
Prelegenci opowiadali o tym w jaki sposób tworzyć środowiska developerskie, a adekwatnie ich konfiguracje i obrazy, aby później można było je gwałtownie odtworzyć np. na nowej maszynie. Chłopaki bardzo sprawnie i płynnie mówili, widać, iż przećwiczyli to wystąpienie wcześniej. Ale niestety używali w swoich wypowiedziach sporo skrótów, które nie koniecznie musieli wszyscy znać. Pokazywali również sporo detalów, a zabrakło mi jakiegoś big picture, co do czego jest, oraz czym różnią się opisywane rozwiązania.
I tak oto było o następujących narzędziach: Packer.io, Puppet, Vagrant, Ansible, Chef, Salt, Fabric, Docker i Fig (nakładka na dockera). Niestety z powodu znikomej znajomości tematu nie jestem w stanie nic więcej tutaj napisać.
Git nie dla początkujących, Tomasz Borek
Tomek na początku przedstawił różnicę, pomiędzy surowym repozytorium (utworzonym z flagą --bare), a zwykłym repozytorium. Dalej już było ciekawiej. Prelegent pokazywał, co tak naprawdę jest potrzebne w katalogu .git, aby istniało repozytorium. I tak są to katalogi: objects i refs/heads oraz plik HEAD z zawartością (np.: „ref: refs/heads/master”). interesująca sztuczka, ale trwała trochę za długo i prelegent miał problemy z koordynacją, tj. czy klepać w klawiaturę, trzymać mikrofon, stać, siedzieć, czy mówić do mikrofonu stojącego na biurku (o którym później prelegent kompletnie zapomniał).
To było trochę jako ciekawostka, ale Tomek omówił również, po co są pozostałe katalogi i pliki. I tak w description jest opis projektu, który nie jest nigdzie pushowany i prawie nigdzie nie używany. W info/exclude można zignorować pewne pliki, których nie chcemy wersjonować. Przydaje się to w momencie, gdy mamy jakiś plik z ustawieniami lub hasłami, który tylko lokalnie powinien być dostępny, a z jakiś powodów nie chcemy go ignorować dzięki .gitignore.
Jeszcze było o wewnętrznej budowie commit’a. Ogółem git’a można potraktować jak acykliczny graf skierowany. Pojedyńczy commit może wskazywać na drzewo lub inne commity, drzewo wskazuje na BLOBy lub drzewa, a w BLOBach zapisywana jest zawartość plików. Co ciekawe, to nazwy plików nie są zapisywane w BLOBie, a w drzewie. Dlatego łatwo jest wykrywać zmiany położenia plików, choćby jak częściowo zmieni się zawartość.
Było jeszcze o root-commit’cie, który jest praojcem wszystkich commit’ów. Jak jakiś inny commit nie jest w stanie osiągnąć tegoż praojca, to znaczy, iż jest wiszącym commit’em i można go usunąć. Swoją drogą ciekawi mnie, skąd się biorą takie wisielce? Chyba jak nie usuwamy niezmerge'owanych branchy z flagą -D, lub jakiś pojedynczych commit'ów, to nie powinno dochodzić do takich sytuacji.
Dalej było wspomniane, iż nie warto wrzucać duże pliki do repozytorium. choćby jak te pliki tam umieścimy, a następnie usuniemy, to i tak strasznie nam to spowolni pracę z git’em. A ciężko takie coś usunąć z historii tak, aby jej nie popsuć.
Oczywiście ta prezentacja nie mogłaby się odbyć z pominięciem tematu funkcji skrótu SHA1. Organizacja NIST(National Institute of Standards and Technology), która to ogłosiła ten algorytm, w tej chwili wycofuje się z niego i zaleca zastąpienie go SHA3. Ale w Gitcie ta funkcja skrótu nie jest wykorzystywana w celach kryptograficznych a identyfikacyjnych, więc zagrożenie jest naprawdę niewielkie. Co prawda można wygenerować plik, który będzie nam kolidował z czymś w repozytorium, ale na to pewnie też się znajdzie obejście. Po za tym zmiana funkcji hashującej wymusiłaby zmianę protokołów git’a, a ta jest dodatkowo tak zoptymalizowana, iż trafia z chache CPU.
SHA1 jest wykorzystywana w Gitcie do identyfikowania commitu i innych obiektów. Dla commitów wystarczają nam zwykle pierwsze 6, lub 8 znaków tegoż skrótu. Największy otwarty znany projekt hostowany na Gicie, czyli linux kernel, potrzebuje 12 znaków do identyfikacji commit’a. Wartości te są widoczne w .git/objects i są one pogrupowane w podkatalogi, aby nie osiągnąć maksymalnego limitu ilości plików w jednym katalogu i aby można było je gwałtownie odszukać.
