Źródło: www.freepik.com
Źródło: www.freepik.comArtykuł jest częścią serii opracowań zagadnień obowiązujących na egzaminie CompTIA Security+ SY0-701. Zapisz się na newsletter, jeżeli nie chcesz przegapić kolejnych publikacji.
Wykaz skrótów używanych w artykule:
- ZT = Zero Trust.
- PEP = Policy Enforcement Point.
- PDP = Policy Decision Point.
- PA = Policy Administrator.
- PE = Policy Engine.
Model bezpieczeństwa zero trust (w wolnym tłumaczeniu: nie ufaj nikomu i niczemu) opiera na zasadzie nieustannej kontroli dostępu do chronionych zasobów, również w przypadku użytkowników i urządzeń, którzy już nawiązali połączenie z siecią wewnętrzną.
Nawet dziś, w wielu firmach, można spotkać się z założeniem, iż jeżeli użytkownik przeszedł pomyślnie proces weryfikacji (podał prawidłowe dane uwierzytelniające) i uzyskał dostęp do sieci organizacji, to znaczy, iż na pewno jest tym, za kogo się podaje. Dalsza weryfikacja poczynań takiego użytkownika wydaje się być zbędna – w końcu przeszedł proces uwierzytelnienia, kiedy łączył się z siecią.
Tradycyjne modele bezpieczeństwa, takie jak castle-and-moat (w dosłownym tłumaczeniu: zamek z fosą), polegające na solidnej ochronie dostępu samej do sieci, ale pełnym zaufaniu wszystkiemu co już jest w środku, rzeczywiście mogły być wystarczające w czasach, gdy sieć oraz niemalże wszystkie zasoby organizacji (także pracownicy) znajdowały się na miejscu (on-premise). Jednakże w dobie rozproszonych usług chmurowych, wszechobecnej pracy zdalnej, a także rozbudowanych ataków, często opierających się na wyrafinowanych metodach socjotechnicznych, takie podejście przestaje być skuteczne.
Można oczywiście zastosować dodatkowe strategie obronne, takie jak defence-in-depth (inna nazwa: layered security), gdzie, jak sama nazwa wskazuje, wdraża się techniki zabezpieczające na różnych warstwach infrastruktury IT organizacji. Na przykład: warstwa sieciowa jest chronione przez firewalle oraz systemy IDS/IPS; cały ruch w sieci wewnętrznej jest szyfrowany; aplikacje wytwarza się zgodnie z standardami SSDLC (Secure Software Development Lifecycle); wszystkie urządzenia pracowników są pod ochroną systemu typu anti-malware itd.
Oba wymienione wyżej podejścia, choćby jeżeli są stosowane nierozłącznie, mają jedną słabość: jeżeli intruzowi uda się w jakiś sposób pokonać wszystkie zabezpieczenia i uzyskać dostęp do chronionych zasobów, jest duża szansa, iż tak już zostanie. Od tego momentu atakujący jest traktowany jako byt zaufany i może kontynuować swoją szkodliwą działalność, jeżeli tylko uda mu się dobrze ukryć.
Załóżmy, iż pracujący zdalnie członek organizacji, z dosyć dużymi uprawnieniami, codziennie łączy się z firmą za pośrednictwem sieci VPN. Kiedy już się uwierzytelni i nawiąże połączenie, posiada szeroki dostęp do różnych istotnych zasobów organizacji. Teraz wystarczy jedynie wyciągnąć dane uwierzytelniające od takiego pracownika i się pod niego podszyć bądź nakłonić go do zainstalowania złośliwego systemu na sprzęcie firmowym. Od tej chwili intruz ma praktycznie takie same możliwości, co zaatakowany pracownik.
Paradygmat zero trust (ZT) wydaje się być remedium na wspomniane bolączki, ponieważ zakłada równe traktowanie podmiotów (użytkownicy, systemy, usługi, aplikacje, którzy próbują uzyskać dostęp) działających wewnątrz sieci oraz podmiotów zewnętrznych.
Innymi słowy, nawet jeżeli użytkownikowi udało się połączyć z siecią organizacji, to każde jego żądanie dostępu (ang. access request) do chronionego zasobu będzie weryfikowane tak samo skrupulatnie, jak w przypadku kogoś spoza sieci. Sprawdzanie każdego żądania często nazywamy ciągłą weryfikacją (ang. continuous validation) bądź ciągłym uwierzytelnianiem (ang. continuous authentication) i choćby jeżeli podmiot otrzyma dostęp do żądanego zasobu, to tylko na ograniczony czas trwania sesji.
Sam proces weryfikacji w podejściu zero trust jest dosyć złożony. Oprócz danych uwierzytelniających (ang. credentials) brane są pod uwagę dodatkowe czynniki, takie jak: źródłowy adres IP podmiotu; czy system operacyjny, z którego przychodzi żądanie, jest odpowiednio zabezpieczony; w jakim czasie nawiązano połączenie lub z jakiego miejsca itd. jeżeli któryś z weryfikowanych atrybutów będzie wyglądał podejrzanie (np. żądanie dostępu przyjdzie w środku nocy z egzotycznego kraju), to użytkownik bądź aplikacja mogą zostać poddani dodatkowej kontroli, a w przypadku bardziej restrykcyjnej polityki bezpieczeństwa, dostęp zostanie całkowicie zablokowany.
Kluczowe zasady podejścia zero trust:
- Bezustanny monitoring (ang. continuous monitoring) i ciągła weryfikacja (ang. continuous validation) – zakładamy, iż atak może przyjść zarówno z zewnątrz, jak i z wewnątrz organizacji. Dlatego każdy użytkownik czy urządzenie są stale i ściśle kontrolowani. Oprócz danych dostępowych sprawdza się dodatkowe atrybuty podmiotu. Weryfikowany jest każdy request, a połączenia, które już uzyskały dostęp, są co jakiś czas restartowane, żeby wymusić ponowną kontrolę.
- Least privilege – podmiot ma dostęp jedynie do tych zasobów, których rzeczywiście potrzebuje i nic ponadto. choćby jeżeli intruzowi uda się przejąć konto zaufanego użytkownika, ewentualne szkody będą ograniczone do możliwości zaatakowanego konta.
- Kontrola dostępu urządzeń (ang. device access control) – polega na dokładnym sprawdzaniu, ile różnych urządzeń próbuje połączyć się z siecią, czy są one odpowiednio zabezpieczone oraz czy nie zostały wcześniej skompromitowane. Należy pamiętać, iż tak szczegółowa kontrola nie zawsze jest możliwa w przypadku urządzeń typu BYOD (Bring Your Own Device), które nie są własnością organizacji.
- Zapobieganie lateral movements (spotkałem się z tłumaczeniem ruch boczny, ale bardzo mnie to kłuje, więc zostańmy przy oryginalnej wersji) – polega na uniemożliwieniu dalszych działań intruzowi, który zdołał przekroczyć granicę sieci (ang. network perimeter). Jest to bezpośrednio związane z zasadą least privilege i obejmuje również takie działania jak segmentacja sieci (ang. network segmentation), czyli jej podział na mniejsze, odizolowane obszary, oraz mikrosegmentacja (ang. microsegmentation), czyli bardziej precyzyjna forma podziału – na poziomie pojedynczych serwerów, aplikacji, a choćby procesów. Mówiąc krótko: intruz zostanie ograniczony do jednej strefy.
- MFA (Multi-Factor Authentication) – stosowanie uwierzytelniania wieloskładnikowego powinno być już w zasadzie standardem i to nie tylko w podejściu zero trust. Należy również mieć na uwadze fakt, iż hardware’owe klucze bądź kody generowane bezpośrednio na urządzeniu są przeważnie bezpieczniejsze niż te generowane przez oprogramowanie działające na serwerze i wysyłane np. SMS-em.
