzaju kompromis pomiędzy estetyką a ograniczeniami konsoli (jedynie znak „x” jest częściowo przysłonięty).
Kopiujemy skompilowaną zawartość z katalogów wynikowych dropbear i lvm (tutaj można pominąć podkatalog usr/share). Tworzymy pusty katalog root, który będzie katalogiem domowym dla wiadomego użytkownika oraz serię plików w katalogu etc.
group
root:x:0:
crontab:x:112:
passwd
root:x:0:0:root:/root:/bin/sh
shadow (skopiowałem odpowiednią linię z pliku /etc/shadow systemu Ubuntu)
root:*:19579:0:99999:7:::
resolv.conf
nameserver 10.0.0.1
Dla pliku etc/shadow bardzo ważne pod względem bezpieczeństwa jest ustawienie chmod 640, aby nikt oprócz użytkownika root nie miał do niego dostępu.
BusyBox zapewnia obsługę sieci. Zamiast manualnej konfiguracji dzięki serii poleceń przy każdym uruchomieniu bardziej profesjonalnym rozwiązaniem będzie zapis ustawień w pliku etc/network/interfaces:
Aby interfejsy sieciowe mogły zostać włączone / wyłączone, musimy jeszcze utworzyć kilka katalogów w etc/network:
Ważnym aspektem jest także poprawna obsługa daty i czasu (strefy czasowe). W tym celu w pliku etc/timezone należy podać adekwatną dla nas strefę (Europe/Warsaw), skopiować katalog /usr/share/zoneinfo z naszego systemu (do usr/share) oraz utworzyć plik etc/profile, w którym zapiszemy
Do obsługi cron’a niezbędny jest katalog var/spool/cron/crontabs wraz z odpowiednimi uprawnieniami:
Tworzymy jeszcze pusty plik var/log/wtmp, z którego korzysta polecenie last wyświetlające bieżące i ostatnie logowania użytkowników w systemie.
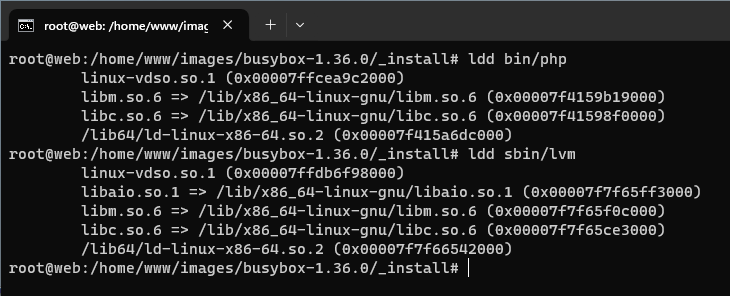
Do naszego systemu dodaliśmy obsługę PHP oraz LVM, natomiast brakuje nam kilku bibliotek. Co ciekawe, jeżeli zbudujemy i uruchomimy system z pominięciem tych bibliotek, to przy próbie wykonania np. php -v, czy choćby /bin/php -v zostanie zwrócony komunikat informujący o tym, iż nie znaleziono polecenia php (pomimo iż binarka znajduje się w katalogu /bin i jest wykonywalna). Taka „reakcja” świadczy właśnie o braku niezbędnych bibliotek. Dodam też, iż serwer httpd w tej sytuacji zwróci kod błędu 404 dla wszystkich skryptów PHP wykonywanych z poziomu przeglądarki.
Polecenie ldd wypisze listę bibliotek wymaganych przez oba pliki binarne. Widoczne biblioteki wystarczy skopiować z głównego systemu do analogicznych lokalizacji w budowanym systemie. Tę samą procedurę należało zastosować podczas tworzenia chroot, o czym pisałem w dedykowanym artykule.
