Na stronie ENISA ukazał się raport pt. Cybersecurity and privacy in AI – Medical imaging diagnosis, przedstawiający analizę obrazowania medycznego wykorzystującego sztuczną inteligencję w diagnostyce osteoporozy. Omawiany przykład pokazuje, iż sztuczna inteligencja może przynieść wiele korzyści dla rozwoju ochrony zdrowia, jak i innych sektorów gospodarki. Jak jednak zauważają twórcy raportu, należy zwrócić uwagę na zagrożenia dla bezpieczeństwa i prywatności wiążące się z wykorzystywaniem AI.
Cele raportu
- Szczegółowy opis scenariusza diagnostyki obrazowania medycznego, na przykładzie choroby kości – osteoporozy.
- Identyfikacja zagrożeń oraz określenie zaleceń w celu zachowania bezpieczeństwa i ochrony prywatności w stosowaniu opisywanego scenariusza.
- Wskazanie zaleceń w celu zachowania równowagi między wydajnością a zachowaniem bezpieczeństwa i ochroną prywatności.
Opis scenariusza diagnostyki obrazowania medycznego osteoporozy
Osteoporoza jest poważną chorobą kości prowadzącą do ich złamań choćby po niewielkim urazie. Rozpoznanie choroby odbywa się głównie dzięki badania obrazowania medycznego, np. tomografii komputerowej lub rezonansu magnetycznego. Niestety ze względu na duże zapotrzebowanie oraz niewystarczającą ilość lekarzy radiologów, czas oczekiwania na analizę zdjęcia rentgenowskiego, a tym samym rozpoznania lub wykluczenia osteoporozy, jest bardzo długi.
Wprowadzenie modelu uczenia maszynowego (modelu ML) mogłoby wspomóc i przyspieszyć pracę radiologów. Poniższa grafika przedstawia proces wykorzystania modelu w diagnostyce osteoporozy.
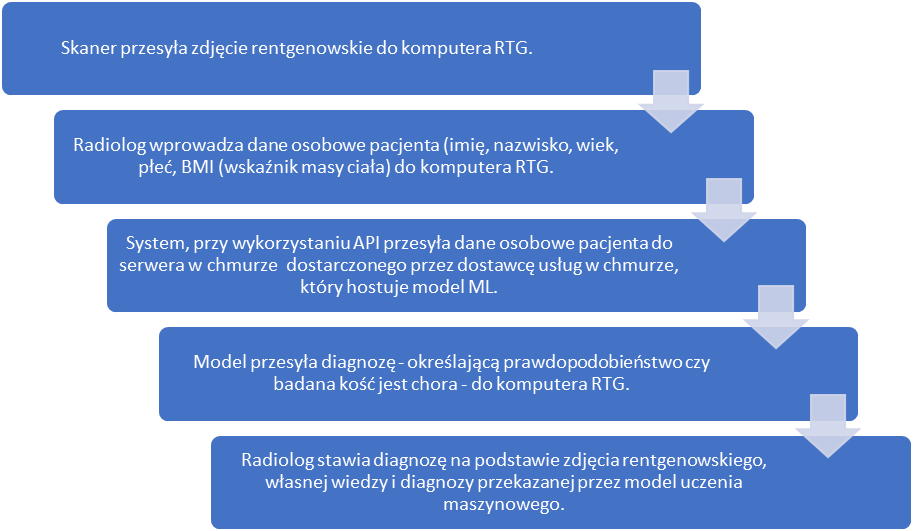
W celu stworzenia modelu ML, który mógłby zostać wykorzystany w pracy radiologów zbudowano bazę danych zawierającą:
- Zdjęcia rentgenowskie i dane medyczne byłych pacjentów – obrazy, które zostały przeanalizowane przez ekspertów, aby określić, czy na obrazie występują oznaki osteoporozy czy nie.
- Zdjęcia rentgenowskie i dane medyczne nowych pacjentów – dane pozyskiwane podczas konsultacji medycznej.
