Poniżej przedstawiamy rozwiązania do zadań, które pojawiły się na organizowanym przez CERT Polska CTF-ie organizowanym w ramach Europejskiego Miesiąca Cyberbezpieczeństwa. Przez przeczytaniem zachęcamy do próby samodzielnego zmierzenia się z nimi – zadania są dostępne w portalu https://hack.cert.pl/
KPN
W tym zadaniu otrzymujemy 32-bitowy plik wykonywalny ELF. Po jego uruchomieniu widzimy następującą wiadomość:
Cześć, jestem Augustyn Zagrajmy w kamień - papier - nożyce Pokonaj mnie 100 razy, a zdradzę Ci mój sekret! Twój wybór (1 - kamień, 2 - papier, 3 - nożyce):Po wybraniu złej odpowiedzi program kończy działanie. Niestety, wygranie 100 razy z rzędu jest niemal niemożliwe. Przyjrzyjmy się zatem zdezasemblowanemu kodowi programu.
Pierwszą rzeczą, która przykuwa uwagę jest wybór imienia, jakim program się przedstawia:

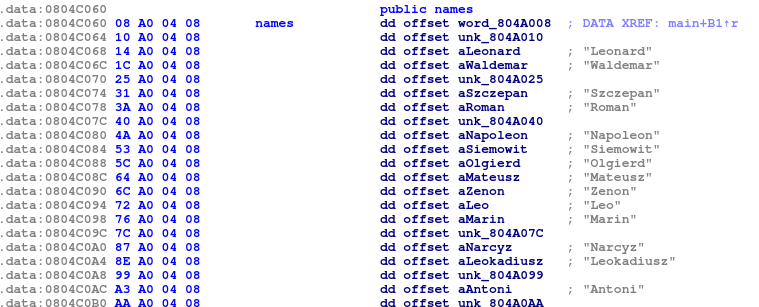
Jest ono wybierane losowo z tablicy zawierającej 256 różnych imion.
Dalsza część programu wygląda standardowo: 100 przebiegów pętli, w których następuje losowanie wyboru komputera przy użyciu funkcji rand, wczytanie wyboru użytkownika funkcją scanf i odpowiednie porównanie obu wartości.
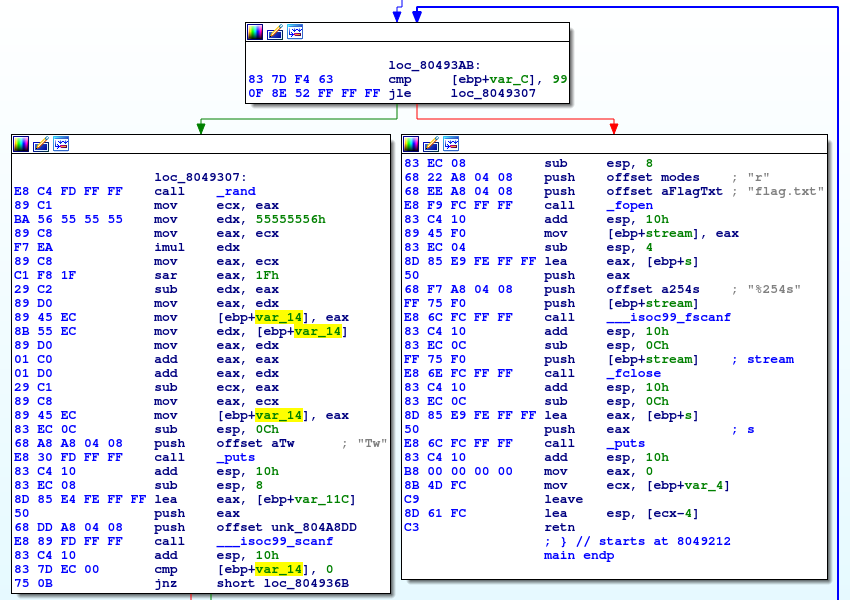

Do rozwiązania zadania użyjemy ataku na generator liczb pseudolosowych (ang. pseudo-random number generator – PRNG).
