Google to duży gracz w gwałtownie rozwijającym się świecie sztucznej inteligencji. Niedawno korporacja ogłosiła, iż oferuje nagrody „łowcom podatności”, którzy znajdą luki w jej oprogramowaniu generatywnej sztucznej inteligencji.
Podobnie jak Microsoft, Amazon i inni rywale, Google integruje możliwości sztucznej inteligencji w coraz szerszej gamie swoich produktów i usług. Ostatnio przedstawiono nowe funkcje oparte na AI w oprogramowaniu Google Maps, ulepszające wskazówki dojazdu i wyniki wyszukiwania oraz wprowadzające immersyjną nawigację.
Teraz Google podejmuje kolejny krok, aby zapewnić większe bezpieczeństwo systemu opartego na sztucznej inteligencji, które wprowadza do swojej oferty. Firma rozszerza swój program nagród za luki w zabezpieczeniach (Vulnerability Rewards Program) o scenariusze ataków specyficzne dla generatywnej sztucznej inteligencji.
Jednocześnie Google poszerza zakres prac nad bezpieczeństwem systemu open source, aby zwiększyć przejrzystość bezpieczeństwa łańcucha dostaw sztucznej inteligencji.
Przyszłościowe podejście?
Dzieje się tak w czasie, gdy podekscytowanie wokół nowych algorytmów i możliwości AI, które rozpoczęło się prawie rok temu z Chatem GPT, spotyka się z równym poziomem obaw o bezpieczeństwo i prywatność.
„Generatywna sztuczna inteligencja rodzi nowe i inne obawy niż tradycyjne bezpieczeństwo cyfrowe, takie jak możliwość nieuczciwego uprzedzenia, manipulacji modelami lub błędnej interpretacji danych (halucynacje)” – mówi Laurie Richardson, wiceprezes ds. zaufania i bezpieczeństwa oraz Royal Hansen, wiceprezes ds. prywatności w Google. „W miarę jak przez cały czas włączamy generatywną sztuczną inteligencję do większej liczby produktów i funkcji, nasze zespoły ds. zaufania i bezpieczeństwa wykorzystują dziesięciolecia doświadczenia i przyjmują kompleksowe podejście, aby lepiej przewidywać i testować potencjalne zagrożenia”.
Richardson i Hansen zauważyli również, iż korzystanie z pomocy zewnętrznych badaczy bezpieczeństwa to kolejny sposób na znalezienie i naprawienie wad w generatywnych produktach AI, co wiąże się z rozwojem ich programu Bug Bounty i wydaniem wytycznych dla badaczy bezpieczeństwa.
„Oczekujemy, iż zachęci to odkrywców podatności do zgłaszania większej liczby błędów i przyspieszy osiągnięcie celu, jakim jest bezpieczniejsza generatywna sztuczna inteligencja” – napisali.
Jakich zagrożeń i podatności spodziewa się Google?
Program nagród za błędy AI obejmuje szereg kategorii, na których mogą skupić się zewnętrzni badacze, od ataków mających na celu wykorzystanie kontradyktoryjnych podpowiedzi w celu wpłynięcia na zachowanie modelu AI oraz manipulowanie modelami, po ataki mające na celu kradzież modeli i potajemną zmianę ich zachowania (tzw. złośliwe uczenie maszynowe).
„Naszym celem jest ułatwienie testowania tradycyjnych luk w zabezpieczeniach, a także zagrożeń specyficznych dla systemów sztucznej inteligencji” – napisali w notatce Eduardo Vela, Jan Keller i Ryan Rinaldi, członkowie Google Engineering.
Dodali, iż kwota przyznana badaczom zależy od powagi scenariusza ataku i rodzaju dotkniętego celu.
W ubiegłym roku program VRP wypłacił ponad 12 milionów dolarów w postaci nagród za znalezione błędy.
Google nie jest pierwszym podmiotem, który zwraca się do zewnętrznych ekspertów, aby znaleźć luki w swoich narzędziach AI. Na początku tego miesiąca Microsoft zaprezentował podobny program, w ramach którego badacze będą dostawać od 2000 do 15 000 dolarów za błędy wykryte w wyszukiwarkach Bing opartych na sztucznej inteligencji, w tym Bing Chat, Bing Chat for Enterprise i Bing Image Creator.
W kwietniu OpenAI ogłosiło program nagród za błędy we współpracy z Bugcrowd, który oferuje programy crowdsourcingowe.
Nowe podejście do AI Security
Nagroda za błąd jest jednym z szeregu innych kroków podjętych przez Google w celu zabezpieczenia generatywnych produktów AI, które obejmują chatbota Bard i technologię rozpoznawania obrazu Lens. Podobnie jak Microsoft, Google również integruje sztuczną inteligencję w całym swoim portfolio, od Gmaila i wyszukiwarki po Google Docs i – jak wspomniano – Mapy.
Na początku tego roku Google wprowadziło funkcję AI Red Teaming, aby ulepszyć wdrażanie platformy Secure AI Framework (SAIF).
„Pierwszą zasadą SAIF jest zapewnienie, iż ekosystem sztucznej inteligencji ma solidne podstawy bezpieczeństwa, co oznacza zabezpieczenie kluczowych elementów łańcucha dostaw, które umożliwiają uczenie maszynowe (ML) przed zagrożeniami, takimi jak manipulowanie modelami, zatruwanie danych i produkcja szkodliwych treści” – napisali Richardson i Hansen.
