Witam w kolejnym odcinku serii o polskich firmach! Cały czas jesteśmy na etapie gromadzenia danych z publicznie dostępnych źródeł – żeby w przyszłości wyłapywać ciekawostki, jakich nie zdradziłyby nam choćby komercyjne wywiadownie gospodarcze.
W poprzednim wpisie poczyniłem pierwsze kroki w świat Monitora Sądowego i Gospodarczego – pisma z bieżącymi informacjami z życia polskich firm. W formie suchych danych, czyli najlepszej.
Zobaczyliśmy platformę, z której można pobrać to zacne pismo, i zerknęliśmy do metadanych w paru tysiącach plików.
Od tamtego czasu liczba moich Monitorów urosła do 2832 i sięga teraz początków roku 2011. Zajrzałem też nieco głębiej – w samą ich treść.
Zobaczymy, iż wyciąganie danych z Monitorów to bolesna sprawa. Ale można przy tym odkryć całkiem interesujące rzeczy:
- Kilkadziesiąt tysięcy wpisów jest wybrakowanych. Są całkiem lub prawie całkiem pozbawione treści albo mają luki w tekście.
- Liczba najgorszych przypadków była znacznie większa w 2020 roku niż w pozostałych latach.
- Czasem coś się w formacie zmienia, z roku na rok znikają niektóre kategorie błędów (na przykład trzy kreski zamiast niektórych numerów pól). Ale bywa, iż na ich miejsce przychodzą nowe.
- Literówki potrafią się trafiać choćby w miejscach, które w każdym rozsądnym świecie byłyby wypełniane przez komputer.
- Mimo błędów przez cały czas można liczyć pewne rzeczy. I zobaczyć na przykład, iż w roku 2020 ponad 15-krotnie wzrosła liczba przypadków zawieszenia lub wznowienia działalności. I jest ich coraz więcej.
- Programy do edycji plików mogą zostawiać w nich swój ślad. Zadziwiająco wiele informacji o tym, co i jak zmieniał użytkownik.
Zapraszam do śmieszno-strasznej wyprawy w głąb Piekielnie Denerwującego Formatu :smile:
Spis treści
- Wprowadzenie
-
W idealnym świecie
- Odczytywanie spisu treści
- Podział na kolumny i wpisy
- Przetwarzanie wpisów
- Porządkowanie szczegółów
-
W prawdziwym świecie
- Kłopotliwa konwersja
- Skubane spisy treści
- Kapryśne kolumny
- Nietypowe Monitory, ciąg dalszy
- Nikczemne nagłówki i wpisy-widma
- Tagi terroru i szokujące szczegóły
- Trzy kreski nicości
- Zawieszenie spółek
- Co dalej
Wprowadzenie
Gwoli przypomnienia: swoje Monitory pobrałem z oficjalnego źródła, ze strony Ministerstwa Sprawiedliwości.
Miałem 2832 egzemplarze. Od egzemplarza nr 1 z 2011 roku do egzemplarza 73 z tego roku. Prawie 8 gigabajtów na dysku, tylko czekających na obróbkę. Wszystkie w formacie PDF, o którym napiszę tutaj kilka słów, bo będzie dość istotny.
PDF to skrót od Portable Document Format. Do życia powołała go korporacja Adobe. To również format, w jakim dostępne są egzemplarze Monitora i wcześniej omawiane odpisy z KRS-u.
Jego głównym założeniem jest to, żeby na każdym urządzeniu wyświetlał się dokładnie tak samo. Tekst ma się nie rozjeżdżać i nie robić niespodzianek, a po wydrukowaniu wyglądać jak na ekranie.
Też miałem trochę założeń i nadziei, kiedy zaczynałem szperać w tych plikach. W pierwszej części wpisu zobaczmy, jak to powinno wyglądać, kiedy wszystko działa. W części drugiej zobaczymy gorzką rzeczywistość. Ale na osłodę będzie parę ciekawostek.
Ograniczam technikalia do minimum, więc wpis powinien być dostępny dla wszystkich. Ale jeżeli sprawy plików Cię nudzą, czytelniczko lub czytelniku, to można przeskoczyć prosto do śmieszkowania z gaf i dziwów.
W idealnym świecie
Konwersja
Pierwszy krok to wyciągnięcie z plików tekstu. Samo to byłoby ciężką sprawą, gdybym musiał pracować od zera. Na szczęście tę część już zrobili za mnie twórcy Popplera, zestawu programów do pracy z PDF-ami.
Od konwersji do tekstu mają pdftohtml – szybki, lekki i skuteczny programik konsolowy.
Postanowiłem sprowadzić tekst do formatu XML, w którym lepiej mi się pracuje. Ogólnie wystarczy do tego jedna komenda, wpisana w konsoli:
Parametr -i od tego, żeby nie wyciągać obrazków. Czyli w praktyce godła razy kilkaset.
Efektem działania są linijki tekstu wraz z informacjami o położeniu lewej i górnej krawędzi, rozmiarze czcionki, fragmentach pogrubionych.
Popplera można łatwo przywoływać przez Pythona, żeby przetwarzać pliki tysiącami, w sposób powtarzalny.