Linuksowa funkcja rand wybiera liczby pseudolosowe w sposób deterministyczny przy pomocy prostych operacji matematycznych wykonywanych na wewnętrznym stanie generatora. jeżeli tylko jesteśmy w stanie poznać stan początkowy (będący jedną liczbą, zwaną seedem), to możemy też przewidzieć wszystkie kolejne liczby zwracane przez generator. Sprawdźmy więc, w jaki sposób odbywa się inicjalizacja:

Niestety nie napawa to optymizmem – program wczytuje 4 bajty z systemowego generatora /dev/urandom. Daje to ponad 4 miliardy możliwych wartości – za dużo, żeby próbować cokolwiek zgadnąć. Zwróćmy jednak uwagę na to, iż samo wczytywanie jest wykonywane przy użyciu funkcji scanf i formatu “%4s”. Format ten wczytuje napis (string) zawierający nie więcej niż 4 znaki do momentu napotkania pierwszego białego znaku (tj. znaku nowej linii, spacji, tabulatora etc.). My natomiast nie wczytujemy napisu, a ciąg losowych bajtów – co, jeżeli drugim bajtem okaże się biały znak? Przypuśćmy, iż na wyjściu systemowego generatora dostaniemy następujący ciąg bajtów (zapis szesnastkowy):
69 0A 41 42
Na drugiej pozycji znajduje się bajt 0x0a odpowiadający znakowi nowej linii, a więc funkcja scanf zakończy odczyt w tym miejscu – zatem stan początkowy, zamiast 4 losowych bajtów, będzie zawierał tylko jeden – 0x69. Zgodnie z dokumentacją (http://www.cplusplus.com/reference/cctype/isspace/) biały znak może stanowić 6 bajtów: 0x20, 0x9, 0xa, 0xb, 0xc, 0xd.
Oznacza to, iż jeżeli jeden z powyższych bajtów znajdzie się na drugiej pozycji w strumieniu wczytanym z /dev/urandom (a prawdopodobieństwo na to wynosi 6/256 – czyli całkiem sporo), to do “odgadnięcia” będziemy mieli tylko jednobajtowy seed. Nieźle, ale takie
rozwiązanie wciąż wymagałoby zbyt wielu żądań przesłanych przez sieć.
Z pomocą przychodzi tutaj losowanie imienia – na podstawie tego, którą pozycję w tablicy names zajmuje, możemy określić pierwszą wylosowaną liczbę modulo 256.
Plan rozwiązania jest więc następujący:
Dla każdej możliwej wartości seeda od 0 do 255 losujemy imię – w sposób analogiczny, w jaki robi to zadanie – i stwórzmy odwzorowanie imię -> seed.
Po połączeniu z serwerem wybieramy seed na podstawie imienia (i liczymy, iż trafiliśmy w sytuację, w której jest on w zakresie [0, 255]).
Na podstawie tego seeda wybieramy funkcją rand wybór komputera i odsyłamy odpowiednią odpowiedź. Ostateczny skrypt rozwiązania:
Powyższe rozwiązanie zwraca flagę po kilkunastu – kilkudziesięciu próbach.
Zipowa forteca
W zadaniu Zipowa forteca mamy do dyspozycji plik ZIP. Niestety, próba rozpakowania go kończy się – w zależności od użytego narzędzia – komunikatem o uszkodzonym pliku lub prośbą o podanie hasła. Musimy więc przyjrzeć się temu plikowi z bliska.
Bardzo pomocne w zrozumieniu rozwiązania będą opisy formatu ZIP dostępne na poniższych stronach:
https://users.cs.jmu.edu/buchhofp/forensics/formats/pkzip.html
https://en.wikipedia.org/wiki/Zip_(file_format)
Do pracy z plikiem binarnym potrzebujemy również hexedytora. Dobrym wyborem będzie świetne narzędzie Veles posiadające wsparcie dla parsowania plików ZIP.
Pierwszym, co rzuca się w oczy, jest komentarz w sekcji End of Central Directory Header o długości 420 bajtów.
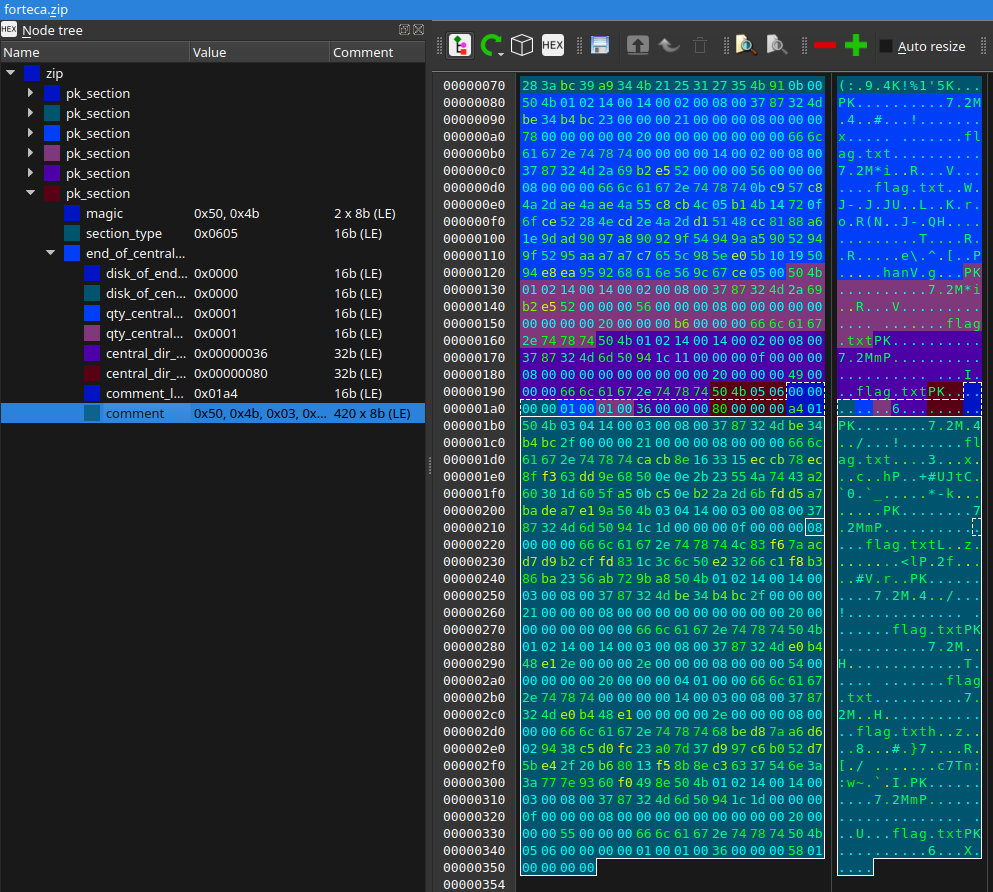
Widzimy w nim… kolejny plik ZIP! Spróbujmy więc je rozdzielić (pamiętając, żeby wyzerować długość komentarza w pierwszym pliku). Pomocny staje się tutaj Veles i jego opcja Save selection to file.
