Cotygodniowa dawka linków, czyli archiwum newslettera Dane i Analizy
Wiecie kto generuje najwięcej ruchu w internecie? Kiedyś to było porno i torrenty (albo inne sposoby wymiany plików peer-to-peer). Teraz układ wygląda jak na poniższym obrazku, przynajmniej według danych opublikowanych przez serwis Statista.
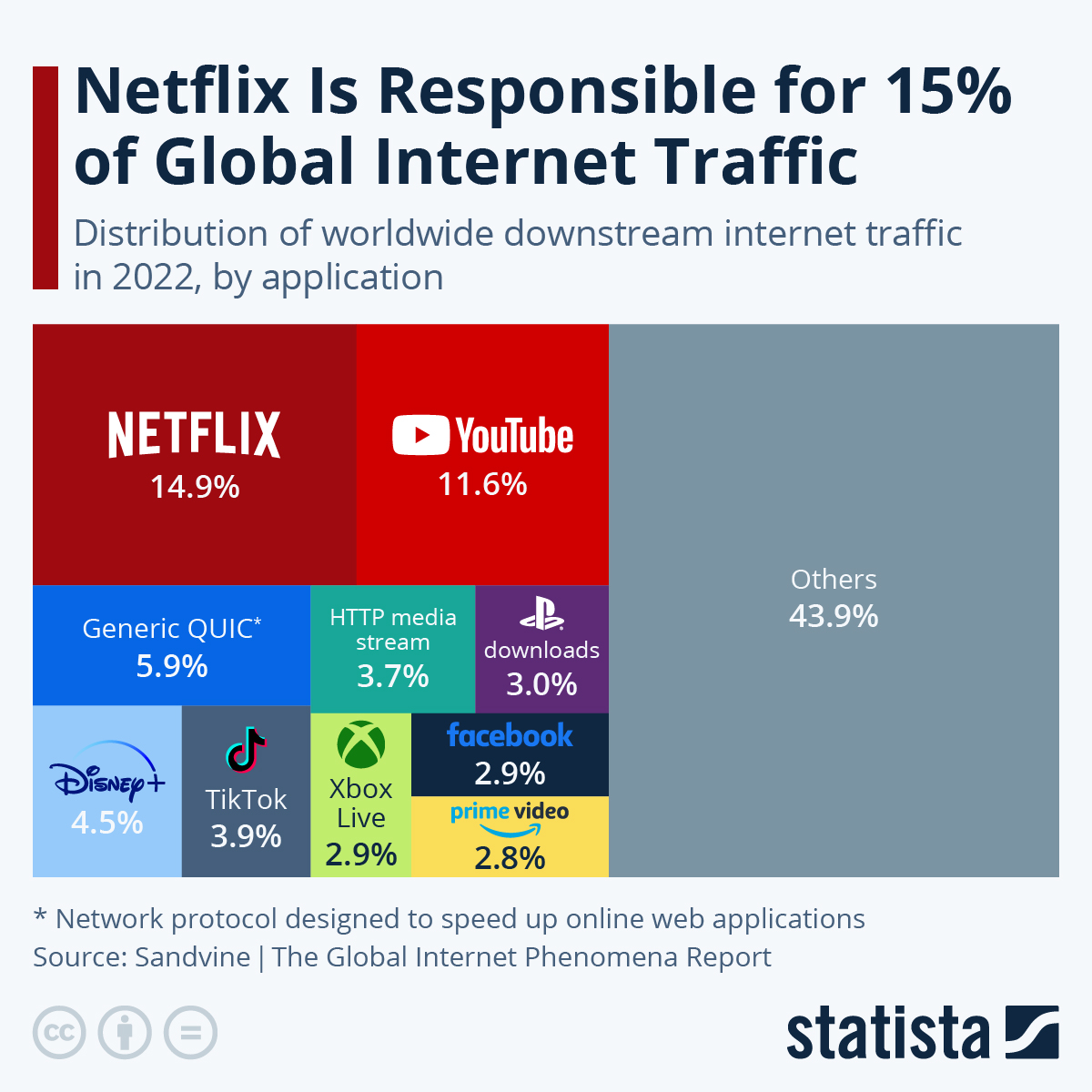
Dzisiaj bardzo dużo treści - oraz eksperyment - polskie tytuły (ale przeważnie angielskie teksty). Wśród tych tekstów sporo o Apache Spark i konkretnych wykorzystaniach albo rozwiązaniach konkretnych problemów.
Znajdziecie też kilka fajnych tekstów o różnego typu problemach rozwiązywanych przez analizę czy modele danych (rekomendacje w Netflixie, OHE i Pandas), gorąco polecam tekst o Apache Arrow.
Dajcie proszę znać, czy polskie tytuły coś ułatwiają czy tylko wprowadzają w błąd (bo pod linkiem jednak jest angielski tekst). A może to bez różnicy?
Mam też przyjemność powiedzieć, iż wraz z Maćkiem - moim przełożonym z korporacji, w której na co dzień pracuję - będziemy opowiadać pierwszego kwietnia o tym jak to "Big Data i sztuczna inteligencja w jednym (stały) domu, pod dachem największego polskiego ubezpieczyciela" w ramach Warszawskich Dni Informatyki. jeżeli masz ochotę - zapraszam. Będzie głównie o Apache Kafka, o tym jak jej używamy oraz o tym, jakie projekty w młodym, dynamicznym zespole zrealizowaliśmy w ciągu ostatnich 3-4 lat.