- Threat Intelligence – aktywna obserwacja przeróżnych baz wiedzy pod kątem potencjalnych zagrożeń i dostosowywanie polityk bezpieczeństwa do bieżących potrzeb. Pamiętajmy, iż niemalże codziennie pojawiają się nowe niebezpieczeństwa, a te już znane często ewoluują.
- Assume breach – to założenie, iż prędzej czy później nastąpi udany atak, o ile już się nie wydarzył.
Wybrane korzyści modelu zero trust:
- Redukcja liczby potencjalnych zagrożeń, a także minimalizowanie potencjalnych szkód w razie udanego ataku (zarówno zewnętrznego, jak i wewnętrznego).
- Sprawdzanie każdego żądania do chronionych zasobów ogranicza dostęp dla urządzań, które mogą być podatne na ataki. Jest to szczególnie istotne dla urządzeń IoT (Internet of Things), gdzie aktualizacje systemu pojawiają się znacznie rzadziej niż w przypadku standardowych stacji roboczych (laptopy, komputery PC) i urządzeń mobilnych (smartfony, tablety).
- Zwiększona widoczność i kontrola nad tym, co dzieje się w sieciach organizacji.
- Wdrożenie architektury zero trust (ZTA = Zero Trust Architecture) bardzo często pomaga osiągnąć zgodność (ang. compliance) z wybranymi standardami bezpieczeństwa, takimi jak HIPAA (Health Insurance Portability and Accountability Act), GDPR (General Data Protection Regulation) czy PCI DSS (Payment Card Industry Data Security Standard). Warto zaznaczyć, iż sam model ZT nie jest wymagany przez wspomniane standardy branżowe, ale jego implementacja narzuca pewne mechanizmy, które mogą być konieczne.
Wdrożenie architektury zero trust to złożony i długotrwały proces, który stawia przed zespołami IT wiele wyzwań. kilka organizacji może sobie pozwolić na stworzenie odpowiednio dostosowanej infrastruktury od podstaw, dlatego jeżeli zdecydujemy się na taki kierunek, warto dokładnie zaplanować poszczególne etapy migracji i rozłożyć je w czasie. Zaleca się, aby pierwszym krokiem było wybranie najmniej krytycznego (z punktu widzenia działania biznesu) obszaru infrastruktury IT i przetestowanie na nim nowego podejścia, zanim przejdziemy do kolejnych działań. Dzięki temu zdobędziemy niezbędne doświadczenie i zidentyfikujemy problemy, których nie byliśmy w stanie przewidzieć na etapie planowania.
Pamiętajmy również, iż nazwa zerowe zaufanie to w rzeczywistości hiperbola. Należy znaleźć złoty środek pomiędzy absolutnym bezpieczeństwem a funkcjonalnością i wygodą. Kiedy użytkownicy naszych systemów napotykają zbyt restrykcyjne reguły bezpieczeństwa, które znacząco utrudniają im pracę, zaczynają intensywnie kombinować, jak je obejść. choćby jeżeli pracownicy organizacji będą musieli częściowo zrezygnować z pewnych udogodnień, należy ich odpowiednio uświadomić, dlaczego jest to istotne i co dzięki temu zyskujemy.
Bardzo prosty i interesujący przykład implementacji modelu zero trust został przedstawiony na nagraniu: Zero Trust Explained | Real World Example. Pokazano tutaj, na przykładzie rozwiązania Twingate, w jaki sposób można wykorzystać technologię ZTNA (Zero Trust Network Access) do szczegółowej kontroli dostępu do urządzenia NAS (Network Attached Storage), zainstalowanego w sieci prywatnej.
Jeśli chcemy wdrażać poważniejsze systemy, powinniśmy zrozumieć w jaki sposób urządzenia sieciowe odpowiedzialne za bezpieczeństwo (fizyczne i wirtualne) dzielą się na warstwę sterowania (ang. control plane) oraz warstwę danych (ang. data plane lub forwarding plane). Szczegóły podziału omówimy poniżej, ale żeby mieć ogólny pogląd, wyobraźmy sobie samochody jeżdżące po miejskich drogach. Poruszające się pojazdy stanowią warstwę danych (jak pakiety danych przemierzające sieć), a znaki i sygnalizacje świetlne są częścią warstwy sterowania (podobnie jak routery, switche i firewalle sterujące ruchem sieciowym).
Przyjrzyjmy się ogólnemu diagramowi reprezentującemu ideę architektury zero trust (uwaga: schemat pokazuje jedynie logiczny podział elementów architektury ZT i jej fizyczna realizacja może się różnić):
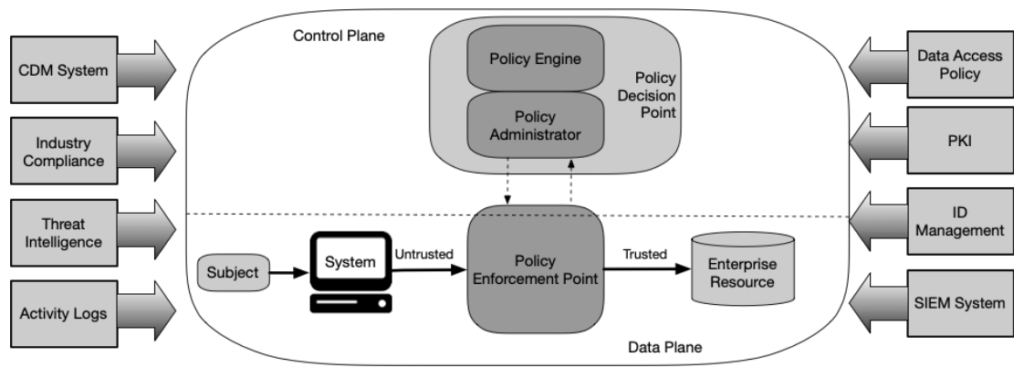 Źródło: NIST SP-800-207 – Zero Trust Architecture. Wersję polską można ściągnąć tutaj: NSC 800-207 (jest trochę starsza i w mojej ocenie niezbyt trafnie przetłumaczona).
Źródło: NIST SP-800-207 – Zero Trust Architecture. Wersję polską można ściągnąć tutaj: NSC 800-207 (jest trochę starsza i w mojej ocenie niezbyt trafnie przetłumaczona).Podmiot (ang. subject) próbuje uzyskać dostęp do zasobu organizacji (ang. enterprise resource) z niezaufanego systemu. Każde żądanie dostępu przechodzi przez punkt kontrolny, zwany Policy Enforcement Point (PEP), którego zadaniem jest przepuszczanie wyłączne w pełni uwierzytelnionych i autoryzowanych zapytań. PEP nie podejmuje jednak decyzji samodzielnie – za to odpowiada Policy Decision Point (PDP), czyli komponent, w którym następuje pełna weryfikacja i zapada werdykt, czy dany podmiot ma prawo uzyskać dostęp do chronionego zasobu. Proces decyzyjny może uwzględniać wiele czynników, co zostało pokazane na powyższym schemacie, ale wrócimy do tego w dalszej części opracowania. Ostatecznie, PEP otrzymuje odpowiedź z PDP i na jej podstawie ustanawia połączenie podmiotu z docelowym zasobem lub je odrzuca.
Control Plane
Warstwa sterowania (ang. control plane) jest częścią sieci kontrolującą to, w jaki sposób dane są przez tę sieć przesyłane i przekazywane. Zaliczamy do niej m.in. tabele routingu, zawierające informacje o trasie do adresu docelowego; polityki dostępu; reguły zdefiniowane na firewallach; tłumaczenia adresów NAT (Network Address Translation). Mówiąc krótko: są to wszystkie elementy, które odpowiadają za sterowanie ruchem w sieci.
W architekturze zero trust w skład warstwy sterowania wchodzą 4 komponenty, opisane poniżej.