Wykorzystany model uczenia maszynowego to konwolucyjna sieć neuronowa (CNN) czyli rodzaj algorytmu głębokiego uczenia, który jest najczęściej stosowany do analizy i poznawania cech wizualnych w oparciu o duże ilości danych. Za zastosowaniem tego algorytmu przemawia uznawanie go za najlepszy model stosowany w wizji komputerowej. Dodatkowo algorytm ten z powodzeniem jest już stosowany do omawiania zdjęć rentgenowskich np. klatki piersiowej, piersi, mózgu, układu mięśniowo-szkieletowego oraz brzucha i miednicy.
Zadaniem scenariusza jest przewidywanie występowania lub braku osteoporozy u pacjentów na podstawie zebranych danych. Inżynierowie danych, analitycy danych oraz radiolodzy współpracują, aby wypracować system, który będzie potrafił wykrywać obecność choroby na zdjęciu rentgenowskim. Poniższa infografika przestawia proces tworzenia tego systemu.
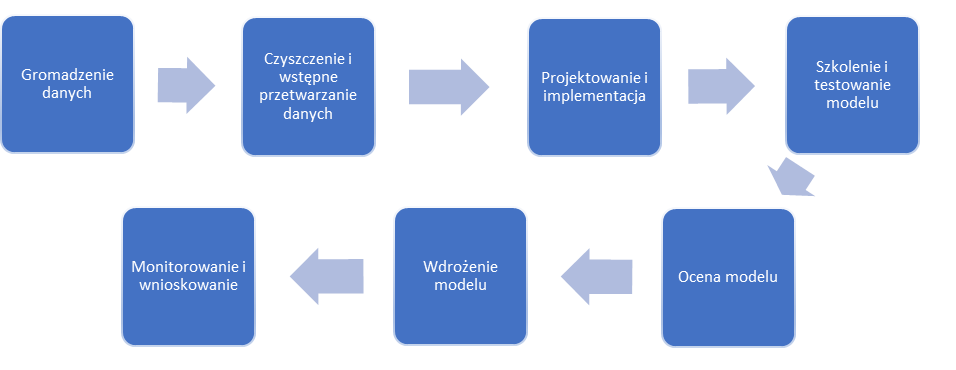
Zagrożenia i słabe punkty scenariusza
Wyróżniono dwa główne negatywne skutki na które należy zwrócić uwagę:
- Utrata integralności danych – może przynieść negatywne konsekwencje zarówno pacjentowi, jak i firmie medycznej. W pierwszym przypadku są dwa scenariusze. Pacjent chorujący na osteoporozę, który został źle zdiagnozowany, w konsekwencji nie jest leczony lub jest niewłaściwie leczony. Z drugiej strony pacjent niechorujący na osteoporozę, który został źle zdiagnozowany, w konsekwencji jest niepotrzebnie leczony lub niewłaściwie leczony. Z kolei firma medyczna może zostać pozwana do sądu przez poszkodowanego pacjenta, co będzie skutkowało utratą jej reputacji. Należy jednak zauważyć, iż ryzyko jest niskie, ponieważ model uczenia maszynowego służy jedynie jako wsparcie pracy radiologów, a nie jako system decydujący o ostatecznej diagnozie.
- Utrata poufności danych osobowych pacjentów – skradzione dane pacjenta mogą zostać wykorzystane do prób phishingu. Informacje o złym stanie zdrowia, które wyciekły, mogą przyczynić się do np. problemów z uzyskaniem kredytu, niedostaniem się na studia, nieprzyjęciem do nowej pracy czy odrzuceniem wniosku o ubezpieczenie. W takiej sytuacji zarówno pacjent, którego dotyczy ujawnienie danych bezpośrednio jak i inni pacjenci stracą zaufanie do usług medycznych.
Zagrożenia, które mogą doprowadzić do wystąpienia powyższych skutków:
- Uszkodzenie elementów systemu diagnostycznego w wyniku ataków hakerskich.
