ksqlDB to rozwiązanie z rodziny Apache Kafka i Confluent. Pozwala na wykorzystanie języka SQL do definiowania zadań przetwarzania strumieniowego. Wpis ten zaczyna serię o ksqlDB. Spróbujemy zrobić coś fajnego na podstawie danych z Packetbeat’a (monitoring ruchu sieciowego) i zobaczymy jak to dalej się rozwinie.
Co to jest ksqlDB?
ksqlDB (wcześniej ksql) to platforma do budowania aplikacji przetwarzających strumienie danych z Kafki (O Apache Kafka dowiesz się z mojego filmu na YT). Pod spodem działa Kafka Streams, czyli biblioteka do budowania aplikacji przetwarzających dane z i do Kafki.
DB sugeruje, iż jest to strumieniowa baza danych. Coś w tym jest. Mamy do dyspozycji strumienie, tabele, widoki zmaterializowane, zapytania, a przede wszystkim operujemy SQL’em.
Dlaczego SQL jest tak dużą zaletą? Na moim blogu znajdziesz serię wpisów o Kafka Streams. Utworzenie aplikacji Kafka Streams wymaga posiadania IDE, wiedzy programistycznej, zbudowania aplikacji, czyli jest to złożony i skomplikowany proces. Napisanie kilku linijek SQL w ksqlDB jest znacznie szybsze. Spark SQL, Flink SQL, Beam SQL… okazuje się, iż SQL jest spoko .
ksqlDB w Cybersecurity?
ksqlDB zwrócił moją uwagę nie bez powodu. Okazuje się, że można tłumaczyć reguły sigma na zapytania właśnie w ksqlDB. Reguły sigma są to takie generyczne moduł detekcji, które możemy przetłumaczyć na dowolne inne rozwiązanie (Splunk, Elasticserach, QRadar itp.)

Jako osoba łącząca światy Big Data i Cybersecurity, widzę tu spory potencjał . Możliwość detekcji na danych które jeszcze nie są w SIEM’ie (a może nie muszą być?) daje spore możliwości architektoniczne. No ale temat potencjału ekosystemu Kafki w rozwiązanich Security zostawię na inny artykuł.
Problem
We wpisie postaramy się wykorzystać ksqlDB do rozwiązania problemów dotyczących monitorowania komunikacji sieciowej (np. Netflow, flowy z Packetbeat/Zeek/Suricata). Póki co wpadły mi do głowy takie:
- Wolumen danych jest ogromny. choćby “bezczynne” stacje mogą generować dużą liczbę zapytań sieciowych. – Spróbujemy zagregować dane w oknach 1 minuty po adresach ip i portach. Powinno to znacznie ograniczyć rozmiar danych zachowując jednocześnie potencjał analityczny.
- Liczenie liczności zabioru to nie lada problem(dla zbiorów o dużej liczności), a skanowanie sieci można wykrywać na podstawie unikalnej liczby adresatów i portów w czasie. – Niektóre rozwiązania podają przybliżone wyniki, np. Cardinality aggregation w Elasticsearch oraz Terms Query o czym napisałem artykuł. Przygotowane agregaty przyśpieszą detekcje.
W tym przypadku użyję Packetbeat’a, czyli aplikacji ze stajni Elastic do monitorowania sieci.
Jeśli masz więcej pomysłow, daj znać .
Środowisko
Kilka VM’ek, jedna z Packetbeatem, druga z Kafką i ksqlDB, trzecia do robienia “hałasu”.
Apache Kafka + Zookeeper + ksqlDB
Poniżej docker-compose.yml ze strony https://ksqldb.io. jeżeli chcesz wystawić Kafkę poza localhost, zmień wartość z KAFKA_ADVERTISED_LISTENERS na adres ip lub nazwę hosta.
