Detekcja pozy w czasie rzeczywistym w React Native z użyciem MLKit
dogtronic.io 3 lat temu
Detekcja pozycji człowieka na podstawie filmów lub obrazów ma kluczową rolę w wielu nowoczesnych zastosowaniach. Określanie poprawności wykonywania ćwiczeń fizycznych, nakładanie filtrów w rzeczywistości rozszerzonej (filtry w wielu aplikacjach społecznościowych), ale również rozpoznawanie języka migowego czy zastosowania medyczne – w tych wszystkich sytuacjach istnieje potrzeba sprawnego modelu rozpoznawania pozycji ciała człowieka.
W 2020 roku naukowcy Valentin Bazarevsky oraz Ivan Grishchenko z firmy Google zaprezentowali światu narzędzie BlazePose które na stałe weszło do MLKit od Google, i służy właśnie do wykrywania pozycji z pojedynczej klatki filmu, zapewniając przy tym obsługę oraz przetwarzanie w czasie rzeczywistym.
Jeśli interesuje Was ten wpis zachęcamy do zapoznania się również z pozostałymi artykułami o wykorzystaniu sztucznej inteligencji i uczenia maszynowego w aplikacjach React Native:
1. Tworzenie natywnych procesorów klatek dla Vision Camera w React Native z użyciem OpenCV. 2. Analiza semantyczna w React Native z wykorzystaniem Tensorflow.
Topologia
W przeciwieństwie do obecnego standardu w przetwarzaniu pozy ludzkiego działa, czyli topologii COCO, składającej się z 17 punktów orientacyjnych, BlazePose posiada możliwość umieszczenia aż 33 punktów, zarówno na kończynach człowieka (używając modelu dłoni) jak i samej twarzy.
Szczegółowy zbiór punktów możemy zobaczyć poniżej:
Topologia punktów obserwacyjnych (źródło: https://ai.googleblog.com/2020/08/on-device-real-time-body-pose-tracking.html)
Sposób działania
Wykrywanie pozy ma charakter dwuskładnikowy: najpierw detektor lokalizuje tzw. obszar zainteresowania (ROI), w tym przypadku będzie to człowiek zlokalizowany na zdjęciu. Następnieprzywidywane są punkty orientacyjne. Dla przyspieszenia obliczeń, pierwsza część jest wykonywana wyłącznie na pierwszej klatce – do obliczeń kolejnych, wykorzystywane są punkty z poprzedniej.
W tym artykule chciałbym zaprezentować przykład użycia MLKit do detekcji pozy w czasie rzeczywistym w aplikacji React Native z wykorzystaniem biblioteki Vision Camera z wykorzystaniem natywnego procesora klatek dla iOS.
Krok 1
Konfiguracja projektu
Pierwszym krokiem będzie stworzenie nowego projektu aplikacji React Native.
Wykorzystywana przeze mnie wersja to React Native 0.68.2. Aby stworzyć nowy projekt wykonujemy polecenie:
npx react-native init posedetection
Musimy również zainstalować potrzebne biblioteki do obsługi kamery oraz animacji:
W przypadku, gdy funkcja wykrywająca zwróci błąd oraz w przypadku, gdy nie zostanie wykryta żadna poza, zwróćmy pusty obiekt typu NSDictionary. W przypadku wykrycia pozy, zwróćmy wybrane koordynaty:
Nasz procesor klatek będzie nosił nazwę poseDetection oraz będzie zwracał obiekt typu NSDictionary (który będzie konwertowany do zwykłego obiektu po stronie JavaScriptu).
Krok 3
Obsługa po stronie JavaScript
Aby umożliwić wykorzystanie procesora klatek, w pliku babel.config.js musimy dodać następujący element:
Dzięki temu, możemy je później użyć do wyświetlenia linii na ekranie. Przejdźmy najpierw jednak do samego obliczenia potrzebnych kordynatów. Poniższy kod ma za zadanie wykorzystać natywny procesor do obliczenia pozycji punktów orientacyjnych oraz wykorzystując proporcje z ekranu użytkownika (tzw. xFactor i yFactor) do zapisu pozycji punktów na ekranie użytkownika.
Po wykonaniu wszystkich kroków, sprawdźmy jak działa nasza aplikacja:
Podsumowanie
Wykorzystywanie wykrywania pozycji człowieka, otwiera niezwykłe możliwości przy tworzeniu wieloplatformowych aplikacji mobilnych, a możliwość skorzystania z gotowych narzędzi jak MLKit, to znaczne ułatwienie.
Nowa architektura fabric oraz biblioteki jak Vision Camera czy Reanimated pozwalają na tworzenie szybkiej komunikacji między kodem natywnym, a kodem JavaScript, co w konsekwencji prowadzi do wielu nowych, ciekawych zastosowań i znaczącej optymalizacji działania aplikacji.
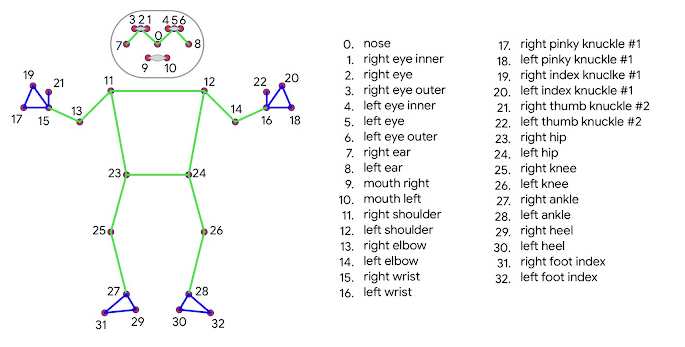 Topologia punktów obserwacyjnych (źródło: https://ai.googleblog.com/2020/08/on-device-real-time-body-pose-tracking.html)
Topologia punktów obserwacyjnych (źródło: https://ai.googleblog.com/2020/08/on-device-real-time-body-pose-tracking.html)
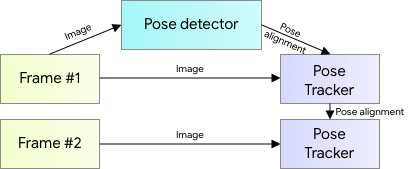 Detektor pozy (źródło: https://ai.googleblog.com/2020/08/on-device-real-time-body-pose-tracking.html)
Detektor pozy (źródło: https://ai.googleblog.com/2020/08/on-device-real-time-body-pose-tracking.html)
 Pierwszym krokiem będzie stworzenie nowego projektu aplikacji React Native.
Pierwszym krokiem będzie stworzenie nowego projektu aplikacji React Native.
 Aby umożliwić wykorzystanie biblioteki MLKit w czasie rzeczywistym w bibliotece Vision Camera, konieczne jest stworzenie natywnego procesora klatek.
Aby umożliwić wykorzystanie biblioteki MLKit w czasie rzeczywistym w bibliotece Vision Camera, konieczne jest stworzenie natywnego procesora klatek.
 Aby umożliwić wykorzystanie procesora klatek, w pliku babel.config.js musimy dodać następujący element:
Aby umożliwić wykorzystanie procesora klatek, w pliku babel.config.js musimy dodać następujący element: