
Modele językowe mają zrewolucjonizował różnych dziedzin z ich zaawansowanymi możliwościami, pozostawiając wiele osób z pytaniami, takimi jak korzystanie z Google MusicLM i modeli GPT OpenAI, w tym ChatGPT I Kodeks, odegrały znaczącą rolę w tym zakłóceniu. Modele te mają możliwość wydajnego generowania tekstu i kodu na podstawie zadanego monitu. przeszkolony na ogromne zbiory danychmożna je zastosować do wielu zadań przetwarzania języka naturalnego (NLP), takich jak analiza sentymentu, systemy chatbotów, podsumowania, tłumaczenie maszynowe, I klasyfikacja dokumentów.
Chociaż te modele mają swoje ograniczenia, oferują rzut oka na potencjał modeli językowych rozumieć języki i opracowywać aplikacje, które mogą poprawić jakość ludzkiego życia. Chociaż istnieją obawy dotyczące ich potencjał do zastąpienia człowieka w różnych dziedzinach podstawową ideą jest zwiększenie produktywności i zapewnienie nowych sposobów poznawania i rozumienia języka jako całości.
 Jak korzystać z Google MusicLM: Interfejs MusicLM
Jak korzystać z Google MusicLM: Interfejs MusicLMDany fundamentalną rolę języka w cywilizacji ludzkiej, konieczne staje się zbudowanie modeli językowych, które mogą dekodować opisy tekstowe i wykonywać zadania, takie jak generowanie tekstu, obrazów, dźwięku, a choćby muzyki. W tym artykule skupimy się przede wszystkim na modele języka muzykiktóre są podobne do modeli takich jak ChatGPT I Dall-E, ale zamiast generować tekst lub obrazy, są przeznaczone do tworzenia muzyki.
Muzyka to złożona i dynamiczna forma sztuki. Obejmuje orkiestrację wielu instrumentów muzycznych, które harmonizują, tworząc doświadczenie kontekstualne. Od pojedynczych nut i akordów po elementy mowy, takie jak fonemy i sylaby, muzyka obejmuje szeroki zakres komponentów. Rozwój model matematyczny w stanie wydobyć z nich informacje tak zróżnicowany zbiór danych jest nie lada zadaniem. Jednak po ustaleniu takiego modelu może on generować realistyczny dźwięk podobny do tego, który jest w stanie wytworzyć człowiek.
 Jak korzystać z Google MusicLM: Wielu entuzjastów wciąż kwestionuje możliwości muzyki generowanej przez sztuczną inteligencję
Jak korzystać z Google MusicLM: Wielu entuzjastów wciąż kwestionuje możliwości muzyki generowanej przez sztuczną inteligencjęMając to wszystko na uwadze, zagłębimy się w podstawową koncepcję modeli języka muzyki i zbadamy, w jaki sposób umożliwiają one generowanie muzyki. W międzyczasie, jeżeli chcesz ulepszyć swoją grę muzyczną, możesz również sprawdzić, jak korzystać z Discord Soundboard i dodawać do niej nowe dźwięki.
Zrozumienie modeli języka muzyki i korzystania z Google MusicLM
MusicLM wykorzystuje różne techniki uczenia maszynowego, takie jak głębokie uczenie się i przetwarzanie języka naturalnego, aby analizować dane i odkrywać ukryte reprezentacje, które ułatwiają generowanie muzyki. Modele te wykorzystują zbiory danych specyficzne dla muzyki do wydobywania informacji, identyfikowania wzorców i poznawania szerokiego spektrum stylów i gatunków muzycznych.
MusicLM ma potencjał automatyzacji szeregu zadań, w tym pisanie partytur muzycznych analizując istniejącą muzykę, polecając nowe progresje akordówLub nawet generując nowe dźwięki. Ostatecznie może wprowadzić nowe formy muzyczne wyrażenie I kreatywność, służąc jako cenne narzędzie do podnoszenia umiejętności muzyków i ułatwiania edukacji muzycznej.
Przedstawiamy Google MusicLM
Google MusicLM to dedykowany model językowy zaprojektowany specjalnie do generowania muzyki na podstawie opisów tekstowych. Na przykład, podając podpowiedź typu „uspokajająca melodia gitary w metrum 6/8”, model może wyprodukować odpowiednią muzykę.
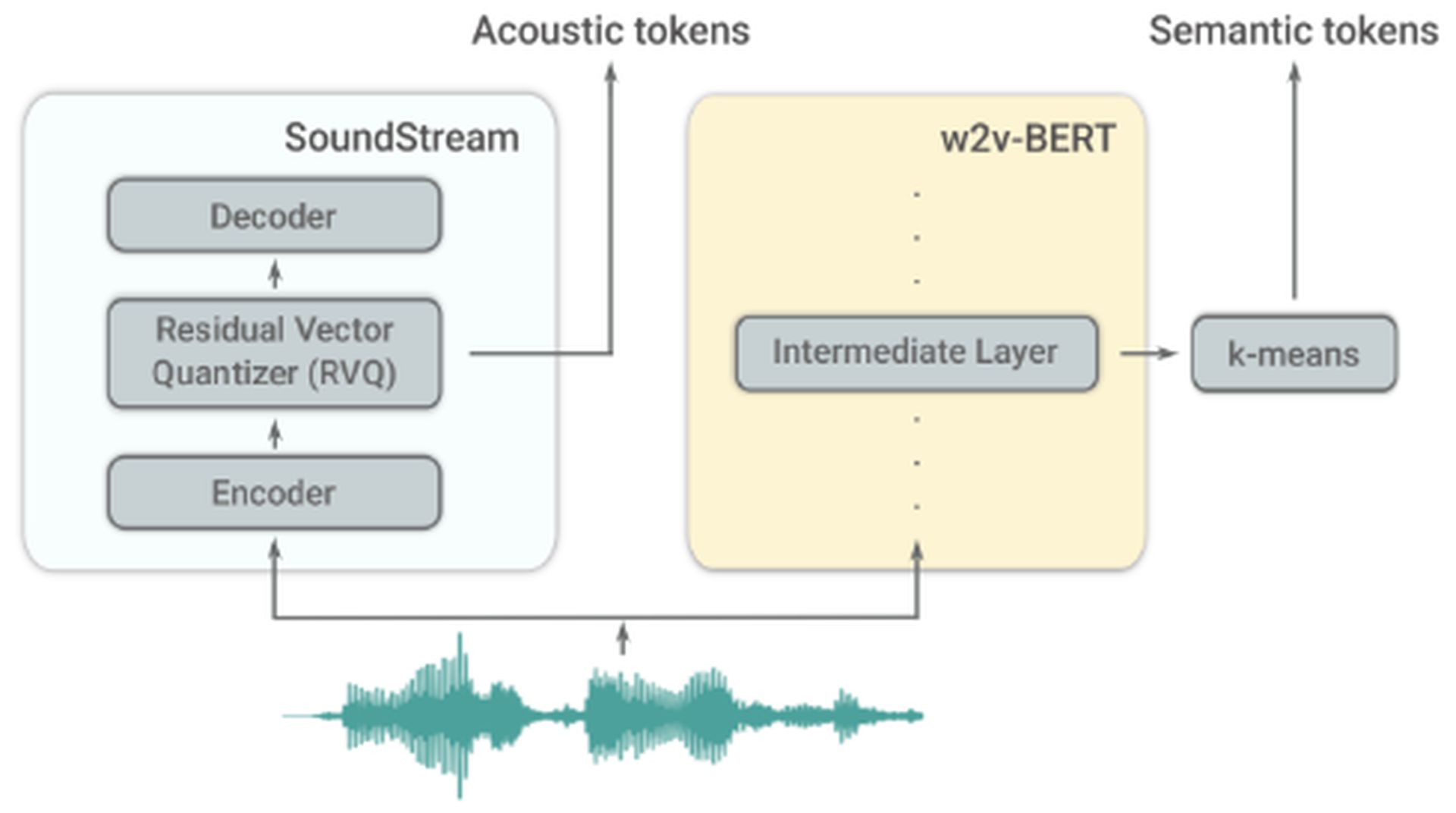 Jak korzystać z Google MusicLM: Dwa tokenizery AudioLM
Jak korzystać z Google MusicLM: Dwa tokenizery AudioLMMusicLM opiera się na AudioLM, inny model językowy opracowany przez Google. AudioLM koncentruje się na generowaniu wysoka jakość I zrozumiały kontynuacje mowy i muzyki fortepianowej. Osiąga to poprzez konwersję wejściowego dźwięku na serię dyskretnych tokenów i generowanie sekwencji audio o długoterminowej spójności. AudioLM wykorzystuje dwa tokenizery: tokenizer SoundStream, który wytwarza żetony akustyczne i tokenizer w2v-BERT, który generuje tokeny semantyczne. Te tokenizatory odgrywają kluczową rolę w ekstrakcji informacji.
 Jak korzystać z Google MusicLM: Proces ekstrakcji informacji
Jak korzystać z Google MusicLM: Proces ekstrakcji informacjiAudioLM składa się z trzech hierarchicznych etapów:
- Modelowanie semantyczne: Ten etap koncentruje się na uchwyceniu długoterminowej spójności strukturalnej. Wyodrębnia strukturę wysokiego poziomu sygnału wejściowego.
- Zgrubne modelowanie akustyczne: W tym przypadku model wytwarza tokeny akustyczne, które są następnie łączone lub uwarunkowane na tokenach semantycznych.
- Precyzyjne modelowanie akustyczne: Końcowy dźwięk ma większą głębię na tym etapie, który obejmuje przetwarzanie grubych tokenów akustycznych dzięki drobnych tokenów akustycznych. Dekoder SoundStream wykorzystuje te tokeny akustyczne do odtworzenia kształtu fali.
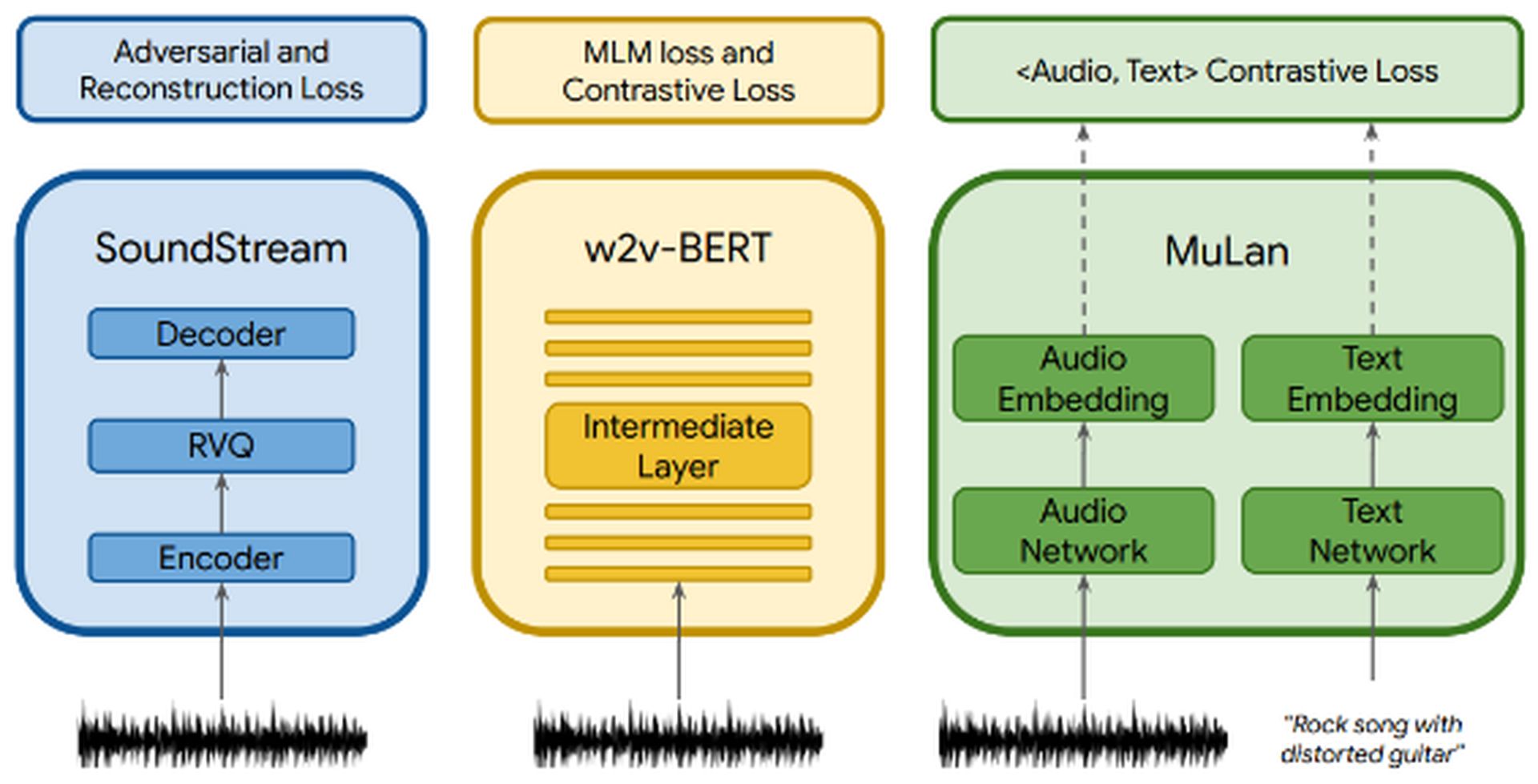 Jak korzystać z Google MusicLM: Hierarchiczne etapy AudioLM
Jak korzystać z Google MusicLM: Hierarchiczne etapy AudioLMMusicLM wykorzystuje AudioLM wielostopniowe modelowanie autoregresyjne jako jego składnik generatywny, a jednocześnie zawiera warunkowanie tekstu. Plik audio przechodzi przez trzy komponenty: SoundStream, w2v-BERT, I MuLan. SoundStream i w2v-BERT przetwarzają i tokenizują wejściowy sygnał audio, podczas gdy MuLan reprezentuje wspólny model osadzania muzyki i tekstu. MuLan składa się z dwie wieże osadczepo jednym dla każdej modalności (tekst i dźwięk).
