Elastic - przykładowe wdrożenie i integracja z Kibana
Logi aplikacji, różnych usług, czy też samego systemu operacyjnego są podstawowym i absolutnie kluczowym źródłem pozwalającym na weryfikację działania danego komponentu. Dzięki logom możemy wykryć różne anomalie (takie jak spadki wydajności, błędy w logice aplikacji, jak również ewentualne ślady złośliwej aktywności) i przyczyny zgłoszonych np. przez klienta problemów. w tej chwili dostępne są odpowiednie rozwiązania (często bardzo kosztowne, ale jednocześnie skuteczne), które automatycznie są w stanie wykryć różne problemy (w tym te powiązane z bezpieczeństwem) z naszymi usługami i raportować o nich poprzez powiadomienia czy komunikaty na czytelnych panelach. Nie oznacza to oczywiście, iż logi stają się reliktem przeszłości.
Logi w zdecydowanej większości przypadków zapisywane są do plików tekstowych (zwykle z rozszerzeniem .log) przechowywanych lokalnie na serwerze hostującym daną usługę. Dzięki temu dostęp do samych logów nie powinien być wyzwaniem dla osób odpowiadających za utrzymanie systemu. Ważne jest również zadbanie o sensowną rotację (usuwanie/archiwizowanie starszych wpisów), aby nie nastąpiła sytuacja wykorzystania całej przestrzeni dyskowej na logi. W tym celu stosuje się m.in. narzędzie logrotate.
W praktyce analiza logów niestety kojarzy się raczej negatywnie. Dla rozbudowanych aplikacji, które niejednokrotnie są uruchomione na kilku serwerach w ramach klastra, odnalezienie wpisu powiązane z konkretnym problemem jest zwyczajnie utrudnione. Zresztą bez znajomości składni narzędzi typu grep czy awk choćby przeszukanie jednego pliku może być skomplikowane, a nie zawsze do otwarcia logu można wykorzystać edytory tekstu, bo plik może zajmować kilkadziesiąt gigabajtów. Już nie wspominając o sytuacjach, gdzie aplikacja uruchomiona jest na zewnętrznym środowisku, do którego dostęp SSH jest znacznie ograniczony – prośby do administratorów po stronie klienta o przeszukanie czy udostępnienie logów są wtedy uzasadnione, ale mało komfortowe dla obu stron.
Elastic Stack
Rozwiązanie tych problemów stanowi Elastic Stack (poprzednio określany jako ELK stack i ta nazwa jest bardziej rozpowszechniona). Współcześnie to niemal standardowe narzędzie do agregacji logów w każdym większym środowisku i z tego powodu warto posiadać odpowiednią wiedzę o dostępnych w nim funkcjach i sposobach konfiguracji.
Uruchomiona instancja Elastic Stack powinna stać centralnym miejscem agregacji logów pochodzących z różnych usług i aplikacji. Dzięki odpowiednim regułom opartym na rolach (dostęp do indeksów i zarządzania Elasticsearch) można zapewnić uprawnienia dla różnych działów czy zespołów projektowych – aby odczyt logów danego projektu mogły wykonać wyłącznie wskazane osoby.
Elastic Stack składa się z trzech komponentów: Elasticsearch, Logstash i Kibana. Nietrudno zauważyć, iż pierwsze litery tych nazw złożyły się w określenie ELK. Ich zastosowanie można bardzo łatwo określić i zapamiętać.
Elasticsearch jest rodzajem bazy danych, w której dane przechowywane są w formacie JSON. Umożliwia tzw. wyszukiwanie pełnotekstowe i z tego powodu znalazł szerokie zastosowanie w różnych aplikacjach, często powiązanych z e-commerce – nie jest to narzędzie przeznaczone wyłącznie do „obsługi” logów. Do obsługi Elasticsearch (operacje na danych, administracja instancją) wykorzystywany jest standardowy protokół HTTP, co znacznie ułatwia przeprowadzenie różnych integracji. W ostatnim czasie wprowadzono szereg zabezpieczeń (X-Pack), które zresztą są domyślnie włączone.
Logstash umożliwia „dostosowane” logów do formatu przyjaznego dla człowieka, jak również bardziej zgodnego z zastosowaniem JSON. Konfiguracja odpowiednich reguł bywa problematyczna i zwykle wymaga wielu testów, bo nie każda aplikacja zapisuje logi w sensowny sposób.
Kibana z kolei stanowi graficzny interfejs do prezentowania danych zgromadzonych w Elasticsearch, ale pozwala też na całkiem wygodną administrację tą usługą.
Oprócz tego wymienić należy Filebeat, który odpowiada za przekazywanie logów do Logstash bądź też bezpośrednio do Elasticsearch – to jednak nie jest najlepsza opcja i zdecydowanie warto zachować porządek poprzez zastosowanie Logstash.
Elasticsearch można uruchomić w ramach natywnego klastra, co w dość łatwy sposób pozwoli na zachowanie high availability (przy założeniu wykorzystania trzech serwerów; sam klaster zadziała przy połączeniu dwóch maszyn). Kibana i Logstash nie posiadają żadnych wewnętrznych zależności. Konfiguracja Kibana przechowywana jest w samym Elaticsearch oraz na serwerach, więc wystarczy zastosować prosty load balacing. Logstash można uruchomić na dowolnej ilości serwerów – odpowiada wyłącznie za „modyfikację” zawartości i przesłanie jej do Elasticsearch.
Kibana raczej nie powinna być dostępna bezpośrednio. Warto uruchomić podstawowe reverse proxy przykładowo z użyciem nginx. Pozwoli to m.in. na zastosowanie własnej domeny i prawidłową obsługę protokołu HTTPS.
Co bardzo ważne, wszystkie wymienione rozwiązania zadziałają zarówno w systemach Linux, jak i Windows czy macOS. Proces instalacji jest oczywiście odmienny, natomiast konfiguracja w każdym przypadku będzie analogiczna.
Elasticseach wymaga minimum 8 GB pamięci operacyjnej, przy czym zalecane jest 16 GB. Do przechowywania danych najlepiej wykorzystać osobny dysk (lub kilka dysków połączonych LVM). W przypadku Linux’a dysk wystarczy zamontować w katalogu /var/lib/elasticsearch. „Minimalny” rozmiar storage to 10 GB. Elasticsearch powinien uruchomić się prawidłowo na instancji nie spełniającej tego wymogu, natomiast nie powinniśmy szukać oszczędności akurat w zasobach dyskowych.
Zostanie zaprezentowana konfiguracja pojedynczej instancji Elastic Stack agregującej logi serwera Apache hostującego przykładową witrynę WordPress. Korzystam z systemu Rocky Linux, co jednak nie ogranicza przygotowanego opisu do jednej grupy dystrybucji Linuxa – z powodzeniem te same kroki (z wyjątkiem procesu instalacji paczek) będą mogły zostać zastosowane w systemach opartych na Debian. SELinux został wyłączony.
Elasticsearch
Paczkę zawierającą Elasticsearch pobierzemy ze strony https://www.elastic.co/downloads/elasticsearch. Jako platformę wybieramy Linux x86_64. w tej chwili najnowsza wersja Elastic Stack to 9.2.3. Same wydania są dość częste, bo w 2025 roku pojawiło się aż pięć wersji.
 Strona pobierania Elasticsearch
Strona pobierania Elasticsearch
Wykonujemy instalację.
Następnie trzeba dostosować dwie opcje w pliku /etc/elasticsearch/elasticsearch.yml:
- network.host: 0.0.0.0 (nie jest to konieczne do samego zbierania logów, bo Logstash będzie na tej samej maszynie, natomiast przeprowadzimy jeszcze integrację z WordPress)
- xpack.security.http.ssl -> enabled: false (Elasticsearch nie jest dostępny w sieci publicznej, więc nie ma rzeczywistego powodu do korzystania z HTTPS i „utrudniania” konfiguracji – HTTPS jest jednak wymagany w przypadku konfiguracji klastra)
Należy jeszcze zablokować możliwość korzystania ze swap (pamięci wymiany w systemach Linux). jeżeli na serwerze swap nie jest aktywny, to te kroki można pominąć. Do modyfikacji są pliki /usr/lib/systemd/system/elasticsearch.service (w sekcji Service dopisujemy LimitMEMLOCK=infinity) i /etc/sysconfig/elasticsearch (dopisujemy MAX_LOCKED_MEMORY=unlimited).
Przeładowujemy daemon systemd (ponieważ edytowaliśmy plik usługi – elasticsearch.service), aktywujemy i uruchamiamy usługę Elasticsearch.
Elasticsearch domyślnie działa na portach 9200 i 9300, które należy odblokować na poziomie zapory sieciowej, jeżeli jest aktywna w naszym systemie.
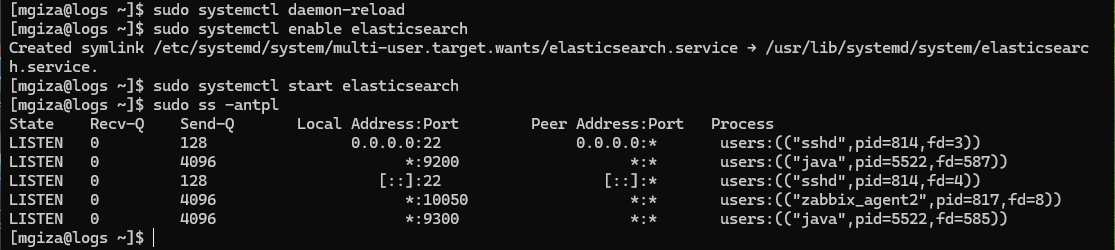 Start usługi Elasticsearch i widoczne aktywne porty
Start usługi Elasticsearch i widoczne aktywne porty
Można teraz wysłać proste zapytanie GET, aby zweryfikować działanie usługi.
