
W poprzednim artykule, związanym z dość traumatyczną próbą nabycia krzesła, wspomniałam o różnych sposobach sprawdzania naszych produktów i naszego kodu pod kątem dostępności cyfrowej. Teraz chciałabym się zająć tym nieco szerzej, opisując jak można łączyć metody manualne z automatycznymi, czy warto wybrać którąś z nich i co do tego ma tytułowy topór.
Poprzednio wspomniałam, iż w swojej pracy oprócz wykorzystywania technologii wspomagających (chyba nikt jeszcze nigdy nie nazwał tak pięknie używania klawiatury) korzystam również z różnego rodzaju wtyczek oraz manualnego sprawdzania produktu pod kątem konkretnych kryteriów dostępności. Czas to uporządkować i przedstawić cały taki proces.
Jak zwykle do znudzenia będę zastrzegać, że przedstawione i opracowane przeze mnie metody analizy dostępności nie są równoważne z profesjonalnym audytem dostępności. To jest jeden z ważnych etapów, który pozwala następnie przejść do najbardziej interesującej (według mnie) części, czyli tworzenia dostępnego kodu.
Ale – ad rem.
Testy manualne
Cały proces testowania i sprawdzania strony zaczynam od wyboru próby: jak chyba w każdym tego typu badaniu nie skupiam się na każdej z kilkunastu/kilkudziesięciu dostępnych podstron, ale wybieram takie, które są najistotniejsze z punktu widzenia użytkownika. Staram się, żeby w miarę możliwości nie były to pojedyncze podstrony, ale całe procesy. Bo co nam z tego, iż strona sklepu internetowego pozwoli nam, przy użyciu np. wyłącznie klawiatury, wybrać i wrzucić produkt do koszyka, jeżeli już operacja wyboru rodzaju i czasu dostawy nie da nam takiej możliwości? Dlatego warto poświęcić chwilę na wybór odpowiedniego zakresu badanych elementów.
Każdą wybraną stronę/proces sprawdzam przy wsparciu kilku technologii i wtyczek, wymienionych już poprzednio.
Mój żelazny zestaw to aktualnie:
- Contrast Color Checker
- Wave
- NVDA
- Heading Maps
- Lighthouse (polecony mi ostatnio w komentarzu, dzięki!)
- AXE Devtools
- Text spacing bookmarklet
Taki wybór, oczywiście zupełnie subiektywny, pozwala mi zadbać o całkiem sporo elementów w zakresie dostępności: mamy tu zarówno ogólne badanie wielu kryteriów (Wave, Lighthouse, AXE), jak i bardziej szczegółowe badanie kontrastu, hierarchii nagłówków czy odległości między wyrazami.
Do wtyczek zaliczam, może niesłusznie, również czytnik ekranu – ale wyłącznie dlatego, iż jako osoba widząca i niekorzystająca z tej technologii na co dzień mogę to traktować jedynie jako kolejne wsparcie i cenną wskazówkę.
Zastosowanie na badanych stronach tego (lub podobnego) zestawu informacji generowanych automatycznie pozwala mi określić w dość prosty i szybki sposób obszary, które z pewnością będą wymagały głębszej analizy na kolejnym etapie. Pewne rzeczy wyłapiemy od razu (np. to, iż kilkanaście podstron dzieli ten sam tytuł, a wszystkie przyciski mają napis “Kliknij tutaj”), niektóre wraz z doświadczeniem będziemy już nauczeni traktować nieufnie (pola formularzy, nagłówki, slidery z grafikami), ale w identyfikacji niektórych faktycznie mogą nam pomóc wskazane wyżej automaty.
Co dalej?
Gdy już mam przed sobą wyniki takich automatycznych badań, przechodzę do chyba najbardziej angażującej części analizy, czyli manualnego sprawdzenia każdego procesu czy podstrony pod kątem wytycznych i kryteriów zawartych w WCAG 2.1. Posługuję się przy tym dostępnymi w Internecie wszelkiego rodzaju listami, opisami i zestawieniami tychże wytycznych. Nie mogę tu nie wymienić przede wszystkim polskiego tłumaczenia WCAG 2.1, jak i listy kontrolnej przygotowanej przez naprawdę świetnych specjalistów z tej dziedziny.
Faktem jest jednak, iż najwięcej materiałów i szczegółowych opisów każdego z kryterium znajdziemy w oryginale, czyli po angielsku. Warto więc do tego typu treści sięgać jak najczęściej.
Każda ze stron jest więc przeze mnie badana pod kątem odpowiednich kryteriów (w przypadku dostępności na poziomie AA tych kryteriów mamy kilkadziesiąt) – część z nich będzie realizowana bardzo podobnie na każdej z badanych przez nas podstron, ale mimo to warto je każdorazowo sprawdzić. I tu znowu, po jakimś czasie wiemy już na co zwrócić uwagę i co może nam wpadać w konkretne kryteria. Nie da się jednak ukryć, iż jest to proces pracochłonny i czasem dość skomplikowany, szczególnie gdy widzimy na stronie takie elementy, których nie widzieliśmy nigdy dotąd.
Po tym wszystkim wykonuję podsumowanie: informacje na temat każdej podstrony zbieram w jedną wielką analizę serwisu, która pozwala mi określić, z czym przyjdzie się mi i mojemu zespołowi mierzyć na kolejnym etapie. Oprócz wskazania co jest nie tak, staram się od razu opisać proponowane rozwiązania i mechanizmy, jakie możemy zastosować, aby poprawić dostępność naszego produktu. I o ile praca audytora może się w tym miejscu zakończyć, to praca programisty właśnie się zaczyna. Ale o tym, mam nadzieję, w kolejnym artykule.
Testy automatyczne – Playwright i przyjaciele
Zanim przejdziemy do faktycznego tematu artykułu, krótkie wyznanie – nigdy nie powiedziałabym o sobie, iż mam coś wspólnego z działalnością testerską. O ile jeszcze wizja testów manualnych jakoś do mnie przemawia i jest dość zrozumiała (ba, ze zdziwieniem odkryłam ostatnio, iż adekwatnie jest to część mojej pracy) to już testowanie automatyczne i związane z tym oprogramowanie było mi dotąd zupełnie obce. Dlatego gdy w zespole pojawił się temat pisania automatycznych testów w zakresie dostępności to, nie ukrywajmy, mój entuzjazm był znacznie większy niż moje umiejętności. Uznaliśmy jednak wspólnie, iż zbadanie tego tematu przyniosłoby nam korzyść. A szczególnie przydatne może być dla osób, które nie mają czasu i zasobów na opisany powyżej proces testowania manualnego.
Zasugerowane przez kolegów narzędzie – Playwright – okazało się na szczęście naprawdę dobrze opisane (tutaj znajdziecie całą oficjalną dokumentację), a ja dodatkowo mogłam skupić się tylko na tej części związanej z dostępnością cyfrową. Ale tutaj ukryte są pierwsze przysłowiowe grabie, bo dla kogoś zielonego w tym temacie wyzwaniem jest połapanie się zarówno w samej budowie testów, jak i tym, co dzieje się, gdy takie testy odpalimy.
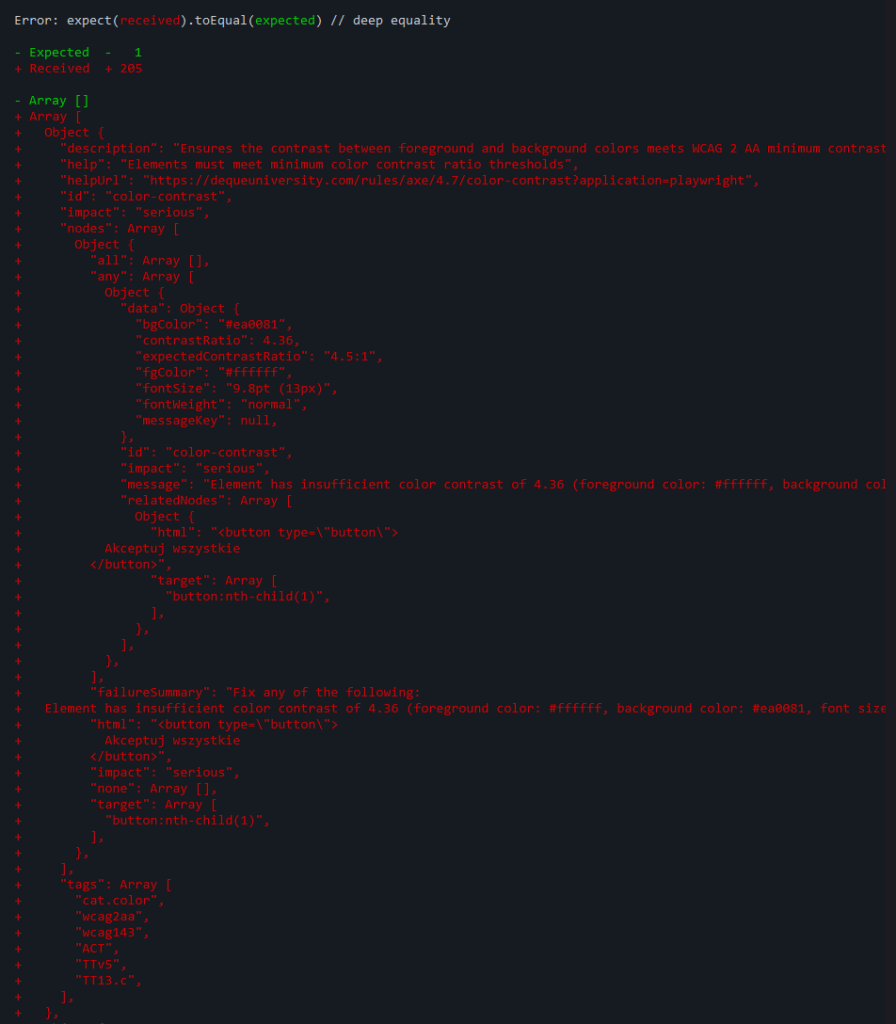 A dzieje się na przykład to.
A dzieje się na przykład to.Na szczęście z pomocą przychodzi internet (i materiały praktycznie w całości w języku angielskim, tak tylko uprzedzam), w którym nie tylko znajdziemy gotowe przykłady takich testów, ale także filmy, w których ktoś krok po kroku powie nam co z tym robi i po co.
Moje pierwsze kroki z testami automatycznymi były jednak koniec końców dość chaotyczne i zanim się zorientowałam, co adekwatnie się dzieje, miałam już w swoim projekcie kilka ogromnych bibliotek wraz z ich znajomymi i przyjaciółmi. Ogólną bibliotekę do testów automatycznych, pakiet do testów dostępności, dodatek do tworzenia ładnych raportów z testów dostępności i wszystko co jeszcze można sobie wymarzyć. Tak to przynajmniej wyglądało na początku z mojej perspektywy. Po przemyśleniu zdecydowałam się na skorzystanie z wciąż dość rozbudowanego zestawu, bazującego przede wszystkim na silniku „axe” czyli tytułowym toporze w służbie dostępności. To narzędzie, które współpracuje m.in. z biblioteką playwright właśnie i pozwala w dość prosty sposób włączyć do naszych testów również te z zakresu dostępności.
Mój zestaw wyglądał więc następująco:
- podstawowa biblioteka Playwright,
- pakiet “@axe-core/playwright”, który rozszerza możliwości tego frameworka właśnie pod kątem dostępności cyfrowej,
- pakiet “axe-playwright”, skupionego już stricte na całościowych testach dostępności i oferującego interesujące rozwiązanie pod kątem raportów.
Przygotowanie plików testowych okazało się dość pracochłonne, ale jednocześnie stosunkowo proste, przede wszystkim dzięki bardzo przydatnym materiałom dodatkowym (jak chociażby ten film o axe-playwright od Asp.Net Monster).
W naprawdę dużym skrócie (tutaj prośba do testerów automatycznych – miejcie litość nad laikiem): zaczynamy od określenia strony, którą chcemy przetestować, a następnie „wstrzykujemy” tam nasz axe-core. Teraz już możemy zacząć pisanie adekwatnych testów – na szczęście dla początkujących wiele przykładów mamy opisanych i adekwatnie gotowych w podlinkowanej wyżej dokumentacji, wystarczy użyć ich w naszym repozytorium. Wszystkie rodzaje, tagi i wartości, które początkowo mogą być dla niektórych niezrozumiałe, znajdziemy z kolei bezpośrednio w AXE API Documentation.