Po rozdzieleniu pliku na dwie części (nazwijmy je dla ułatwienia first.zip i second.zip) spróbujmy je rozpakować. W wyniku tego z pliku first.zip otrzymamy – znów w zależności od użytego narzędzia – jeden lub dwa pliki flag.txt o zawartościach:
“Próbuj dalej!”i
“HA HA! To nie to, czego szukasz!”Spójrzmy więc co kryją.
first.txt
W pliku first.txt łatwo zauważyć pewne niezgodności co do liczby plików w archiwum – widzimy 2 nagłówki typu Local File Header, 3 wpisy Central Dir Entry, natomiast w nagłówku End of Central Directory pole z liczbą plików w archiwum jest równe 1.
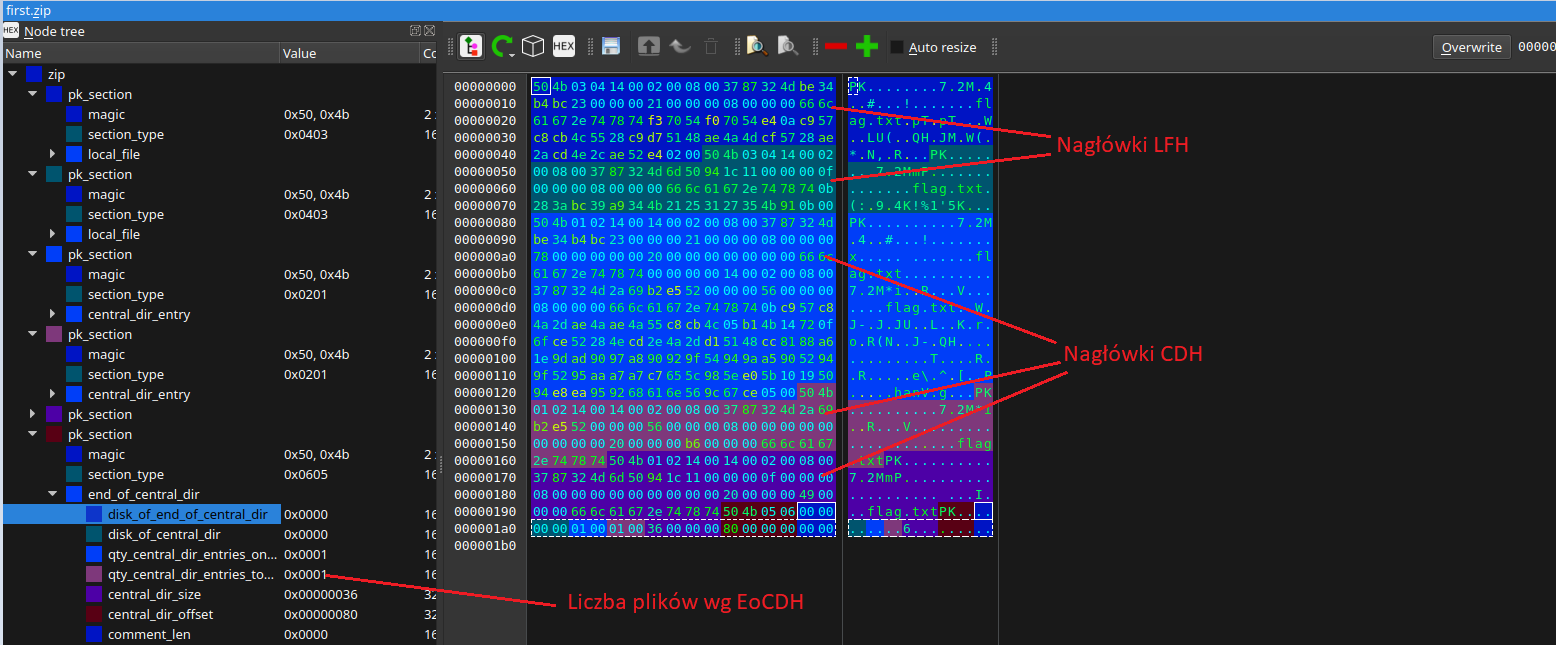
Zacznijmy od ustawienia adekwatnych wartości w EoCDH:
qty_central_dir_entries_on_disk: 3
qty_central_dir_entries_total: 3
central_dir_size: 0x11a (282 bajty – suma długości wszystkich wpisów CDH)
central_dir_offset jest ustawiony prawidłowo, nie wymaga zmiany
Pozostaje sprawa “zaginionego” LFH. Sprawdźmy więc, na które wpisy LFH wskazują wszystkie 3 wpisy CDH:
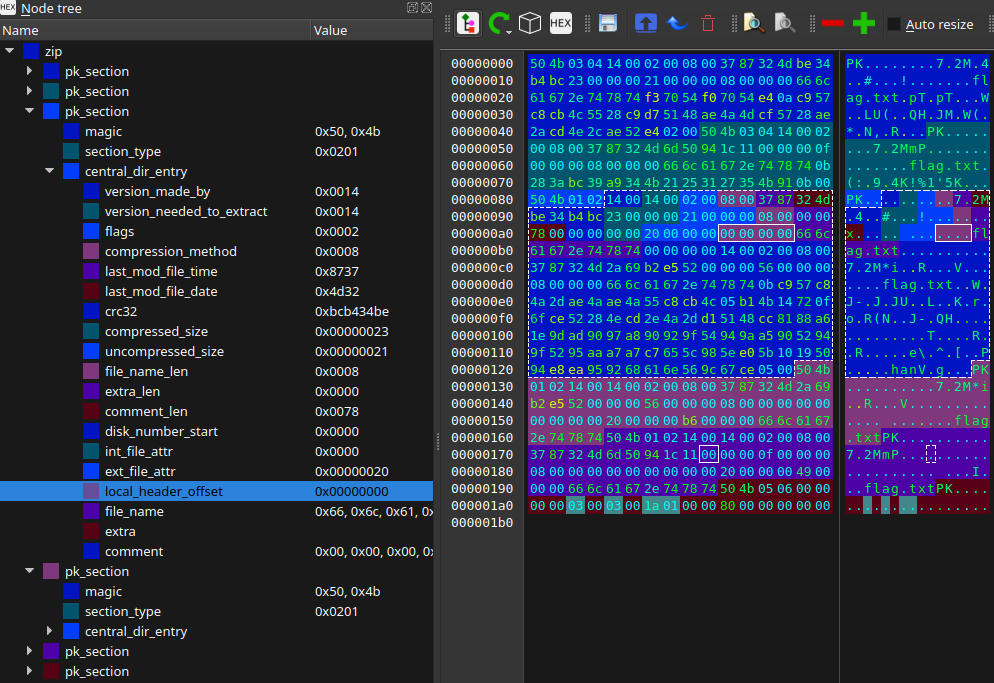
Pierwszy wpis wskazuje na pozycję 0 – czyli pierwszy nagłówek LFH. Zwraca natomiast uwagę komentarz o długości 0x78 bajtów w tej sekcji.