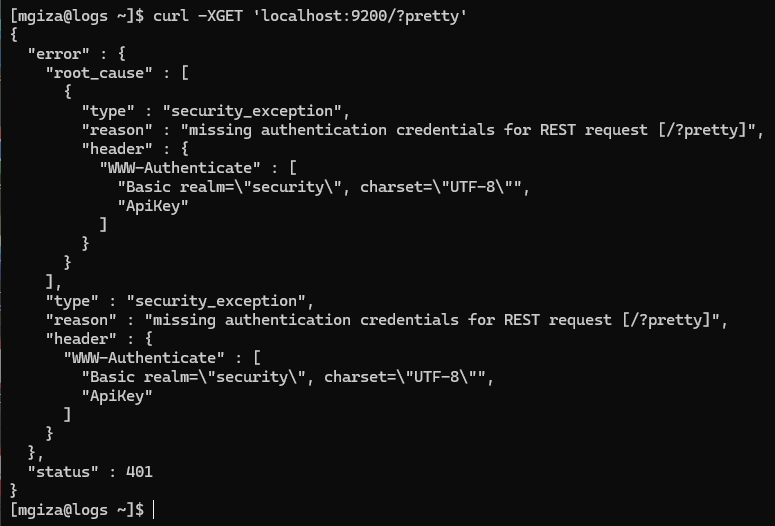 Odpowiedź zwrócona przez serwer Elasticsearch
Odpowiedź zwrócona przez serwer Elasticsearch
Jak widać, została zwrócona odpowiedź 401, co oznacza, iż wymagana jest autoryzacja. Jest to związane z działaniem wspomnianego X-Pack – jeszcze kilka lat temu Elasticsearch domyślnie nie wymagał autoryzacji. Wystarczyło uruchomić usługę, aby każdy zainteresowany (przy założeniu działającego dostępu sieciowego) miał możliwość jej odpytania.
Usługa działa i jest możliwa komunikacja, więc można zresetować hasło dla użytkownika administracyjnego elastic i użytkownika służącego do wdrożenia Kibana. Jako parametr URL podajemy adres, na którym nasłuchuje Elasticsearch.
 Reset hasła użytkownika kibana_system
Reset hasła użytkownika kibana_system
Konfigurację Elasticsearch na ten moment można uznać za zakończoną i przejść do instalacji i uruchomienia Kibana.
Kibana
Adresy paczek RPM/DEB z wszystkimi komponentami Elastic Stack są tworzone według tego przykładu:
https://artifacts.elastic.co/downloads/kibana/kibana-9.2.3-x86_64.rpm
Nie trzeba więc sprawdzać za każdym razem odnośnika na stronie pobierania. Ta wiedza przyda się, jeżeli przykładowo zamierzamy zautomatyzować (np. dzięki Ansible) wdrożenia Elastic Stack.
Instalacja Kibana jest analogiczna – pobieramy paczkę i poleceniem dnf install dokonujemy instalacji w systemie. najważniejsze zmiany pozostają do wprowadzenia w pliku /etc/kibana/kibana.yml:
- server.publicBaseUrl: https://logs.avlab.pl (adres, na którym będzie dostępna Kibana)
- elasticsearch.hosts: [„http://192.168.1.155:9200”] (ponownie – jeżeli Elasticsearch działa na adresie 127.0.0.1, to nie zmieniamy tej opcji)
- elasticsearch.password: „XXX” (hasło ustawione wcześniej poleceniem elasticsearch-reset-password)
Aktywujemy i uruchamiamy usługę.
Jak opisano wyżej, warto uruchomić reverse proxy dla Kibana. Tutaj skorzystamy z najszybszej możliwości, czyli serwera nginx. Konfiguracja jest całkiem typowa dla reverse proxy i może wyglądać jak poniżej. Trzeba pamiętać o odblokowaniu dostępu do wykorzystywanych przez nginx portów – u nas domyślne, czyli 80 (przekierowanie na „wersję” HTTPS) i 443.
Jeśli wszystko zostało poprawnie ustawione, to po wejściu na adres wskazany w konfiguracji zobaczymy poniższą stronę logowania.
 Strona logowania Kibana
Strona logowania Kibana
Logujemy się z użyciem poświadczeń dla użytkownika elastic. Po udanym zalogowaniu od razy wybieramy Explore on my own przy komunikacie zachęcającym do dodania integracji. Interfejs Kibana mniej doświadczonym osobom może wydać się skomplikowany i niezbyt uporządkowany, ale w dalszej części pokażę, w jaki sposób można osiągnąć lepszą przejrzystość.
Monitoring Elasticsearch
Większe znaczenie niż eleganckie GUI ma jednak monitoring Elastic Stack. W zależności od wykorzystywanych przez nas narzędzi można zastosować różne metody monitoringu. W naszym przypadku używany jest Zabbix, który posiada naprawdę świetny template Elasticsearch Cluster by HTTP. Wymagane jest dodanie trzech zmiennych (makr) do konfiguracji hosta.
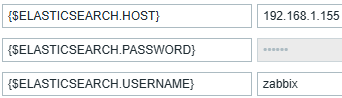 Makra powiązane z monitoringiem Elasticsearch w Zabbix
Makra powiązane z monitoringiem Elasticsearch w Zabbix
Widocznego użytkownika zabbix dodamy po wejściu w ikonę trzech poziomych pasków i dalej Stack Management. Przechodzimy do zakładki Users i wybieramy przycisk Create user. Dane powinny być uzupełnione analogicznie do poniższego zrzutu ekranu.
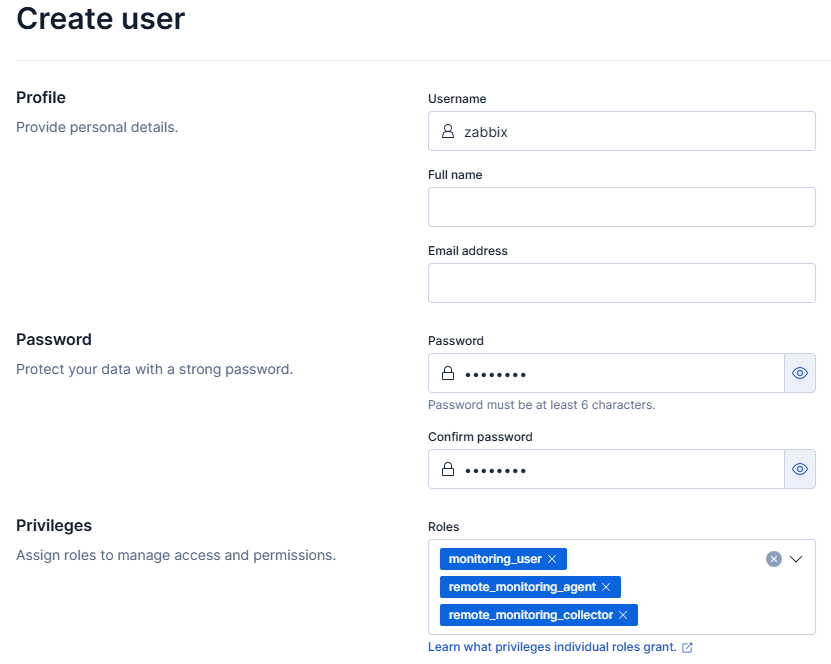 Formularz dodawania użytkownika w Kibana
Formularz dodawania użytkownika w Kibana
Zmiany zapisujemy przyciskiem Create user. Można podejrzeć konfigurację tego użytkownika po odpytaniu endpointa _security/user/zabbix (używając poświadczeń użytkownika elastic).
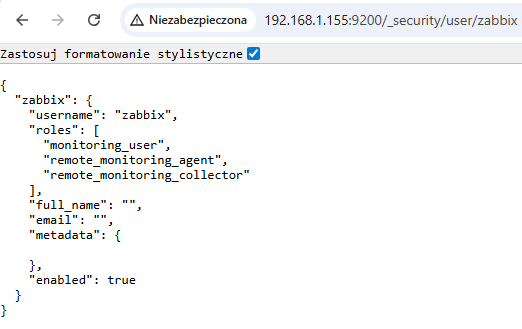 Wynik zapytania do /_security/user/zabbix
Wynik zapytania do /_security/user/zabbix
Konfiguracja roli i użytkownika do tworzenia i zapisu indeksów
Teraz do wykonania jest kluczowa konfiguracja pozwalająca na bezpieczny i działający zapis danych – w naszym przypadku logów. Po przejściu do zakładki Roles i wybraniu Create user uzupełniany pola analogicznie do podanych ustawień:
- Role name: web_write (polecam zachowanie tego porządku – nazwa serwera/projektu_write – rola pozwalająca na dostęp do zapisu dla indeksów)
- Cluster privileges: manage_index_templates, monitor
- Index privileges: web-* – create_index, write
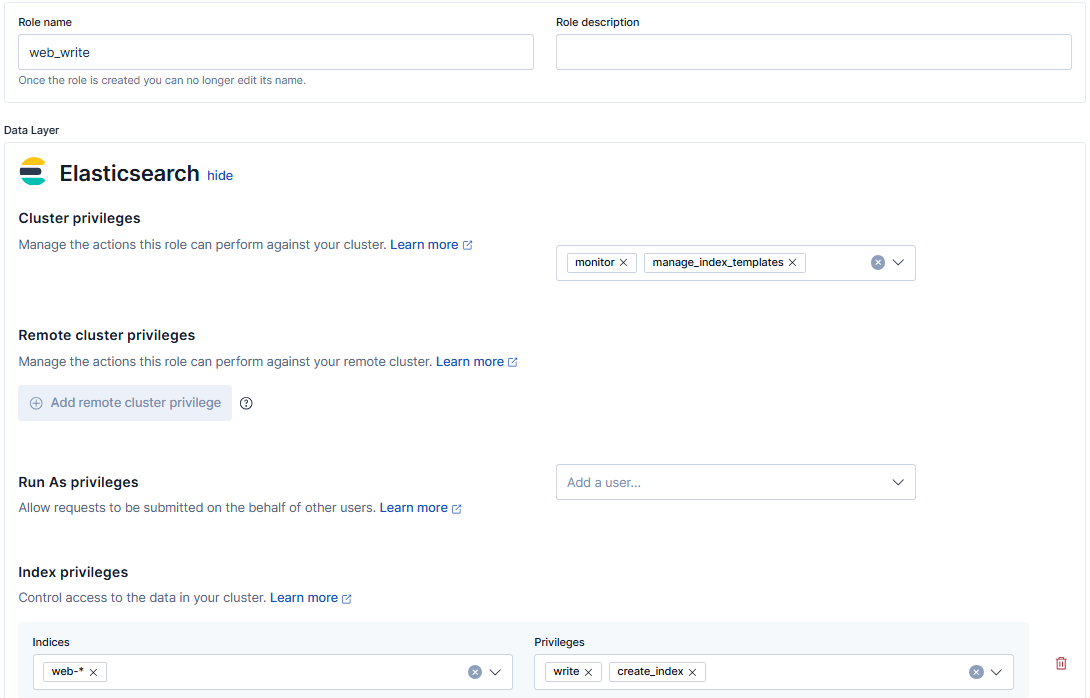 Konfiguracja roli pozwalającej na zapis do indeksu i jego tworzenie
Konfiguracja roli pozwalającej na zapis do indeksu i jego tworzenie
Wyjaśnienia wymaga podanie nazwy indeksu jako web-*. Istotna jest konfiguracja „rotacji” indeksów, aby uniknąć wiadomej sytuacji wyczerpania przestrzeni dyskowej, a do adekwatnego działania niezbędne jest posiadanie kilku indeksów powiązanych z jednym „projektem”. Odpowiednią regułę rotacji dodaje się do opcji danego indeksu (co zostało opisane w dalszej części. Uruchomienie (realizowane automatycznie przez silnik Elasticsearch) tej reguły bez indeksu możliwego do zastąpienia będzie działać (skasuje indeks i wraz z nim dane), a Logstash utworzy kolejny indeks, jednak bez dodanej reguły rotacji dane będą wtedy przyrastać w nieskończoność – bo nowy indeks nie będzie posiadał tej konfiguracji.
Rolę zapisujemy przyciskiem Create role.
Następnie przechodzimy do zakładki Users i wybieramy Create user celem utworzenia użytkownika powiązanego z dodaną właśnie rolą web_write. Tutaj raczej nie są potrzebne dodatkowe tłumaczenia poszczególnych pól formularza. Ponownie zalecam zastosowanie reguły nazewnictwa – nazwa serwera/projektu_writer.
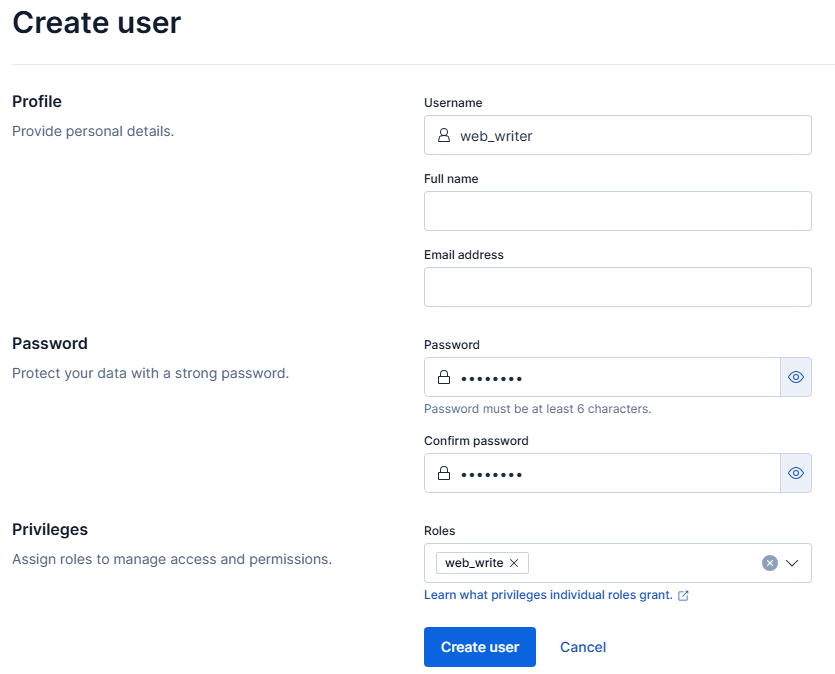 Tworzenie użytkownika z możliwością zapisu do indeksu
Tworzenie użytkownika z możliwością zapisu do indeksu
Logstash
Można przystąpić do instalacji i konfiguracji Logstash. Paczka znajduje się pod adresem https://artifacts.elastic.co/downloads/logstash/logstash-9.2.3-x86_64.rpm.
Komunikacja do Logstash będzie szyfrowana, więc musimy wcześniej przygotować dowolny certyfikat SSL, także self-signed.
Najpierw w konfiguracji OpenSSL (dla systemów RHEL jest to plik /etc/pki/tls/openssl.cnf) dodajemy w sekcji [ v3_ca ] opcję subjectAltName o wartości adresu IP hosta, na którym działa Logstash.
Generujemy certyfikat i klucz oraz ustawiamy właściciela na użytkownika powiązanego z Logstash.
Tworzymy ogólną konfigurację „serwera” w katalogu /etc/logstash/conf.d. Plik polecam nazwać jako beats.conf.
W tym samym katalogu tworzymy kolejny plik zawierający ustawienia dla konkretnego zestawu logów. Zamierzamy agregować logi z serwera Apache, dla którego istnieje gotowy moduł Filebeat i dlatego widoczna konfiguracja w sekcji filter nie jest szczególnie skomplikowana. jeżeli jednak moduł dla naszej aplikacji nie jest dostępny (dotyczy to m.in. zbierania logów z kontenerów Docker – nie ma przecież jednego formatu), to niestety trzeba będzie poświęcić sporo czasu w przygotowanie odpowiedniej konfiguracji. Służą to tego przede wszystkim filtry grok.
Widoczna nazwa apache_web de facto zabezpiecza przed możliwością przesłania logów do niewłaściwego indeksu. O ile przy logicznych ustawieniach ról taki scenariusz nie jest bardzo prawdopodobny, to jednak warto wcześniej założyć, iż w przyszłości nasza instancja może nie być ograniczona do jednego serwera, z którego zbieramy logi. Z kolei jako nazwę indeksu podajemy web-%{+yyyy.MM.dd}. Może to być dowolny inny ciąg znaków (chociaż ten wydaje się najbardziej racjonalny), natomiast należy zachować przedrostek web-, bo wcześniej konfigurowaliśmy rolę posiadającą możliwość tworzenia i zapisu do tych właśnie indeksów (web-*).
Sekcja output zawiera wyłącznie „instrukcję” połączenia z serwerem Elasticsearch.
Aktywujemy i startujemy usługę.
Jeśli korzystamy z zapory sieciowej, to do odblokowania pozostaje port 5044.
Filebeat
Ostatnia usługa do uruchomienia to oczywiście Filebeat. Paczka znajduje się pod adresem https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-9.2.3-x86_64.rpm. Instalację i konfigurację wykonujemy na serwerze, z którego będą zbierane logi. Przed przystąpieniem do pracy trzeba pamiętać o skopiowaniu pliku z certyfikatem Logstash – w naszym przypadku znajduje się on w katalogu /ssl.
W pliku /etc/filebeat/filebeat.yml wprowadzamy szereg zmian:
- filebeat.inputs -> enabled: true
- paths: /home/www/wp/logs/apache/*.log (ścieżka do plików zawierających logi)
- fields:
server_name: web
log_type: apache_web (można dopisać to bezpośrednio po linii z paths)
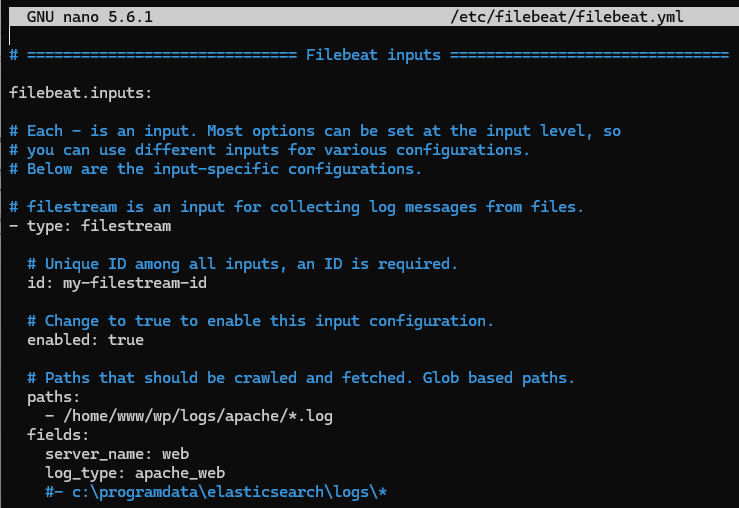 Konfiguracja Filebeat
Konfiguracja Filebeat
- zakomentowanie output.elasticsearch (w tej sekcji także opcje hosts i preset)
- odkomentowanie output.logstash, a w niej hosts i ssl.certificate_authorities
- dopisanie do output.logstash opcji bulk_max_size: 1024
 Konfiguracja Filebeat
Konfiguracja Filebeat
Wykonując polecenie
wyświetlimy listę dostępnych modułów. Wszystkie domyślnie są wyłączone. Nas interesuje apache i dlatego wykonujemy
Oprócz tego w pliku /etc/filebeat/modules.d/apache.yml zmieniamy opcje (występują dwa razy – dla access i error logów) enabled na wartość true.
