– Tato, co robisz? – do pokoju, w którym pracuję, wbiegły dziewczynki z pytaniem.
– Sprawdzam, czy modele, które zbudowałem, przez cały czas działają – odpowiedziałem.
– A mogą przestać działać? – zapytała Jagódka.
– Mogą? – powtórzyła Otylka.
– Hmm… pomyślcie o modelu jak o telewizorze. Świat gwałtownie się zmienia, dochodzą nowe kanały telewizyjne, filmy zmieniają się na takie o znacznie lepszej jakości. Stary telewizor może przestać odbierać nowsze kanały, zacząć mieć zakłócenia, albo wyświetlać bajki w gorszej jakości. Dlatego warto obserwować, jak działa i jeżeli zacznie coś się dziać, wiedzieć o tym, aby moc zadziałać.
– A to może zmienimy nasz stary telewizor na nowszy? – z uśmiechem zaproponowała Jagódka.
– Nie potrzebujemy zmieniać telewizora, ale model, na który patrzyłem na monitorze, gdy wchodziłyście do pokoju, chyba już wymaga zmiany…
Naszym podstawowym założeniem, którego używamy w uczeniu maszynowym, jest to, iż dane i logika, których użyliśmy do zbudowania modelu, naśladują rzeczywisty świat. Gdyby tak nie było i nie wierzylibyśmy w nasze predykcje, to byśmy nie wdrożyli modelu na produkcji .
Niestety (albo na szczęście) prawdziwy świat się zmienia. Czasem powolutku i stopniowo, a czasem dość gwałtownie. Kiedy tak się stanie to dane treningowe, których pierwotnie używaliśmy do trenowania modelu, mogą bardzo różnić się od tego, co dzieje się w aktualnym świecie. I może to spowodować pogorszenie jakości predykcji modelu. Popatrzmy chociaż przez pryzmat pandemii i tego, jak gwałtownie wpłynęła na zmianę naszych zachowań.
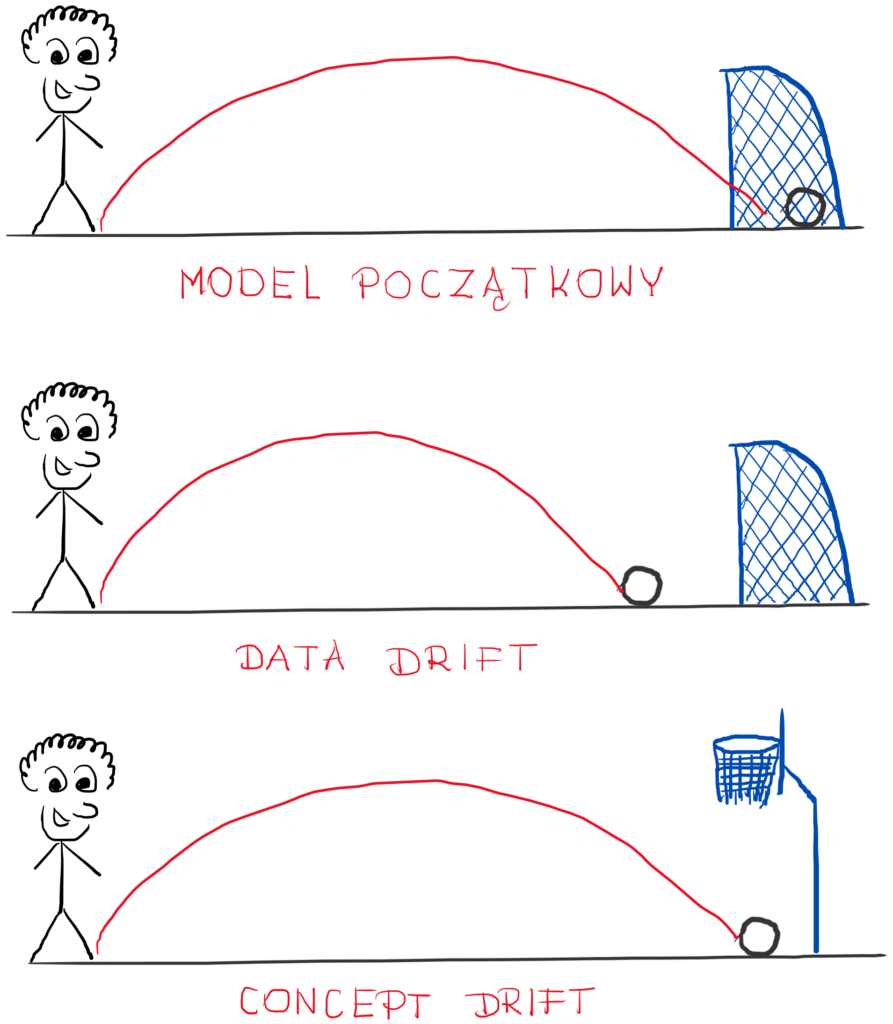
Czym jest dryft modelu (ang. model drift) ?
Dryft modelu odnosi się do spadku wydajności modelu z powodu zmian danych i relacji między zmiennymi wejściowymi i wyjściowymi.
Taki dryft może spowodować pogorszenie jakości modelu na produkcji, co skutkuje niedokładnymi i gorszymi prognozami. A to ma negatywny wpływ na firmę, ponieważ może narazić ją na duże straty. Właśnie dlatego warto monitorować degradację modelu, aby zespół data scientistów czy właściciele biznesowi byli ostrzegani z wyprzedzeniem przed spadkiem wydajności modelu, dając im czas na:
- skorygowanie dryftu danych,
- przetrenowanie modelu na nowych danych,
- zaktualizowanie modelu o nowe zmienne źródła danych,
- lub zmianę polityki użycia (zmiana progów odcięcia lub dodanie nowych dodatkowych reguł, kiedy i jak używać modelu).