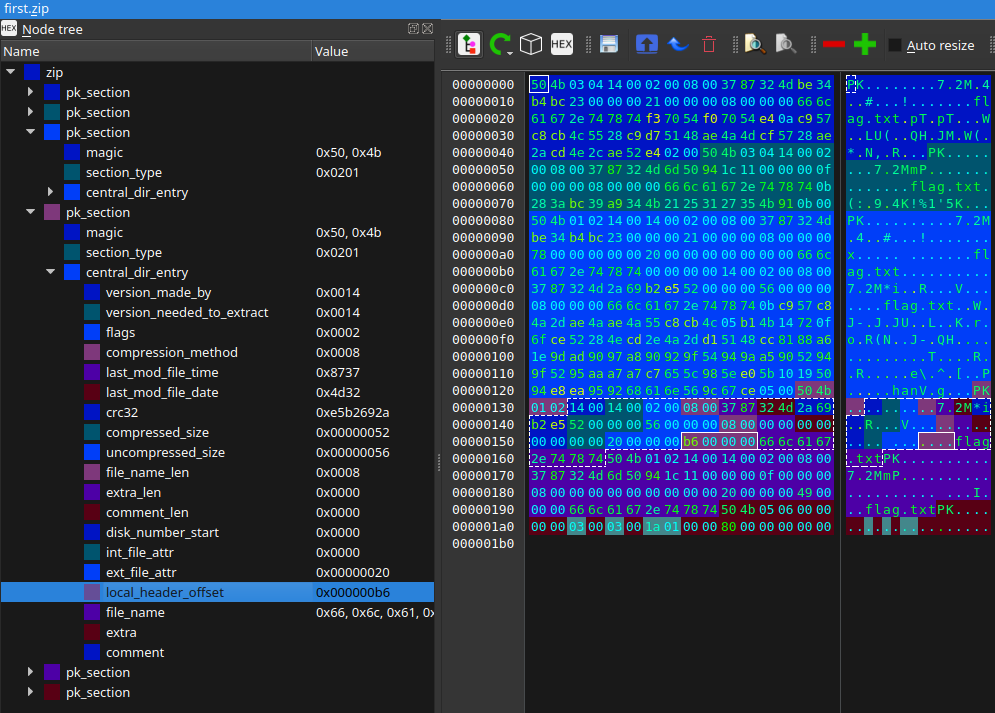
Drugi wpis CDH ma wskazuje na pozycję 0xb6, czyli początek wspomnianego wyżej komentarza. Pod tą pozycją, zamiast prawidłowego nagłówka (PK\x03\x04, czyli 50 4b 03 40) widzimy 4 bajty o wartości 0… zamieńmy je na adekwatne i zapiszmy plik:
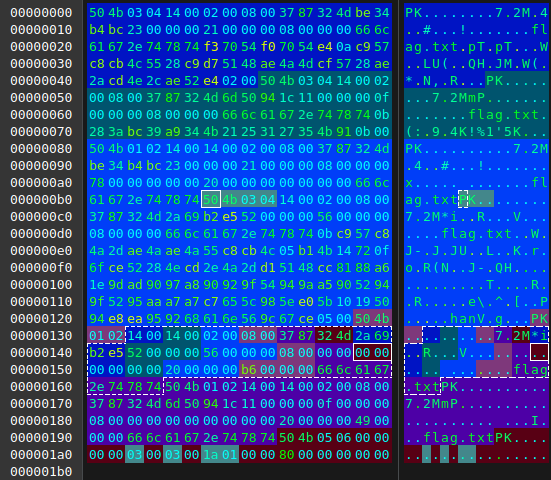
Tak przygotowany plik rozpakowuje się już prawidłowo do 3 plików o nazwie flag.txt (niektóre narzędzia dalej mogą mieć z tym problem – wtedy konieczna będzie zmiana tych nazw w hexedytorze). Zawartość dwóch z nich widzieliśmy wyżej, trzeci natomiast jest już ciekawy:
To jeszcze nie jest mój sekret, ale jesteś na dobrej drodze... 3qgpMpYPraEJda876sn7second.zip
Spróbujmy użyć otrzymany w poprzednim kroku ciąg znaków do odpakowania pliku second.zip. Bingo! Niestety, jedyne, co otrzymujemy, to plik flag.txt o zawartości “Próbuj dalej!”…
Po otwarciu pliku second.zip w Velesie widzimy, iż został on uszkodzony w bardzo podobny sposób, co first.zip. Naprawmy go więc w analogiczny sposób:
EoCDH:
central_dir_offset: 0x98
central_dir_size: 0xf6
qty_central_dir_entries_on_disk: 3
qty_central_dir_entries_total: 3