Aktywujemy i startujemy usługę Filebeat.
Podstawowe operacje w Elasticsearch
Odpytując endpoint /_cat/indices zobaczymy, iż indeksy zostały pomyślnie utworzone, a choćby zawierają dane.
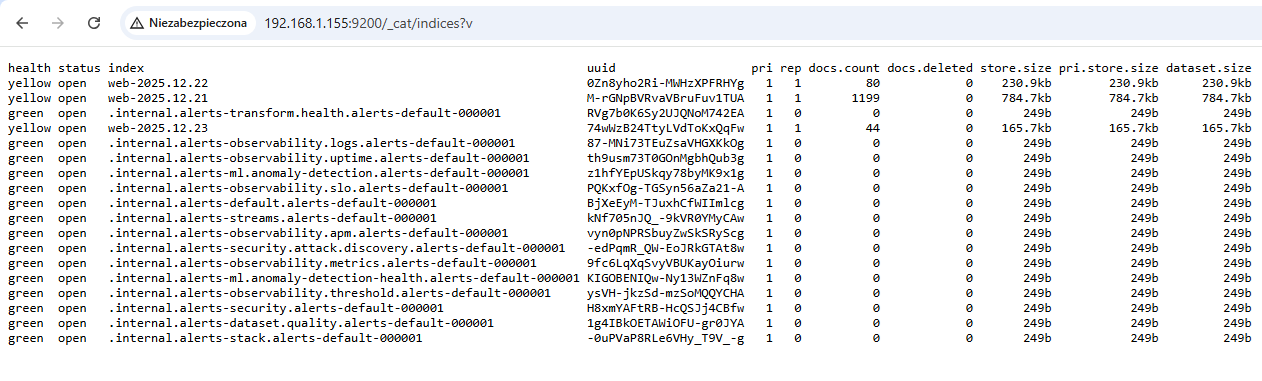 Indeksy dostępne w Elasticsearch
Indeksy dostępne w Elasticsearch
Możemy od razu sprawdzić zawartość indeksów web-* – endpoint /web-*/_search. Jak widać, jest to format JSON.
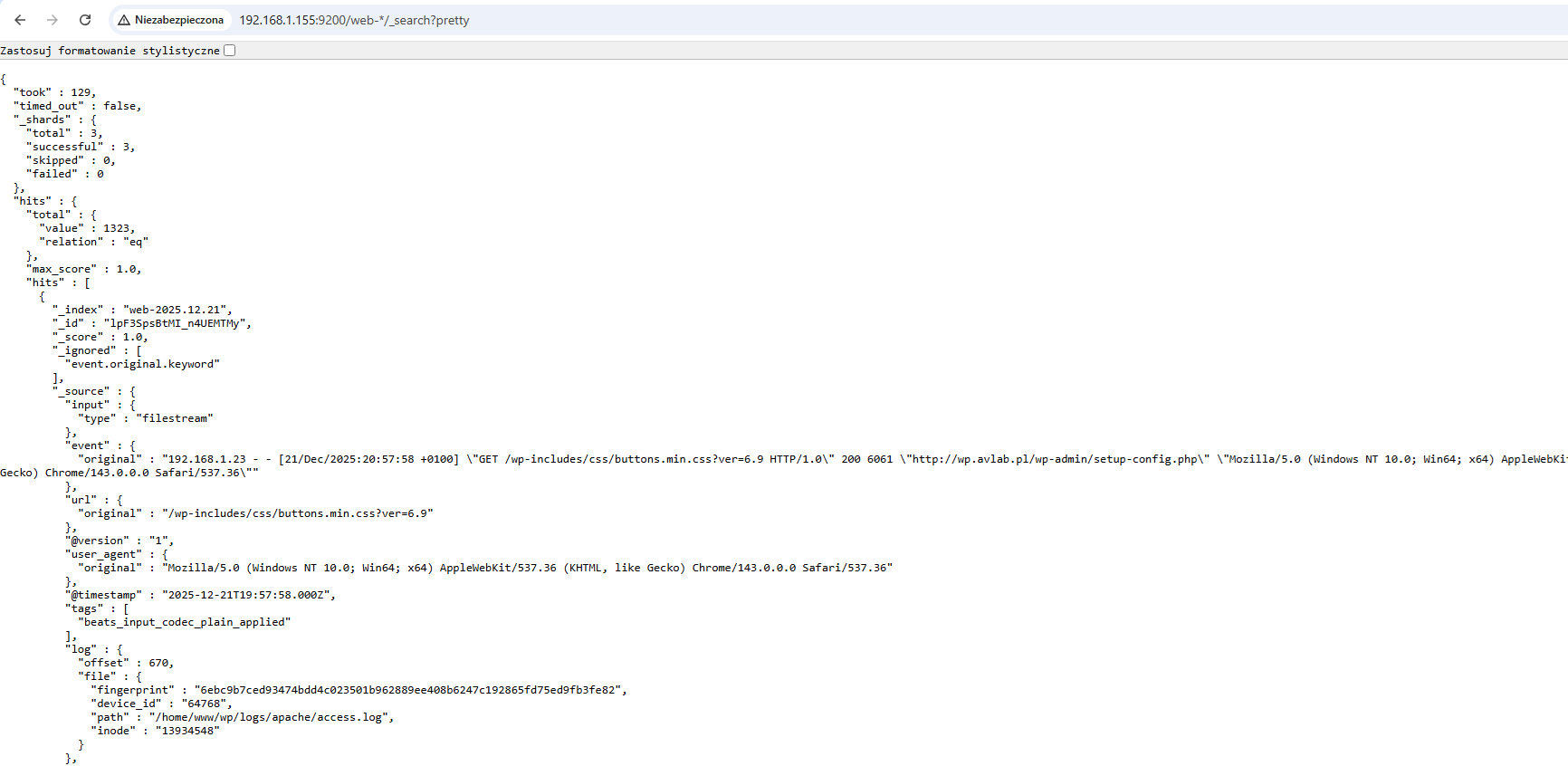 Wyświetlenie zawartości indeksów
Wyświetlenie zawartości indeksów
Jeśli monitorujemy naszą instancję, to po utworzeniu nowego indeksu możemy spodziewać się alertu podobnego do tego z systemu Zabbix.
 Alert dotyczący klastra Elasticsearch z Zabbix
Alert dotyczący klastra Elasticsearch z Zabbix
To jest całkowicie typowe zachowanie silnika Elasticsearch, gdy nie działa w ramach klastra – a tutaj operujemy na instancji standalone. Rozwiązanie stanowi wysłanie żądania PUT do endpointa _settings o następującej zawartości:
W odpowiedzi zostanie zwrócone
I teraz „health” wszystkich indeksów powinien być ponownie jako „green”
Lifecycle policy i index template
Możemy rozpocząć tworzenie lifecycle policy, która zapewni odpowiednią rotację indeksu, a tym samym będzie stanowić podstawowe, ale jednocześnie absolutnie najważniejsze zabezpieczenie przed zbyt dużym wykorzystaniem storage. Całą konfigurację można w łatwy sposób przeprowadzić w Kibana. Przechodzimy do zakładki Index Lifecycle Policies i poprzez Create policy otwieramy kreator. Uzupełniamy poszczególne pole w ten sposób:
- Policy name – nazwa tworzonej polityki, w naszym przykładzie siedem_dni
- Hot phase -> Delete data after this phase (należy kliknąć ikonę kosza)
Dalej po rozwinięciu sekcji Advanced settings w Hot phase:
- odznaczyć opcję Use recommended defaults
- odznaczyć opcję Enable rollover
Ostatecznie w Delete phase:
- Move data into phase when: 7 days
Zmiany dodajemy dzięki przycisku Save policy. Oczywiście ilość dni, przez którą przechowujemy indeksy, może być dłuższa. Politykę do indeksu przypisujemy wchodząc w Index Management, wybierając interesujący nas indeks, a następnie rozwijając menu Manage index opcję Add lifecycle policy.
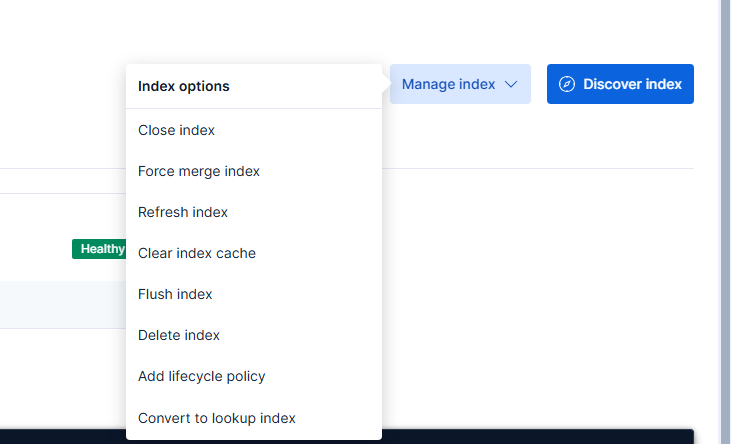 Opcje zarządzania indeksem w Kibana
Opcje zarządzania indeksem w Kibana
Wskazujemy utworzoną wcześniej politykę i zapisujemy zmiany.