Adaptive identity
Adaptive identity (inna nazwa: adaptive authentication) można przetłumaczyć dosłownie jako adaptacyjna tożsamość. Koncept ten zakłada weryfikację tożsamości, która nie opiera się jedynie na danych uwierzytelniających, przekazanych przez użytkownika, ale bierze pod uwagę także dane kontekstowe i inne atrybuty tego użytkownika. Mogą to być takie informacje jak:
- Źródłowy adres IP podmiotu próbującego uzyskać dostęp do zasobów sieciowych.
- Miejsce, z którego łączy się użytkownik (geolokalizacja).
- Czas połączenia (np. czy ktoś próbuje łączyć się poza standardowymi godzinami pracy).
- Dane o urządzeniu, z którego łączy się użytkownik (np. czy posiada aktualną wersję oprogramowania; czy jest prawidłowo skonfigurowane; czy zainstalowano na nim oprogramowanie typu anti-malware).
- Relacja z organizacją: czy użytkownik jest pełnoetatowym pracownikiem, podwykonawcą czy kontrahentem?
- Wszystkie pozostałe wskazówki, które pomogą w identyfikacji podmiotu (np. wzorce zachowań).
Podejście adaptacyjne zakłada dostosowanie środków bezpieczeństwa do zaistniałej sytuacji, ocenianej na podstawie otrzymanych danych uwierzytelniających oraz zgromadzonych informacji kontekstowych. Oznacza to, iż system (a dokładnie PEP) może zażądać od użytkownika wykonania dodatkowych kroków celem uwierzytelnienia, gdy nastąpi jakaś anomalia bądź całkowicie odrzucić żądanie, jeżeli polityki nie zezwalają na dodatkową weryfikację.
Na przykład: o ile pracownik firmy znajdującej się w USA nawiązał połączenie z adresu IP zlokalizowanego w Chinach (a wczoraj wieczorem widziano go w biurze, w Nowym Jorku), to sytuację można uznać za mocno podejrzaną. W tym momencie, zgodnie z podejściem ZT, takie połączenie powinno zostać całkowicie zablokowane bądź należy zażądać od użytkownika dodatkowego uwierzytelnienia, w zależności od skonfigurowanej polityki bezpieczeństwa.
Threat scope reduction
Redukcja obszaru podatnego na zagrożenia (ang. threat scope reduction) to nic innego jak ograniczenie dostępu użytkownika (człowieka bądź systemu) tylko do tych zasobów, które są niezbędne do realizacji jego zadań. Dzięki temu ograniczamy pole rażenia (ang. blast radius), jeżeli okaże się, iż konto zostało skompromitowane i przejęte przez intruza.
Redukcja zagrożeń bazuje mi.in. na zasadzie least privilege oraz na segmentacji opartej o tożsamość, tj. dostęp do wybranych obszarów sieci bądź zasobów jest przyznawany na podstawie atrybutów użytkownika (np. jego przynależności do działu, roli w organizacji itp.).
Policy-driven access control
Kontrola dostępu oparta o polityki bezpieczeństwa (ang. policy-driven access control) jest kluczowym konceptem podejścia ZT, który został już w dużym stopniu omówiony wcześniej. Dla przypomnienia, w tradycyjnym podejściu podmiot zostaje uwierzytelniony na podstawie danych uwierzytelniających bądź dodatkowych informacji wymuszonych przez MFA. Kontrola dostępu oparta o polityki pozwala na bardziej szczegółową weryfikację, z uwzględnieniem pełnego kontekstu żądania oraz atrybutów podmiotu.
Bardziej wyrafinowane rozwiązania nie polegają jedynie na sztywno zdefiniowanych regułach, ale podejmują decyzję o przyznaniu bądź zablokowaniu dostępu w oparciu o dane pochodzące z różnych źródeł (widocznych na powyższym diagramie):
- CDM (Continuous Diagnostics and Mitigation) System – system monitorujący stan zasobów organizacji, odpowiadający za aktualizację konfiguracji i oprogramowania. Jest w stanie dostarczyć informacje o bezpieczeństwie urządzeń żądających dostępu, zarówno tych należących do przedsiębiorstwa, jak i zewnętrznych, a także wyegzekwować odpowiednie polityki bezpieczeństwa.
