W środę 9 października użytkownicy platformy Microsoft Azure na całym świecie doświadczyli poważnych zakłóceń. Wiele usług stało się niedostępnych, a administratorzy nie mogli choćby zalogować się do portalu zarządzającego – wszystko z powodu awarii jednego z kluczowych komponentów infrastruktury. Ten incydent pokazał nie tylko, jak bardzo jesteśmy zależni od chmurowych gigantów, ale też jak kruche mogą być warstwy pośrednie w architekturze sieciowej.
Gdzie nastąpił błąd i jakie miał skutki?
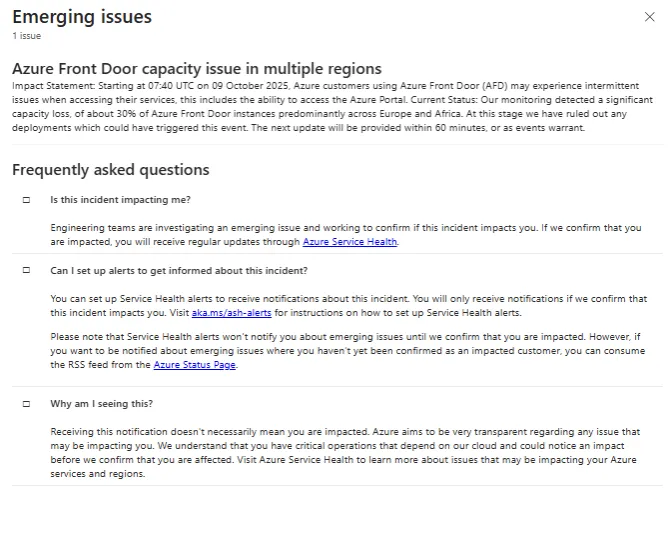
Uszkodzenie dotyczyło usługi Azure Front Door (AFD) – systemu Microsoftu, pełniącego rolę globalnej sieci dostarczania treści (CDN) oraz bramy ruchu internetowego do aplikacji chmurowych. Według danych firmy awaria spowodowała istotną utratę wydajności – choćby do 30% instancji AFD.
W wyniku incydentu użytkownicy z regionów takich jak Europa Północna, Europa Zachodnia, Francja Centralna oraz części Afryki zgłaszali problemy z dostępnością aplikacji, usług API, połączeń sieciowych, a także, iż nie mogą wejść na portal Azure w celu zarządzania zasobami.
Obszar awarii nie ograniczył się tylko do operatorów lokalnych – z konsekwencjami zmagały się globalne firmy bazujące na Azure, aplikacje mobilne, serwisy internetowe, systemy API i back-endy wspierane przez tę platformę.
Dlaczego AFD jest kluczowy?
Azure Front Door działa jako „frontowa brama” ruchu internetowego do wielu usług chmurowych – to warstwa, która przyjmuje zapytania od klientów, optymalizuje trasę ruchu, zapewnia cache’owanie treści, a także wspiera SSL/TLS, balansowanie obciążenia, reguły routingu oraz ochronę DDoS. Kiedy AFD zawodzi, choćby jeżeli zaplecze (backend) działa poprawnie, ruch nie może dotrzeć do usług – nic się nie wyświetli, konfiguracje API nie zostaną wywołane, usługi będą niedostępne. W skrócie: uszkodzenie tej warstwy skutkuje „zamknięciem frontu” dla aplikacji.
Reakcja Microsoftu, czyli co się działo za kulisami
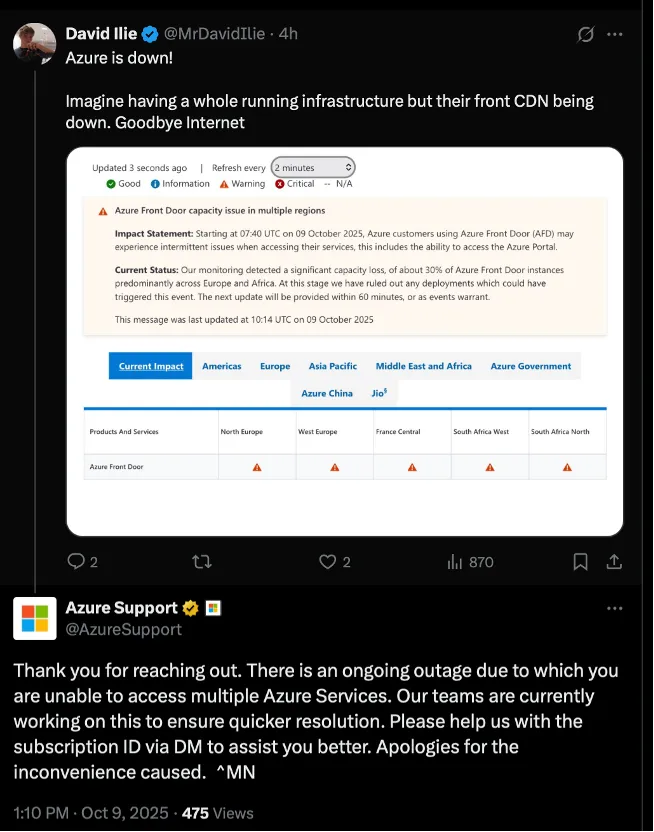
Microsoft gwałtownie zareagował, potwierdzając za pośrednictwem swojego wsparcia (m.in. na Twitterze) wystąpienie incydentu, i poinformował, iż zespoły inżynierskie pracują nad jego usunięciem.
W komunikacie firmy znalazła się informacja, iż awaria nie została wywołana przez nowe wdrożenia (deployments), co sugeruje, iż problem był głębszy – prawdopodobnie związany z infrastrukturą, skalowaniem usług albo wewnętrzną awarią mechanizmów. Microsoft zobowiązał się przekazywać aktualizacje co ok. 60 minut lub w miarę rozwoju sytuacji, a także skontaktować się indywidualnie z klientami w celu zebrania szczegółów dotyczących ich subskrypcji i wpływu incydentu.
Społeczność reaguje – frustracja i alarmy
Administratorzy, deweloperzy i użytkownicy natychmiast zauważyli problem – na platformach społecznościowych pojawiło się wiele głosów z żądaniem uaktualnienia statusu i informacji o przyczynach. Najbardziej krytycznym elementem było to, iż sam portal Azure stał się niedostępny – co oznaczało, iż wielu administratorów nie mogło ani sprawdzić stanu usług, ani podjąć działań awaryjnych.
Wnioski dla użytkowników chmurowych
- Nawet komponent pośredniczący (CDN, brama ruchu) może stać się wąskim gardłem całej infrastruktury – jego awaria skutkuje globalnymi problemami.
- Firmy muszą planować architekturę z redundancją – np. alternatywne ścieżki ruchu, fallbacki, mechanizmy zapasowe poza jednym punktem awarii.
- Monitorowanie i alerty na poziomie warstw frontowych są równie istotne jak te dotyczące backendów.
- Procedury komunikacji z dostawcą chmury oraz informowania własnych użytkowników muszą być przygotowane z wyprzedzeniem – czas reakcji ma ogromne znaczenie w ograniczaniu szkód.