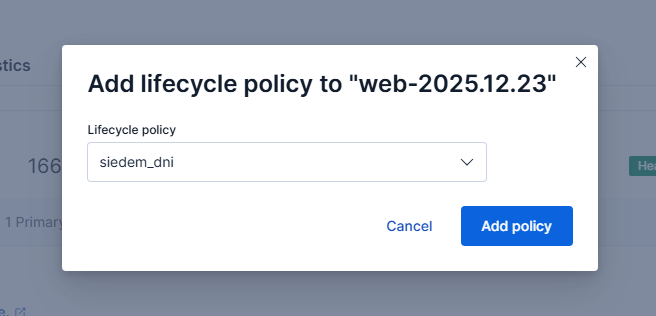 Wybór lifecycle policy dla indeksu
Wybór lifecycle policy dla indeksu
Jak wspomniałem, lifecycle policy będzie już działać poprawnie, ale usunie indeks, a wraz z nim dodaną politykę – kolejny indeks (w tym przykładzie web-2025.12.24) będzie przyrastać w nieskończoność. Zamiast dodawać lifecycle policy każdego dnia, trzeba utworzyć template dla naszego indeksu, aby to i inne ustawienia były aplikowane automatycznie przy każdym utworzeniu indeksu web-*.
Wracamy więc do zakładki Index Management i wybieramy Index Templates. Klikamy Create template i uzupełniamy opcje z zgodnie z tą instrukcją:
- Name – siedem_dni_web (nazwa-polityki_nazwa-indeksu, może być inna dowolna)
- Index patterns – web-*
- odznaczona opcja Create data stream (data stream nie jest odpowiedni dla logów, potrzebujemy standardowego indeksu)
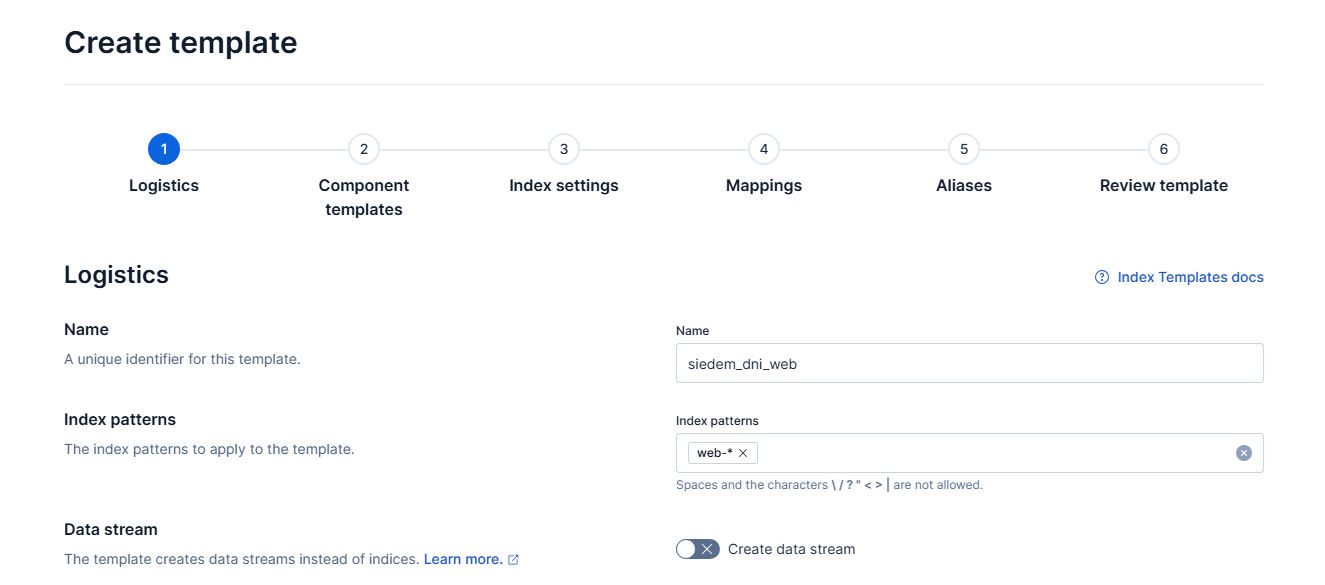 Dodawanie template indeksu w Kibana
Dodawanie template indeksu w Kibana
Następnie przechodzimy do „kroku” Index settings, gdzie w polu tekstowym wklejamy tę zawartość:
Pozostaje zapisać utworzoną template przyciskiem Create template w ostatnim dostępnym „kroku” Review template.
Spaces
Możliwe, iż najlepszą metodą zachowania porządku w Kibana jest zastosowanie spaces. Po zalogowaniu użytkownik będzie miał wybór „przestrzeni”, do której chciałby uzyskać dostęp, aby sprawdzić logi itd. W zakładce Spaces wybieramy Create space i podajemy nazwę tworzonej przestrzeni – u nas będzie to Serwer WWW.
Powinniśmy też ograniczyć widoczność różnych funkcjonalności dostępnych w Kibana – wystarczy nam dostęp do logów zebranych w indeksach. Dlatego w sekcji Set feature visibility rozwijamy gałąź Analytics i pozostawiamy zaznaczenie wyłącznie przy Discover. Odznaczany też wszystkie pozostałe gałęzie, czyli Elasticsearch, Observability, Security i Management. W tej ostatniej zaznaczamy jednak Data View Management. Wyżej znajduje się też „nowość” w Kibana, czyli Select solution view – osobiście radzę wybrać ten po prostu Classic.
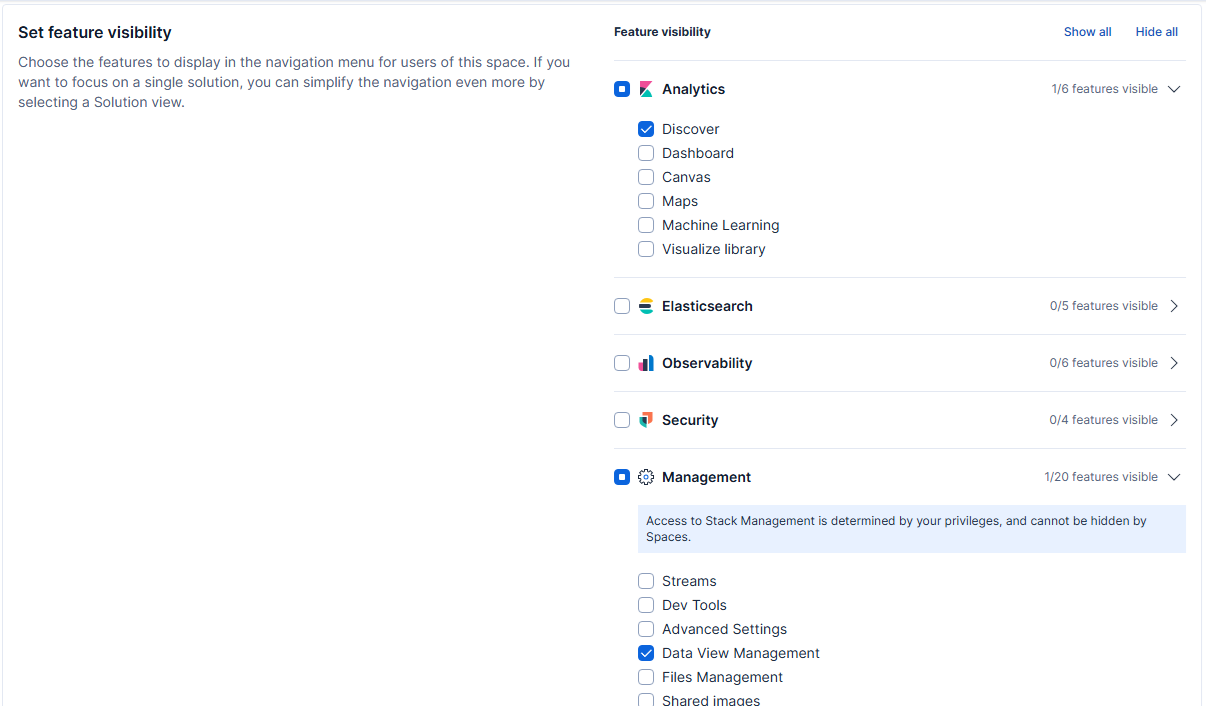 Wybór funkcjonalności dla tworzonego space w Kibana
Wybór funkcjonalności dla tworzonego space w Kibana
Można choćby ustawić grafikę lub awatar.
Trzeba dodatkowo utworzyć kolejną rolę (np. serwer_www_view), która będzie posiadać wyłącznie możliwość odczytu (read) indeksów web-*. Rolę musimy przypisać do utworzonego space. Przy okazji warto ograniczyć też dostęp do funkcji Kibana, aby faktycznie uzyskać intuicyjny interfejs dla użytkowników – pamiętajmy, iż niekoniecznie musi to być osoba techniczna.