Na jakie pytania powinniśmy odpowiedzieć?
Intuicyjnie czujemy, aby wiedzieć, czy model dalej działa poprawnie, czy nie, to powinniśmy w jakimś stopniu monitorować model. Dodatkowo mam nadzieję, iż czujesz przez skórę, iż powinniśmy mieć coś więcej niż tylko metryki biznesowe, które posłużyły nam do wybrania tego modelu.
Mam nadzieję, iż również już czujesz, iż aby uzyskać kontrolę nad naszymi projektami AI powinniśmy z wyprzedzeniem wiedzieć o potencjalnych zagrożeniach. Zatem powinniśmy zawsze po wdrożonym projekcie na produkcji w jakiś sposób go monitorować.
Dlatego warto odpowiedzieć na poniższe pytania:
1. Czy przychodzące dane odzwierciedlają te same wzorce co dane, na których model był zbudowany?
2. Czy model działa tak samo dobrze, jak w fazie projektowania?
3. A jeżeli nie to dlaczego?
Jednak zanim zaczniemy na nie odpowiadać, przyjrzyjmy się różnym rodzajom dryftu danych.
Dryft modelu – jakie są rodzaje?
Jest kilka typów dryftu, których warto być świadomym. Jednak, aby je lepiej zrozumieć, posłużmy się przykładem. Załóżmy, iż rok temu zbudowaliśmy model do wykrywania transakcji fraudowych na kartach kredytowych. Podczas wdrażania byliśmy zadowoleni z jego metryk.
Poniższy rysunek niech reprezentuje właśnie te nasze dane testowe. Niewielka linia przerywana to granica decyzji dla naszego modelu klasyfikatora do wykrywania fraudów. Losując losowo 12 transakcji z próbki testowej, model prawidłowo rozróżniał transakcje fraudowe (czerwone kropki) od normalnych (granatowe).

… minął rok. W tym czasie wiele mogło się zmienić. Sprawdźmy, jak mogłyby teraz wyglądać różne sytuacje. Pierwsza z nich to taka, iż nic się nie zmieniło, ale ją pomińmy, ponieważ nie ma w tym nic ciekawego.
Dryft koncepcji (ang. concept drift)
Najbardziej znanym rodzajem dryftu jest dryft koncepcji. Jest on również jednym z bardziej niebezpiecznych. Dlaczego?
Ponieważ w tym dryfcie zmieniają się wcześniejsze reguły i zasady gry. Czyli zmienia się prawdopodobieństwo tego, czy coś jest czerwone (fraud) czy szare (transakcja normalna).
Lub innymi słowy: zmienia się relacja między danymi wejściowymi i wyjściowymi modelu.
Dlaczego może się zmienić? Na przykład z tego względu, iż przestępcy, robiąc fraudy, zmienili sposoby okradania klientów lub coraz bardziej upodobnili się do normalnych transakcji po to, aby oszukać algorytmy, modele i ludzi!
Na naszym poglądowym wykresie można byłoby przedstawić zmianę granic decyzji:

Dryft danych (ang. data drift)
Dryft danych występuje, gdy po prostu zmieniły się dane przychodzące, ale granica decyzji przez cały czas obowiązuje.
Aby być bardziej precyzyjnym, dryft danych możemy podzielić na 2 kategorie:
a) dryft etykiet (label drift)
Dryft etykiet to zmiana wartości wyjściowych, czyli zmienia się twoje prawdopodobieństwo zmiennej prognozowanej (na przykład jest coraz więcej grup przestępczych i zwiększa się dwukrotnie ilość fraudów, ale fraudy wyglądają podobnie jak podczas budowy modelu)
b) dryft zmiennych (feature drift)
Dryft zmiennych to zmiana wartości wejściowych, czyli zmienia się prawdopodobieństwo danych wejściowych (np. wprowadzono promocje 0% za szybkie przelewy i zwiększył się procentowy udział szybkich przelewów).
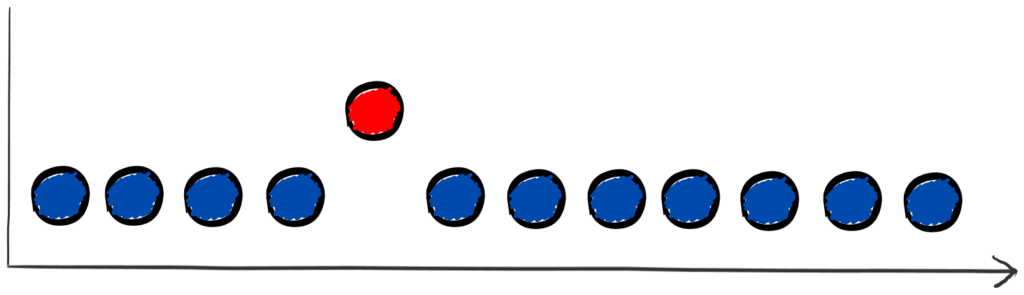
Teraz w jakimś stopniu te zmiany wpływają na jakość i dokładność naszych modeli. Na przykład poniżej widać, jak 1 obserwacja niesłusznie została zakwalifikowana jako normalna, mimo iż jest fraudem.

Jednak data drift nie musi zawsze wpływać na metryki modelu . Mogą zmienić się nasze dane wejściowe, ale nasze obserwacje dalej będą w granicy decyzji, zatem model będzie działał dalej tak samo.
Widać ten przykład na poniższym obrazku. Jednak mimo iż model działa dalej tak samo, to warto mieć świadomość tego, iż mieliśmy dryft etykiet. Ponieważ może być on pierwszym sygnałem przyszłego problemu z wydajnością modelu.

Dryft modelu – przykłady
Podsumujmy sobie prostym przykładem, jak różnią się dryfty:
– concept drift – fraudy były na przelewy walutowe. A aktualnie złodzieje przerzucili się na szybkie przelewy, których nie było wcześniej w próbce.
– label drift – większa proporcja transakcji fraudowych (dołączyły kolejne grupy przestępcze, które okradają w ten sam sposób, jak podczas budowy modelu)
– feature drift – większa proporcja klientów z VISA (bo np. Mastercard miał awarię tego dnia).
Szybkość wystąpienia dryftu
Kiedyś zastanawiałem się, czy mój pierwszy model się zestarzeje. Teraz wiem, iż nie należy zastanawiać się, CZY, ale KIEDY! Jedną z kluczowych kwestii jest szybkość wystąpienia dryftu. A to, w jaki sposób doświadczymy dryftu, może się mocno różnić. Zmiana może być:
– nagła – z dnia na dzień, np. lockdowny w wyniku pandemii COVID-19 lub wybuch wojny na Ukrainie pokazały nam, jak gwałtownie mogą nastąpić duże zmiany,

– stopniowe lub narastające – np. gdy wartość cechy zmienia się powolutku, to może nie być to oczywiste, iż niedługo będziemy mieć duży problem. Jest to interesujący przykład, ponieważ jak zmiany są niewielkie przez dłuższy czas, to można je przegapić. Zwłaszcza gdy nie mamy ustawionych odpowiednich poziomów, kiedy ma się zapalić lampka ostrzegawcza,

– impulsowa i jednorazowa, np. w przypadku błędnie zasilonych danych.
Niektórzy wyróżniają jeszcze jeden rodzaj: dryft sezonowy lub nawracający, np. czarny piątek w sprzedaży lub ilość sprzedaży w biedronce w święta państwowe. Moim zdaniem jednak sezonowość to znana koncepcja modelowania i mimo iż chwilowo wygląda to, jak dryft danych, to patrząc w dłuższym horyzoncie czasowym, to tak nawracającą zmianę potrafimy przewidzieć.

Jak wykrywać dryft modelu (model drift)?
Mamy dwa podejścia do wykrywania dryftu modelu, które zależy od odpowiedzi na pytanie: czy mam dostępne odpowiedzi (target) dla moich przewidywanych danych?
1. Oparte o prawdę (ang. ground truth)
Ground truth to poprawna odpowiedź na pytanie, na które stara się odpowiedzieć nasz model. W przypadku naszych transakcji kartowych będzie to odpowiedź, czy ta transakcja kartą kredytową jest rzeczywiście fałszywa.
Gdy znamy wartości wszystkich przewidywań, możemy z całą pewnością ocenić nasz model i jak dobrze sobie radzi i wykonuje jego robotę. Oraz o ile działa gorzej (lub lepiej ) w stosunku do okresu z budowy modelu. Natomiast jest to najlepszy sposób monitorowania modelu: po prostu przeliczamy metryki biznesowe i mamy odpowiedź.

Możemy również użyć dodatkowych bardziej zaawansowanych metod uczenia nadzorowanego takich jak:
- analiza sekwencji,
- statystyczny proces kontroli (SPC) do oceny tempa zmian,
- precyzyjniejsze monitorowanie zmian wielu rozkładów (ADWIN),
Uwaga! Pamiętaj, iż warto przedyskutować z biznesem ten temat, bo może dla niego będzie ważne, aby dodać specyficzne metryki.
W tym przypadku największym problemem monitorowania ground truth jest zdobycie tej prawdy. Może to wymagać:
a) oczekiwania na zdarzenie – jeżeli nasz model przewiduje roczny horyzont czasu do przodu (np. czy klient nie spłaci kredytu w ciągu najbliższych 12 miesięcy), to jest to bardzo długi okres.
b) zaangażowania osób, aby ktoś manualnie poetykietował dane.
W przypadku naszych fraudów transakcyjnych mówimy o obu czynnikach: potrzebujemy czasu, aby klient złożył reklamację i analityka, który przeanalizuje sprawę i potwierdzi fraud.
Natomiast nikt nie chce wdrożyć modelu na produkcję, zamknąć oczy i czekać przez rok. I tutaj pojawia się drugie podejście.
2. Na podstawie danych wejściowych (ang. input drift)
Gdy mamy dostępną ground truth, to jest to najlepsze rozwiązanie, jakie możemy zrobić na produkcji do monitorowania modelu. Jednak uzyskanie ground truth jak wspomniałem powyżej, może być powolne i kosztowne.
Jeśli nasz przypadek użycia wymaga szybkiej informacji zwrotnej lub podstawowa prawda nie pozostało dostępna, dobrym sposobem może być ocena dryftu danych. Dlaczego?
To jak dobrze model działa jest tak naprawdę odzwierciedleniem danych wykorzystanych do uczenia modelu. Zatem potencjalna zmiana w rozkładzie wejściowych danych może prowadzić do dryftu danych.
Mamy tutaj proste i najważniejsze założenie, iż model będzie dokładnie przewidywał, gdy dane, na których został zbudowany, będą odzwierciedlały te dane, na których aktualnie działa i przelicza dane rzeczywiste.

