
W dobie rozwoju pojazdów autonomicznych znaczenie semantycznej segmentacji jest nie do przecenienia. Rozpoznawanie typów obiektów znajdujących się wokół pojazdu to najważniejszy element dla zachowania najwyższych standardów bezpieczeństwa.
Semantyczna segmentacja, na podstawie danych z kamery potrafi skategoryzować widziany świat. Im robi to szybciej, tym szybciej da się zareagować na nadchodzące zmiany. Przy dużej zmienności obserwowanej sceny (np. szybka jazda samochodem) prędkość działania jest niezmiernie istotna. Praca o modelu FasterSeg opisuje model, który dla klatki w standardzie 720p jest w stanie pracować z prędkością 318 FPS na karcie NVidia GTX 1080Ti, osiągając przy tym bardzo dobre wyniki.
W tym poście opiszę podejście i założenia w pracy
"FasterSeg: Searching for FASTER real-time semantic segmentation".
(wersja pierwsza: grudzień 2019, wersja druga: styczeń 2020)
NAS
Znalezienie modelu, który będzie skuteczny a zarazem wydajny to nie jest trywialny temat. Generalnie naukowcy prezentują tutaj dwa podejścia: manualne poszukiwania architektur sieci, które podołają tym wyzwaniom oraz algorytmy automatycznego szukania architektur sieci oceniające uzyskiwane rezultaty i maksymalizujące pożądane cechy.
Istniejące algorytmy poszukujące architektur sieci adresowały do tej pory jedynie część hiperparametrów sieci takich jak głębokość sieci, długość warstw, rozdzielczość... Porównujac powstałe w ten sposób modele do architektur sieci stworzonych manualnie przez ludzi widzimy, iż nie wszystkie aspekty są automatyzowane. Niezaadresowane są poszukiwania architektów wielogałęziowych. Jako jeden ze swoich elementów, praca "FasterSeg: Searching for FASTER real-time semantic segmentation" adresuje ten brak.