Kompilacja kernela
Przeprowadzenie kompilacji jądra Linux nie jest skomplikowane, jednak z pewnością zajmie więcej czasu niż wszystkie pozostałe. Instalujemy wymagane pakiety:
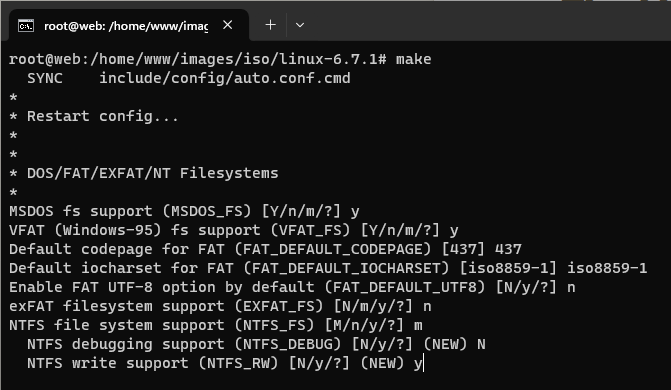
Link do archiwum z kodem najnowszej wersji kernela znajdziemy bezpośrednio na stronie https://kernel.org/ (Latest Release). Po wypakowaniu wykonujemy polecenie make defconfig. Zostanie utworzony plik .config, w którym opcjom CONFIG_EXT4_FS i CONFIG_NTFS_FS przypisujemy m. Dzięki temu będzie możliwość skompilowania modułów kernela do obsługi tych dwóch systemów plików.
Wykonujemy dalej make (można z parametrem -j podając ilość dostępnych CPU), po czym zobaczymy dwa „pytania” dotyczące systemu NTFS. Debugging nie będzie konieczny, natomiast wsparcie zapisu danych na dysku z tym systemem plików jak najbardziej.
Po skończeniu kompilacji plik bzImage z kernelem zostanie zapisany w katalogu arch/x86/boot. Zarówno plik kernela (najlepiej skopiować go pod nazwą vmlinuz) oraz pliki System.map i .config kopiujemy w inne miejsce, ponieważ będą potrzebne przy tworzeniu partycji rozruchowej. Teraz jest czas na skompilowanie wspomnianych wcześniej modułów. Służą do tego polecenia
Moduły zapisały się w katalogu lib w widocznej ścieżce. Zawarte zostało niepotrzebne dowiązanie symboliczne build (lib/modules/6.7.1/build) — można je usunąć.
Tworzenie skryptu init i obrazu systemu
Kopiujemy zawartość katalogów _install i lib z modułami do osobnej lokalizacji. System jest praktycznie gotowy, pozostało nam wyłącznie przygotowanie skryptu init. Na początku skrypt powinien utworzyć kilka niezbędnych do pracy systemu katalogów.
Skrypt sprawdza więc, czy wypisane katalogi istnieją. jeżeli warunek nie jest prawdziwy, to zostaną utworzone. Do katalogów systemowych należy zamontować specjalne systemy plików.
BusyBox nie ładuje automatycznie modułów kernela, więc polecenie użycie polecenia mount w celu zamontowania partycji ext4 czy NTFS musiałby zawierać parametr -t <system_plików> lub być poprzedzone poleceniem modprobe <moduł_kernela>. Byłoby to uciążliwe, dlatego dodamy proste polecenie, w którym dla każdej linii z pliku /etc/modules.conf wykonujemy modprobe. Nie ma możliwości załadowania kilku modułów jednocześnie (polecenie modprobe nic wtedy nie zwraca, więc wydaje się, iż zadziałało, ale nie jest to prawdą).
Ustawiamy także hostname dla naszego systemu.
Podnosimy interfejsy sieciowe.
Wykonujemy sprawdzenie, czy istnieje katalog i pliki potrzebne do działania Dropbear.
Ustawiamy domyślne hasło root, gdy nie zostało zmienione, aby umożliwić zalogowanie do systemu.
Na koniec przekazujemy działanie do skryptu /sbin/init. exec jest tutaj bardzo istotny, ponieważ /sbin/init musi mieć ustawiony PID 1 (pierwszy proces w systemie).
Nadajemy prawo do wykonania dla utworzonego skryptu init. W dalszej kolejności tworzymy katalog etc/init.d i plik etc/init.d/rcS o następującej zawartości:
Jest to lista poleceń, które mają zostać uruchomione w tle (deamon) po każdym starcie systemu. Dodajemy też plik etc/inittab:
Za interpretację tego pliku odpowiada właśnie skrypt /sbin/init. Oba dodane pliki muszą mieć ustawione prawo do wykonania. Pozostało nam już adekwatnie tylko utworzenie pliku etc/modules.conf, którego zawartości można się domyślić:
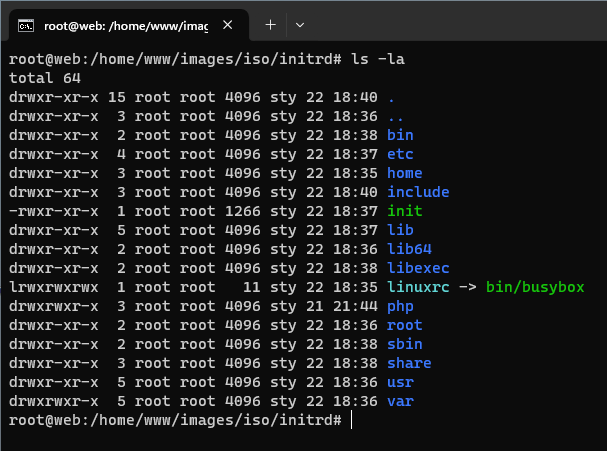
Katalog główny naszego systemu ostatecznie wygląda w ten sposób:
Całą zawartość widocznego katalogu zapisujemy do odpowiedniego pliku initrd.img poleceniem
Tworzenie bootowalnego pliku ISO
W celu utworzenia pliku ISO posiadającego możliwość uruchomienia systemu (z pliku initrd.img) skorzystamy z narzędzia ISOLINUX (do pobrania stąd). Tworzymy katalog cdboot/isolinux. Do katalogu cdboot kopiujemy pliki vmlinuz i initrd.img. Natomiast do katalogo cdboot/isolinux przenosimy z rozpakowanego archiwum pliki bios/core/isolinux.bin i bios/com32/elflink/ldlinux/ldlinux.c32. W tym miejscu musi znaleźć się także plik konfiguracyjny isolinux.cfg:
Docelowy plik ISO utworzymy narzędziem mkisofs (z pakietu genisoimage).
Możemy go choćby zamontować do wybranego katalogu. Jak widać, plik jest poprawny i zawiera potrzebne dane.
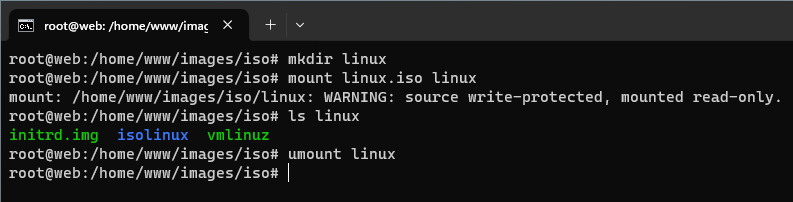
Testy systemu Live CD
Uruchomiłem maszynę wirtualną z systemem z utworzonego pliku ISO. System został poprawnie załadowany i jest gotowy do pracy.
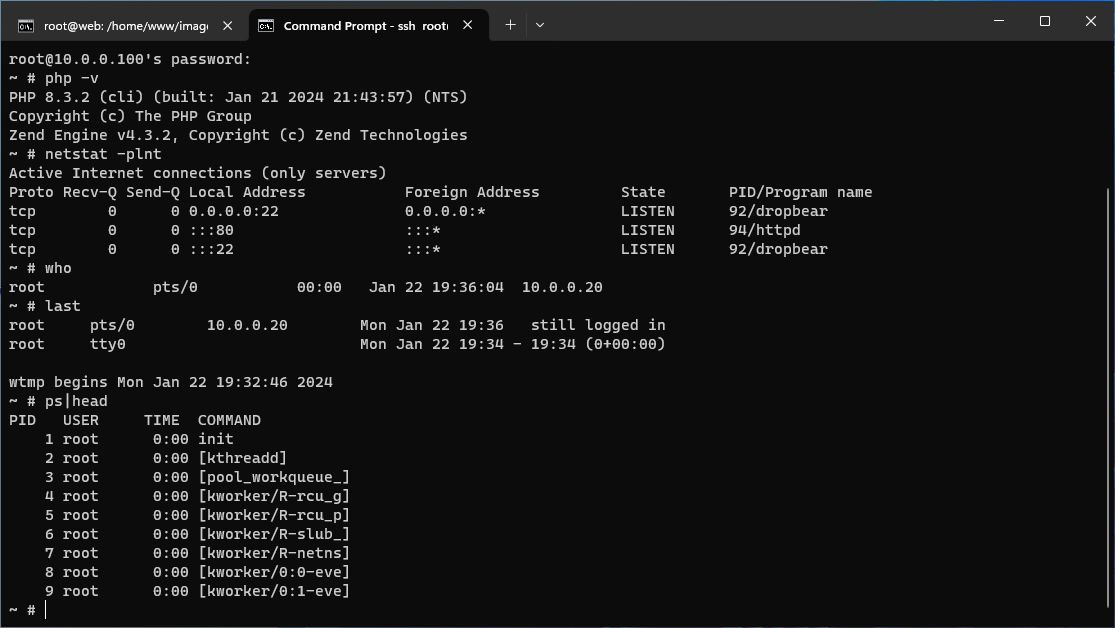
Możliwe jest połączenie poprzez SSH. Widać, iż usługi nasłuchują na adekwatnych portach, a polecenie php jest wykonywane.
Serwer httpd obsługuje skrypty PHP.
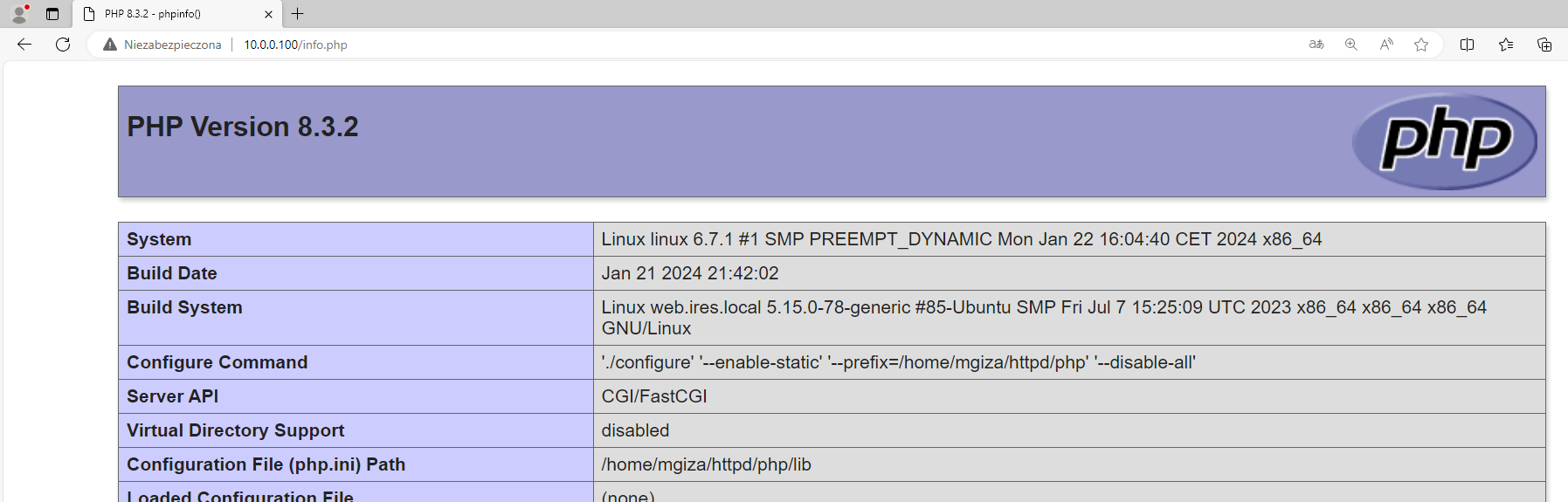
Nie ma trudności z zamontowaniem partycji LVM (z systemem plików ext4) po uruchomieniu ISO na innej maszynie.
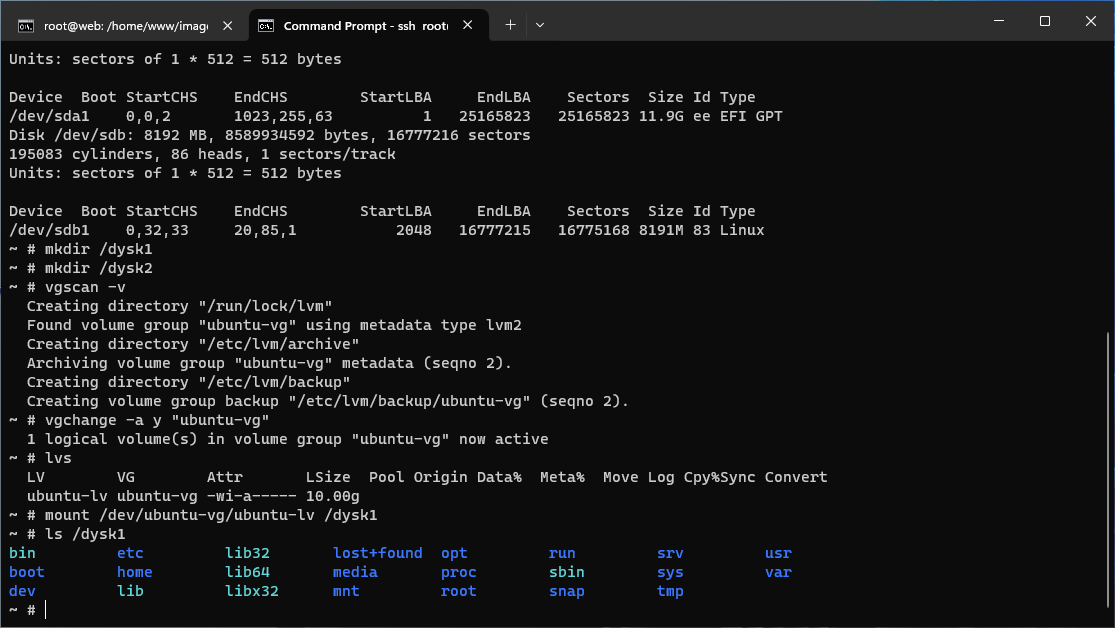
Podobnie z systemem NTFS na maszynie z Windows Server.
Tworzenie nośnika z systemem
Przygotowany przez nas system Live CD funkcjonuje w zamierzony sposób. Posiada jednak pewną wadę — wszystkie wprowadzone w nim zmiany (dodanie użytkownika, utworzenie plików, itd.) bytują wyłącznie w pamięci operacyjnej. Dopóki nie zapiszemy ich na nośniku, to po prostu zostaną zachowane do czasu wyłączenia (polecenie poweroff) czy restartu.
Rozwiązaniem jest utworzenie na dysku partycji z systemem oraz dodanie standardowego w środowiskach Linux boot manager’a GRUB. Sugeruję adekwatnie utworzyć dwie partycje dla katalogu głównego / i osobnego dla /boot, w którym zapiszemy initrd.img oraz kernel. Użyłem dysku o pojemności 1 GB (wystarczającej dla tak małego systemu), na którym utworzyłem właśnie dwie partycje po 512 MB. Pierwsza partycja /boot ma oczywiście ustawioną boot flag.
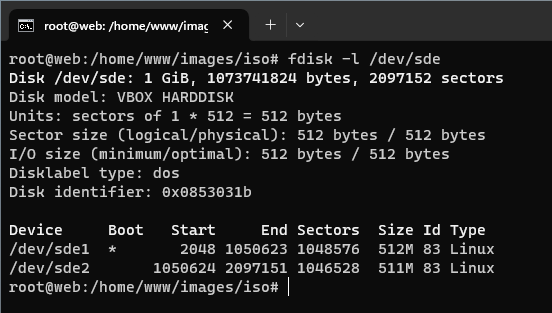
W pierwszej kolejności do wybranego katalogu montujemy partycję główną (tutaj /dev/sde2), a dalej tworzymy na niej katalog boot, do którego montujemy pierwszą partycję. Kopiujemy katalog z naszym systemem na dodaną partycję główną. Generujemy też od razu plik etc/fstab:
Musimy utworzyć plik initrd.img zawierający kolejny skrypt init, który po załadowaniu przez GRUB zamontuje dysk z systemem operacyjnym do tymczasowego katalogu, a następnie wykona (skądinąd bardzo ciekawe) polecenie switch_root uruchamiając napisany wcześniej skrypt init. Myślę, iż w tym celu można wykorzystać istniejący katalog z systemem (którego zawartość skopiowaliśmy na /dev/sde2 i nie jej modyfikujemy w żaden sposób), bo w praktyce zmieniamy tylko jeden plik — init. Jego zawartość może ograniczyć się do tych kilku linii:
Budujemy initrd.img:
Pozostało nam dostosowanie katalogu boot. Kopiujemy do niego pliki powstałe w procesie kompilacji kernela, czyli vmlinuz, System.map, .config oraz initrd.img. Tworzymy dodatkowo podkatalog grub wraz z plikiem konfiguracyjnym grub.cfg:
W GRUB menu (widocznym przez 5 sekund, chyba iż użytkownik naciśnie Enter) zobaczymy wpis BusyBox Linux. Zostanie załadowany initrd.img, który wykona opisaną wyżej procedurę. /boot to osobna partycja, stąd konieczność podania ścieżek względnych. Na koniec uruchamiamy grub-install:
Podłączyłem dysk do innej maszyny i, jak widać, wszystkie etapy przebiegają zgodnie z założeniami.
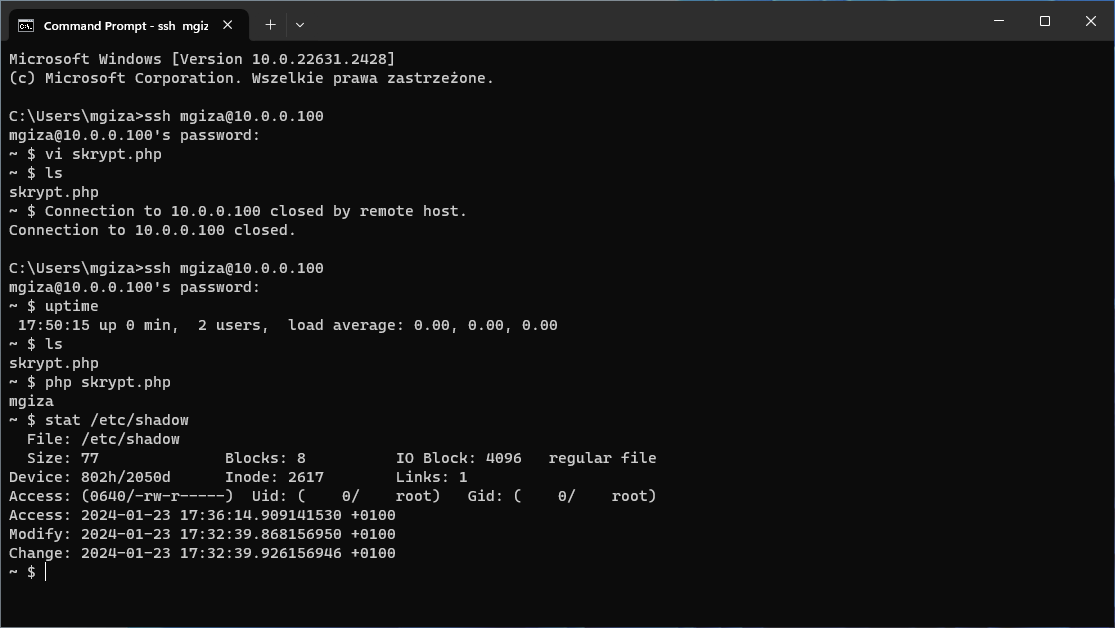
Zmieniłem hasło użytkownika root i dodałem drugiego użytkownika. Z jego poziomu utworzyłem plik skrypt.php wyświetlającego nazwę użytkownika, który go wykonał.
Dane są poprawnie zapisywane na dysku i zostają zachowane podczas restartów.
VirtualBox posiada opcję nagrywania ekranu. Uznałem, iż nagranie startu maszyny będzie odpowiednim dodatkiem do tego tekstu.
Podsumowanie
Mam nadzieję, iż opis przygotowania własnego minimalnego systemu operacyjnego był interesującą lekturą. Utworzony system może stanowić bazę do dalszych modyfikacji i dodawania kolejnych funkcji.