#analiza_danych_koncepcje
12 sposobów na testowanie Twoich prognoz
Analitycy danych zawsze koncentrują się na znalezieniu najlepszego modelu dla swojego zestawu danych. Jednak często zapominają o tym, jak istotny jest wybór najlepszej metody szacowania wydajności. Jak znaleźć najlepsze podejście do szacowania wydajności prognoz szeregów czasowych spośród 12 proponowanych w literaturze strategii?
Analiza klasyfikacji binarnej dzięki binclass-tools
Zobacz co to krzywe kalibracji, wykresy wzmocnienia i wzrostu - mierniki które pomogą ocenić jakość modeli klasyfikacyjnych
#analiza_danych_projekty
Ukryte klejnoty Netflix (finał sezonu)
Tworzenie systemu rekomendacji - budowanie i wdrażanie. TF-IDF, odległość kosinusowa, dane z IMDb oraz Streamlit
Apache Kafka i model ML
Implementacja systemu rekomendacji Netflix opartego na uczeniu maszynowym przy użyciu Apache Kafka i Python
#big_data
Budowanie prostego centrum danych
Miejsce na dane, kawałek obliczeniowy, orkiestrator całości - to zostanie zbudowane w ramach tego tutorialu. Domowe centrum danych oparte na Dockerze
Spark, Dask czy Ray?
Wybieramy framework do obliczeń rozproszonych
A może Redpanda zamiast Apache Kafka?
Kafka jest de facto standardem w przesyłaniu strumieniowym. Redpanda to platforma do strumieniowego przesyłania danych - bez Javy, w C++, kompatybilna z Kafką. Kai porównuje obie platformy (na swój sposób, #pdk)
#ciekawostki
Jak sztuczna inteligencja może pomóc w automatyzacji HR?
W kilku obszarach HR można wdrożyć rozwiązania ułatwiające albo optymalizujące pracę dzięki uczenia maszynowego. W jakich?
Sortowanie 400 zakładek w Chrome w 60 sekund
Otwierasz dużo zakładek? A potem nie potrafisz sobie z nimi poradzić? Może przyda się wtyczka do Chrome? Przygotujmy taką korzystając z JavaScript, Rust i (oczywiście bez AI się nie obędzie ;-) GPT-3
#management
Dlaczego detaliści nie stosują zaawansowanej analizy danych?
Zaawansowane narzędzia analityczne są dostępne dla firm od lat i są coraz lepsze, ale z kilkoma dużymi wyjątkami większość sprzedawców detalicznych przez cały czas korzysta z bardzo podstawowych narzędzi. Robią to, mimo iż rozumieją korzyści, jakie analityka dała ich konkurentom. Co powstrzymuje ich przed pełniejszym wykorzystaniem analiz?
#mlops
Najlepsze praktyki MLOps (na rok 2023)
Artykuł podsumowuje kurs MLOps Engineering z Coursery - może warto go przeczytać przed rozpoczęciem kursu?
Najlepsze narzędzie do orkiestracji dla MLOps
Porównanie trzech najpopularniejszych frameworków
#python
Klasy w Pythonie
Wprowadzenie do programowania obiektowego
Tworzenie mapy odległości dla całego miasta
Mapowanie izochronowe przy użyciu sieci grafów i map folium dla wielu punktów jednocześnie - brzmi strasznie, ale chodzi o dość prostą rzecz
One Hot Encoding i Pandas
Możesz bezpiecznie używać pandas.get_dummies do aplikacji uczenia maszynowego, wystarczy odrobić pracę domową!
Apache Arrow pod płaszczykiem PyArrow - co warto wiedzieć?
Apache Arrow dla Pythona - w postaci PyArrow - to coś pomiędzy Pandas a Sparkiem. Warto poznać ogólne możliwości i cechy tej biblioteki, bo Pandas 2.0 ma z niej mocno korzystać. Znając PyArrow wiadomo czego się spodziewać (szybciej, bardziej wydajnie w gospodarowaniu pamięcią)
#spark
Nowojorskie taksówki i PySpark
Dziewięć pytań zadanych przy okazji jednego zbioru danych i szukanie odpowiedzi z użyciem Sparka
Rzutowanie typów danych w PySpark
Data zakupu, liczba produktów i ich cena - wszystko stringiem. Jak często masz do czynienia z takimi danymi? Jak sobie radzisz ze zmianą typów w Sparku?
Potoki uczenia maszynowego: SciKit-Learn kontra Apache Spark MLlib
Implementacje kodu dla potoków ML: od surowych danych do predykcji, dla porównania w dwóch frameworkach. Bo jak ktoś zna SciKit-Learn to będzie mu łatwiej przejść do Sparka
Ograniczenie przesyłania zależności w aplikacjach sparkowych
Każdego dnia inżynierowie danych LinkedIn przesyłają prawie 30 milionów (!) zależności do HDFSa w celu uruchamiania aplikacji Spark
#ux
Wywiady z użytkownikami 1-0-1
Jak przygotować się i jak przeprowadzić wywiady z użytkownikami? Dla badaczy wiedza podstawowa!
#środowisko_pracy
CodeGPT - pomocnik programisty (w VSCode)
Dodatek do VSCode piszący kod za Ciebie. Czy produkty Jetbrains to mają? ;-)
Zestawienie linków przygotowuje automat, wybacz więc wszelkie dziwactwa ;-)