- Industry Compliance – odpowiada za weryfikację i egzekwowanie polityk niezbędnych do zapewnienia zgodności z obowiązującymi przepisami, których musi przestrzegać organizacja.
- Threat intelligence – źródła informacji (wewnętrzne i zewnętrzne) o najnowszych zagrożeniach, takich jak techniki ataków, wykryte podatności, odmiany złośliwego oprogramowania.
- Activity Logs – logi zbierane z sieci oraz systemów organizacji.
- Data Access Policy – reguły definiujące polityki dostępu. Mogą być zdefiniowane na sztywno lub wygenerowane dynamicznie. Jest to punkt wyjściowy procesu autoryzacji dostępu do chronionych zasobów.
- PKI (Public Key Infrastructure) – system odpowiedzialny za generowanie oraz weryfikację elektronicznych certyfikatów bezpieczeństwa i ogólnie za zarządzanie rozwiązaniami opartymi o kryptografię, stosowanymi w organizacji.
- ID Management – system zarządzania tożsamością, odpowiedzialny za administrację kontami użytkowników/usług. Tutaj przechowywane są najważniejsze informacje dotyczące określonych kont, włączając w to role i uprawnienia.
- SIEM (Security Information and Event Management) System – system, który zbiera i agreguje wszystkie informacje oraz zdarzenia związane z bezpieczeństwem. Zgromadzone dane mogą być później prezentowane administratorom w formacie ułatwiającym dalszą analizę.
Policy Administrator
Policy Administrator (PA) to nie jest człowiek, jak może sugerować nazwa, ale komponent będący częścią Policy Decision Point (PDP), który odpowiada za przekazywanie do PEP decyzji, podjętej przez Policy Engine, o przyznaniu bądź zablokowaniu dostępu wybranemu podmiotowi.
Innymi słowy, jeżeli podmiot powinien uzyskać dostęp do żądanego zasobu, PA mówi o tym PEP, udostępniając jednocześnie niezbędne dane uwierzytelniające, tokeny dostępu bądź klucze sesji wymagane do nawiązania połączenia z zasobem. W innym przypadku (brak dostępu), nakazuje PEP zakończyć bieżącą sesję (połączenie).
Policy Engine
Policy Engine (PE) to drugi element PDP, który analizuje żądania przechodzące przez PEP pod kątem zdefiniowanych reguł, polityk bezpieczeństwa oraz wszystkich danych zebranych z innych komponentów całego systemu (np. SIEM, dzienniki zdarzeń) i podejmuje ostateczną decyzję o przyznaniu (ang. grant), odrzuceniu (ang. deny) bądź cofnięciu (ang. revoke) dostępu.
Decyzja o przyznaniu dostępu jest podejmowana przez odpowiednie algorytmy zaufania (ang. Trust Algorithms), które na wejściu przyjmują dane z wielu źródeł, opisanych krótko w paragrafie Policy-driven access control. Każda taka decyzja jest zapisana w adekwatnym dzienniku (log) oraz przekazana do PEP za pośrednictwem PA.
Data Plane
Data plane (warstwa danych), nazywana również forwarding plane, jest częścią infrastruktury sieciowej odpowiedzialną za przesyłanie i przetwarzanie danych. Zaliczamy do niej urządzenia przesyłające i przetwarzające dane sieciowe w czasie rzeczywistym, czyli m.in. switche, routery, firewalle.
Zwróćmy uwagę, iż granica między warstwą danych oraz warstwą sterowania jest abstrakcyjna i jedno urządzenie może należeć do obu płaszczyzn. Przykładowo: router sieciowy przekazuje pakiety do odpowiedniego miejsca docelowego (warstwa danych) i robi to na podstawie zapisanych u siebie tabel routingu (warstwa sterowania).