Zatem jeżeli widzimy istotne różnice między danymi z budowy modelu a takimi, na jakich teraz działa to jest bardzo duże prawdopodobieństwo, ze wydajność modelu jest zagrożona.
W przeciwieństwie do ground truth tutaj potrzebujemy mieć tylko dane wejściowe. Zatem należy się skupić na tym, jak różnią się rozkłady rzeczywiste od tych z budowy modelu i jak jeden rozkład odbiega od drugiego.
Mamy kilka metod:
– Population Stability Index (PSI) – najpopularniejsza metryka w branżach finansowych porównująca ilość obserwacji w podziale wartości zmiennej na koszyki (ang. bins),
– dywergencja Kullbacka-Leiblera – porównuje różnice pomiędzy dwoma rozkładami – aktualnym i z budowy modelu,
– dywergencja Jensena-Shannona – bazuje na dywergencji KL i jest to pomiar podobieństwa między dwoma rozkładami prawdopodobieństwa z zawsze skończoną wartością,
– test Kołmogorowa-Smirnowa (KS test) – określa ilościowo odległość między rozkładem próbki a rozkładem kumulacyjnym. Warto go użyć w przypadku nietypowych średnich dystrybucji.
Można również użyć bardziej zaawansowanych metod wykorzystujących uczenie bez nadzoru, które głównie działają globalnie takie jak: MD3, FAAD, UDetect, DDAL, SAND, itp. jeżeli interesuje Cię ten temat, to możesz spojrzeć na zestawienie TUTAJ.
Dryft modelu – jak analizować przyczynę?
Brawo! Stosując powyższe metody odkryliśmy, iż coś jest nie tak z naszymi danymi. Teraz trzeba dotrzeć do pierwotnej przyczyny tego, co się dzieje.
Możliwe są dwie najważniejsze przyczyny:
1. Kwestia integralności danych (ang. data integrity)
To jest pierwsze miejsce, gdzie warto sprawdzić to, czy nic się nie zmieniło. Może jest jakiś błąd czy „robak” w pipelinach, które zasilają nasze dane. Albo mogło zmienić się API i teraz zwraca same puste wartości.
Jest to ważne, aby sprawdzić, zanim wejdziemy głębiej w szukanie problemów. Chcemy otrzymywać alerty o czymś niestandardowym. Możemy mieć nagłe braki wartości danych, nowe wartości poza pierwotnym zakresem, może nasza firma opracowała nowy katalog produktów.
2. Rzeczywiste zmiany w danych (ang. real label or feature change)
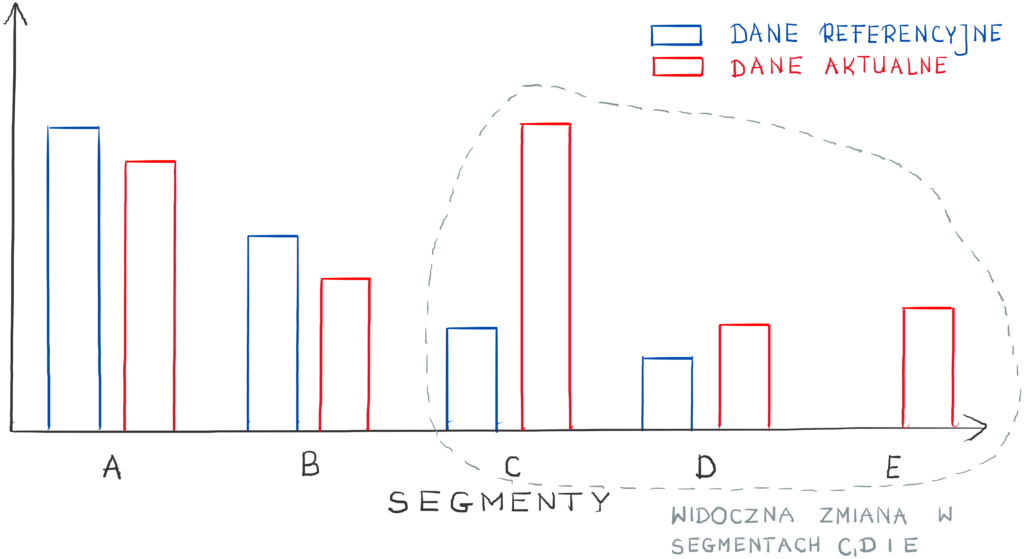
Jak mamy pewność, iż nie ma problemu z integralnością danych, możemy wejść głębiej i przyjrzeć się analityce dryftu. Przede wszystkim koncentrujemy się na porównaniu rozkładów na poziomie poszczególnych zmiennych i znalezieniu rozbieżności z próbką z budowy.