Oprócz ogłoszenia oferty nagród za błędy związane ze sztuczną inteligencją Google oświadczyło w tym tygodniu również, iż intensyfikuje współpracę z fundacją Open Source Security Foundation oraz iż własny zespół ds. bezpieczeństwa systemu Open Source zwiększa bezpieczeństwo łańcucha dostaw sztucznej inteligencji.
Podano, iż SLSA obejmuje standardy i mechanizmy kontrolne zapewniające odporność łańcuchów dostaw, a Sigstore służy do sprawdzania, czy oprogramowanie w łańcuchu dostaw jest tym, za co się podaje. Google udostępnia pierwsze prototypy do podpisywania modeli w Sigstore i weryfikacji atestów dzięki SLSA.
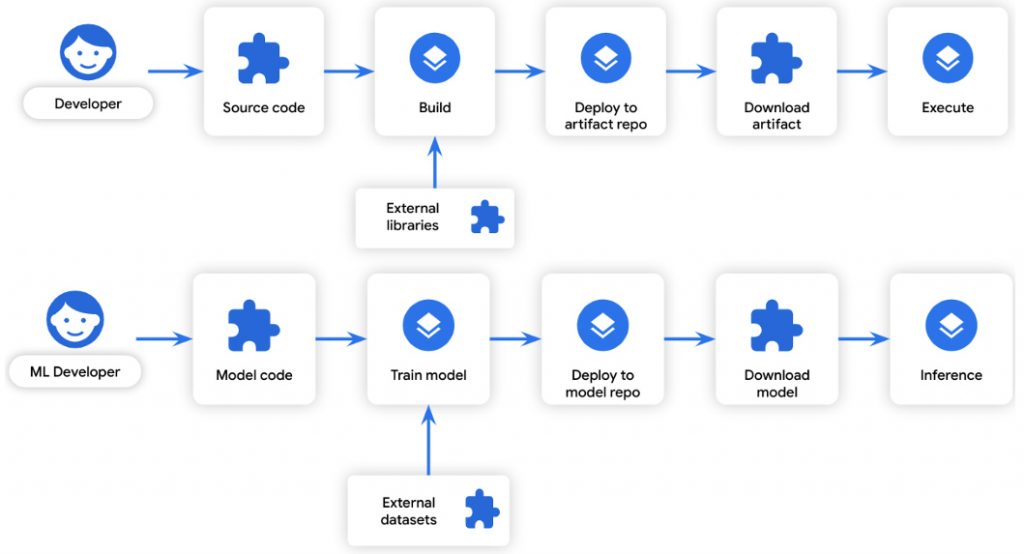
Firma wierzy, iż przejrzystość całego cyklu życia systemu pomoże również zabezpieczyć modele uczenia maszynowego, ponieważ opracowywanie ich odbywa się według podobnego cyklu życia, jak w przypadku standardowego oprogramowania, co widzimy na schemacie poniżej:
 Źródło: security.googleblog.com
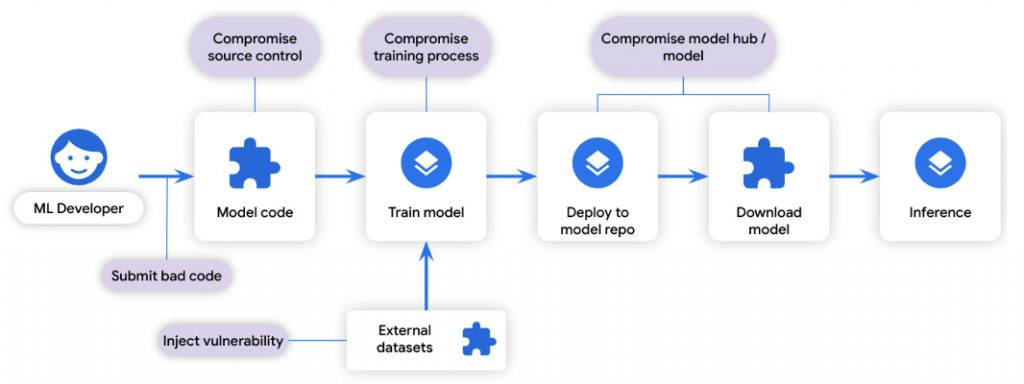
Źródło: security.googleblog.comProces uczenia ML można traktować jako „kompilację”: przekształca niektóre dane wejściowe w pewne dane wyjściowe. Podobnie dane szkoleniowe można traktować jako „zależność”: są to dane wykorzystywane podczas procesu kompilacji. Ze względu na podobieństwo cykli rozwoju oprogramowania, te same wektory ataków na łańcuch dostaw oprogramowania, które zagrażają rozwojowi oprogramowania, dotyczą również tworzenia modeli:
 Źródło: security.googleblog.com
Źródło: security.googleblog.com„Bazując na podobieństwach w cyklu życia systemu i wektorach zagrożeń, proponujemy zastosowanie tych samych rozwiązań łańcucha dostaw z modeli SLSA i Sigstore do ML, aby w podobny sposób chronić je przed atakami w łańcuchu dostaw”.