Emotet jest aktualnie jedną z najbardziej medialnych rodzin złośliwego oprogramowania. Dzięki swojej modularnej architekturze może bardzo łatwo adaptować się do nowych warunków bez modyfikacji głównego komponentu.
Pierwsze wersje Emoteta zostały zaobserwowane w roku 2014. W tamtych czasach był używany jako trojan bankowy – w tej chwili jako spammer i dropper innych rodzin złośliwego oprogramowania.
Ostatnio autorzy rodziny zdecydowali się na zmianę protokołu komunikacji i technik obfuskacji kodu. Może mieć to związek z niedawno opublikowanymi narzędziami pozwalającymi badaczom na łatwe pobieranie próbek z serwerów C21 oraz detekcję maszyn zainfekowanych Emotetem2.
W tym artykule przyjrzymy się najciekawszym funkcjom Emoteta oraz przedstawimy niektóre ostatnio wprowadzone zmiany.
Analizowana próbka: 500221e174762c63829c2ea9718ca44f
Odpakowane binarium: e8143ef2821741cff199eeda513225d7
Spis treści
- Techniki utrudniające analizę
- Ekstrakcja statycznej konfiguracji
- Komunikacja
- Podsumowanie
Techniki utrudniające analizę
Zaciemnienie przepływu kodu
W celu utrudnienia życia analitykom badającym oprogramowanie, autorzy skorzystali z obfuskacji kodu. Każda funkcja została podzielona na bloki instrukcji, które następnie zostały umieszczone w strukturze przypominającej maszynę stanów.
Odtworzenie oryginalnej struktury kodu jest możliwe, ale nietrywialne. Analiza kodu w tej postaci jest trochę utrudniona, ale na szczęście przez cały czas możliwa.
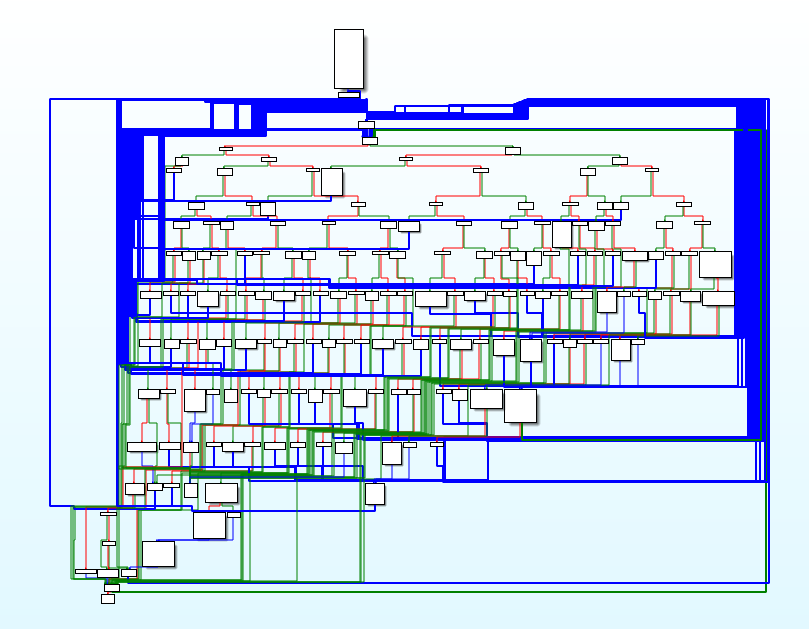
Graf instrukcji zobfuskowanej głównej funkcji
Zaszyfrowane łańcuchy znaków
Wszystkie użyte ciągi znaków są zaszyfrowane, tak jak miało to miejsce w poprzednich wersjach. Jednak w obecnej wersji klucz do deszyfrowania dzięki operacji xor nie jest przekazywany jako argument funkcji, tylko znajduje się przed zaszyfrowanymi danymi.
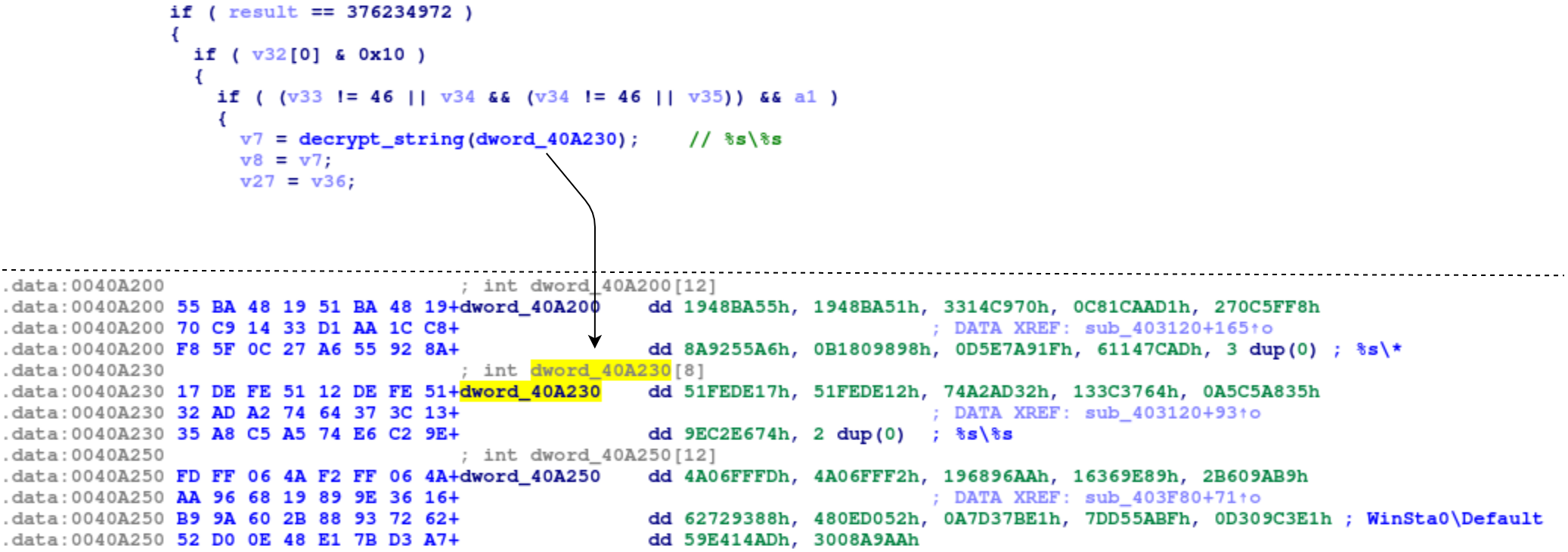
Przykład zaszyfrowanych ciągów znaków

Struktura zaszyfrowanych tekstów
Deszyfrowanie może być zrealizowane dzięki krótkiego skryptu w języku Python.
Kod służący do odszyfrowania zaszyfrowanych tekstów
WinAPI
Kolejną metodą utrudniania życia analitykom jest ukrywanie wywołań funkcji API Windowsa. Zastępuje się je wywołaniami autorskiej funkcji szukającej danego API w załadowanych bibliotekach programu.
Emotet wywołuje funkcji API dzięki funkcji szukającej hashy nazw funkcji. Nie jest to nic nowego – jednak w przeciwieństwie do poprzednich wersji, najnowsza wersja dokonuje wyszukania dopiero w momencie zamiaru wywołania danej funkcji, a nie na początku wykonywania programu.

Użycie funkcji wyszukującej danego API
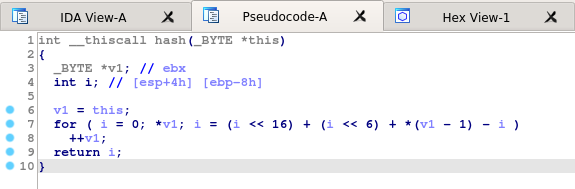
Funkcja licząca hasz dla danej nazwy funkcji
To utrudnienie jest równie proste do obejścia. Trzeba jedynie zaimplementować funkcję haszującą i porównać wyniki wykonania dla standardowych bibliotek ze stałymi zawartymi w kodzie.
Ważnym punktem jest oznaczenie typu stałej w funkcji find_api na typ nowo stworzonej wartości enum. To pozwoli dekompilatorowi na automatyczne wstawienie nazw API w wywołaniach funkcji wyszukującej.
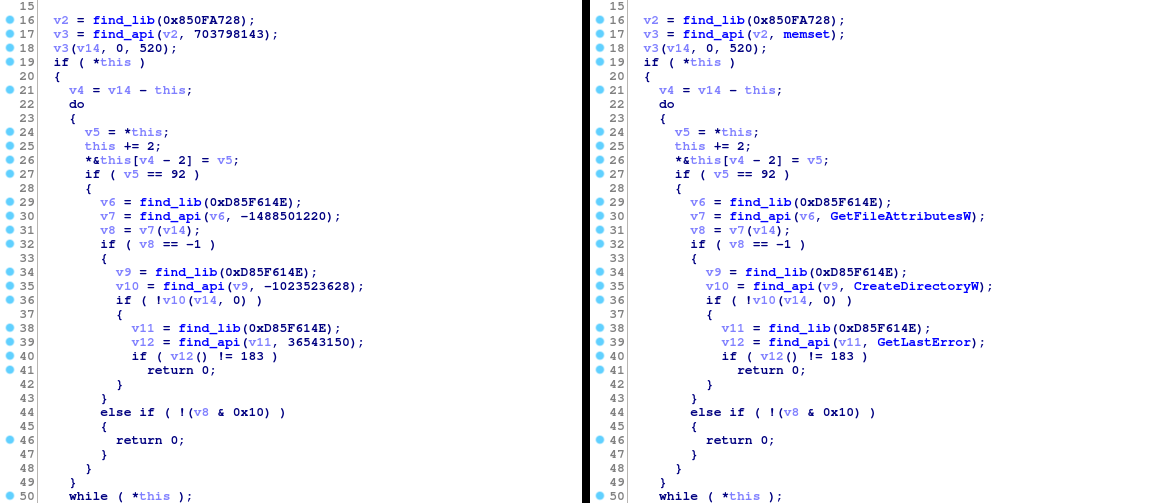
Usuwanie poprzednich wersji oprogramowania
Podczas analizy zdeszyfrowanych ciągów znaków, natrafiono na listę słów obecnych w poprzednich wersjach. Była ona używana do generowania ścieżek systemowych, w których następnie zapisywany był główny moduł Emoteta. Wydawało się to dziwne, ponieważ metoda ta została zastąpiona kompletnie losowym generatorem ścieżek.
Po bliższej inspekcji i potwierdzeniu przez użytkownika @JRoosen3, okazało się, iż lista słów jest używana do usunięcia binariów pozostawionych przez poprzednie wersje Emoteta.

Część funkcji odpowiedzialnej za usuwanie starych wersji Emoteta
Ekstrakcja konfiguracji
Klucz publiczny RSA
Klucz publiczny RSA jest szyfrowany tak samo jak łańcuchy znaków. Klucz jest użyty do szyfrowania kluczy AES używanych podczas połączenia z serwerem C2. Dzięki temu choćby podsłuchanie całości komunikacji między zainfekowaną maszyną i serwerem, nie daje możliwości odszyfrowania pakietów.
Do deszyfracji klucza można zatem użyć tego samego algorytmu co przy tekstach:
W wyniki otrzymujemy klucz zakodowany w formacie DER, który może zostać przetworzony przy pomocy kolejnego skryptu:
Wynikowy klucz publiczny w formacie PEM
Lista serwerów C2
Metoda dekodowania serwerów C2 nie zmieniła się względem poprzednich wersji. Są one przez cały czas zapisane jako 8-bajtowe bloki, zawierające spakowane adres IP oraz port.
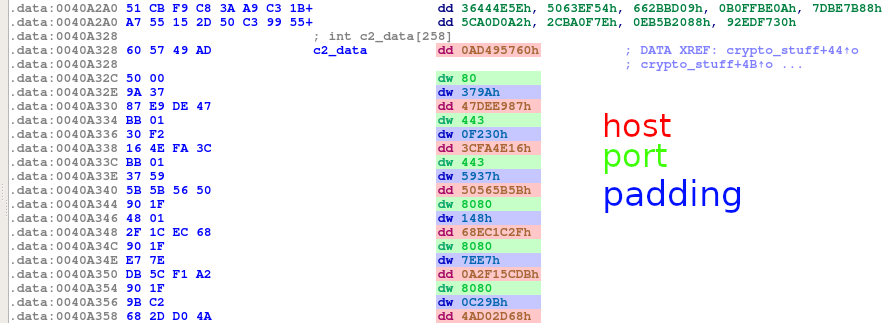
Komunikacja
Generowanie ścieżek URL
Generowanie ścieżek dzięki konkatenacji losowych słów z listy zostało porzucone na korzyść całkowicie losowych ciągów znaków alfanumerycznych.
Każda ścieżka składa się z losowej liczby znaków oddzielonymi znakiem /.

Nowy algorytm użyty do generowania losowych ścieżek URL
Co więcej, zamiast prostego umieszczania pakietu w ciele zapytania HTTP, jest on teraz załączany jako plik.
Metoda generowania losowych nazw załączników oraz plików jest dosyć podobna do algorytmu użytego do generowania ścieżek URL.

Część funkcji odpowiedzialnej za zakodowanie danych jako załącznik

Przykładowe zapytanie przedstawione w programie Wireshark
Struktura zapytań
Sposób wykonywania zapytań do serwera C2, to część kodu, w której wprowadzono najwięcej zmian. Struktura pakowania pakietów „Protobuf” została zastąpiona autorskim algorytmem.
Szyfrowanie pakietów
Dokładnie jak w poprzednich wersjach, wszystkie pakiety są szyfrowane dzięki szyfru AES w trybie CBC, z IV ustawionym na wartości null. Klucz AES jest najpierw generowany dzięki funkcji CryptGenKey, a następnie szyfrowany dzięki klucza publicznego RSA i dołączony na koniec każdego pakietu.
Dodatkowo, do weryfikacji integralności pakietów, do pakietu dołączany jest również hasz SHA-1 zawartości pakietu.

Struktura zaszyfrowanych pakietów
Struktura pakietu
Pakiety z rozkazami są dodatkowo kompresowane i opakowane w prostej strukturze.
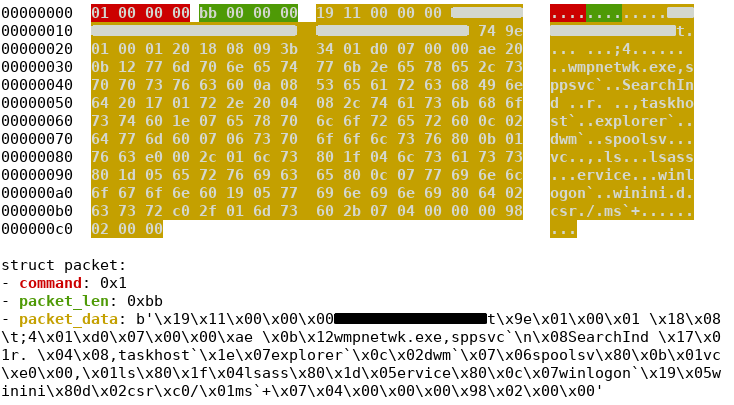
Struktura pakietu przedstawiona dzięki narzędzia dissect.cstruct
Kompresja pakietów
Kolejna zaobserwowana zmiana, to algorytm użyty do kompresji i dekompresji przychodzących i wychodzących pakietów.
Historycznie w tym celu używany był algorytm zlib, jednak przy okazji ostatnich aktualizacji zostało to zmienione. Ciężko stwierdzić dokładną nazwę nowego algorytmu, ale funkcja evolution_unpack4 z projektu quickbms poprawnie dekompresuje dane otrzymane z serwerów C2.