Implicit trust zones
Nawet w podejściu zero trust nie da się obejść bez pewnej dozy zaufania, jeżeli cały system ma być funkcjonalny. Kiedy podmiot próbujący uzyskać dostęp do chronionego zasobu, spełni wszystkie wymagania procesu uwierzytelnienia i autoryzacji (tj. zostanie przepuszczony przez PEP), trafia do strefy domyślnego zaufania (ang. implicit trust zone). Oznacza to, iż przez jakiś czas taki użytkownik, system, usługa bądź aplikacja są traktowani jako byty zaufane i mają dostęp do elementów znajdujących się w tej strefie (np. serwer bazodanowy).
Mówiąc krótko: implicit trust zone to obszar, gdzie wszystkie podmioty, które się w nim znajdują, otrzymały pewną dozę zaufania od ostatniego punktu kontrolnego PDP/PEP. Taki obszar sieci możemy sobie wyobrazić jako część lotniska, między punktem kontroli bezpieczeństwa (odpowiednik PDP/PEP), a bramkami strzegącymi wejścia do samolotu. Wszystkie osoby przebywające w tej strefie (pasażerowie, pracownicy lotniska, załoga) można traktować jako zaufane do pewnego stopnia.
Warto mieć na uwadze, iż sam zasób, z którym udało się połączyć, może wymagać dodatkowego uwierzytelnienia. Na przykładzie serwera baz danych: każda baza może mieć skonfigurowanego indywidualnego użytkownika, od którego wymaga się dodatkowo podania loginu i hasła.
Domyślne strefy zaufania powinny być możliwie jak najmniejsze, zgodnie z omówioną wcześniej zasadą threat scope reduction. Poza tym, każde przejście z jednej strefy zaufania do drugiej wymaga ponownej weryfikacji (dostęp do niektórych obszarów może być bardziej restrykcyjny niż w przypadku innych).
Subject/System
Terminy takie jak podmiot (ang. subject) oraz system już przewinęły się w tym tekście niejednokrotnie, więc teraz jedynie przypomnijmy sobie definicje:
- Subject – podmiot, który próbuje uzyskać dostęp do chronionego zasobu i jest weryfikowany przez PDP/PEP. Często jest to człowiek, który posługuje się wybranym kontem użytkownika, ale równie dobrze może to być oprogramowana maszyna. W tym przypadku podmiotem jest usługa bądź aplikacja, która łączy się z siecią wykorzystując konto użytkownika automatycznego, nazywane zwykle kontem usługi (ang. service account).
- System – urządzenie z systemem operacyjnym, które jest używane przez podmiot do nawiązania połączenia i uzyskania dostępu do chronionych zasobów organizacji.
Policy Enforcement Point
Policy Enforcement Point (PEP) jest to punkt w sieci, przez który przechodzą wszystkie żądania dostępu od podmiotów i w zależności od wyników weryfikacji, dostęp jest przyznawany bądź blokowany.
Jest to rodzaj strażnika bramy (ang. gatekeeper), który przepuszcza tylko uprawnionych interesantów. Sam jednak nie podejmuje decyzji, ponieważ dokładne wskazówki otrzymuje od swojego bezpośredniego dowódcy, czyli wspomnianego wcześniej komponentu Policy Decision Point (Policy Administrator + Policy Engine). PDP z kolei wydaje werdykt na podstawie informacji o żądaniu otrzymanych z PEP, zestawionych z instrukcjami pochodzącymi z innych źródeł (np. zdefiniowane polityki dostępu).
Na wykresie PEP jest przedstawiony jako pojedynczy element, ale pamiętajmy, iż jest to jedynie abstrakcyjny koncept i funkcjonalność PEP może składać się z wielu rozproszonych elementów.

![Nowelizacja ustawy o cyberbezpieczeństwie uderzy w małe firmy? Nie spełnisz wymagań – stracisz kontrakt [PYTANIA DO EKSPERTA]](data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAIAAAACCAYAAABytg0kAAAAFElEQVQYV2N8+vTpfwYGBgZGGAMAUNMHXwvOkQUAAAAASUVORK5CYII=)