Odczytywanie spisu treści
Każdy Monitor liczy od kilkuset do ponad tysiąca stron i ma następującą strukturę:
- Okładka i ogólne informacje
- Spis treści
- Jakieś inne, nieinteresujące mnie ogłoszenia
-
Wpisy z życia firm
To ich szukam. Dzielą się na dwie sekcje: dla firm nowo założonych oraz dla zmian w firmach istniejących.
- Indeks (dawniej)
- Ostatnia strona
W trosce o swój niemłody komputer postanowiłem nie przetwarzać całego pliku jak leci, żeby potem odrzucać większość stron.
Zamiast tego ładuję tylko kilkanaście pierwszych stron pliku, odczytuję ze spisu treści numery stron, potem przetwarzam wyłącznie te strony.
Może i używam niewydajnego Pythona, ale hej! Zawsze to plus ileśtam do energooszczędności. Poza tym dzięki temu wyłapałem interesujące rzeczy w spisach treści, o czym później.
Podział na kolumny i wpisy
Po znalezieniu sekcji z informacjami o firmach trzeba ją jakoś przetworzyć. Przeciętna strona i przeciętny wpis wyglądają tak:

Tekst w Monitorze jest zawsze ułożony w trzy kolumny. To czytelne, ale dla człowieka; nam zależy na samych danych, więc dla wygody można to wszystko uprościć i „wypłaszczyć” zawartość kolumn i stron w jeden długi blok tekstu.
Potem trzeba jeszcze połączyć linijki. I nie jest to kwestia zwykłego sklejenia ich ze sobą. Trzeba bowiem pamiętać o rozbitych słowach.
Gdyby na końcu jakiejś linijki było moni-, a na początku kolejnej tor, to by to trzeba połączyć w jedno słowo, usuwając kreseczkę (oficjalnie: dywiz).
Ale gdyby kreseczka „dzieląca” pokrywała się z kreską wcześniej obecną w słowie, to już byłby problem. Fikcyjna Kasia Nowak-Słowak stałaby się Kasią NowakSłowak.
Na szczęście w tekście Monitorów odeszli od zaleceń typografii i zawsze dodają kreseczkę; jeżeli pokrywa się z istniejącą, to mamy po prostu dwie pod rząd, jedną można usunąć. Ogromne ułatwienie. Choć nie mamy go niestety w przypadku dat oraz nazw firm z nagłówka:

Jeśli dziwne kreski w ostatnim wpisie budzą Twoją ciekawość, to cierpliwości, jeszcze o nich będzie.
Ledwo co połączymy tekst w jeden blok, a już trzeba go ponownie rozbijać! Najpierw na wpisy, a następnie każdy wpis na pomniejsze wydarzenia.
Warto tu zaznaczyć, iż elementy wyraźnie wyróżniające nagłówek – szare tło i pogrubiona linia – niestety są nieobecne w XML-u stworzonym przez Popplera. Dysponujemy jedynie tekstem i znacznikami wskazującymi pogrubione fragmenty.
Ale w idealnym świecie to żaden problem! Przy tak powtarzalnej numeracji wystarczyłaby regułka w stylu:
znacznik pogrubienia + "Poz." + ciąg cyfr.
Rozbijając w takich miejscach, zdobędziemy długą listę wpisów. jeżeli dotarliśmy do tego etapu, to jest dobrze; choćby gdyby coś było nie tak z pojedynczym wpisem, to nie wpłynie to na resztę.
Zresztą w idealnym świecie żadnych problemów by nie było.
Przetwarzanie wpisów
Wpis jest napchany informacjami. Te z nagłówków łatwo wyciągnąć, pozostaje główna część z listą zmian w firmie. Która jest o tyle ciekawa, iż może tam być dowolna kombinacja zdarzeń.
W idealnym świecie pozwalają to okiełznać tagi (jak nazywam elementy zapisane pogrubionym tekstem). Nadają wpisowi strukturę i pozwalają zbierać informacje jak po sznurku.
Na każdym poziomie można się natknąć na tag wpisać albo wykreślić, który mówi nam, czy nasze dane oznaczyć plusem, czy też minusem.
Poza tym mamy tagi, które można nazwać strukturalnymi. Mamy wśród nich wyraźną hierarchię, odpowiadającą budowie KRS-u:
- dział,
- rubryka,
- podrubryka,
- numer pozycji,
- podrubryka wewnątrz pozycji.
Przy czym trzy ostatnie rzeczy pojawiają się tylko przy niektórych rodzajach zmian.
Dzięki takiej hierarchii wiemy jasno, co robić. Przechodząc na niższy poziom, gromadzimy coraz dokładniejsze informacje. Przechodząc z niższego na wyższy, możemy wszystkie zebrane informacje gdzieś zapisać i zacząć gromadzenie nowego kompletu.
Spójrzmy ponownie na przykładowy wpis. Tagi to w nim elementy pogrubione:

Po rozbiciu tego tekstu na najdrobniejsze pary (tag / tekst) przerabiamy go krok po kroku.