--- version: '2' services: zookeeper: image: confluentinc/cp-zookeeper:7.0.0 hostname: zookeeper container_name: zookeeper ports: - "2181:2181" environment: ZOOKEEPER_CLIENT_PORT: 2181 ZOOKEEPER_TICK_TIME: 2000 broker: image: confluentinc/cp-kafka:7.0.0 hostname: broker container_name: broker depends_on: - zookeeper ports: - "29092:29092" environment: KAFKA_BROKER_ID: 1 KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181' KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://broker:9092,PLAINTEXT_HOST://localhost:29092 KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1 KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0 KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1 KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1 ksqldb-server: image: confluentinc/ksqldb-server:0.22.0 hostname: ksqldb-server container_name: ksqldb-server depends_on: - broker ports: - "8088:8088" environment: KSQL_LISTENERS: http://0.0.0.0:8088 KSQL_BOOTSTRAP_SERVERS: broker:9092 KSQL_KSQL_LOGGING_PROCESSING_STREAM_AUTO_CREATE: "true" KSQL_KSQL_LOGGING_PROCESSING_TOPIC_AUTO_CREATE: "true" ksqldb-cli: image: confluentinc/ksqldb-cli:0.22.0 container_name: ksqldb-cli depends_on: - broker - ksqldb-server entrypoint: /bin/sh tty: truedocker-compose up postawi wszystko na nogi.
Packetbeat
Po instalacji w ścieżce /etc/packetbeat.packetbeat.yml znajdziesz plik konfiguracyjny. W moim przypadku:
- Maszyna wirtualna ma dwa interfejsy sieciowe. Jeden z nich ustawiłem w tryb nasłuchu (ip link set nazwa_interfejsu promisc on). W konfiguracji można wskazać konkretny interfejs na którym słuchamy packetbeat.interfaces.device: nazwa_interfejsu
- Dane lądują bezpośrednio w kafce
no i odpalamy systemctl start packetbeat.
Jeśli wszystko działa to w Kafce powinien pojawić się topic packetbeat. Poniżej użycie aplikacji kafkacat.
maciej@node-01:~/kafka$ kafkacat -b 192.168.63.132:29092 -L Metadata for all topics (from broker 1: 192.168.63.132:29092/1): 1 brokers: broker 1 at 192.168.63.132:29092 (controller) 4 topics: topic "packetbeat" with 1 partitions: partition 0, leader 1, replicas: 1, isrs: 1 topic "_confluent-ksql-default__command_topic" with 1 partitions: partition 0, leader 1, replicas: 1, isrs: 1 topic "default_ksql_processing_log" with 1 partitions: partition 0, leader 1, replicas: 1, isrs: 1 topic "__transaction_state" with 50 partitions: partition 0, leader 1, replicas: 1, isrs: 1 partition 1, leader 1, replicas: 1, isrs: 1 partition 2, leader 1, replicas: 1, isrs: 1 partition 3, leader 1, replicas: 1, isrs: 1 ...ksqlDB
Aby dostać się do CLI ksqldb wpisz docker exec -it ksqldb-cli ksql http://ksqldb-server:8088 .
maciej@node-01:~/kafka$ sudo docker exec -it ksqldb-cli ksql http://ksqldb-server:8088 OpenJDK 64-Bit Server VM warning: Option UseConcMarkSweepGC was deprecated in version 9.0 and will likely be removed in a future release. =========================================== = _ _ ____ ____ = = | | _____ __ _| | _ \| __ ) = = | |/ / __|/ _` | | | | | _ \ = = | <\__ \ (_| | | |_| | |_) | = = |_|\_\___/\__, |_|____/|____/ = = |_| = = The Database purpose-built = = for stream processing apps = =========================================== Copyright 2017-2021 Confluent Inc. CLI v0.22.0, Server v0.22.0 located at http://ksqldb-server:8088 Server Status: RUNNING Having trouble? Type 'help' (case-insensitive) for a rundown of how things work! ksql>Możemy wypróbować SHOW STREAMS oraz SHOW TABLES.
ksql> show streams; Stream Name | Kafka Topic | Key Format | Value Format | Windowed ------------------------------------------------------------------------------------------ KSQL_PROCESSING_LOG | default_ksql_processing_log | KAFKA | JSON | false ------------------------------------------------------------------------------------------ ksql> show tables; Table Name | Kafka Topic | Key Format | Value Format | Windowed ----------------------------------------------------------------- -----------------------------------------------------------------Gdzie strumyk płynie z wolna
Przykładowy rekord
Czas utworzyć strumień na bazie topic’a packetbeat. Strumień wymaga konkretnego schematu. Spójrzmy na przykładowy dokument z kolejki.
{ "@timestamp" : "2021-12-12T16:39:46.106Z", "@metadata" : { "beat" : "packetbeat", "type" : "_doc", "version" : "7.16.0" }, "source" : { "ip" : "192.168.63.1", "port" : 61668, "packets" : 5, "bytes" : 607, "mac" : "00:50:56:c0:00:0b" }, "event" : { "category" : [ "network_traffic", "network" ], "action" : "network_flow", "type" : [ "connection" ], "start" : "2021-12-12T16:39:42.257Z", "end" : "2021-12-12T16:39:42.258Z", "duration" : 59589, "dataset" : "flow", "kind" : "event" }, "flow" : { "id" : "EQQA////DP//////FP8BAAEAUFYxBLMAUFbAAAvAqD+EwKg/AZgf5PA", "final" : false }, "agent" : { "id" : "bc13a45f-d15e-4f8f-9dd8-b8a415c77cba", "name" : "sonda", "type" : "packetbeat", "version" : "7.16.0", "hostname" : "sonda", "ephemeral_id" : "3b163a1e-4015-4269-8bbd-9b5b6ed15275" }, "destination" : { "mac" : "00:50:56:31:04:b3", "ip" : "192.168.63.132", "port" : 8088, "packets" : 4, "bytes" : 691 }, "type" : "flow", "network" : { "community_id" : "1:lDm3gUH3XVecHFO7Rgl1pM9ys7k=", "bytes" : 1298, "packets" : 9, "type" : "ipv4", "transport" : "tcp" }, "ecs" : { "version" : "1.12.0" }, "host" : { "os" : { "type" : "linux", "platform" : "ubuntu", "version" : "20.04.3 LTS (Focal Fossa)", "family" : "debian", "name" : "Ubuntu", "kernel" : "5.4.0-91-generic", "codename" : "focal" }, "id" : "a6be3dd21ef0448e9f1148cc0ce23900", "containerized" : false, "ip" : [ "192.168.63.131", "fe80::250:56ff:fe3e:a6b4", "fe80::250:56ff:fe31:676a" ], "mac" : [ "00:50:56:3e:a6:b4", "00:50:56:31:67:6a" ], "hostname" : "sonda", "architecture" : "x86_64", "name" : "sonda" } }Stream ‘packetbeat’
Nie potrzebujemy wszystkich pól. Ograniczymy się do nadawcy, adresata, typu oraz informacji sieciowych.
CREATE STREAM packetbeat ( "@timestamp" VARCHAR, "type" VARCHAR, destination STRUCT < packets INT, bytes INT, mac VARCHAR, ip VARCHAR, port INT >, source STRUCT < packets INT, bytes INT, mac VARCHAR, ip VARCHAR, port INT >, network STRUCT < community_id VARCHAR, bytes INT, packets INT, "type" VARCHAR, ksqltransport VARCHAR > ) WITH ( kafka_topic='packetbeat', value_format='json', partitions=1 );“Niepoprawne” nazwy kolumn otoczone są " lub '. W sekcji WITH można zdefiniować pole odpowiadające za czas rekordu (TIMESTAMP oraz TIMESTAMP_FORMAT). Prawdopodobnie z powodu nazwy nie mogłem zrobić tego na tym etapie. Zediniujemy to w kolejnej iteracji strumienia.
Zajrzeć w strumień można dzięki SELECT * FROM PACKETBEAT EMIT CHANGES;
ksql> SELECT * FROM PACKETBEAT EMIT CHANGES; +---------------------------+---------------------------+---------------------------+---------------------------+---------------------------+ |@timestamp |type |DESTINATION |SOURCE |NETWORK | +---------------------------+---------------------------+---------------------------+---------------------------+---------------------------+ |2021-12-12T17:08:06.106Z |flow |{PACKETS=981, BYTES=99900, |{PACKETS=1334, BYTES=185319|{COMMUNITY_ID=1:dLXfK8dyy8V| | | |MAC=00:50:56:31:04:b3, IP=1|4, MAC=00:50:56:3e:a6:b4, I|KZRcQtDWxdwExpmE=, BYTES=19| | | |92.168.63.132, PORT=29092} |P=192.168.63.131, PORT=5060|53094, PACKETS=2315, type=i| | | | |2} |pv4, TRANSPORT=tcp} | |2021-12-12T17:08:06.106Z |flow |{PACKETS=202, BYTES=13947, |{PACKETS=205, BYTES=13710, |{COMMUNITY_ID=1:yOSZ3T04I7D| | | |MAC=00:50:56:31:04:b3, IP=1|MAC=00:50:56:3e:a6:b4, IP=1|5ymG8mdUZFO/lsqc=, BYTES=27| | | |92.168.63.132, PORT=29092} |92.168.63.131, PORT=50600} |657, PACKETS=407, type=ipv4| | | | | |, TRANSPORT=tcp} | |2021-12-12T17:08:06.106Z |flow |{PACKETS=11862, BYTES=88076|{PACKETS=5983, BYTES=687565|{COMMUNITY_ID=1:x89DUAxMC1t| | | |7, MAC=00:50:56:31:04:b3, I|, MAC=00:50:56:c0:00:0b, IP|Qo+dR7Sz8qb8xV4g=, BYTES=15| | | |P=192.168.63.132, PORT=2909|=192.168.63.1, PORT=52238} |68332, PACKETS=17845, type=| | | |2} | |ipv4, TRANSPORT=tcp} | |2021-12-12T17:08:06.106Z |flow |{PACKETS=5, BYTES=870, MAC=|{PACKETS=7, BYTES=727, MAC=|{COMMUNITY_ID=1:6ykEYsDO1g6| | | |00:50:56:31:04:b3, IP=192.1|00:50:56:c0:00:0b, IP=192.1|jlUviXxYLxdWxyKE=, BYTES=15| | | |68.63.132, PORT=8088} |68.63.1, PORT=50703} |97, PACKETS=12, type=ipv4, | | | | | |TRANSPORT=tcp} |Stream ‘packetbeat_renamed’
Przy tworzeniu strumienia packetbeat był problem z nazwą dwóch pól. Zrómy kolejny strumień w którym użyjemy aliasów.
CREATE STREAM packetbeat_renamed AS SELECT "@timestamp" as ts, destination, source, network, "type" as flow_type FROM packetbeat EMIT CHANGES;Stream ‘packetbeat_flows’
Załóżmy, iż interesują nas tylko rekordy type = 'flow'. Przy okazji poprawimy też kwestię czasu utworzenia rekordu.
CREATE STREAM packetbeat_flows WITH ( timestamp = 'ts', timestamp_format = 'yyyy-MM-dd''T''HH:mm:ss.SSSX' ) AS SELECT ts, destination, source, network FROM packetbeat_renamed WHERE flow_type = 'flow' EMIT CHANGES;Zwróć uwagę na format znacznika czasu. Tutaj masz ściągę. Przy szukaniu odpowiedniego formatu timestamp’a przydały mi się logi ksqldb. SELECT * FROM... nic nie zwracał przy błędnym formacie (nawet błędu).