Rozkłady, dla których zmienne się zmieniły? Czy to zmiany w cechach, które najbardziej wpływają na predykcje modelu? Warto patrzeć na cechy z perspektywy czasu (np. w oknach miesięcznych lub tygodniowych) jak się zmieniały rozkłady.
Na tym etapie warto wypracować z twórcami modelu (jeśli to nie Wy go tworzyliście ), analitykiem danych lub osobą z wiedzą domenową, która pozwoli zrozumieć różnice, np. czy to była powolna zmiana, czy nagła.
Możesz też przygotować analizy dla różnych segmentów (np. wiek klientów, kanał sprzedaży, region). Jest duża szansa, iż nakieruje Cię na adekwatne tory.
Jak naprawić model?
To już zależy tylko od powyższych odkryć.
W największej ilości przypadków z mojego doświadczenia była to naprawa pipeline z danymi, które w wyniku jakiegoś innego projektu zmieniły swój zakres (były wartości puste i nagle pojawiły się 0) lub z błędnego zasilenia danymi (potem przychodził mail o błędzie i iż będzie ponowne zasilenie po czym wszystko wracało do normy).
W przypadku pogarszających się modeli warto byłoby pewnie odświeżyć model o nowe dane i nową próbkę z przesuniętym oknem czasowym.
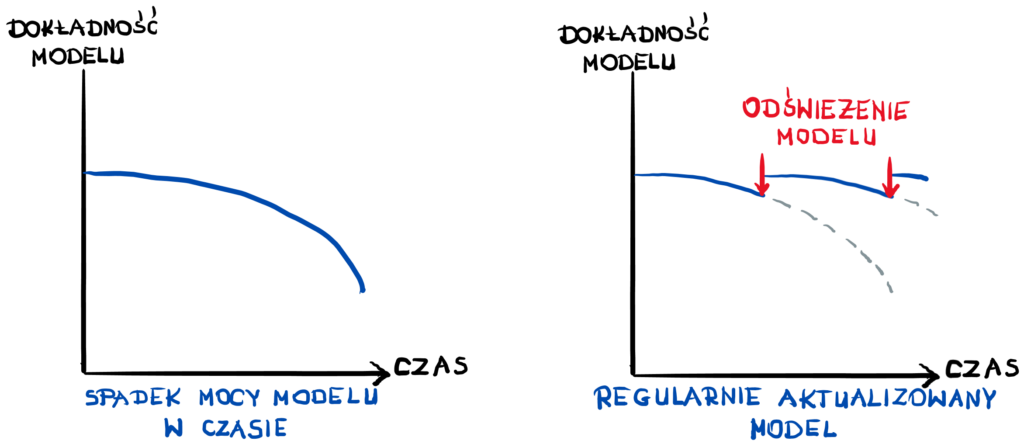
A czasami możesz zauważyć, iż może potrzebne jest przełączanie modeli w zależności od cyklów, jakie występują (jeśli podstawowy model sam się tego nie nauczył).
Możesz poszukać, w których segmentach model gorzej działa:
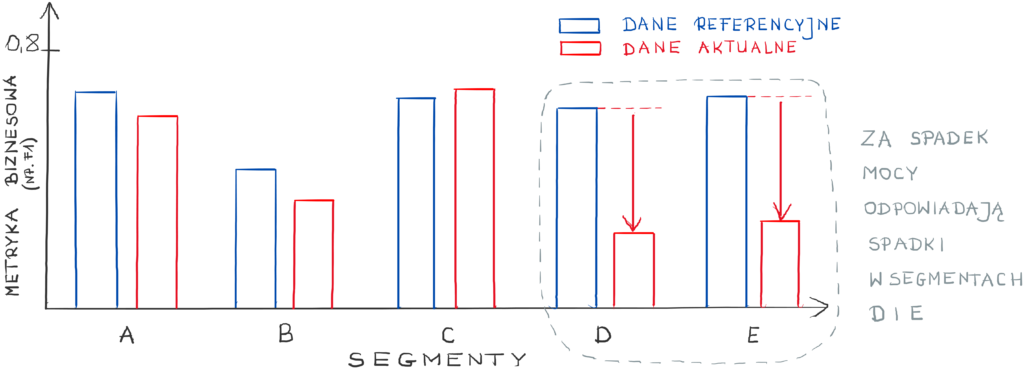
i dla nich może wystarczy odrobinę zmienić próg odcięcia:

Metod i sposobów jest naprawdę sporo i spokojnie można byłoby na ich temat napisać niejeden doktorat
Ach, jeszcze dodałbym tylko, iż w przypadku gdy mamy nowe modele przeliczane co miesiąc, wówczas nie mamy problemów związanych z data drift (bo zawsze mamy model na najświeższych danych), ale pojawia się o wiele więcej innych problemów, o których chętnie kiedyś napiszę
One more thing: gotowe biblioteki z rozwiązaniem od ręki
Pamiętam, iż za czasów, gdy zajmowałem się ryzykiem kredytowym, pisałem takie rozwiązania przy wykorzystaniu VBA i Excela. Na szczęście dzisiaj jest wiele pakietów pythonowych, które dają gotowe rozwiązania i nie trzeba wszystkiego pisać samemu.
Poniżej kilka przykładowych ciekawych pakietów, których sam miałem okazję użyć:
1. Evidently
2. Deepcheck
3. Nannyml
Powodzenia w monitorowaniu Waszych modeli!
Pozdrawiam serdecznie,

Image by Halit Akkaya from Pixabay