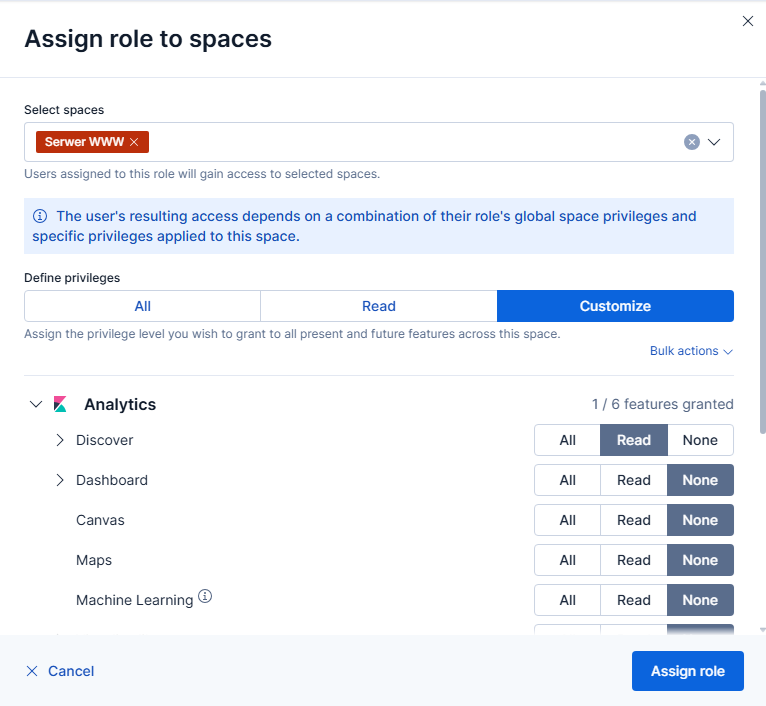 Przypisywanie roli do space w Kibana
Przypisywanie roli do space w Kibana
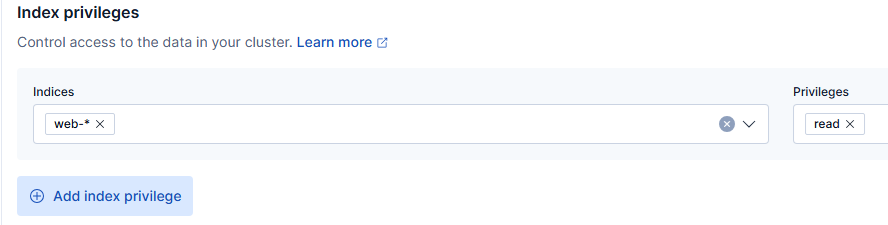 Ustawienie możliwości odczytu indeksów
Ustawienie możliwości odczytu indeksów
Wystarczy już tylko utworzyć użytkownika z przypisaną rolą serwer_www_view.
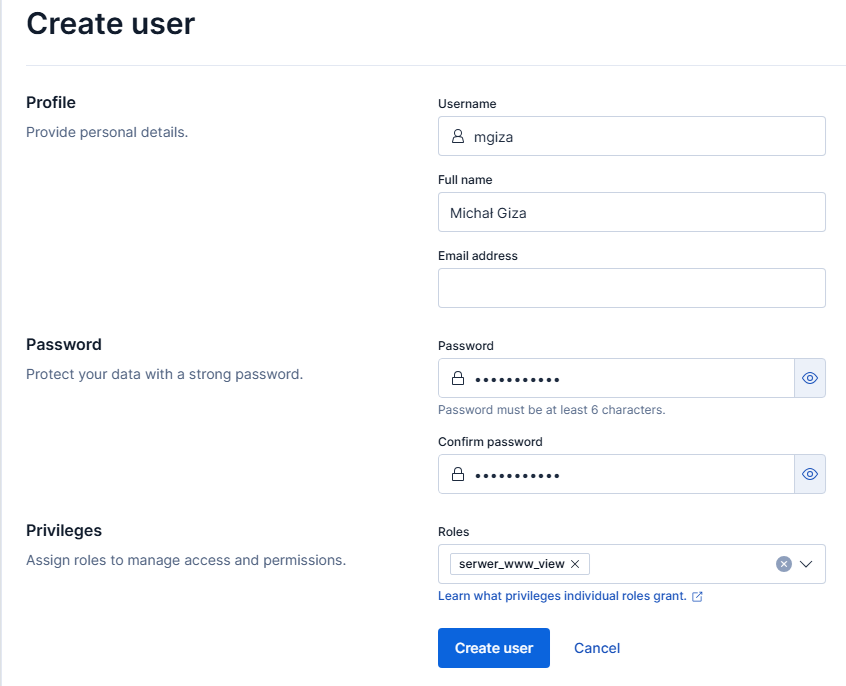 Dodawanie użytkownika z rolą serwer_www_view
Dodawanie użytkownika z rolą serwer_www_view
Jeśli wylogujemy i zalogujemy się ponownie (wciąż jako użytkownik elastic), to powinniśmy zobaczyć poniższy komunikat.
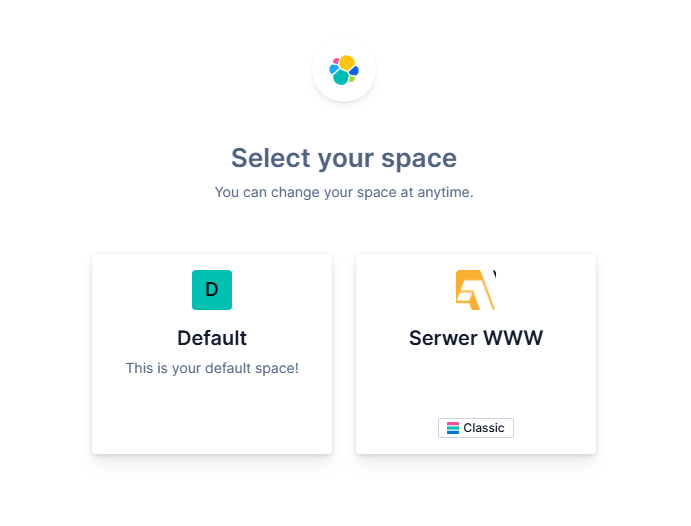 Wybór space w Kibana
Wybór space w Kibana
Tworzenie data view
Musimy skonfigurować data view, czyli widok logów, jaki zobaczą użytkownicy. Rozwijamy menu (trzy poziome kreski) i przechodzimy do Discover, dalej rozwijamy pozycję All logs i wybieramy Create a data view. Ustawienia powinny wyglądać zgodnie ze zrzutem ekranu.
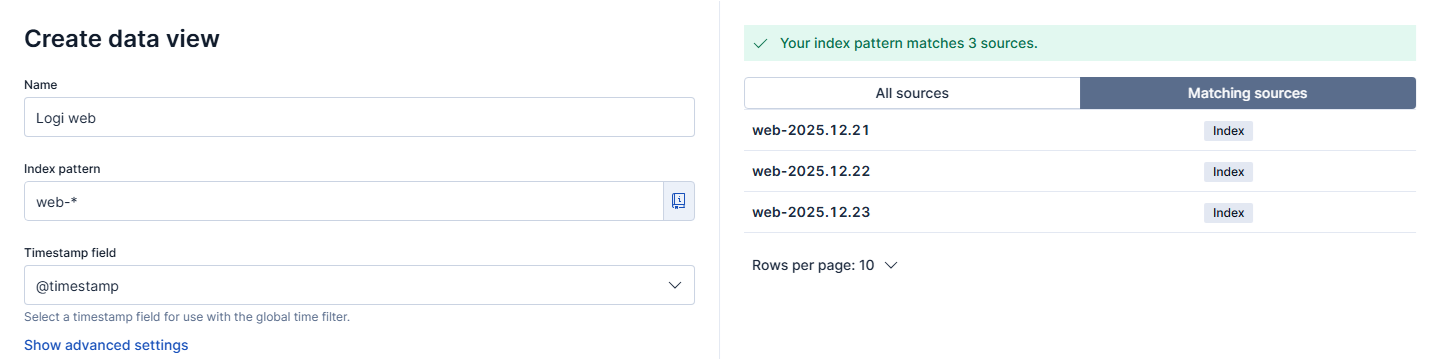 Tworzenie data view
Tworzenie data view
Po zapisaniu zmian przyciskiem Save data view to Kibana prawdopodobnie zobaczymy ten widok:
Widać, iż logi są poprawnie zbierane, ale sam widok nie jest czytelny. Dlatego też z listy Available fields należy wybrać (najechać kursorem i wybrać znak plus) pola, które będą dostarczać pewną wartość dla osoby analizującej logi. Na początek proponuję url.original, http.request.method i http.response.status_code. Można dostosować szerokość tych kolumn poprzez przeciągnięcie wiersza z nazwą danej kolumny.
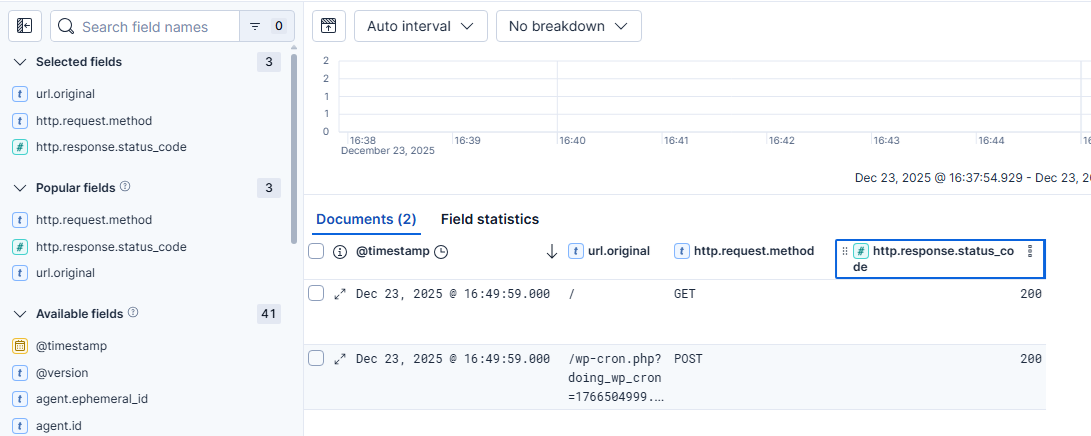 Dostosowywanie szerokości kolumny
Dostosowywanie szerokości kolumny
Po zakończeniu modyfikacji wybieramy przycisk Save i jeszcze raz podajemy nazwę date view, po czym finalnie zapisujemy ustawienia.