Table ‘packetbeat_flows_by_1m’
Tym razem utworzymy tabelę. Będzie to agregacja z wykorzystaniem Tumbling Window o stałym odstępie 1 minuty.
CREATE TABLE packetbeat_flows_by_1m WITH (KEY_FORMAT='JSON') AS SELECT source -> ip as srcip, source -> port as srcport, destination -> ip as dstip, destination -> port as dstport, network -> transport, SUM(source -> packets) as source_packets, SUM(source -> bytes) as source_bytes, SUM(destination -> packets) as destination_packets, SUM(destination -> bytes) as destination_bytes, SUM(network -> packets) as network_packets, SUM(network -> bytes) as network_bytes, COUNT(*) as cnt FROM packetbeat_flows WINDOW TUMBLING (SIZE 1 MINUTE) GROUP BY source->ip, source-> port, destination->ip, destination->port, network->transport EMIT CHANGES;Kod jest dość prosty. Zwróć uwagę na:
- KEY_FORMAT – Format JSON wymagany jest dla kluczy składających się z wielu kolumn.
- -> – W ten sposób odnosimy się do pól w polach typu STRUCT.
- WINDOW TUMBLING (SIZE 1 MINUTE) – Okno o stałej długości 1 minuty które nie nachodzi na siebie.
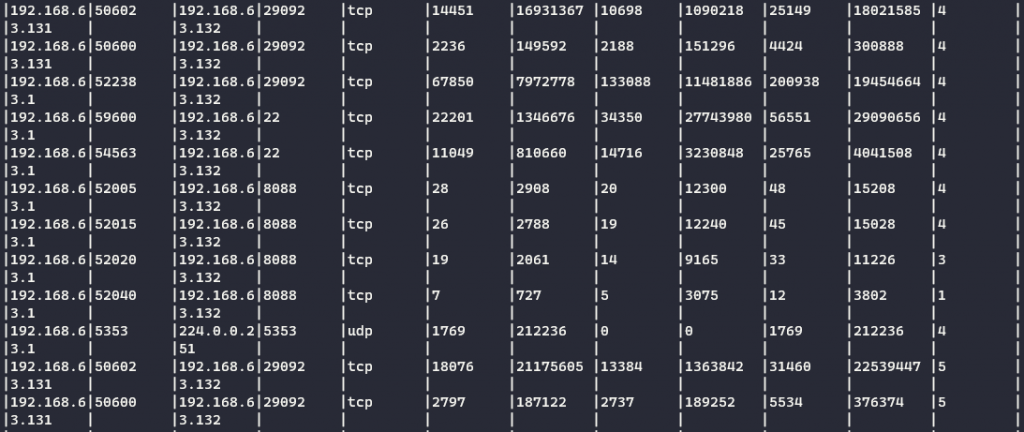 Ostatnia kolumna to COUNT(*). Prawie 50 rekordów zagregowane do 13’tu.
Ostatnia kolumna to COUNT(*). Prawie 50 rekordów zagregowane do 13’tu.Pewnie zastanawiasz się co to jest tabela i czym różni się od strumienia. Tabela jest to odpowiednik topic’a w kafce z kompaktowaniem danych ( log compaction). Polega to na tym, iż rekordy nadpisane (rekord o tym samym kluczu, ale nowszy) znikają z kolejki.