Było jeszcze o różnicy w sposobie przechowywania zmian w gitcie, a w SVNie. I tak SVN przechowuje różnice w plikach. Natomiast Git przechowuje całe pliki i gdy się nic w nich nie zmienia, to aktualizuje tylko wskaźnik na aktualną wersję pliku. Nie jest to do końca prawdą, gdyż gdy repozytorium nam rośnie, to git przechowuje stare rewizje również jako różnice w pliku i dodatkowo je kompresuje. Najnowsza wersja jest zawsze przechowywana jako pełen plik, gdyż najczęściej jej potrzebujemy. Dodatkowo Git został zoptymalizowany pod względem ilości zajmowanego miejsca na dysku.
Tomek wspomniał również o komendzie add w trybie interaktywnym, gdzie można wybrać, które zmiany w danym pliku wejdą do commita. Było również o takich poleceniach jak squash (pozwala złączyć commity w jeden), rebase (modyfikuje historię) i instaweb. Ta ostatnia komenda git’a pozwala przeglądać historię repozytorium przez przeglądarkę. Niestety funkcjonalność ta, póki co, nie działa w mysysgit na Windowsie(#11).
Z rzeczy poza Gitem z prezentacji dowiedziałem się o fajnej powłoce ZSH i o nakładce na nią ze zbiorem fajnych rozszerzeń: Oh My ZSH.
Prezentacja bardzo fajna. Spodziewałem się trochę więcej o komendach typu plumbing i tego co się pod spodem dzieje, gdy wywołujemy komendy typu porcelain. Ale o tym można sobie doczytać (nawet po polsku) w książce Pro Git 9. Mechanizmy wewnętrzne w Git, a prezentacja Tomka była dobrym wstępem do tego.
Po tej prelekcji niestety zmarnowałem trochę czasu w chodzeniu po stanowiskach sponsorskich, ale mówi się trudno. Ominięte wykłady oglądnę, gdy już zostaną opublikowane.
Clean architecture - jak uporządkować architekturę Twojej aplikacji. Wnioski z projektu. Andrzej Bednarz
Prelegent opowiadał, o swoim greenfield projekcie, w którym wraz z zespołem postanowili poszukać dobrej architektury. W tym celu przejrzeli to, co wielkie autorytety tego świata mówią i piszą w tym temacie i zaczęli podążać ścieżką promowaną przez Wujka Boba, a mianowicie Clean architecture.
Podejście nie jest jakoś szczególnie nowe. Mówi o odseparowaniu GUI i baz danych od naszej logiki. Każda sensowna architektura o tym mówi. najważniejsze w czystej architekturze jest odwrócenie zależności, tj. aby nasz core aplikacji NIE był zależny od bazy danych, frameworka GUI i innych komponentów. Czyli w naszych encjach powinniśmy przechowywać przykładowo datę w formacie typowym dla daty, a nie zdeterminowanym przez bazę danych, czy ORM. Innymi słowy, musimy mieć zależności DO naszej aplikacji. Więcej powinien wyjaśnić ten rysunek ze strony Wujka Boba:
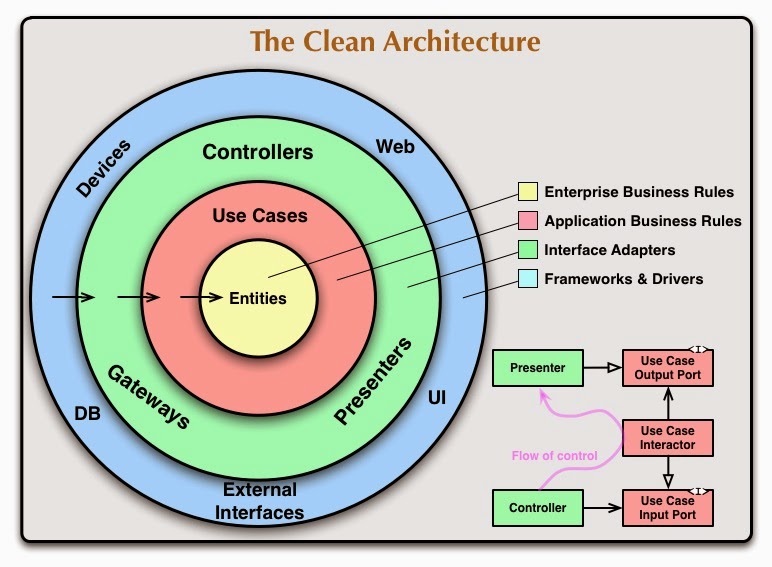
Podejście takie powoduje, iż nie jesteśmy uzależnieni od używanych framework'ów i możemy je łatwo wymienić. Zyskujemy również na łatwości testowania naszej logiki biznesowej. Architektura ta wymusza jednak pewien narzut na tworzenie warstw abstrakcji, wielu DTO i konwersji między różnymi obiektami.
Prezentacja była ogółem fajna. Andrzej pokazał na przykładzie kodu, jak to wygląda u niego w projekcie. Osobiście zabrakło mi trochę porównania w kodzie, z typową architekturą 3warstwową, aby móc uświadczyć różnice. Wadą wystąpienia było patrzenie prelegenta przez plecy, na kod wyświetlany na ścianie, aby pokazywać gdzie coś jest. Jak by nie można było włączyć odpowiedniego trybu pracy z rzutnikiem.
JVM and Application Bottlenecks Troubleshooting with Simple Tools Daniel Witkowski
W tym roku było sporo wykładów na Confiturze dotyczących szybkości działania tworzonych przez nas aplikacji. Prelegent pokazał kilka prostych sztuczek, jak wyłapywać problemy w naszych aplikacjach.
Na początku trzeba ustalić nasze wymagania jakościowe, czyli SLA, czas odpowiedzi, ile requestów na sekundę musimy wytrzymać itd. Następnie prelegent odpalił przygotowaną aplikację, „klikający” w nią JMeter i obserwowaliśmy, co nam pokazuje nam JVisualVM. I gdzieś tam chyba z Thread Dump’a wyczytaliśmy, iż gdzieś jest manualnie wywoływany Garbage Collector. Oczywiście wiadomo, iż to jest zła praktyka, ale można zawsze ją wyłączyć, dzięki flagi -XX:+DisableExplicitGC.
Będąc już przy temacie GC, to warto zawsze zapisywać logi z jego działania i przeglądać dzięki GCViewer.
Inną pożyteczną wiadomością, jaką ze sobą niesie JVisualVM, jest podgląd wątków. Można tam przykładowo sprawdzić, czy liczba wątków http (przyjmujących żądania) jest taka jak się spodziewamy. Gdy będzie tylko jeden, to nie dobrze, bo requesty będą obsługiwane sekwencyjnie.
Wykres aktywności wątków, może również pokazać nam problemy z synchronizacją i blokowaniem się. Może to świadczyć o niewłaściwym użyciu słówka synchronized (np. na metodzie doGet()) lub innych mutex’ów. jeżeli widzimy, iż wiele wątków nam się blokuje, to musimy znów w Thread dumpie szukać miejsc, gdzie coś może być nie tak.
Warto też spojrzeć, czy nie mamy problemów z odczytem / zapisem na dysku. W Linuxach można to sprawdzić dzięki top’a, a na Windowsie poprzez Process Explorer. I tak jeżeli dyski nie wyrabiają, może to oznaczać, ze mamy włączony za wysoki poziom logowania. Przy tej okazji w końcu zrozumiałem zasadność takich zapisów:
if(log.isDebugEnabled()) {
log.debug(createLogMessage());
}
Jeśli ktoś napisze jakieś długotrwające operacje w metodzie createLogMessage(), to powyższy if, spowoduje, iż nie będą ona wykonywane, gdy są i tak niepotrzebne. I tu bardzo fajnie widać wyższość Scali, gdzie taki argument mógłby być wyliczany w razie potrzeby.
Ponadto jakie nie wiemy w jaki sposób jest zaimplementowane isDebugEnabled(), to lepiej odczytać tą wartość raz i trzymać gdzieś w systemie.
Na koniec była jeszcze (na szczęście krótka) reklama narzędzia Zing Vision, jako iż prelegent jest przedstawicielem Azul Systems. Firma ta jest również producentem maszyny wirtualnej Zing, która wg. producenta jest lepsza od implementacji Oracla.
Working with database - still shooting yourself in the foot? Piotr Turski
Prezentacja Piotrka bardzo mi się podobała, gdyż w moim projekcie doszliśmy do prawie tych samych wniosków co prelegent, a o drobnych różnicach mogliśmy sobie porozmawiać na Spoinie.