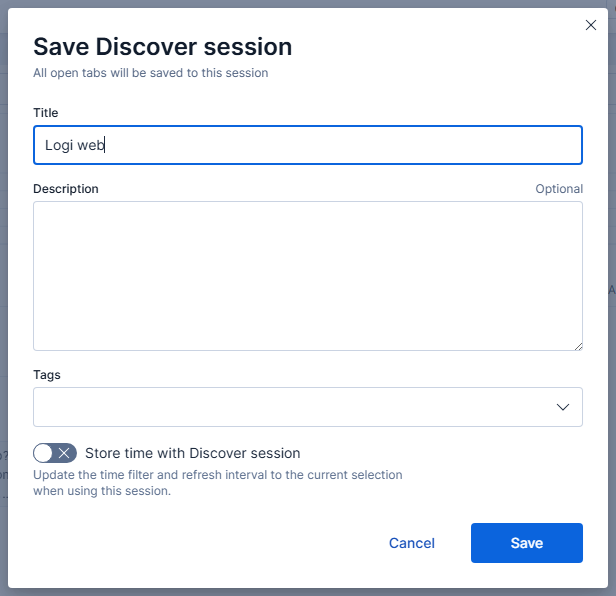 Zapisywanie utworzonego data view
Zapisywanie utworzonego data view
Adres z widokiem będzie miał postać https://logs.avlab.local/s/serwer-www/app/discover#/view/192453fc-687d-4c7f-b943-24f5ead38197.
Profile użytkowników
Użytkownicy mogą edytować swoje profile. Trzeba przyznać, iż ilość dostępnych do wprowadzenia zmian jest imponująca, tym bardziej, iż Kibana to jednak narzędzie techniczne.
 Przejście do edycji profilu w Kibana
Przejście do edycji profilu w Kibana
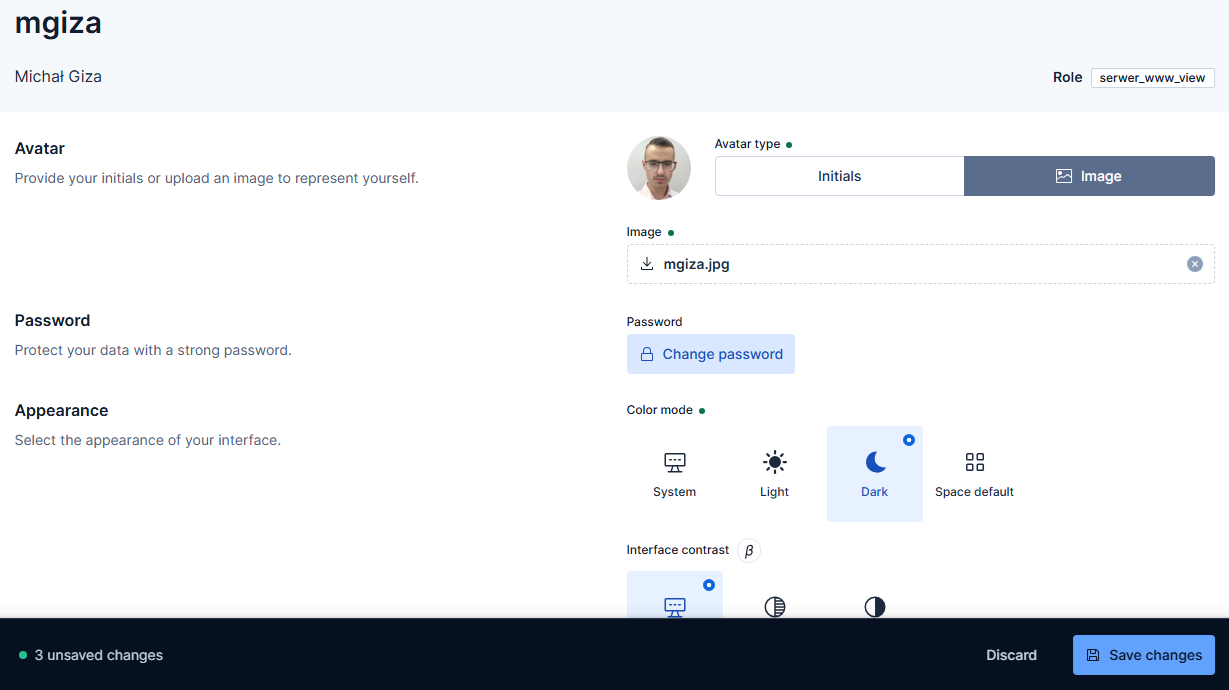 Edycja ustawień profilu
Edycja ustawień profilu
Użytkownicy z rolą serwer_www_view zobaczą tylko jedną pozycję w menu.
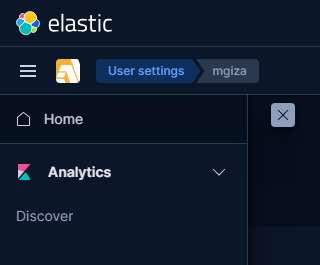 Widok menu dla użytkownika z ograniczoną rolą
Widok menu dla użytkownika z ograniczoną rolą
Po wybraniu Discover powinien zostać załadowany przygotowany wcześniej widok – jednak nie zawsze tak się dzieje i wtedy najlepiej skopiować podany wyżej link (adres będzie bezpośrednio po zapisaniu widoku).
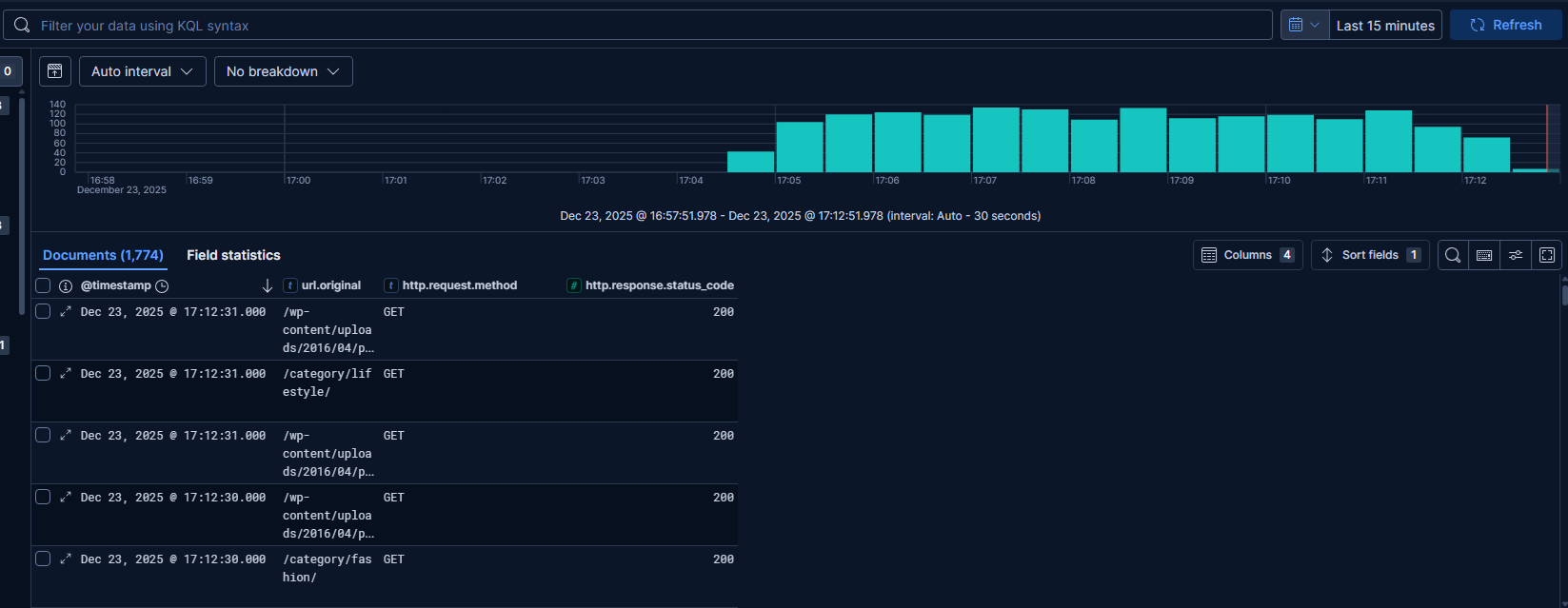 Załadowany data view
Załadowany data view
Integracja WordPress z Elasticsearch
Pokażę również sposób integracji istniejącej witryny WordPress z Elasticsearch. Na początek musimy zainstalować wtyczkę ElasticPress.
 Instalacja wtyczki ElasticPress
Instalacja wtyczki ElasticPress
Nasza instancja wymaga autoryzacji, dlatego edytujemy plik wp-config.php dodając te dwie opcje:
W środowiskach produkcyjnych należy unikać wykorzystania użytkownika elastic do takich integracji. Z poziomu Kokpitu wchodzimy do zakładki ElasticPress i zaznaczamy checkboxy przy zawartości, która powinna zostać zapisana w Elasticsearch.
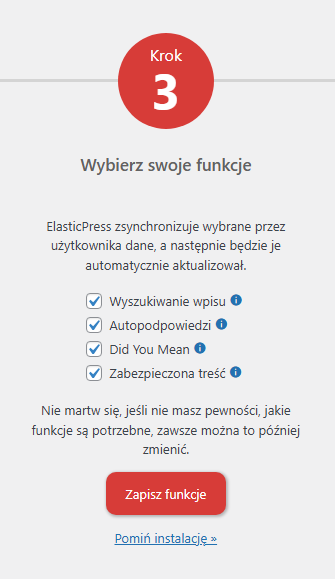 Wybór danych do synchronizacji
Wybór danych do synchronizacji
Klikamy kolejno Zapisz funkcje i Indeksuj swoją treść.
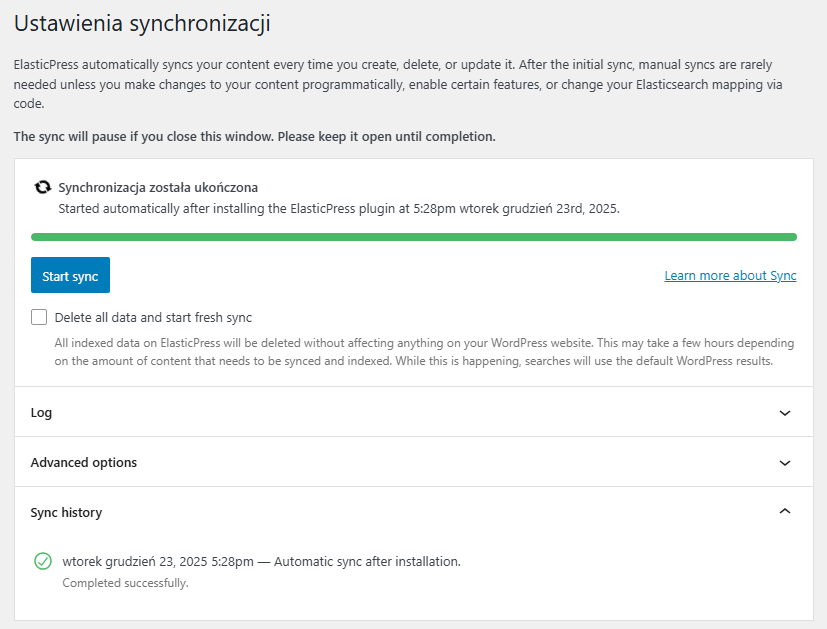 Zakończona synchronizacja danych do Elasticsearch
Zakończona synchronizacja danych do Elasticsearch
Indeks został pomyślnie utworzony.
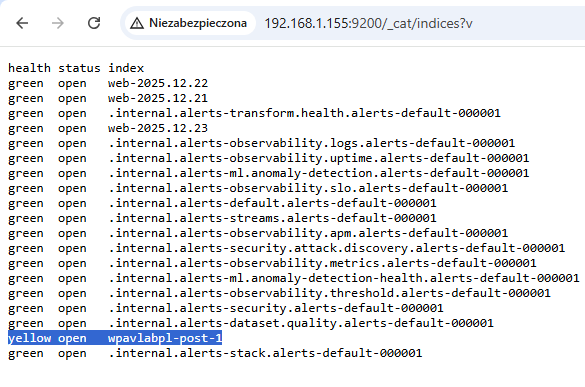 Indeks powiązany z witryną WordPress
Indeks powiązany z witryną WordPress
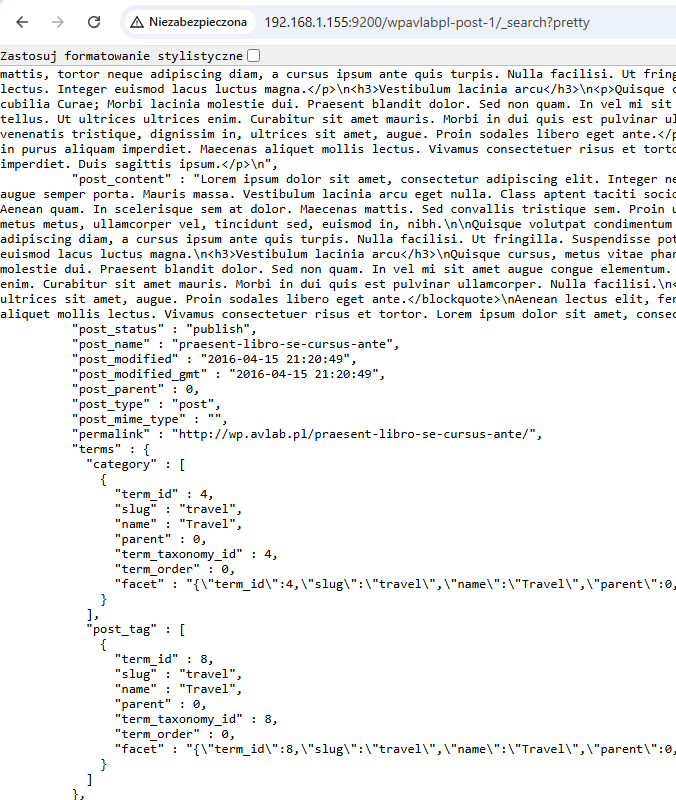 Zawartość indeksu z danymi WordPress
Zawartość indeksu z danymi WordPress
Na podstawie przekazanych informacji powinniśmy bez większych trudności utworzyć data view prezentujący dane z WordPress – bezpośrednio w space Serwer WWW jako użytkownik elastic.
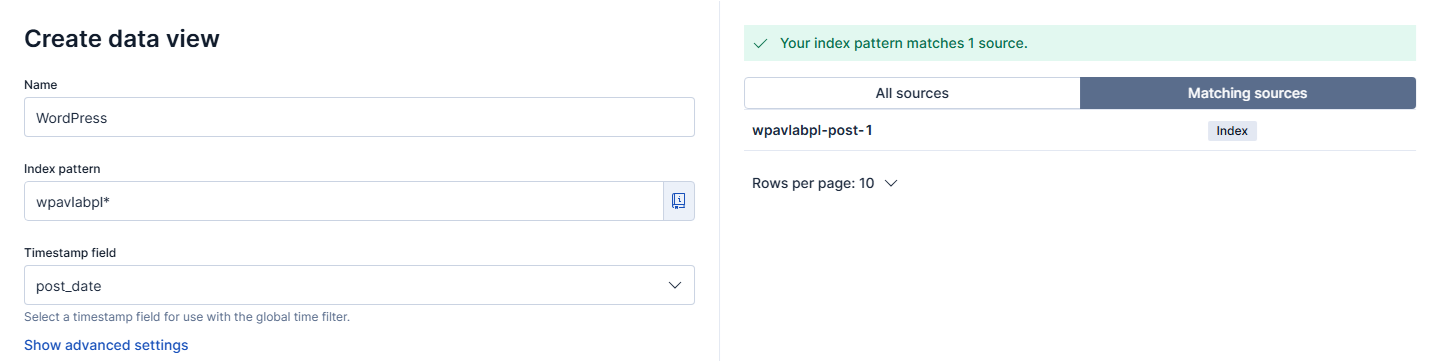 Tworzenie data view z indeksem powiązanym z WordPress
Tworzenie data view z indeksem powiązanym z WordPress
Zakres danych można gwałtownie zmienić poprzez gotowe wartości dostępne po wybraniu ikony kalendarza. Domyślnie są wyświetlane dane z ostatnich 15 minut.
 Zmiana zakresu danych w data view
Zmiana zakresu danych w data view
Dodałem indeks wpavlabpl* do utworzonej wcześniej roli serwer_www_view.
 Dodanie roli uprawnień read do indeksu
Dodanie roli uprawnień read do indeksu
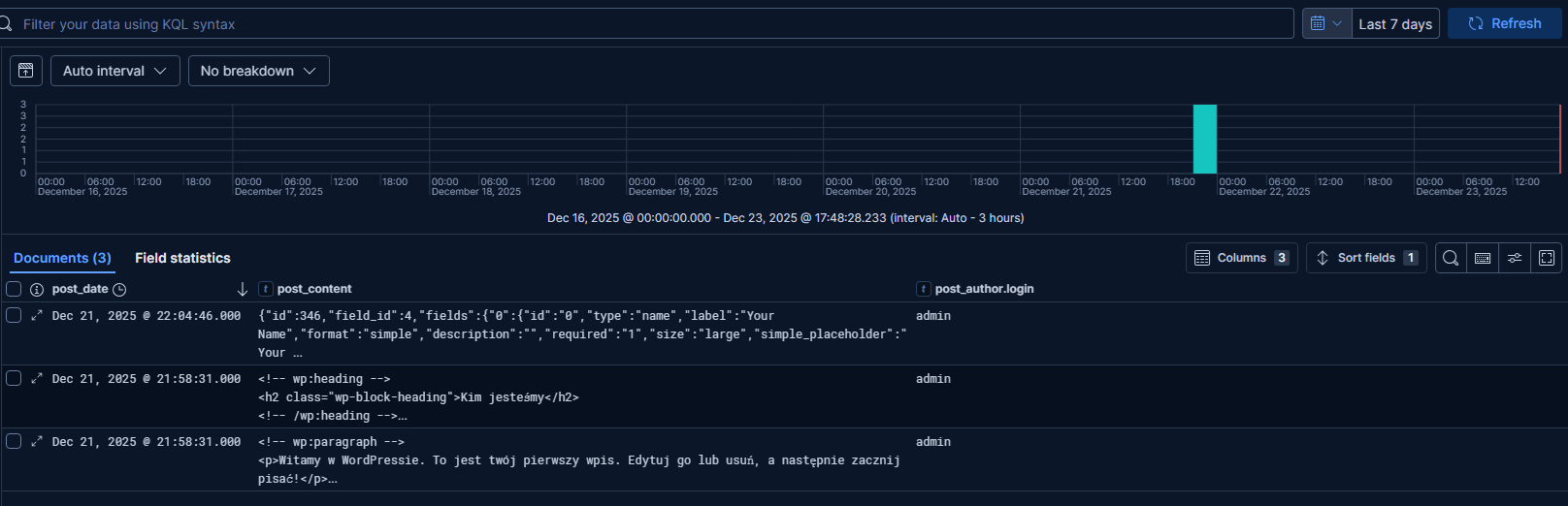 Odczyt indeksu w data view przez użytkownika z ograniczonymi uprawnieniami
Odczyt indeksu w data view przez użytkownika z ograniczonymi uprawnieniami
Podsumowanie
Wdrożenie Elastic stack pomoże zapanować nad logami, szczególnie w przypadku złożonych środowisk. Nie będzie konieczności manualnego wyszukiwania logów na serwerach, ponieważ te będą w jednym, centralnym miejscu. Znacznie ułatwi to pracę, a co za tym idzie, przyspieszy proces analizy błędów – korzyści biznesowe są oczywiste. Korzystanie z tego rozwiązania będzie również świadczyć o pewnej fachowości zespołów technicznych.








