To niesamowite, na co sztuczna inteligencja już powala, a tymczasem naukowcy przesuwają granice jej możliwości jeszcze dalej. Microsoft właśnie zaprezentował możliwości sztucznej inteligencji VASA-1, której wystarczy pojedyncze zdjęcie i próbka audio, aby stworzyć realistyczne wideo przedstawiające mówiącą osobę.
Wideo na podstawie pojedynczego zdjęcia
VASA-1 to dzieło naukowego projektu. Microsoft nie ma w planach komercjalizacji jego rezultatów. Nie zamierza udostępniać go też nikomu za darmo, ale może to i lepiej, biorąc pod uwagę to, jak realistyczne rezultaty VASA-1 produkuje.

Jak już wspomniałam we wstępie, VASA-1 tworzy krótkie materiały wideo na podstawie pojedynczego zdjęcia i próbki audio. Są to materiały o rozdzielczości 512 x 512 pikseli i 40 FPS-ach. Mowa o materiałach wideo, bohater których przemawia do nas tak, jakby po prostu został nagrany. Sztuczna inteligencja zadbała w ich przypadku nie tylko o realistyczny ruch ust mówiących osób, ale również realistyczną mimikę i ruch głowy.
Okej, na próbkach, którymi podzielił się Microsoft widać, iż coś jest nie tak – iż to materiały stworzone przez sztuczną inteligencję. Niektóre ruchy głowy czy ust przedstawionych na nich postaci zdają się zbyt płynne. Część postaci również charakterystycznie „pulsuje” na ekranie – nie ważne czym zarejestrowalibyśmy człowieka na wideo, takie zjawisko nie będzie miało miejsca. Myślę jednak, iż nie potrzeba byłoby wielu godzin pracy, aby sztuczną inteligencję udoskonalić i te błędy wyeliminować.
Sztuczna inteligencja o przerażających możliwościach
Co ważne, Microsoft stworzył przy użyciu VESA-1 wszystkie demonstracyjne animacje na podstawie obrazów, które wcześniej również zostały wygenerowane przez sztuczną inteligencję. Innymi słowy, żadna z nich nie przedstawia żyjącego, prawdziwego człowieka. Tylko jedno wideo nie powstało w oparciu o obraz wygenerowany przez AI – wideo z Mona Lisą. Zupełnie inaczej jest jednak w przypadku audio. Zauważyłam, iż firma wykorzystała w demonstracji audio z fragmentu występu komika Jimmy’ego O Yanga – ciekawe, czy uprzednio go o tym poinformowała.
Najbardziej zaskakujące jest to, iż sztuczna inteligencja VESA-1 potrafi generować realistyczne animacje choćby na podstawie typów obrazów i form audio, które nie były częścią danych, na których ją wytrenowano. Mowa na przykład o obrazach namalowanych, a jeżeli chodzi o audio – o nagraniach śpiewu czy mowy w języku innym niż angielski.
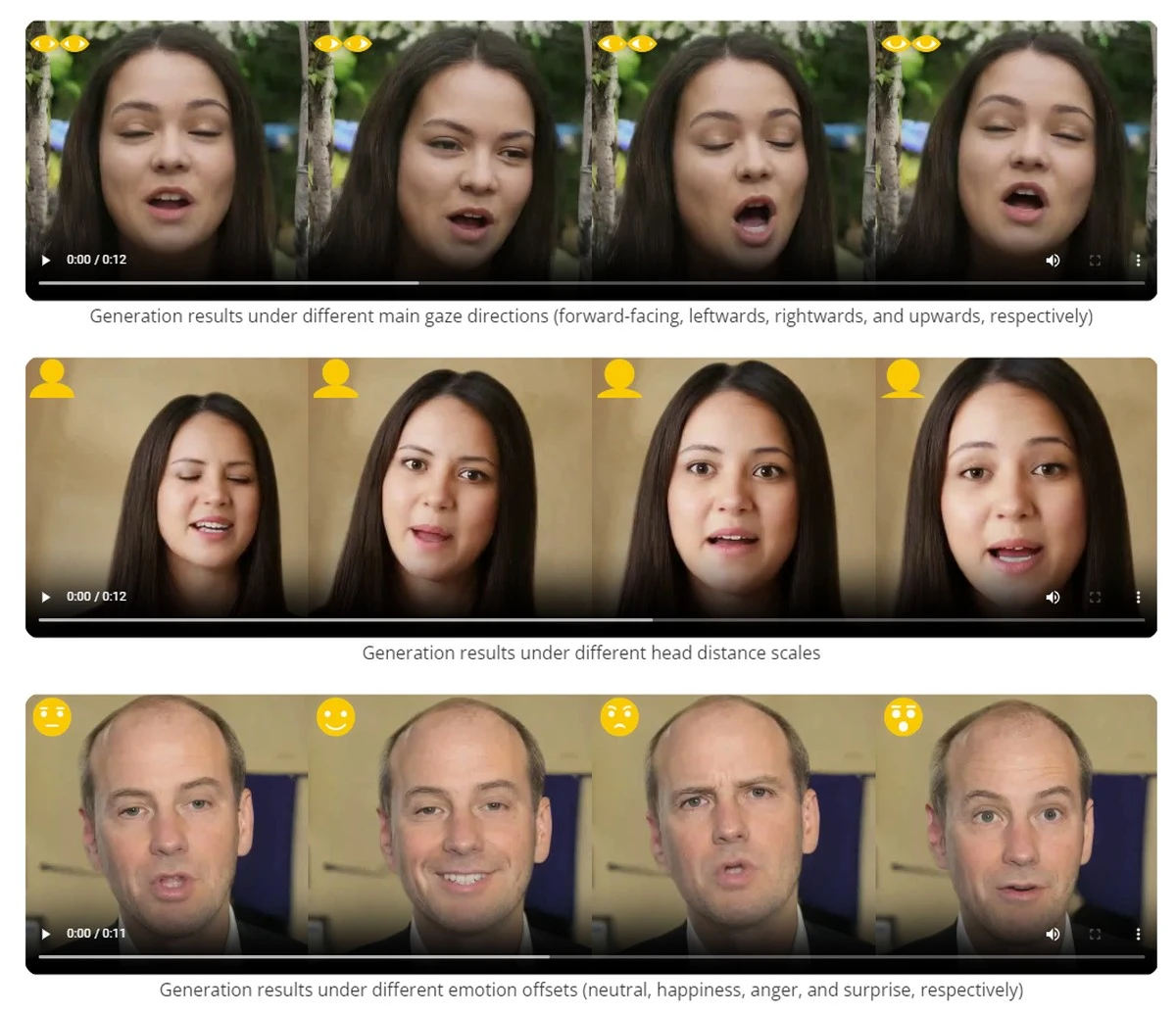 VASA-1 daje człowiekowi duża kontrolę nad ostatecznym wyglądem tworzonych materiałów. | Źródło: Microsoft
VASA-1 daje człowiekowi duża kontrolę nad ostatecznym wyglądem tworzonych materiałów. | Źródło: MicrosoftDziwi również to, jak wielką kontrolę nad powstającą animacją ma osoba, która korzysta z modelu VESA-1. Jak możemy zobaczyć na filmie Microsoftu, taka osoba może zmienić ton głosu bohatera filmu, jego szybkość i głośność mowy czy ustawienie bohatera filmu w kadrze.
Prawdę mówiąc mam nadzieję, iż podobna technologia nigdy nie będzie publicznie dostępna. Wyobraźcie sobie, jak wiele szkód mogłyby wyrządzić tworzone z jej użyciem deepfake’i.
Źródło: Microsoft, fot. tyt. Microsoft