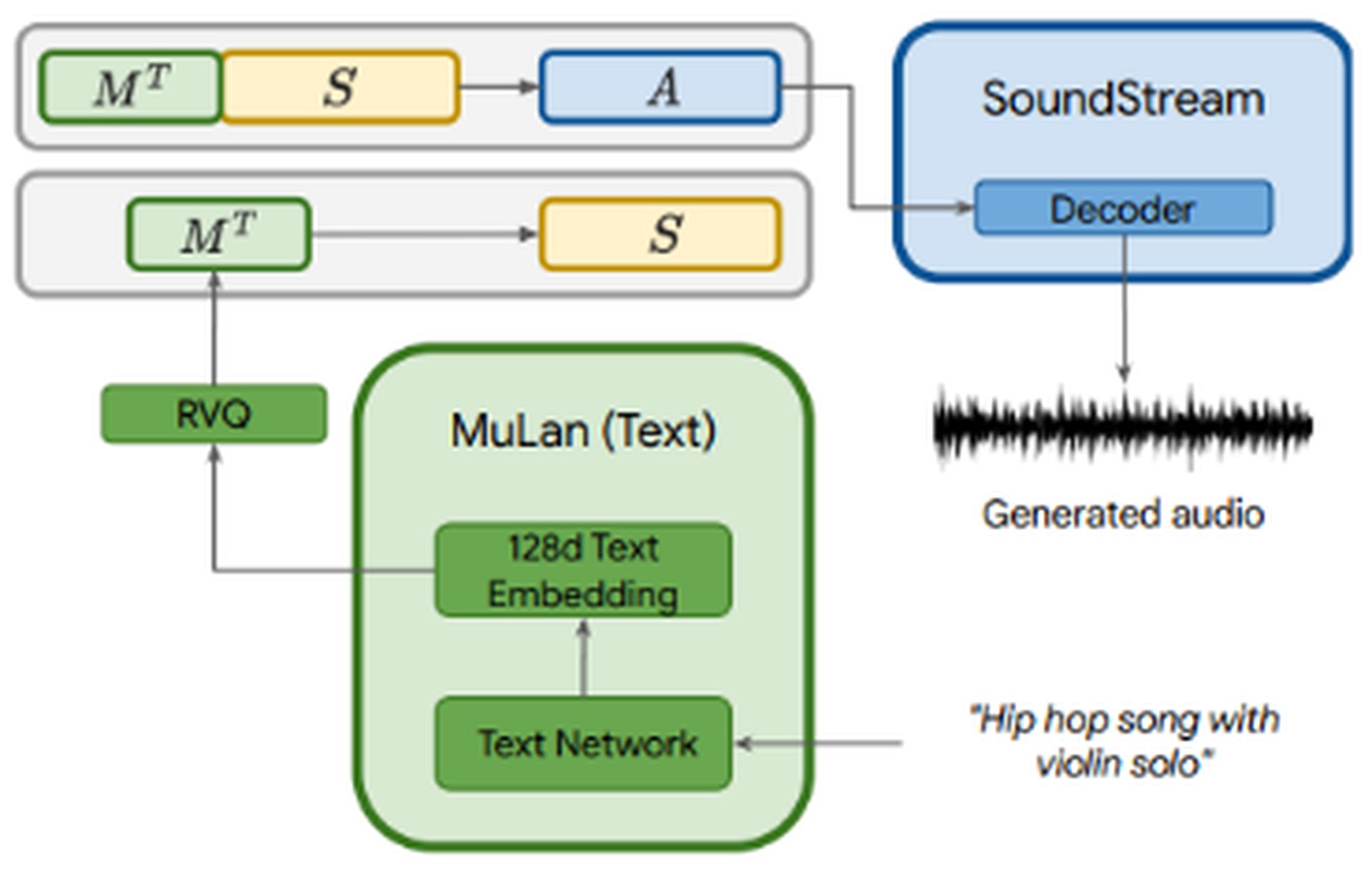 Jak korzystać z Google MusicLM: Trzy komponenty MusicLM
Jak korzystać z Google MusicLM: Trzy komponenty MusicLMPodczas gdy dźwięk jest dostarczany do wszystkich trzech komponentów, opis tekstowy jest wprowadzany tylko do MuLan. Osadzenia MuLan są kwantyzowane, aby zapewnić znormalizowana reprezentacja w oparciu o dyskretne tokeny zarówno dla sygnału kondycjonującego, jak i audio. Dane wyjściowe z MuLan są następnie wprowadzane do etap modelowania semantycznego, gdzie model uczy się mapowania z tokenów audio na tokeny semantyczne. Dalszy proces przypomina proces AudioLM.
MusicLM, oparty na AudioLM i MuLan, oferuje trzy najważniejsze zalety:
- Generacja muzyki oparta na opisy tekstowe.
- Włączenie melodii wejściowych aby rozszerzyć funkcjonalność. Na przykład, dostarczając nucącą melodię i instruując MusicLM, aby przekształciła ją w gitarowy riff, model może wygenerować żądany wynik.
- Generowanie długich sekwencji na dowolny instrument muzyczny.
Zbiór danych
Zbiór danych używany do trenowania MusicLM obejmuje ok 5,5 tys. par muzyka-tekst. Ten zbiór danych obejmuje ponad 200 000 godzin muzykiw towarzystwie bogate opisy tekstowe dostarczane przez ludzkich ekspertów. Google udostępnił ten zestaw danych na Kaggle o nazwie MusicCapsi jest w tej chwili dostępny dla publiczności.
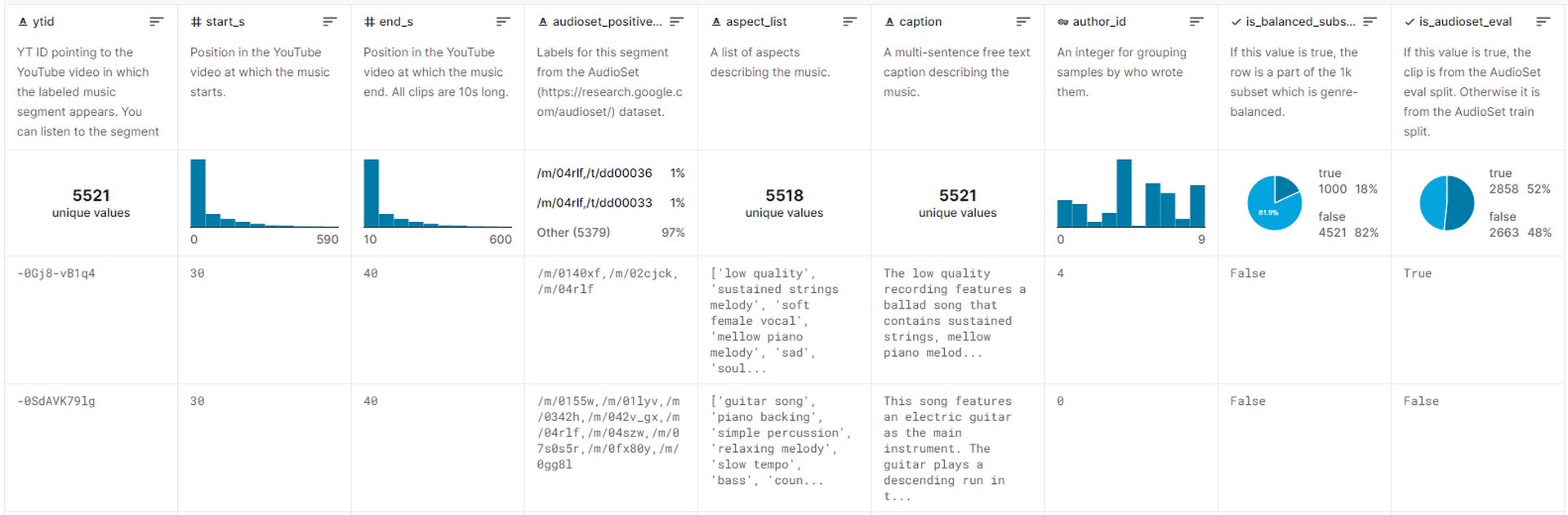 Jak korzystać z Google MusicLM: Przegląd zbioru danych MusicLM
Jak korzystać z Google MusicLM: Przegląd zbioru danych MusicLMGenerowanie muzyki dzięki MusicLM
Niestety, Google w tej chwili nie planuje dystrybucji modeli związanych z MusicLM, powołując się na potrzebę dodatkowej pracy. Jednak biała księga opublikowana przez Google zawiera liczne przykłady pokazujące, w jaki sposób można generować muzykę dzięki opisów tekstowych.
Oto kilka podejść do generowania muzyki dzięki MusicLM:
- Bogate napisy: Dostarczać szczegółowe opisy jak „Główna ścieżka dźwiękowa gry zręcznościowej. Jest szybki i optymistyczny, z chwytliwym riffem gitary elektrycznej. Muzyka jest powtarzalna i łatwa do zapamiętania, ale zawiera nieoczekiwane dźwięki, takie jak trzaski talerzy lub bębny”, MusicLM może tworzyć muzykę, która pasuje do określonych kontekstów i wymagań.
- Długie pokolenie: Takie podejście obejmuje generowanie ciągłego i wysokiej jakości dźwięku przez dłuższy czas, na przykład 5 minut. Używając monitów, takich jak „Heavy metal” lub „kojące reggae”, użytkownicy mogą uzyskać muzykę w pożądanym gatunku i stylu.
- Tryb opowieści: Godną uwagi cechą MusicLM jest możliwość generowania sekwencji muzycznej na podstawie serii podpowiedzi tekstowych. Na przykład określając różne odstępy czasowe i odpowiednie działania, takie jak „czas na medytację (0:00-0:15)“, “pora wstawać (0:15-0:30)„i tak dalej, użytkownicy mogą organizować muzyczną podróż.
- Warunkowanie tekstu i melodii: Takie podejście pozwala użytkownikom tworzyć muzykę zgodną z podaną melodią, np sekwencja buczenia lub gwizdów z poszanowaniem podanego monitu tekstowego. Zasadniczo konwertuje jedną sekwencję audio na żądane wyjście.
- Kondycjonowanie napisów malarskich: MusicLM może generować muzykę na podstawie opisów obrazów. Na przykład, podając opis słynnego dzieła sztuki Salvadora Dali „Trwałość pamięci“, modelka potrafi tworzyć muzykę inspirowaną konceptami i obrazami obrazu.
- Miejsca: Opisy konkretnych miejsc lub środowisk mogą służyć jako zachęty do generowania muzyki. Na przykład, używając opisu typu „słoneczny i spokojny czas na plaży„, MusicLM może generować muzykę, która zawiera esencję tego ustawienia.
Dodatkowe przykłady obejmują generowanie dźwięku 10s z tekstu, biorąc pod uwagę poziomy doświadczenia muzyków, epoki, a choćby solówki akordeonowe. MusicLM oferuje wszechstronny zestaw możliwości generowania muzyki w różnych domenach i scenariuszach.
Imponujące możliwości generowania MusicLM muzyka o wysokiej wierności pokazać niezwykły potencjał ludzkiej kreatywności, zamiast polegać wyłącznie na algorytmach sztucznej inteligencji. Jednak ten postęp również podnosi obawy etyczne I może napotkać opór środowiska muzycznegopodobnie jak modele generujące obrazy, takie jak Dalle i ChatGPT.
 Jak korzystać z Google MusicLM: Duża pojemność MusicLM ekscytuje fanów muzyki generowanej przez AI na przyszłość
Jak korzystać z Google MusicLM: Duża pojemność MusicLM ekscytuje fanów muzyki generowanej przez AI na przyszłośćBadacze Google potwierdzają kwestie etyczne związane z systemem takim jak MusicLM, w tym potencjał włączenie chronionych prawem autorskim treści z danych treningowych do wygenerowanych utworów. Odkryli to podczas eksperymentów 1% muzyki generowanej przez system bezpośrednio odtwarzało utwory z danych treningowych. Ten procent został uznany za wysoko wydać MusicLM w obecnej formie.
Chociaż jest mało prawdopodobne, aby MusicLM stała się publicznie dostępną aplikacją w najbliższej przyszłości, możemy spodziewać się pojawienia się otwartych modeli muzycznych, które mogą zostać poddane inżynierii wstecznej przez niezależnych programistów. Przyszłość trzyma ekscytujące możliwości za wykorzystanie modeli językowych w celu zwiększenia kreatywności i ekspresji muzycznej przy jednoczesnym zapewnieniu odpowiedzialnego i etycznego korzystania z tych technologii.