Piotrek korzysta w swoim projekcie z dwóch baz: H2 i Oracle. Jednak H2 nie do końca sprawdzała się w testach, gdyż czasem pojawiały się błędu specyficzne dla Oracla. Przykładowo w klauzurze in nie może być więcej niż 1000 elementów. Jest to dość znany problem, ale u Piotrka wyszło to dopiero na produkcji. Innym problemem było wykorzystywanie specyficznych możliwości „wyroczni” w zakresie wyszukiwania po umlautach (üöä). H2 tego nie obsługiwało, więc nie dało się testować. Innym problemem był typ Date, który na Oracle, inaczej jak na H2, po za datą zawiera również dokładną godzinę.
Z tych powodów w projekcie prelegenta testy integracyjne puszczano na Oracle, i każdy developer miał pod ręką dla siebie takową bazę. H2 nie zostało jednak wyrzucone z projektu (mimo 3 rund rozmów na ten temat), gdyż jest lżejsze, szybsze, i tylko kilka funkcjonalności na nim nie działa.
W takim wypadku, warto mieć mechanizm czyszczenia bazy na potrzeby testów. Można to załatwić DbUnit’em, ale utrzymywanie plików z danymi jest kosztowne. Po za tym narzędzie to nie zresetuje sekwencji. Można próbować również próbować przywracać dane z backup’a, ale to również może prowadzić do innego stanu bazy. Problematyczne jest tutaj usuwanie constraint’ów i powiązanych z nim index’ów. Dlatego warto wygooglać, jak można resetować bazę na Oraclu i dopasować rozwiązanie do własnych potrzeb.
Przy takich akrobacjach, warto zadbać o proces wprowadzania zmian na bazie danych. Piotrek używał w tym celu flyway, a ja u siebie korzystałem z liquibase. Nie można wtedy niestety manualnie robić hotfix’ów. Zaletą jest to, iż do testów można wtedy budować bazę tak samo jak na produkcji.
Warto również wprowadzić mechanizm testu „produkcyjnego deploymentu”. Chodzi o to, aby zgrywać stan z produkcyjnej bazy danych (schemat i dane) i wykonać deployment aplikacji (co wymusza wykonanie migracji). Zyskujemy wtedy pewność, iż nic nie powinno się posypać przy roll out’cie.
Było jeszcze trochę o testowaniu integracyjnym z bazą danych, np., gdy chcemy sprawdzić HQL’a. Można do tego zaprząc wspomnianego już DbUnit’a, ale analizowanie później czemu test się wywalił, jest czasochłonne. Lepiej przygotować dane do testów w teście. Przecież i tak mamy prawdopodobnie możliwość zapisywania naszych encji w bazie, więc możemy to wykorzystywać w setupie naszych testów. Warto również przy tej okazji skorzystać z Builder’ów.
Programowanie JEE'ish bez stresu Jakub Marchwicki
Prelegent opowiadał na początku o tym, iż warto czasem zbudować jakąś aplikację, wykorzystując inne technologie, niż standardowy Spring, Hibernate i JSF. Pozwala nam to przypomnieć, co te technologie załatwiają za nas, oraz jak działają pewne rzeczy na niższym poziomie. Do tego są lekkie, a przecież nie zawsze potrzebujemy tych wszystkich kombajnów, aby skosić 2m² trawnika.
I tak Jakub pokazał kilka alternatywnych rozwiązań:
Opisywane przykłady, można sobie tutaj przejrzeć: github.com/kubamarchwicki/micro-java
Zakończenie konferencji.
Na zakończenie konferencji było jeszcze losowanie nagród, wręczanie statuetek, podziękowania dla wolontariuszy itd. Szkoda, iż część konkursów była wcześniej rozwiązywana, tj. w przerwach międzywykładowych. Niszczyło to szansę potencjalnych zwycięzców. Oganizatorzy od razu zapowiedzieli, iż rejestracja w przyszłym roku będzie poprawiona i nie będzie tak długiej kolejki. Trzymam za słowo.
Na koniec była jeszcze impreza: Spoina, gdzie można było jeszcze trochę pogadać, zjeść pizzę, napić się piwka i pograć w kręgle. Bardzo fajne zwieńczenie tej konferencji, na którą 1400 wejściówek rozeszło się w 2 godziny od rozpoczęcia rejestracji.
Organizatorzy namawiali jeszcze do udziału w siostrzanej konferencji tj: w Warsjawie. A ja ze swojej strony dziękuję za super konferencję i zachęcam do nowej inicjatywy dBConf.




.jpg)