Dokładny opis metody-
Dz.3 /
(ustawiamy 3 jako numer działu)
-
Rub.2 / Wzmianki o złożonych dokumentach
(ustawiamy 2 jako numer rubryki, można też zapisać jej nazwę)
-
wpisać: /
(ustawiamy aktywny tryb)
-
1 / 1. data złożenia…
(ustawiamy 1 jako numer pozycji, a tekst odkładamy do jakiegoś schowka)
-
1 / 3. OD 01.01.2017…
(napotkaliśmy numer na tym samym poziomie hierarchii.
Po pierwsze: zapisujemy do naszej wielkiej listy zdarzeń komplet: tryb + dział + rubryka + numer + tekst;
Po drugie: tekst w schowku zastępujemy tym obecnym) -
1 / 4. OD 01.01.2017…
Jak wyżej; dodajemy poprzedni tekst do listy zdarzeń, jako drugi element. Dział, rubryka i inne rzeczy takie same.
Poza tym to ostatnia para, więc dodajemy do listy również tekst z niej, jako trzeci element.
Kończymy z trzema elementami; każdy z nich z działu 3, rubryki 2, pozycji 1.
Metodycznie i systematycznie. Nie jest to może najsprytniejszy sposób na przerobienie tych danych, ale jest niezawodny. W idealnym świecie.
Porządkowanie szczegółów
Po przypisaniu zdarzenia do odpowiednich działów, rubryk i tym podobnych możemy czasem je rozbić na drobniejsze szczegóły i pogrupować.
W kolejnych krokach, linijka po linijce:
Nie jest to obowiązkowe, ale może pomóc, jeżeli chcemy potem dokładniej przeczesywać dane albo stworzyć w bazie osobną tabelkę na pewne informacje (tu akurat o dokumentach finansowych, ale podobny format mają dane adresowe).
W ten sposób, wychodząc od wielkiego pliku PDF, stopniowo schodzimy coraz głębiej, dodając do naszej bazy wpis za wpisem, zdarzenie za zdarzeniem, szczegół za szczegółem.
OK. To tyle ze świata idealnego i przyjemnego. A teraz przejdźmy do rzeczywistości!
W prawdziwym świecie
Powiem wprost: właściwie każde moje założenie okazało się błędne.
Spis mówi prawdę? Numery zawsze będą pogrubione? Kolejność elementów będzie się zgadzała? A takiego!
Co się sprawdzało przy stu Monitorach, potrafiło efektownie się rozkraczyć przy sto pierwszym. Nie tylko przez moje braki warsztatowe (choć przyznaję się do nich pokornie), ale również przez liczne błędy w samych plikach.
W związku z tym przyzwyczaiłem się, iż co pewien czas odkładam na bok dziwne przypadki i biorę je „pod lupę”. Po załataniu problemu odpalam skrypt ponownie. Czasem wyskakiwało po tym jeszcze więcej błędów. Ale to akurat dobrze.
Nie oznaczało to, iż ich przybyło – tylko iż coraz lepiej je wykrywam.
W ten sposób, po kilku tygodniach hobbystycznego szlifowania, z czasem wyłoniło się coś znośnego. Będącego w stanie przerobić wszystkie Monitory (choć nie wszystkie wpisy) z ponad 10-letniego okresu.
Oczywiście choćby się nie łudzę, iż skrypt zawsze zadziała – z ciekawości pobrałem parę najstarszych Monitorów i widzę, iż od pewnego etapu zaczynają się skany pozbawione tekstu. Hurra.
Ale trzymajmy się tego, co mamy teraz. Przedstawiam wielką listę dziwów i zagwozdek :smile:
Kłopotliwa konwersja
Dla ludzkich oczu sprawa jest prosta. Patrzymy na tekst, widzimy słowa. Na przykład „z ograniczoną odpowiedzialnością”. Czytanie po prostu działa.
Ale za kulisami często jest inaczej; w trzewiach plików PDF mamy tylko krótkie fragmenty zdań – czasem choćby pojedyncze literki – oraz ich położenie na stronie. Żeby zrobić z tego ciągły tekst, programy muszą porównywać ich położenie i łączyć literki w słowa, słowa w zdania.
Prowadzi to do dość zaskakujących przypadków, na przykład spacji wewnątrz słów:
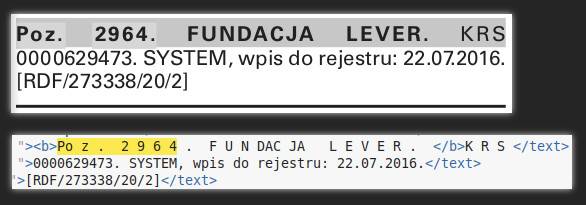
U góry wygląd w programie do czytania PDF-ów, u dołu XML od Popplera.
W Monitorze mamy normalny, czytelny tekst. Ale niektóre najważniejsze słowa w pliku XML (takie jak Poz.) są podzielone spacjami; skrypt musi zacząć od przeszukania tekstu i ściśnięcia ze sobą ich liter. Pierwsza rozbieżność względem świata idealnego.