Autorzy proponują początkową architekturę sieci złożoną z wielu gałęzi. Na każdym poziomie z danego węzła wychodzą dwie gałęzi, które tworzą drzewo o zadanej długości L. Rozgałęzienia adresują problem wyszukiwania obiektów w różnych rozdzielczościach, gdyż jedna z gałęzi transformowana jest do kolejnego zagłębienia rozdzielczości (downsample). Każdy węzeł złożony jest z precyzyjnie wybranego zestawu operacji konwolucji (ala moduł w sieci typu Inception).
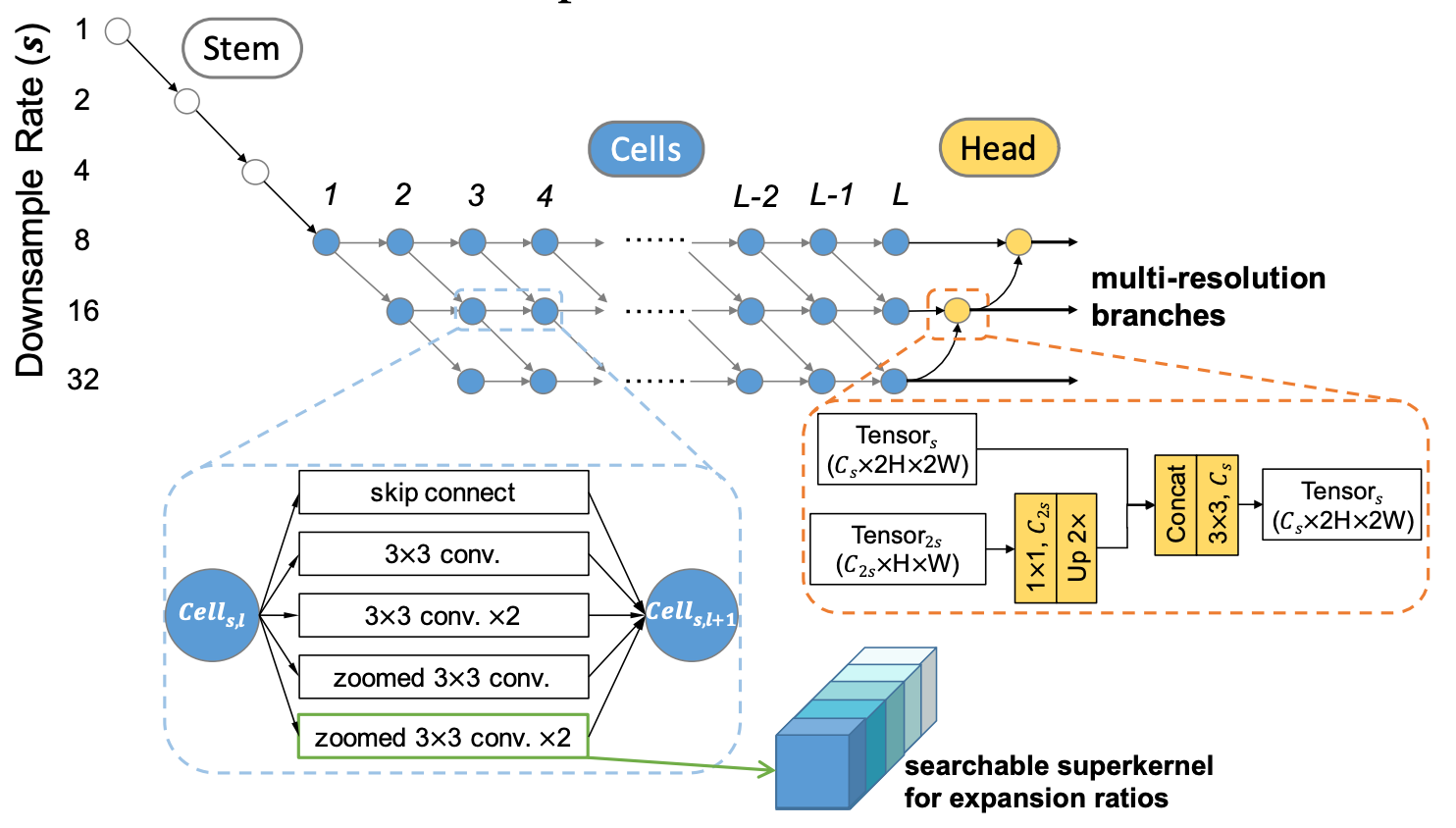 źródło: https://arxiv.org/pdf/1912.10917.pdf
źródło: https://arxiv.org/pdf/1912.10917.pdfCelem zadania poszukiwania architektury jest nauczenie się agregowania cech z różnych poziomów rozdzielczości obrazu. Autorzy wskazują, iż zadana architektura pokrywa inne istniejące rozwiązania w jednym ze swoich wariantów:
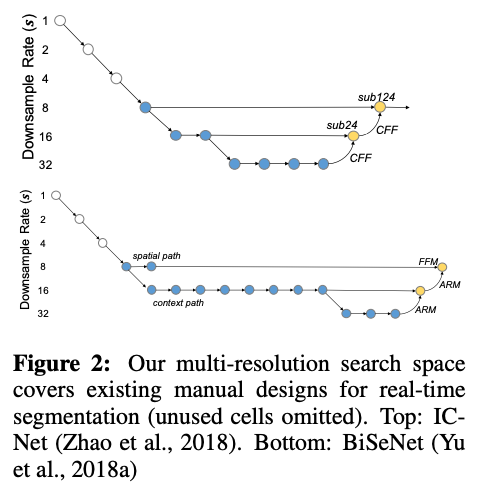 źródło: https://arxiv.org/pdf/1912.10917.pdf
źródło: https://arxiv.org/pdf/1912.10917.pdfJednym z elementów poszukiwania jest też zbalansowanie dokładności sieci i prędkości późniejszego użycia. Dlatego właśnie oprócz optymalizacji samego rezultatu jakościowego autorzy optymalizują funkcję czasu wywołania, która wspierana jest przez charakterystyki czasów wykonywania danych rodzajów operacji na zadanym sprzęcie (szczegóły techniczne w samej pracy, rodział 3.2). Dodatkowo wprowadzona regularyzacja dla danych typów operacji, sprawia, iż dokładność sieci nie jest degradowana przez zbyt duże dążenie do samej optymalizacji czasu wykonania.