- Ominięcie ochrony bezpieczeństwa informacji – jest to możliwe gdy zostanie naruszony jeden z elementów systemu diagnostycznego. Atakujący może zmodyfikować urządzenia do przechwytywania obrazu (np. skaner lub oprogramowanie rentgenowskie), aby dodać dodatkowy szum do obrazu. W konsekwencji model mógłby stawiać nieprawidłowe diagnozy.
- Błąd ludzki – np. brak wystarczającej ostrożności ze strony pracowników przy przetwarzaniu danych.
- Ujawnienie danych – atakujący wskutek zainstalowania programu szpiegowskiego lub dzięki niewystarczającym zabezpieczeniom baz danych, może uzyskać dostęp do danych znajdujących się w tych bazach.
- Wprowadzenie fałszywych informacji – radiolog z pobudek prywatnych (np. dyskryminacja jakiejś grupy etnicznej, rasowej, seksualnej, kwestie finansowe, strach przed byciem zastąpionym przez maszynę) może celowo wprowadzić fałszywe adnotacje dotyczące pacjenta.
- Przetwarzanie niezgodne z prawem – przetwarzane dane powinny być niezbędne do diagnozowania osteoporozy.
- Nieuczciwe przetwarzanie danych – np. radiolog zbytnio zaufał diagnozie postawionej przez algorytm i poświęcił niewystarczająco uwagi danemu przypadkowi.
- Niewystarczająca przejrzystość zasad przetwarzania danych – zasady przetwarzania danych mogą nie być wystarczająco jasne i klarowne dla pacjentów, których dane mają być przetwarzane.
- Przekierowanie celu – dane pacjenta powinny być wykorzystywane jedynie w celu diagnozy osteoporozy. Istnieje jednak ryzyko, iż zostaną one wykorzystane w innych celach bez wiedzy i zgody pacjenta.
- Brak zachowania zasady minimalizacji danych – istnieje ryzyko, iż będą gromadzone i przetwarzane nie tylko dane niezbędne do postawienia diagnozy osteoporozy, ale również niewymagane dane.
- Brak dokładności przy gromadzeniu danych – w przypadku niedokładnego wprowadzenia danych, diagnoza postawiona przez algorytm jest niewiarygodna.
- Nieprzestrzeganie okresu przechowywania danych – okres przechowywania danych w praktyce medycznej może być inny niż okres przechowywania danych regulowany lokalnymi przepisami.
- Niedostosowanie modelu do problemu – przyczyną tego może być bazowanie na niewystarczająco reprezentatywnych danych, celowe i złośliwe działania człowieka lub brak procedury testowej.
Cyberbezpieczeństwo i ochrona prywatności a wydajność modelu.
W raporcie wskazano szereg zaleceń, stosowanych w celu utrzymania równowagi między wydajnością modelu, a zachowaniem bezpieczeństwa i ochroną prywatności. Poniższa tabela przedstawia te zalecania.