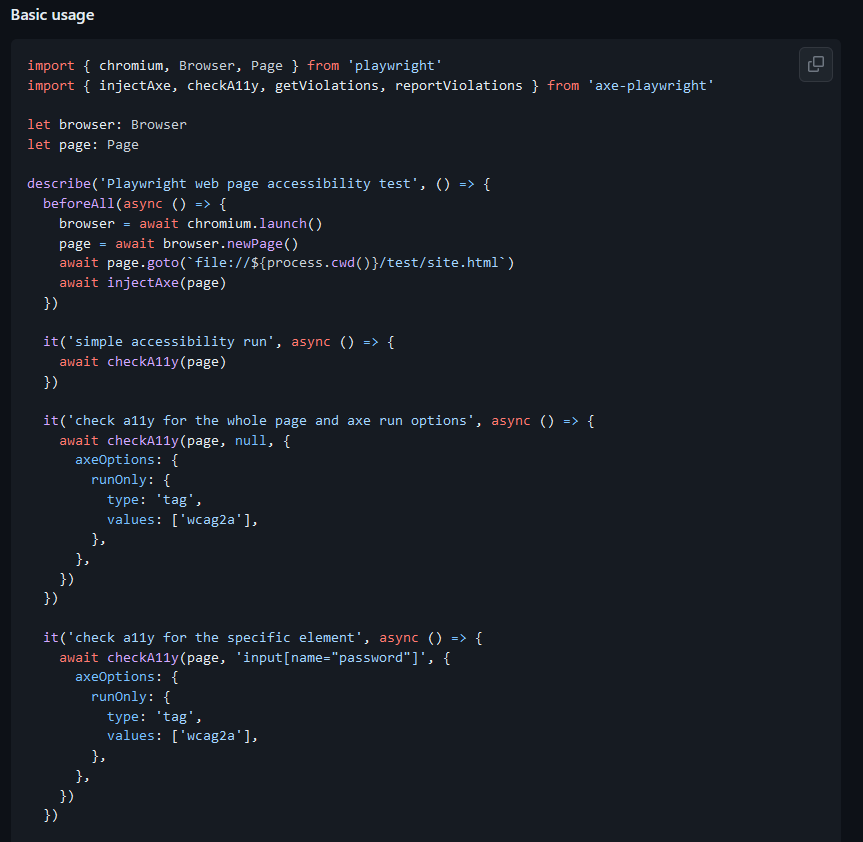 właściwie gotowy przepis na testy na poziomie WCAG 2.0 A
właściwie gotowy przepis na testy na poziomie WCAG 2.0 AW praktyce
Ja zdecydowałam się na stworzenie trzech plików testowych zawierających testy wskazanej przeze mnie aplikacji: oddzielnie na poziomie WCAG 2.1 A (podstawowy), oddzielnie WCAG 2.1 AA (optymalny) oraz dodatkowy plik pozwalający na testowanie wybranych elementów lub wybranych zasad dostępności. Kilka/kilkanaście takich testów w zakresie dostępności można napisać (moim zdaniem) dość sprawnie, jak już oswoimy się z ich sposobem działania i wykonywania. Po napisaniu takich testów przychodzi oczywiście czas na ich wykonanie i tu spotyka nas miłe zaskoczenie: dzięki odpowiednim ustawieniom możemy wygenerować sobie wyniki w naprawdę przyzwoicie skonstruowanym pliku HTML.
// all wcag rules test and save in html file test('Simple accessibility check', async () => { await checkA11y(page, null, { axeOptions: { runOnly: { type: 'tag', values: [ 'wcag21a' ] } } }, undefined, 'html') })Taki raport jest nie tylko przejrzysty i wygodny dla programisty, ale również strawny dla osób niesiedzących na co dzień w kodzie – znajdziemy tam zarówno opis znalezionych nieprawidłowości, rodzaj reguły, który określa dany błąd, konkretne kryterium w WCAG, wagę błędu oraz liczbę jego wystąpień. A to tylko pierwsza tabelka! W kolejnych znajdziemy bowiem (także po zdefiniowaniu odpowiednich parametrów testu) między innymi wskazanie, gdzie bezpośrednio w kodzie znajduje się błąd i co można zrobić, aby go naprawić. To zdecydowanie najlepsza forma feedbacku z testów, jaką udało mi się podczas tych prób uzyskać i która może być najprzydatniejsza dla nie-developerów i osób, które chcą w szybki sposób podsumować sobie znalezione na stronie błędy.
 raport wygenerowany na podstawie jednego z popularnych serwisów informacyjnych – zdecydowanie jest co poprawić…
raport wygenerowany na podstawie jednego z popularnych serwisów informacyjnych – zdecydowanie jest co poprawić…Ale to, co chyba najbardziej mnie zaciekawiło i zachęciło do wykorzystania tego typu testów, to możliwość ich szczegółowej parametryzacji. Wcześniej wydawało mi się, iż takie testy mogą być przydatne na bardzo ogólnym i ograniczonym poziomie, ale nie da się w ten sposób sprawdzić różnych elementów niezależnie od siebie. przez cały czas tak twierdzę, ALE – jeżeli ktoś naprawdę zainteresuje się tematem a dodatkowo ma w tym większe niż ja umiejętności, może stworzyć cały ich zestaw, który bada nie tylko konkretne elementy, jakie chcemy mieć na swoich stronach (np. skip-linki) ale również konkretne, najbardziej kontrowersyjne dostępnościowo elementy interfejsu (wspomniany już slider, menu nawigacyjne czy stopka).
// Test the skip-link test('has a skip-link', async ({ page }) => { await page.goto(testpage) await page.getByRole('link', { name: 'Skip to main content' }).click() // Expects the URL to contain text await expect(page).toHaveURL(/.*page-skip-link/) }) await page.goto(testpage) const accessibilityScanResults = await new AxeBuilder({ page }) .include('.footer') .analyze()Na koniec jeszcze jeden interesujący szczegół: testy wykonujemy równocześnie na różnych przeglądarkach, czyli np. Firefox, Chrome czy Safari. Dzięki temu możemy sprawdzić, czy któryś z naszych elementów nie zachowuje się inaczej ze względu na używaną przez nas przeglądarkę czy system operacyjny.
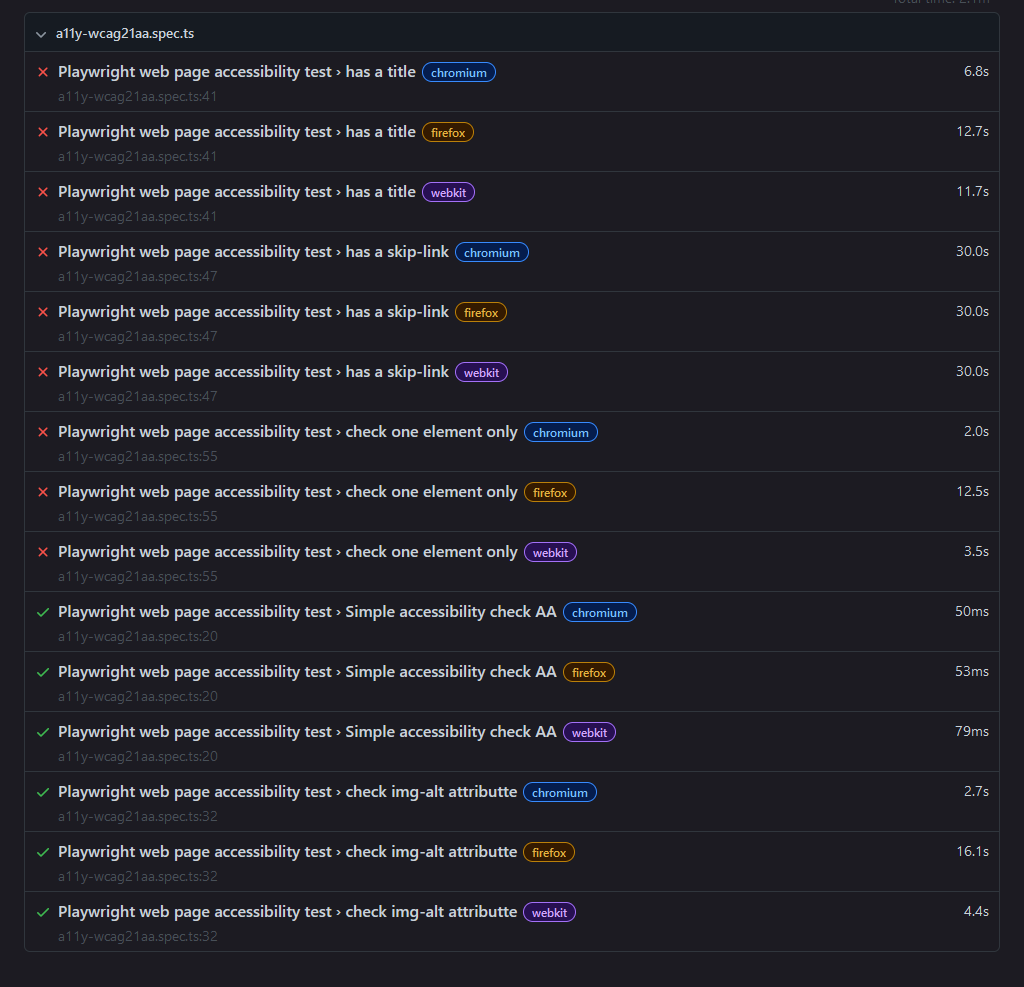 trochę się udało, trochę się nie udało
trochę się udało, trochę się nie udałoAle czy warto?
Zawsze. Ale to już chyba wielokrotnie powtórzyłam w poprzednich artykułach, więc mimo wszystko trochę rozwinę temat.
Przede wszystkim – najwięcej z automatycznego testowania dostępności wyciągną osoby, które się na tym znają, pisanie testów sprawia im przyjemność, a przy tym doskonale wiedzą co robią (czyli moje zupełne przeciwieństwo). jeżeli ktoś ma chociażby podstawową wiedzę na temat testowania przy wykorzystaniu Playwright, to dorzucenie do tego elementów związanych z dostępnością może przynieść naprawdę świetne efekty. Wyobrażam sobie, iż docelowo można objąć testami praktycznie wszystkie elementy, co do których mamy wątpliwości, przewidzieć co i gdzie powinno się na stronie znaleźć oraz przyjrzeć się spełnieniu każdego z kilkudziesięciu kryteriów WCAG.
Co prawda uzyskamy wtedy dziesiątki linijek kodu z informacją zwrotną, a nasze testy wykonywać się będą co najmniej godzinę, ale ej, kto Wam, testerzy, zabroni?
Wyobrażam sobie również wykorzystanie bardziej ogólnych, podstawowych testów przez programistów. Tych którzy chcieliby mieć ogląd na to, czy produkt, jaki planują wypuścić, jest jakkolwiek dostępny, czy może jednak warto przyjrzeć się tym grafikom bez altów, tabelkom bez tytułów i nagłówkom bez sensu. To dość szybki sposób na zorientowanie się w sytuacji i ewentualne skorzystanie z bardziej lub mniej gotowych rozwiązań.
Widzę też wady takiego rozwiązania – mam wrażenie, iż wiele z tych testów, które musimy zaimplementować, napisać i wykonać, w sposób równie dokładny a przy tym prostszy wykonują się same we wtyczkach czy narzędziach developerskich w przeglądarce. Jest to często ten sam poziom szczegółowości, a nie wymaga od nas przebrnięcia przez wielostronicową dokumentację, filmy na youTubie oraz przypadkowe posty na prehistorycznych forach.
Ja na pewno będę jeszcze zgłębiać temat automatycznych testów dostępności – jeżeli ktoś dotarł do tego momentu i ma do polecenia inne biblioteki/rozwiązania w tym zakresie, to bardzo chętnie się z nimi zapoznam. Na co dzień jednak wszystkie automaty będę przez cały czas wykorzystywać jedynie jako wstęp do pogłębionej, manualnej analizy. Może i pracochłonnej, ale dającej zdecydowanie najlepsze efekty.