Pseudokod nowego algorytmu kompresującego
Postanowiono zaimplementować algorytm dekompresji w języku Python, wyniki eksperymentu podano poniżej.
Struktura pakietu rejestracyjnego
Jak zostało wspomniane wcześniej, protokół protobuf został porzucony na rzecz własnego rozwiązania autora.
Jednym z zaobserwowanych komend pakietów jest pakiet rejestrujący maszynę w botnecie.
Struktura tego pakietu może być prosto przedstawiona jako struktura w języku C:
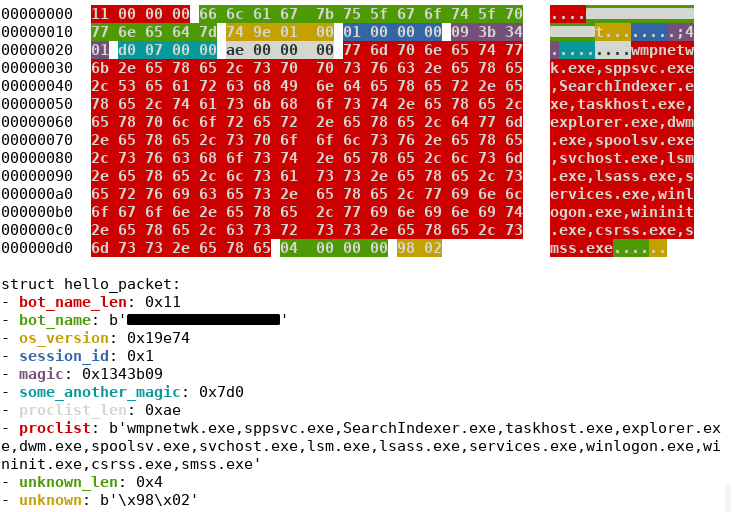
Struktura pakietu rejestracyjnego przedstawiona dzięki narzędzia dissect.cstruct
Podsumowanie
Celem tego artykułu było przybliżenie badaczom wprowadzonych zmian w Emotecie.
Emotet po raz kolejny okazał się zaawansowanym zagrożeniem, potrafiącym gwałtownie dostosować się do zmieniających się warunków.
Analiza jedynie pobieżnie prezentuje funkcje Emoteta i powinna być traktowana jako wprowadzenie, a nie pełny opis jego możliwości. Zachęcamy czytelników do skorzystania z zawartych informacji i dalszego przeciwdziałania operacjom botnetu.
Dalsze informacje o działaniach Emoteta
- https://twitter.com/cryptolaemus1
- https://github.com/d00rt/emotet_research
- https://blog.malwarebytes.com/botnets/2019/09/emotet-is-back-botnet-springs-back-to-life-with-new-spam-campaign/
- https://www.cert.pl/en/news/single/analysis-of-emotet-v4/
Odniesienia
1: https://d00rt.github.io/emotet_network_protocol/
2: https://github.com/JPCERTCC/EmoCheck
3: https://twitter.com/JRoosen/status/1225188513584467968
4: https://github.com/mistydemeo/quickbms/blob/master/unz.c#L5501








![Passus – czy AI to szansa czy ryzyko? [Analiza] (Analizy i komentarze)](https://www.sii.org.pl/static/img/018944/passus-1360.jpg)