A skąd się te spacje wzięły?
Możliwe, iż wina częściowo leży po stronie Popplera. Za kulisami PDF składa się z regułek graficznych. Być może najpierw tekst jest ustawiany w większych odstępach, a potem „ściskany” inną regułką? A Poppler jej nie wyłapuje i stąd rozbieżność między tym co widzimy a jego XML-em? Nie mam niestety na tyle czasu i umiejętności, żeby zajrzeć do jego kodu i to zbadać.
Natomiast zastanawia fakt, iż takie rzeczy trafiają się tylko w niektórych miejscach, zaś w innych nie. Może to oznaczać, iż prawdopodobnie ktoś manualnie majstrował przy danym wpisie.
Nie znam zaplecza KRS-u i Monitora, ale obstawiałbym następujący obieg informacji, od momentu wprowadzenia danych aż po strony Monitora:
- Ktoś zmienia jakieś informacje dotyczące swojej firmy.
W tym celu wpisuje nowe informacje w jakiś formularz (jeden standardowy szablon? A może są różne warianty?). - Informacje trafiają do systemu.
Od teraz można je pobrać w formie odpisów KRS. - Autorzy Monitora otrzymują swego rodzaju „wydruk” informacji z systemu. Układają to w postać względnie czytelną dla ludzi.
W centrum zdarzeń jest komputer. Zaś komputery są przewidywalne i często przechowują dane jako najprostszy tekst. Bez informacji o jakichś odstępach między słowami, bo dla nich to zupełnie niepotrzebne.
Dlatego, jeżeli na końcu wyjdą jakieś zmiany – zwłaszcza takie dotyczące pojedynczych przypadków, a nie wszystkich wpisów naraz – to prawdopodobnie zostały wprowadzone przez ludzi. A gdyby coś było bardzo powtarzalne, to prawdopodobnie wynika z winy komputera.
Oprócz tekstu rozstrzelonego trafiały się czasem zduplikowane linijki. Dla naszych oczu niewidoczne, bo idealnie się nakładają. Identyczne położenie, identyczny tekst, ta sama strona. Dla skryptu kłopotliwe, ale łatwe do usunięcia.
Takie coś mogło powstać na przykład wskutek manualnego edytowania wpisu, gdyby ktoś nacisnął Ctrl+C i potem Ctrl+V, wklejając go w tym samym miejscu. Nie znam działania programów do desktop publishingu, ale jeżeli bazują na warstwach, jak Gimp, to byłoby to całkiem możliwe.
Skubane spisy treści
„Zaufaj spisowi treści, mówili. Będzie fajnie, mówili”.
Pomysł, żeby kierować się spisem i nie czytać całego dokumentu, zwykle działał. Ale okazało się, iż numery podane w spisie mogą zawierać błędy. Musiałem dopisać parę regułek, żeby skrypt nigdy nie wierzył spisowi na ślepo i sprawdzał, czy znajduje się tam gdzie powinien.
Błędy w spisie dotyczyły zarówno numerów stron, jak i numerów wpisów. Występowały w różnych odmianach.
- Najprostszy – ewidentna literówka. Na przykład strona pierwsza ma numer wyższy niż ostatnia albo numery sekcji nakładają się na siebie.
- Groźniejszy – literówka wiarygodna. Kiedy wpisy dla firm powinny np. zaczynać się od strony 165, a tak naprawdę są od 156.
- Dziwny – całkowity brak numerów stron.
- Jeszcze dziwniejszy – literówka w innej, szablonowej części spisu treści.

Literówka z Monitora nr 23 z 2021 roku.
A ponieważ jesteśmy ludźmi kultury i nie polegamy na dowodach anegdotycznych, przedstawiam trochę statystyk. Różne braki w numeracji stron:
Rok 2018: 6
Rok 2019: 2
Rok 2020: 25
Rok 2021: 1
Rok 2022: 2
Liczba błędów w numeracji stron w spisie treści.
W roku 2020 dość mocno wzrosła liczba błędów w numeracji stron! Może się potwierdzać obserwacja z poprzedniego wpisu, iż ten rok był w jakiś sposób przełomowy.
Z kolei błędy w numerach wpisów, również zawartych w spisie treści, zwykle polegały na zamianie miejscami dwóch cyferek albo zgubieniu jednej.
To raczej „ludzkie” literówki, więc mamy argument za tym, iż spis treści nie jest przygotowywany ani sprawdzany przez komputer.
Kiedy dopracuję i upowszechnię skrypt, to polecam autorom wypróbować. Co jak co, ale liczenie wpisów działa dobrze i ułatwiłoby końcową korektę :wink:
Kapryśne kolumny
Po okiełznaniu spisu zabieramy się za nasz trójkolumnowy układ tekstu.
Ale czy na pewno? Okazuje się, iż niektóre elementy nie trzymają się reguł i potrafią zaczynać się w niestandardowych położeniach.
Nie nazwałbym tego błędem, ale na pewno jest pewnym odejściem od normy; zwykle mamy linijkę pod linijką. Nietypowe wymiary pojawiają się w XML-u od Popplera na przykład wtedy, kiedy tekst w Monitorze jest wyjustowany:
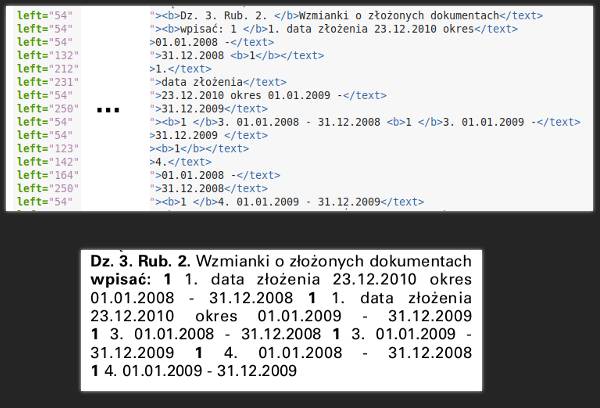
Wartość left pokazuje, gdzie zaczyna się dana linijka. Gdyby nie justowanie, mielibyśmy jedynie siedem linijek, jedną pod drugą.
Spójrzmy na liczbę stron, na których trafiały się elementy niepokorne, zaczynające się w nietypowym położeniu. Tym razem to nie rok 2020 przoduje, ale lata dawniejsze:
Rok 2012: 21839
Rok 2013: 262
Rok 2014: 75
Rok 2015: 265
(potem podobnie jak w 2015)
Liczba stron, na których były elementy leżące poza standardowymi kolumnami.
Liczba takich stron w dawniejszych latach jest powalająca.
Tak jak wcześniej pisałem – kiedy mamy do czynienia ze zmianami na wielką skalę, to prawdopodobnie winę ponosi komputer.
Z ciekawości odpaliłem jeszcze raz skrypt do gmerania w metadanych, którego użyłem podczas tworzenia poprzedniego wpisu (z tym iż wówczas na Monitorach nowszych). Okazało się, iż dla lat 2011-2012 wyszły dość interesujące rzeczy, które później już się nie pojawiały:
- w polu Page Size mamy wymiary 576 x 841.89 – inne od późniejszych, wynoszących w zaokrągleniu 595 x 842;
- w polu Title (zawierającym nazwę pliku, z którego stworzono PDF-a) pojawiły się pliki z rozszerzeniem .qxp. W nowszych Monitorach mamy już .indd, format od Adobe.
Wyszukałem, czym jest format .qxp i znalazłem informację, iż jest wykorzystywany przez program QuarkXPress. Bingo!
Mamy zatem mocny dowód na to, iż do roku 2012 ludzie z Ministerstwa pracowali w tym programie, a potem przeszli na programy od Adobe.
Ciekawostką poboczną może być to, iż QXP ostrzej sobie poczyna z plikiem, częściej rozbijając tekst na krótsze linijki. A przynajmniej tak to wygląda w „oczach” Popplera. Ma też ustawiony inny rozmiar stron.
W związku z tym możliwe, iż dałoby się ustalić na podstawie samych linijek tekstu, iż jakiś plik PDF został stworzony w Quarku. Byłyby jak odcisk palca, tylko iż dla programów, a nie internautów.
Mamy też znacznie rzadsze przypadki Monitorów, w których układ kolumn w całym dokumencie różnił się od tego typowego:
- z roku 2013: nr 228, 234, 240;
- z roku 2017: nr 165;
- z roku 2018: nr 166, 173.
Każda strona miała w nich trzy kolumny, tylko iż różniące się szerokością od typowych. Najbardziej prawdopodobna przyczyna to moim zdaniem użycie innych programów niż zazwyczaj, z odmiennymi ustawieniami. Może jakiś komputer się popsuł i pracowano na rezerwowym.
Nietypowe Monitory, ciąg dalszy
W poprzednim wpisie, patrząc na same metadane, znalazłem 8 Monitorów nie pasujących do reszty, z których aż połowę wydano w 2020 roku. Postanowiłem bliżej im się przyjrzeć i zobaczyć, czy wyróżniają się również pod względem błędów i dziwów.
Przy sześciu z nich – nie. Stety-niestety. Okazały się dość typowe. Parę braków miały, ale raczej z gatunku tych powszechniejszych. Albo coś przeoczyłem.
Natomiast dwa pozostałe Monitory potwierdziły swoją wyjątkowość również swoją zawartością:
-
Numer 22 z 2020 roku.
204 strony z nietypowym położeniem elementów. -
Numer 23 z 2020 roku.
192 strony z nietypowym położeniem elementów.
Do tego 2 rzadkie przypadki nałożonych na siebie, zduplikowanych linii.
To tym ciekawsze, iż w roku 2020 mój skrypt wykrył łącznie 464 przypadki stron odstających od trójkolumnowego standardu. Oraz 2 przypadki pokrywającego się tekstu.
Zatem te dwa Monitory, wydane jeden po drugim, odpowiadają za prawie 100% nietypowych stron w dokumentach w tamtym roku.
Obstawiałbym, iż ktoś je edytował dość intensywnie; w nietypowym programie (Adobe InDesign CS6, jeżeli wierzyć metadanym), może również niezgodnie ze wcześniej stosowanymi metodami.
Niestety nie dowiemy się, kto to był. Jak pisałem w poprzednim wpisie, pole Author w metadanych dla obu tych plików było puste.
To był gorący okres dla Ministerstwa Sprawiedliwości, zwłaszcza iż mówimy o dwóch egzemplarzach wydanych jeden po drugim. Może mają z tym jakiś związek zmiany kadrowe, które wypatrzyłem w poprzednim wpisie.
Rozwiązania zagadki na chwilę obecną nie mam. Ale możemy co najwyżej się zadziwić, iż garść metadanych i linijek tekstu potrafi tak wiele nam ujawniać. Fascynujące, nieprawdaż?
Nikczemne nagłówki i wpisy-widma
Elegancki, zgodny z kolejnością numer wpisu, a po nim kompletny nagłówek? W świecie idealnym tak było! Wystarczyło znaleźć tag od pogrubionego tekstu, potem słowo Poz., potem liczbę. W ten sposób wyłowilibyśmy każdy wpis. Po słowie KRS znalazłby się numer KRS. I tak dalej.
Ale nie. choćby w miejscach, które uważam za najbardziej szablonowe i powtarzalne, w sam raz do wypełnienia przez komputer, potrafiły pojawić się błędy:
- nagłówki nie zawsze były pogrubione;
- zdarzały się literówki w słowie Poz. albo brak spodziewanych spacji;
- czasem oprócz słowa ucięty był cały numer wpisu;
- innym razem numer wpisu się zgadzał, ale wnętrze nagłówka (najczęściej wokół słowa KRS) było „nadgryzione”.

Według moich statystyk błędne nagłówki to już na szczęście raczej melodia przeszłości :+1: Od kilku lat nie mamy na przykład uciętych i niekompletnych numerów wpisów:
Rok 2015: 4
Rok 2016: 14
Rok 2017: 26
Rok 2018: 25
Rok 2019: 4
Liczba wpisów z nagłówkiem uciętym na początku.
Całkiem wyginęły również błędy związane z brakiem numeru KRS w środku nagłówka:
Rok 2012: 4
Rok 2014: 1
Rok 2017: 12
Rok 2018: 37
Rok 2019: 1
Liczba wpisów z niekompletnym środkiem nagłówka.
Ale wstrzymajmy się z zachwytami. W nieco późniejszych latach tak się bowiem zdarzało, iż nagłówek był kompletny i elegancki… A wpisy zawierały wyłącznie pustkę. Ewentualnie samą informację o rubryce.

Błąd najbardziej dotkliwy, czyli wpisy całkiem pozbawione treści, to zdecydowanie rzecz współczesna; przybyły w roku 2018, a najszybszą ekspansję zaliczyły w latach pandemicznych:
Rok 2020: 13350
Rok 2021: 5530
Liczba wpisów całkiem pozbawionych informacji po nagłówku.
Miejmy nadzieję, iż ich zerowa liczba w tym roku już z nami zostanie.
Powoli wygasa również liczba wpisów niepełnych. Które też zaliczyły pewien skok w roku pandemicznym. Ale, o dziwo, wciąż nieporównywalnie mniejszy niż w latach 2015-2017:
Rok 2014: 26
Rok 2015: 7285
Rok 2016: 10235
Rok 2017: 11603
Rok 2018: 1180
Rok 2019: 863
Rok 2020: 1674
Rok 2021: 528
Rok 2022: 77
Liczba wpisów z nagłówkiem i śladowymi informacjami o rubryce.
Jeśli chodzi o analizę danych, te dwa rodzaje wpisów oznaczają kłopoty.
Z pustego i Salomon nie naleje, więc stajemy przed brutalną prawdą – Monitor Sądowy i Gospodarczy nam zwyczajnie nie da wszystkich potrzebnych informacji.
Ale hej, to nie koniec świata!
Lecz jeżeli chcemy, te wszystkie dziury miłością KRS-em da się załatać.
Inspiracja: motyw muzyczny z „Rodziny Zastępczej”.
Znając numery KRS z nagłówków, możemy kiedyś pobrać odpisy dla feralnych firm i zobaczyć, jakich informacji brakowało. Ale to sprawa na kolejny wpis. Tymczasem lećmy dalej; do tekstu tych wpisów, które w ogóle go mają.
Tagi terroru i szokujące szczegóły
Jeśli już udało się zebrać wpisy, a ich nagłówki były kompletne, to pozostało rozbijanie tekstu na części. Tutaj trafiłem na kilka rodzajów uciążliwości:
- Literówki w nazwach tagów (ub. zamiast Rub., pisać zamiast wpisać i tak dalej).
- Pogrubienie czegoś innego niż tag (rzadko).
- Niepotrzebne spacje w tekście.
- Literówki w miejscach innych niż tagi, na przykład w nazwach rubryk.
- Nagłe urwanie tekstu po tagu
(przykładowo: mamy Prub., tag oznaczający podrubrykę, a po nim koniec wpisu albo nowy dział).

Źródło: monitor nr 135 z 2018 roku.

W nazwach rubryk, takich jak „Dane wspólników”, znajdziemy często niepotrzebne spacje. Pod tym względem dominował rok 2017:
Rok 2016: 471
Rok 2017: 2336
Rok 2018: 1053
Rok 2019: 600
Rok 2020: 4
Rok 2022: 1
Liczba wpisów ze spacjami wewnątrz nazw rubryk.
Rok 2013 był z kolei rokiem literówek:
Rok 2012: 4
Rok 2013: 789
Rok 2014: 2
Rok 2015: 8
(potem też mało, po 2019 zero)
Liczba wpisów z literówkami w nazwach rubryk.
Na szczęście zarówno literówki, jak i spacje wewnątrz tagów stopniowo wygasają. Zostawiając nas z myślą: co w ogóle było ich źródłem? Jakieś dziwne ustawienia systemu? Czy może błędy ludzkie?
Rok 2020 ponownie dał o sobie znać również w przypadku tekstu wpisów. To w nim najczęściej występowały wpisy nagle urwane, zostawiające nas ze słowem PRub., strollowanych jak po usłyszeniu żartu o żółtych kuleczkach.
Rok 2019: 3
Rok 2020: 136
Rok 2021: 1
Liczba wpisów nagle urwanych po nazwie rubryki.
Patrząc na te i poprzednie rodzaje błędów, można się cieszyć, iż wiele z nich staje się coraz rzadszych. Ale jest coś, w czym rok 2022 zdecydowanie króluje – liczba niedomkniętych nawiasów.
Rok 2017: 111
Rok 2018: 206
Rok 2019: 198
Rok 2020: 161
Rok 2021: 187
Rok 2022: 354
Liczba niedomkniętych nawiasów w tekście wpisu.
Trzy kreski nicości
W toku rozbijania wpisów na szczegóły dość gwałtownie trafiłem na wpisy „wykreskowane”:

Jasnoszare prostokąty na dole dodane przeze mnie; wszystkie kreskowane braki już tam były.
Brakowało w nich jakiejś informacji – czasem o numerze działu, czasem o jakiejś szczegółowej wartości – a zamiast niej były trzy kreski. O takie:
Długa, długa, krótka. W alfabecie Morse’a byłaby to literka G. Jak sami wiecie co.
Jak pomiętamy, powtarzalne zachowanie oznacza prawdopodobnie błąd po stronie systemu; być może tak reaguje, kiedy nie wie co wpisać.
Na szczęście większość wpisów z lukami była poza tym kompletna, więc można było odczytać, o jaką firmę i zdarzenia chodzi, a potem to sprawdzić w KRS-ie:
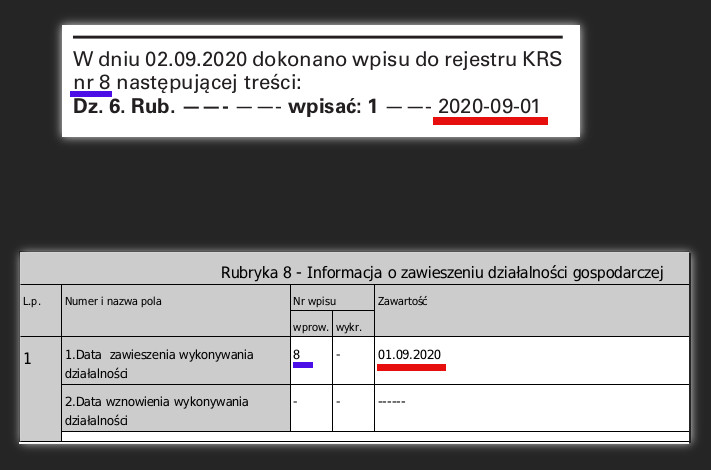
Braki danych dotyczące Działu 6 najczęściej wiązały się z zawieszaniem albo wznawianiem działalności. System z jakiegoś powodu nie lubi tej rubryki i ciągle pojawia się ona w Monitorze z kreskami zamiast informacji.
Potraktowałem ją jak osobny przypadek i oddzieliłem od innych przykładów luk. Zaraz do niej wrócimy.
A na razie skupię się na luce pokazanej na początku, dotyczącej przeważnie dość rzadkiej kategorii przedsiębiorstw państwowych.
To dość interesujący przypadek; z jednej strony brak danych, więc wina komputera. Ale z drugiej strony występuje tylko przy konkretnych wpisach.
Może nam to sugerować, iż przedsiębiorstwom państwowym odpowiadała oddzielna część systemu albo ich wpisy były dodawane osobnym kanałem. I gdzieś po drodze system dostawał czkawki od ich danych.
Luki tego rodzaju, gdy mamy kreski zamiast na przykład numeru rubryki, są już na szczęście w zaniku. Ostatnią mieliśmy w 2020 roku:
Rok 2015: 26
Rok 2016: 32
Rok 2017: 21
Rok 2018: 2
Rok 2019: 3
Rok 2020: 1
Liczba wykreskowanych luk zamiast numerów działów (nie licząc tych we wpisach dotyczących zawieszenia firm).
Ale kreski zamiast tagów oraz wpisy związane z zawieszonymi firmami i tak są rzadkie w porównaniu z kreskami obecnymi w zwykłym tekście, czyli w informacjach szczegółowych. Spójrzmy tylko na ich liczbę w podziale na lata:
Rok 2012: 7307
Rok 2013: 8604
Rok 2014: 8269
Rok 2015: 98832
Rok 2016: 97461
Rok 2017: 51956
Rok 2018: 66
(później coraz mniej)
Liczba wykreskowanych luk zamiast niektórych informacji szczegółowych (nie licząc tych we wpisach o zawieszeniu firm).
W roku 2012 ich liczba wprost eksplodowała! W roku 2015 ponownie. A potem, w 2018 roku, nagle się gwałtownie skurczyła i taka już została.
Wyjaśnienie jest proste; najczęstszym źródłem takich luk była numeracja pól dotyczących e-maili, stron internetowych i klasyfikacji PKD. Trzy kreski pojawiały się dosłownie w każdym takim przypadku, więc nie dziwota, iż jest ich tak wiele.

Być może w 2018 roku komuś w końcu przestały podobać się kreski i ustawił problematycznym rubrykom jakiś numer. Większość luk wyparowała z dnia na dzień.
Ale nie zniknęły całkowicie; te, które zostały, są mniej konsekwentne.
Czasem brakuje numeru lokalu (co akurat ma sens… tylko czemu po prostu go nie olać zamiast wypluwać trzy kreski?). Czasem nazwiska. Na razie nie dostrzegam w tym reguły.
Zawieszenie spółek
W końcu, po tych wszystkich walkach z błędami, możemy wyłowić interesujące informacje. Nie patrząc choćby na szczegóły z wnętrza wpisów, tylko na luki oraz numery działów.
Jak widzieliśmy, dział dla spółek zawieszonych rządzi się swoimi prawami.
Gdyby ktoś chciał policzyć, ile spółek się zawiesiło, to nic by nie dało wyszukiwanie w pliku słów w stylu „zawieszenie”. Ono od dawna zwyczajnie się nie pojawia.
Zwrotem kluczowym dla poszukiwaczy jest zamiast tego „Dz. 6”.
Bowiem, jak wspomniałem wyżej, rubryka z trzema kreskami nicości w połączeniu z numerem działu równym 6 oznaczają zawieszenie lub wznowienie działalności. Zawsze.
Wiedząc o tym, można policzyć takie wpisy. I zobaczyć istotną zmianę w roku 2020.
Przypomnę, iż Monitor dotyczy danych z KRS-u, czyli tylko spółek od jawnej wzwyż. Gdybyśmy chcieli patrzeć, jak zamykają się jednoosobowe działalności, musielibyśmy zajrzeć do CEIDG.
Nie wszystko to zawieszenia, ponieważ niekompletne wpisy dotyczą również wznowień. Natomiast myślę, iż dość prawdziwa będzie teza: „w kwestii zawieszania i wznawiania zaczęło się dużo dziać”.
Rok 2012: 127
Rok 2013: 189
Rok 2014: 205
Rok 2015: 492
Rok 2016: 396
Rok 2017: 327
Rok 2018: 228
Rok 2019: 163
Rok 2020: 3809
Rok 2021: 7657
Rok 2022: 3681
Średnia dla lat od 2011 do 2019 wynosi 245 zawieszeń/wznowień na rok.
W 2020 mamy ich 3809, czyli ponad 15 razy więcej. Jakby tego było mało, w 2021 liczba wzrosła dwukrotnie. Miejmy nadzieję, iż są wśród nich wznowienia!
A w tym roku? Według moich Monitorów już prawie dogoniliśmy stan z końca 2020. A przypominam, iż nie jesteśmy choćby w połowie.
Co dalej
Dzięki za wspólną podróż po meandrycznych drogach Monitora! Jej efektem jest komplet danych na temat firm, od roku 2011 do teraz, zapisanych w jednoplikowej bazie danych. Co dalej?
Przede wszystkim chętnie podzieliłbym się skryptem, który pozwolił mi to wszystko przetworzyć i policzyć błędy.
Ale pozwolę sobie chwilę z tym poczekać – czuję, iż jeszcze przyda się parę szlifów. A nie chcę robić jak CD Projekt i martwić się łataniem wszystkiego po fakcie :wink:
Poza tym, jak zobaczyliśmy w tym omówieniu, niektóre wpisy z Monitora są zwyczajnie puste. Dopóki ich nie uzupełnię informacjami z KRS-u, nie można mówić o kompletnych danych.
Kolejny wpis będzie dotyczył wielkiej fuzji – połączenia skryptu od KRS-u (który jest w stanie wyciągać i wizualizować informacje, ale tylko wybrane) z tym od Monitora (który zbiera znacznie więcej, ale na razie nic z tym nie robi).
Przy okazji spojrzymy na jeden szczególnie wredny przypadek brakujących wpisów i spróbujemy się z nim uporać.
Do zobaczenia!