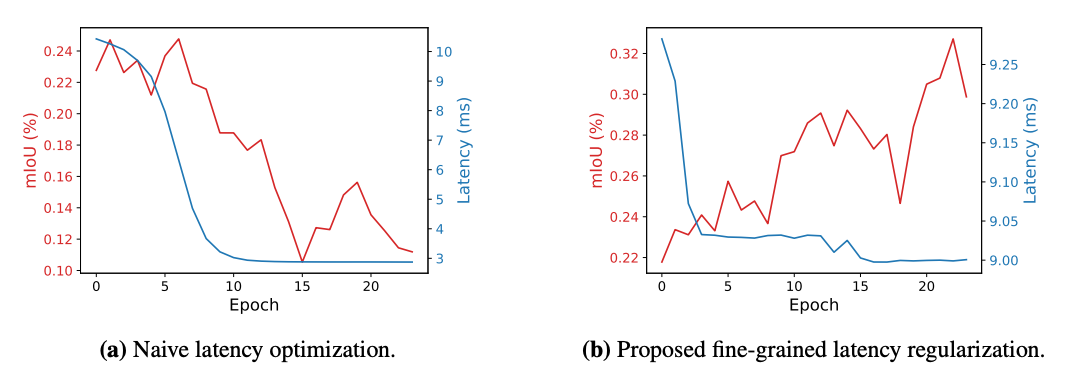 źródło: https://arxiv.org/pdf/1912.10917.pdf
źródło: https://arxiv.org/pdf/1912.10917.pdfTransfer wiedzy
Trening zakłada przeprowadzenie także procesu optymalizacji rozmiarów sieci przez transfer wiedzy (knowledge distillation). Symultanicznie trenowane są dwie sieci: nauczyciel i uczeń. Wprowadzona jest także składowa funkcji kosztu adresująca rozbieżności rozkładów prawdopodobieństwa uzyskiwanych map segmentacyjnych.
Praca opisuje też strategię wyboru ostatecznych rozgałęzień które pozostawione są w sieci wynikowej. Podczas procesu poszukiwania architektury trenowane są trzy parametry: współczynnik korzystania z węzłów poprzednich, współczynniki używania gałęzi z danym typem konwolucji oraz współczynniki liczności kanałów warstw konwolucji. Do sieci wynikowej wybierane są ścieżki o najwyższych wagach.
Rezultaty
Wyniki dokładności i szybkości prezentowango podejścia w porównaniu do innych modeli kształtuje się następująco:
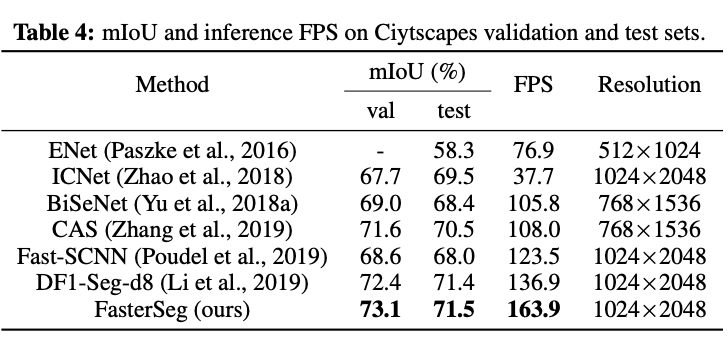 wyniki dla zbioru: Cityscapes, źródło: https://arxiv.org/pdf/1912.10917.pdf
wyniki dla zbioru: Cityscapes, źródło: https://arxiv.org/pdf/1912.10917.pdfwyniki prędkości na mniejszych datasetach są jeszcze bardziej spektakularne:
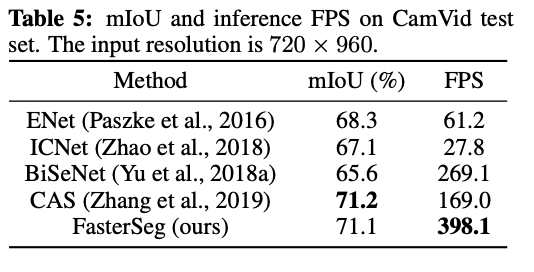 źródło: https://arxiv.org/pdf/1912.10917.pdf
źródło: https://arxiv.org/pdf/1912.10917.pdf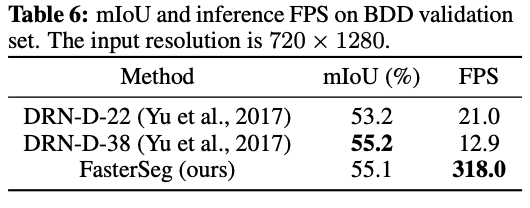 źródło: https://arxiv.org/pdf/1912.10917.pdf
źródło: https://arxiv.org/pdf/1912.10917.pdfPotencjał
Wydaje mi się, iż wspomniany model jest idealny do użycia w autonomicznych pojazdach. Prędkość działania jest imponująca. Co więcej, duża szansa na dodatkowe przyspieszenie działania modelu leży w zastosowaniu kwantyzacji.
Należy pamiętać jednak, iż nie jest to w tej chwili najdokładniejszy model i jest duża ilość wolniejszych algorytmów, które radzą sobie o wiele dokładniej.
Linki
Praca:
Kod z implementacją:
Papers with code: Real-time semantic segmentation @Cityscapes:
Papers with code: Semantic segmentation @Cityscapes: