Dzisiaj będzie kontynuacja dwóch poprzednich wpisów (1 i 2) dotyczących sposobów wykrywania plagiatów. Dzisiaj będzie ostatni wpis z tej serii. Opiszę w nim kolejne 3 sposoby wykrywania plagiatów.
Systemy bazujące na analizie drzewa wyprowadzeń
Systemy opierające się na analizie drzewa wyprowadzeń wyszukują podobieństwa między programami poprzez wyszukiwanie identycznych lub podobnych poddrzew w drzewie wyprowadzeń.
System CloneDR
System CloneDR jest komercyjnym systemem stworzonym przez firmę Semantic Designs. Działanie systemu opiera się na sprowadzeniu kodu źródłowego programu do drzewa wyprowadzeń, a następnie każda para drzew dwóch programów jest testowana w 3 fazach:
- wykrywanie identycznych i bardzo podobnych powtórzeń poddrzew w badanych drzewach
- wykrywanie powtórzeń deklaracji w kodzie
- wykrywanie podobnych poddrzew, które nie zostały znalezione w pierwszej fazie
Na podstawie danych zebranych podczas tych trzech faz algorytmu system decyduje o prawdopodobieństwie zajścia plagiatu.
Systemy bazujące na analizie grafu zależności
Systemy opierające się na analizie grafu zależności opierają się na budowie i badaniu grafu zależności programów.
System GPlag
Analizowane dane w system GPlag są reprezentowane przez grafy zależności i przepływu danego programu.
Szukanie podobieństw polega na szukaniu izomorficznych podgrafów pomiędzy dwoma drzewami programów.
Systemy bazujące na aproksymacji złożoności Kołmogorowa
Podejście do wykrywania plagiatów poprzez złożoność Kołmogorowa stawia na szukanie podobieństw w ilości informacji niesionych przez program.
Teraz będzie ciężko…
Niech  będzie ciągiem wszystkich maszyn Turinga zakodowanych dzięki słów nad alfabetem
będzie ciągiem wszystkich maszyn Turinga zakodowanych dzięki słów nad alfabetem  . dla wszystkich słowa
. dla wszystkich słowa  możemy zdefiniować jego złożoność Kołmogorowa względem
możemy zdefiniować jego złożoność Kołmogorowa względem  jako
jako

A co to znaczy bardziej po ludzku?
Intuicyjnie można powiedzieć, iż złożonością Kołmogorowa jest wielkość najmniejszego ciągu, z którego można odtworzyć ciąg x.
Ideą działania systemów opierających się na aproksymacji złożoności Kołmogorowa jest znalezienie właśnie tej aproksymacji dla wszystkich programu poprzez kompresje danego ciągu.
W przypadku systemów do wykrywania plagiatów przez  określa się długość mierzoną w danej jednostce (np. bajty) najkrótszego programu, który dla pustego wejścia zwróci na wyjściu x. Przez
określa się długość mierzoną w danej jednostce (np. bajty) najkrótszego programu, który dla pustego wejścia zwróci na wyjściu x. Przez 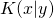 rozumie się warunkową złożoność Kołmogorowa. Określa ona ile nowych informacji wnosi napis x, w przypadku kiedy mamy już dany napis y.
rozumie się warunkową złożoność Kołmogorowa. Określa ona ile nowych informacji wnosi napis x, w przypadku kiedy mamy już dany napis y.
Odległość między dwiema złożonościami Kołmogorowa jest definiowana jako:
 , gdzie:
, gdzie:
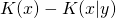 określa ile informacji o słowie x znajduje się w słowie y.
określa ile informacji o słowie x znajduje się w słowie y.
System SID
Ideą działania algorytmu SID jest tokenizacja ciągu wejściowego, jego kompresja oraz przybliżenie złożoności Kołmogorowa.
Pierwszym etapem systemu SID jest zamiana kodu programu źródłowego na ciąg Tokenów przy użyciu parsera.
W kolejnym etapie ciąg tokenów jest poddawany silnej kompresji bezstratnej algorytmem TokenCompress. Twórcy systemu oparli swój algorytm kompresji na algorytmie LZ z pewnymi modyfikacjami. Istotne było uzyskanie jak największego stopnia kompresji, kosztem czasu kompresji.
Aproksymacja 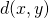 jest liczone w następujący sposób:
jest liczone w następujący sposób:
 , gdzie:
, gdzie:
 jest skompresowaną wielkością słowa x.
jest skompresowaną wielkością słowa x.
Im obliczona wartość jest bardziej zbliżona do 0 tym odległość w sensie informacyjnym jest między programami mniejsza i tym samym jest większe prawdopodobieństwo, iż programy są do siebie podobne.
Podsumowanie
Tak jak wspomniałem we wstępie, wpisem tym kończę przegląd istniejących sposobów wykrywania plagiatów. Z wszystkich wymienionych sposobów wybiorę jeden i będę starał się go zaimplementować, a następnie przetestować w praktyce




.jpg)