| Pseudonimizacja danych byłych pacjentów | Zastąpienie imion i nazwisk pacjentów identyfikatorami. Powstają wtedy dwie bazy. Jedna zawierająca identyfikator, wiek, płeć, BMI oraz zdjęcie rentgenowskie oraz druga, zawierająca identyfikator, imię i nazwisko. |
| Dodanie do zbioru danych przykładów przeciwstawnych | Wprowadzenie przeciwstawnych przykładów do algorytmu, aby zwiększyć jego odporność na ataki omijające zabezpieczenie. |
| Wybranie najbardziej odpornego na zagrożenia projektu modelu | Stosowanie modelu, który w jak największym stopniu jest odporny na ataki omijające zabezpieczenia. |
| Zintegrowana kontrola zakłóceń | Algorytm DNN użyty w tym scenariuszu można sprawdzić pod kątem zakłóceń dzięki techniki STRIP, która polega na zakłóceniu danych wejściowych i obserwacji losowości przewidywań algorytmu. Technikę tę stosuje się jedynie w fazie szkoleń modelu. |
| Powiększenie zbioru danych | Szkolenie modelu na podstawie danych medycznych zbieranych przez kilka lat. Dzięki obszernej bazie danych jest mniejsze prawdopodobieństwo błędnego diagnozowania. |
| Zabezpieczone przekazywanie danych | Zapewnienie, aby przekazywanie danych odbywało się w sposób bezpieczny i chroniący dane przed utratą integralności. W tym celu stosowany jest protokół TLS 1.3, który uniemożliwia atakującemu modyfikacje danych podczas fazy tranzytu. |
| Zapewnienie zgodności wszystkich systemów i urządzeń z zasadami uwierzytelniania i kontroli dostępu | zarządzanie centralne – np. Active Directory,wieloskładnikowe uwierzytelnianie analityków danych i administratorów, którzy powinni mieć do nich dostęp,protokół OAuth 2.0,przestrzeganie polityki uwierzytelniania, opartej na aktualnych zaleceniach organów takich jak ENISA czy NIST. |
| Weryfikacja i kontrola podmiotów przetwarzających dane | Prowadzona jest kontrola dostawcy usług w chmurze oraz jego działań. Klauzule umowne, audyty wewnętrzne i zewnętrzne zapewniają prawidłowe i zgodne z polityką bezpieczeństwa i prywatności działanie podmiotów przetwarzających dane. |
| Ocena prawnie uzasadnionych interesów | Podstawą prawną przetwarzania danych jest prawnie uzasadniony interes. |
| Upewnienie się, iż model jest wystarczająco odporny na środowisko, w którym będzie działał | Przedstawiciele środowiska medycznego we współpracy z analitykami danych muszą upewnić się, iż model jest jak najbardziej odporny na środowisko w którym jest stosowany. W tym celu model jest testowany w rzeczywistych warunkach i przy wykorzystaniu rzeczywistych danych. |
| Stosowanie wiarygodnych źródeł do oznaczania danych | Radiolodzy muszą być odpowiednio przeszkoleni, aby w rzetelny sposób znakować wprowadzane do bazy dane. W przeciwnym razie model może generować nieprawidłowe diagnozy. |
| Sprawdzanie podatności elementów systemu na ataki | Regularne audyty bezpieczeństwa, w celu sprawdzania funkcjonalności zabezpieczeń;Przygotowany oraz weryfikowany w czasie plan naprawczy, który w razie potrzeby można wdrożyć. |
| Monitorowanie działania i wydajności modelu | Analitycy danych oraz inżynierowie danych muszą stale kontrolować, szkolić i oceniać stosowany model, tak aby być pewnym skuteczności i wydajności algorytmu. |
| Minimalizacja danych na każdym etapie przetwarzania | Gromadzone są jedynie dane istotne oraz niezbędne do efektywnego działania modelu. Należy przeprowadzić badanie, które wskaże czy dane takie jak: imię i nazwisko, wiek, masa ciała oraz zdjęcie rentgenowskie są rzeczywiście wymagane, a dowód tej konieczności podać do wiadomości publicznej. Minimalizacja danych obejmuje również wyżej opisaną pseudonimizację. |
Podsumowanie:
- Wykorzystanie sztucznej inteligencji w codziennym życiu może w dużym stopniu wpłynąć na rozwój wszystkich sektorów gospodarki oraz wspomóc i ułatwić pracę ludziom.
- Niewłaściwe użycie sztucznej inteligencji może przynieść negatywne skutki oraz być zagrożeniem dla bezpieczeństwa i ochrony prywatności.
- Każde wykorzystanie sztucznej inteligencji wymaga dokładnego przebadania danego przypadku oraz zidentyfikowanie zagrożeń, które mogą wystąpić.
- Raport stanowi swego rodzaju przewodnik do identyfikacji i oceny zagrożeń, jednak należy pamiętać, iż przedstawione założenia nie będą dopasowane do wszystkich scenariuszy wykorzystujących model uczenia maszynowego.