 Konfiguracja tabeli/topic’a wyświetlona w narzędziu Conduktor
Konfiguracja tabeli/topic’a wyświetlona w narzędziu ConduktorW powyższym screenie widać, iż cleanup.policy jest zarówno delete jak i compact. W przypadku samego compact tabela/topic może bardzo spuchnąć, aczkolwiek czasami jest ku temu powód. delete to domyślna polityka dla topicu w kafce (rekordy znikają po tygodniu).
maciej@node-01:~$ kafkacat -t PACKETBEAT_FLOWS_BY_1M -b localhost:29092 -c3 -K : % Auto-selecting Consumer mode (use -P or -C to override) {"SRCIP":"192.168.63.131","SRCPORT":50602,"DSTIP":"192.168.63.132","DSTPORT":29092,"TRANSPORT":"tcp"}}:{"SOURCE_PACKETS":4889,"SOURCE_BYTES":5456387,"DESTINATION_PACKETS":3630,"DESTINATION_BYTES":370056,"NETWORK_PACKETS":8519,"NETWORK_BYTES":5826443,"CNT":1} {"SRCIP":"192.168.63.131","SRCPORT":50600,"DSTIP":"192.168.63.132","DSTPORT":29092,"TRANSPORT":"tcp"}}:{"SOURCE_PACKETS":772,"SOURCE_BYTES":51636,"DESTINATION_PACKETS":755,"DESTINATION_BYTES":52167,"NETWORK_PACKETS":1527,"NETWORK_BYTES":103803,"CNT":1} {"SRCIP":"192.168.63.1","SRCPORT":52238,"DSTIP":"192.168.63.132","DSTPORT":29092,"TRANSPORT":"tcp"}}:{"SOURCE_PACKETS":23272,"SOURCE_BYTES":2713747,"DESTINATION_PACKETS":45827,"DESTINATION_BYTES":3790956,"NETWORK_PACKETS":69099,"NETWORK_BYTES":6504703,"CNT":1}W pobranych danych dzięki kafkacat widać klucz (kolumny po których grupowaliśmy) oraz wartości (w tym przypadku sumy).
Table ‘packetbeat_flow_unique_dest_by_srcip’
Zajmijmy się kolejnym problemem, czyli skanowaniem portów.
CREATE TABLE packetbeat_flow_unique_dest_by_srcip AS SELECT source -> ip as srcip, COUNT_DISTINCT(destination -> ip) as unique_dstip_cnt, COUNT_DISTINCT(destination -> port) as unique_dstport_cnt FROM packetbeat_flows WINDOW TUMBLING (SIZE 1 MINUTE, GRACE PERIOD 1 MINUTE) GROUP BY source->ip EMIT CHANGES;Kod SQL jest dość prosty. Tym razem nie musimy wskazywać formatu klucza. Dodałem GRACE PERIOD, czyli maksymalny czas na jaki pozwalamy “spóźnić się” rekordom z tego okna czasowego. We wcześniejszych wersjach ksqlDB domyślnyą wartością były 24 godziny. Zostało to zmienione w KIP-633.
Returns the approximate number of unique values of col1 in a group. The function implementation uses HyperLogLog to estimate cardinalities of 10^9 with a typical standard error of 2%.Powyższy fragment pochodzi z dokumentacji COUNT_DISTINCT. Pamiętasz jak wspominałem, iż liczenie liczności to nie lada problem?
 Ten 192.168.63.130 jest LEKKO podejrzany…
Ten 192.168.63.130 jest LEKKO podejrzany…Wnioski
ksqlDB zapowiada się obiecująco. Można w znaczny sposób ograniczyć wolumen danych i uprościć dalszą analizę/detekcję.
Co dalej?
Pewnie spróbuję wrzucić wyniki do Elasticsearch’a. Zastanawiam się czy będzie trzeba definiować id dokumentów (w końcu wynik agregacji może się zmienić jak przyjdzie jakaś zguba).
Repozytorium
Utworzyłem repo zorteran/cybersecurity-ksqldb. Zobaczymy, może z czasem wrzucę tam wiecej skryptów związanych z ksqlDB.



![[VIDEO] Przez cztery dni robili zakupy obok bomby. Nikt nie wiedział.](https://dzikizachod.eu/wp-content/uploads/2026/04/IMG_7010_compressed_2026_04_10_094123.webp)