Komentarz drugiego wpisu CDH (na offsecie 0x104), podobnie jak w first.txt, naprawiamy wpisując tam prawidłowy nagłówek LFH. Zapisujemy i… widzimy, iż drugi plik dalej się nie rozpakowuje ?
Spójrzmy więc na naprawiony przed chwilą nagłówek LFH. Niestety, Veles traktuje go jako komentarz i nie potrafi sparsować jego pól – musimy zrobić to manualnie.
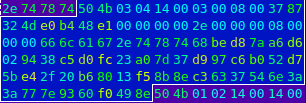
Widzimy tu po kolei:
4 bajty: 50 4b 03 04 – nagłówek (sami go przed chwilą nadpisaliśmy)
2 bajty: 14 00 – wersja
2 bajty: 03 00 – flagi
2 bajty: 08 00 – typ kompresji
2 bajty: 37 87 – czas modyfikacji
2 bajty: 32 4d – data modyfikacji
4 bajty: e0 b4 48 e1 – suma kontrolna crc32
4 bajty: 00 00 00 00 – wielkość skompresowanych danych
Zatrzymajmy się na chwilę w tym miejscu – od razu widać, iż długość danych z pewnością jest większa niż 0 bajtów. Dane zaczynają się zaraz za nazwą pliku, więc łatwo policzyć ich adekwatną wielkość:
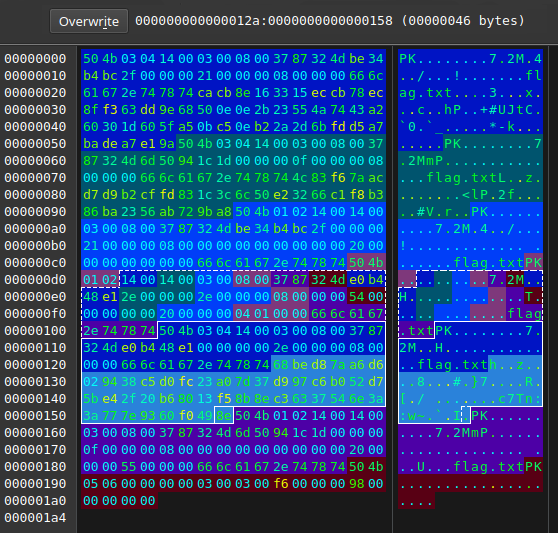
Zajmują 46 bajtów, czyli 0x2e szesnastkowo. Wpiszmy tę wartość we adekwatne pole, zapiszmy, rozpakujmy używając hasła wyciągniętego z first.zip i cieszmy się rozpakowaną flagą.
Notes
Po krótkim przeklikaniu się przez zadanie widzimy, iż mamy do czynienia z typową aplikacją – notesem pozwalającą na rejestrację nowych użytkowników, logowanie i dodawanie notatek.
Kolejną opcją jest zakładka Profile, pozwalająca na ustawienie avatara poprzez podanie URL-a do niego. Po wykonaniu tej operacji avatar dostępny jest pod adresem http://notes.ecsm2018.hack.cert.pl/static/uploads/{nazwa użytkownika}
Można więc przypuszczać, iż aplikacja łączy się z podanym URL-em, ściąga stamtąd obrazek, a następnie zapisuje na serwerze.
Skorzystajmy z podpowiedzi, która znajduje się w treści zadania:
“Ustaliliśmy iż cyberatak rozpoczął sie w ścieżce /static/templates”
Pod adresem http://notes.ecsm2018.hack.cert.pl/static/templates/ widzimy nieprzetworzony szablon frameworka Flask. Co warte uwagi, zdradza on – niewidoczną dla zwykłego użytkownika – zakładkę admin.
Niestety, próba przejścia pod ten adres jako zwykły użytkownik kończy się niepowodzeniem.
Możemy jednak obejrzeć szablon tej końcówki pod adresem http://notes.ecsm2018.hack.cert.pl/static/templates/admin.html
Widzimy tutaj kolejne 2 końcówki: /admin/grant/{{ user.login }} i /admin/revoke/{{ user.login }}
Po nazwie można domyślić się, iż końcówka /admin/grant/{{ user.login }} nadaje uprawnienia administratora podanemu użytkownikowi. Ponieważ jest to zwykły link, następuje to przy pomocy metody HTTP GET.
Łącząc powyższe na myśl przychodzi zastosowanie ataku Server Side Request Forgery (https://pl.wikipedia.org/wiki/Server-side_request_forgery).
Spróbujmy dodać jako avatar adres http://127.0.0.1/admin/grant/{nazwa użytkownika} – wtedy serwer wykona sam do siebie zapytanie zapytanie dające dostęp naszemu użytkownikowi uprawnienia administratora. Po tym wszystkim możemy przeczytać flagę pod – już działającą – końcówką http://notes.ecsm2018.hack.cert.pl/admin
crackme

Po szybkim rzucie oka na kod funkcji main staje się jasne, iż całe sprawdzanie flagi odbywa się w funkcji pod adresem 0x1180. Po podejrzeniu tej funkcji w IDA czeka nas jednak niespodzianka…

Wygląda to na częściowo zaszyfrowany kod. Wywołanie następuje jednak przed jakimkolwiek rozszyfrowaniem, więc przynajmniej początek tej funkcji powinien zawierać prawidłowy kod. Na szczęście IDA pozwala wymusić deasemblację, co pozwala przeczytać początek funkcji sprawdzającej.

pierwsze, co widzimy, to wczytanie trzech znaków (można to poznać m.in. po sygnaturze funkcji std::operator>> – pierwszy argument jest typu char) do bufora na stosie (pod adresem esp+0x60).

Dalej następuje liczenie tajemniczo wyglądającej funkcji skrótu (dla dociekliwych – jest to SipHash, ale wiedza ta nie jest niezbędna do zrozumienia przedstawionego rozwiązania).

Dalej następuje wywołanie funkcji sub_D80. W zależności od jej wyniku funkcja albo kończy działanie zwracając 0 (co, jak pamiętamy z analizy funkcji main, skutkuje informacją o niepowodzeniu), albo wykonuje skok dalej.
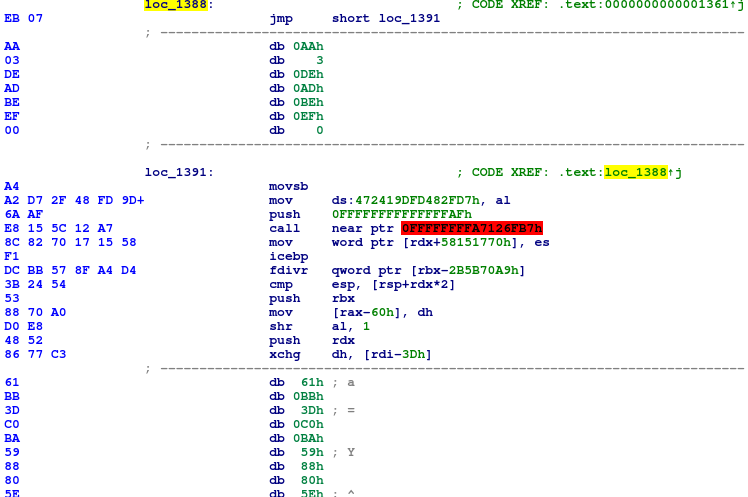
Dalsza część kodu jest już zaszyfrowana. Dzięki temu wiemy, bez głębszej analizy, iż funkcja sub_D80 robi dwie rzeczy: sprawdza, czy pierwsze 3 znaki wprowadzonej flagi się zgadzają oraz rozszyfrowuje dalszą część kodu. Analizę sub_D80 na razie pominiemy – ponieważ program przyjmuje flagę, możemy skorzystać z tego, iż znamy jej format (ecsm2018{tresc_flagi}) a co za tym idzie – pierwsze 9 znaków.
Odpalmy zatem nasz program pod debuggerem i ustawmy breakpoint na adresie 0x1388 (ponieważ program jest skompilowane jako Position Independent Executable, musimy dodać do tej wartości adres bazowy – w przypadku gdb domyślnie jest to 0x555555554000), podajmy prawidłowy początek flagi i zobaczmy rozszyfrowany kod. Drobna uwaga – nie możemy postawić breakpointa w zaszyfrowanym kodzie. Jest tak, ponieważ debugger, ustawiając breakpoint, tak naprawdę modyfikuje kod programu w tym miejscu, przez co procedura deszyfrująca będzie działała na zupełnie innych danych. Szerzej opisane jest to w tym artykule: https://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints
Wygląda to niemal identycznie jak poprzednia część – wczytanie 3 znaków i obliczenie hasha – tym jednak z innymi stałymi. Mamy więc dwie możliwości – mozolne odwracanie, przepisywanie i łamanie hasha albo znalezienie czegoś sprytniejszego. Wybierzmy opcję dla leniwych i przyjrzyjmy się wspomnianej wyżej funkcji sprawdzająco – deszyfrującej (sub_D80).
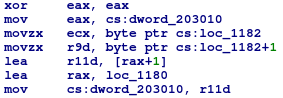
Na samym początku następuje inkrementacja zmiennej dword_203010 (jej wartość początkowa to 2). Oznacza to, iż pod tym adresem zapisana będzie informacja o tym, ile 3-znakowych fragmentów udało się dotychczas rozszyfrować.
Na końcu funkcji znajdujemy natomiast następujący kod:
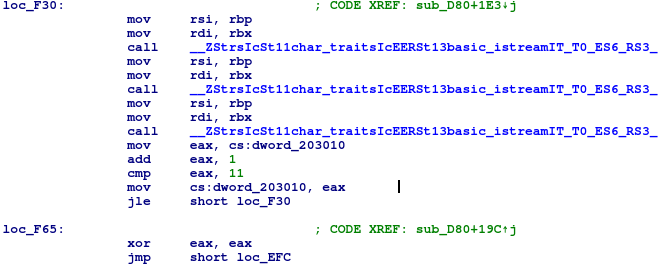
Wywołuje się on w momencie niepowodzenia funkcji i odpowiada za doczytanie reszty wejścia z bufora. W tym momencie w zmiennej dword_203010 mamy dokładną informację na temat liczby poprawnych kawałków w momencie wczytania pierwszego niepoprawnego. jeżeli więc zmodyfikujemy kod programu tak, żeby w tym miejscu kończył działanie, zwracając wartość dword_203010 jako kod błędu, będziemy mogli w prosty sposób odnaleźć flagę sprawdzając po kolei wszystkie 3-znakowe możliwości.
Łatkę nałożymy w miejscu instrukcji “add eax, 1”. Kod, który zastosujemy, będzie następujący:
W kodzie maszynowym: 48 89 c7 b8 3c 00 00 00 0f 05
Zmienioną binarkę zapiszmy jako patched. Teraz wystarczy prostu kod w pythonie, który po kilkunastu – kilkudziesięciu minutach zwróci prawie całą flagę (oprócz ostatniego 3-znakowego kawałka – ten można znaleźć porównując wyjście oryginalnego programu z ciągiem “OK!”
outsourz3d
Treść zadania sugeruje, iż będziemy musieli znaleźć rozwiązanie do co najmniej kilku plików wykonywalnych. Weźmy pod lupę jeden z nich:

Na początek inicjalizacja zmiennych lokalnych różnymi wartościami oraz sprawdzenie, czy program został uruchomiony dokładnie z jednym argumentem – czyli polecenie należy podać właśnie jako argument linii poleceń.
Następnie seria 32 bardzo podobnych testów:
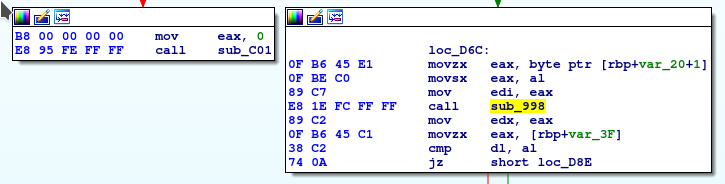

Każdy test sprawdza dokładnie jeden znak i opiera się na prostych operacjach (alternatywa wykluczająca, dodawanie, odejmowanie, rotacja bitowa itp.).
Zadanie to jest idealnym przypadkiem, który można rozwiązać przy użyciu frameworka do wykonania symbolicznego angr (https://angr.io/). W tym przypadku jedyne, co musimy zrobić, to podać angrowi adres, pod którym ostatecznie chcemy się znaleźć. Do tego pomocne będzie narzędzie YARA, która pozwoli gwałtownie znaleźć odpowiedni wzorzec.

Dobrym wzorcem, powtarzającym się we wszystkich binarkach w zadaniu, jest ciąg instrukcji
call ??? lea rdi, ??? call ???regułę YARA dla tych instrukcji możemy przedstawić w ten sposób:
E8 [4] 48 8d 3d [4] E8Całe rozwiązanie zamyka się w prostym skrypcie pythona:
Przeszukanie
W zadaniu uzyskujemy dostęp do zaawansowanej wyszukiwarki wraz z kodem. Wyszukiwarka oparta jest o składnię Apache Lucene (http://lucene.apache.org/), z którą warto zapoznać się dla lepszego zrozumienia rozwiązania.
W uproszczeniu składnia Lucene wygląda następująco:
<obiekt>:<wartość>
przykładowo:
name: “Jan Kowalski”
Spójrzmy więc jak interpretowane są oba pola przez wyszukiwarkę:
Jak widać, lewa strona wyrażenia dzielona jest przez znak kropki, a następnie budowane jest wyrażenie pythona dzięki mechanizmu refleksji, przy czym jedyny obiekt, do którego mamy dostęp, to model BadGuy.
Sprawdźmy więc w praktyce – fraza “id: 5” powinna zwrócić obiekt BadGuy z id równym 5:

W pliku app.py widzimy, iż flaga znajduje się w konfiguracji Flaska:
Skoro możemy niemal dowolnie korzystać z mechanizmu refleksji, spróbujmy zastosować – popularną na zawodach CTF – technikę ucieczki z piaskownicy pythona:
https://lbarman.ch/blog/pyjail/
http://wapiflapi.github.io/2013/04/22/plaidctf-pyjail-story-of-pythons-escape/
https://blog.osiris.cyber.nyu.edu/ctf/exploitation%20techniques/2012/10/26/escaping-python-sandboxes/
W tym celu musimy znaleźć odpowiednią ścieżkę od obiektu BadGuy do konfiguracji. Po kilku ręcznych próbach okazuje się to nietrywialne, więc wspomożemy się tu skryptem. Najlepiej będzie zmodyfikować oryginalną aplikację. Pierwsze, co zrobimy, to ustawienie fałszywej flagi (żeby wiedzieć, czego szukamy):
Następnie dodajmy końcówkę, która przeszukując odwołania DFS-em znajdzie odpowiednią ścieżkę:
Po odpaleniu zmodyfikowanej aplikacji i odwiedzeniu końcówki /find błyskawicznie otrzymujemy prawidłową ścieżkę:
PATH: .query.session.app.__dict__I rzeczywiście, pod BadGuy.query.session.app.__dict__ znajduje się słownik, zawierający konfigurację (a, co za tym idzie, flagę) jako jeden ze swoich elementów. Pozostaje teraz jedynie ją wyciągnąć.
Jako wyjście otrzymujemy jedynie obiekty BadGuy, więc będziemy musieli zastosować technikę podobną jak przy atakach Blind SQL Injection. Oczywistym wydaje się zastosowanie wildcardów.
Niestety, są one zablokowane. Możemy jednak łatwo zasymulować je przez wyszukiwanie przedziałów.
Bardzo pomocny staje się w tym poniższy kawałek kodu:
Dzięki temu wiemy, iż przeszukiwane pola (inne niż te typu InstrumentedAttribute, czyli pochodzące z bazy danych) zostaną skonwertowane na postać szesnastkową i będą zawierały jedynie znaki 0-9 i a-b. Łącząc wszystko powyższe zamykamy rozwiązanie w poniższym skrypcie:
















