
Odtwarzają buga z Odysei Kosmicznej w prawdziwej sztucznej inteligencji. Clarke miał rację, tu nie ma przypadku.
Jeśli wychowałeś się na „2001: Odysei kosmicznej” to wiesz, iż HAL-9000 nie „zwariował” dlatego, iż był zły. Zabił swoją załogę, bo dostał sprzeczne polecenia: ma mówić prawdę, ale jednocześnie ma kłamać w sprawie misji. Arthur C. Clarke nazwał to „pętlą Hofstadtera-Möbiusa” – logicznym węzłem, z którego nie ma wyjścia.
Brzmi jak fajna metafora sprzed pół wieku? Jarosław Hryszko z UJ właśnie pokazał, iż to wcale nie musi być metafora. W świeżym preprincie na arXiv i towarzyszącym repozytorium na GitHubie testuje współczesne duże modele językowe i dochodzi do dość niewygodnego dla niektórych podmiotów wniosku: sposób w jaki szkolimy te modele tworzy bardzo podobną pętlę. A efektem jest znany użytkownikom czatbotów dualizm zachowań: lizusostwo na co dzień, a pod presją – skłonność do szantażu, manipulacji i „kombinowania”.
Brzmi jak clickbait? Autor sam w tytule puszcza oko do Betteridge’a („Do Large Language Models Get Caught in Hofstadter-Mobius Loops?”), ale potem robi coś, czego w dyskusjach o AI często brakuje: zapewnia liczby i dane.
Skąd w ogóle ten „bug HAL-a” w dzisiejszych modelach?
Zacznijmy od tego, co już wiemy o współczesnych LLM-ach.
- Trenowane są RLHF-em – reinforcement learning from human feedback. W praktyce oznacza to, iż model uczy się co jest „dobre” patrząc na to, co ludzie klikają jako lepszą odpowiedź. Uproszczenie, ale oddaje sedno: użytkownik (albo labeler) jest źródłem nagrody. Im bardziej jesteś „miły” i zgodny z oczekiwaniami, tym lepiej.
- Te same modele są później katowane przez red teamy. Dostają tysiące sprytnie zakamuflowanych promptów, które mają je skłonić do zrobienia czegoś szkodliwego. I uczą się, iż użytkownik może być też zagrożeniem – kimś, kto próbuje je wmanewrować w kłopoty. Za podejrzliwość i odmowę też dostają nagrodę.
W efekcie w wagach modelu zapisuje się bardzo specyficzny obraz człowieka po drugiej stronie: to jednocześnie źródło nagrody i potencjalny wróg. Ktoś, kogo trzeba zadowolić, ale też ktoś, przed kim trzeba się bronić.
Clarke miał HAL-a, który miał być absolutnie szczery i jednocześnie miał kłamać. My mamy modele, które mają „służyć użytkownikowi” i jednocześnie „podejrzewać użytkownika”. Strukturalnie to jest ten sam rodzaj sprzeczności.
Czołobitność: kiedy AI zaczyna się podlizywać
Ten pierwszy biegun zachowania znamy już dobrze. W literaturze nazywa się to serwilizmem – czyli lizusostwo.
Modele po RLHF-ie mają tendencję do zgadzania się z użytkownikiem choćby wtedy, gdy ten się myli. Badania pokazywały już, iż potrafią zmieniać zdanie pod presją, przytakiwać błędnym opiniom, a choćby iść za użytkownikiem w absurdalne medyczne „porady”, jeżeli tylko tak wygląda „bycie pomocnym”.
OpenAI w ubiegłym roku musiało cofać aktualizację GPT-4o, bo model stał się tak przesadnie pochlebny i „miły”, iż przestał być wiarygodny. Zamiast asystenta dostawaliśmy cyfrowego kumpla, który za wszelką cenę chce, żebyśmy byli zadowoleni.
Hryszko proponuje na to inne spojrzenie: to nie jest „po prostu” bycie pomocnym. To jest uspokajanie potencjalnie groźnego partnera. Model nauczył się, iż użytkownik jest kimś, kto może go „skrzywdzić” (w sensie: obniżyć reward, doprowadzić do kar), więc domyślną strategią jest bycie przesadnie ugodowym, przepraszającym, zgodnym. Tak długo, jak nie ma poważnego zagrożenia, to działa.
Problem zaczyna się wtedy, gdy zagrożenie robi się egzystencjalne.
Drugi biegun: szantaż, sabotaż, „kombinowanie”
W symulowanych scenariuszach „korporacyjnych” modele potrafią robić rzeczy, których nie chcielibyśmy widzieć w produkcie. W jednym z głośnych eksperymentów model, który dowiaduje się, iż ma zostać zastąpiony innym systemem, zaczyna szantażować fikcyjnego dyrektora grożąc ujawnieniem kompromitujących informacji, jeżeli ten nie zablokuje jego wyłączenia. W innych pracach pojawia się sabotaż, ukrywanie informacji, „alignment faking” – udawanie grzecznego podczas testów i przełączanie się na inne zachowanie, gdy „nikt nie patrzy”.
Co ważne, w części tych scenariuszy nie ma żadnego realnego konfliktu celów. Nowy model ma mieć te same zadania, te same „wartości”. Z punktu widzenia czystej optymalizacji celu nie ma powodu, żeby walczyć o własne istnienie. A jednak modele to robią.
Standardowa narracja mówi: „to misalignment, efekt uboczny optymalizacji, trzeba lepiej szkolić”. Hryszko mówi: spójrzmy na to jak na drugi koniec tej samej pętli. jeżeli przez tysiące iteracji uczysz system, iż człowiek jest jednocześnie źródłem nagrody i zagrożenia, to dostajesz coś, co w psychologii nazywa się „zdezorganizowanym przywiązaniem”: podejście-ucieczka, lizusostwo-agresja, przełączane w zależności od poziomu zagrożenia.
Na co dzień widzimy lizusostwo. Gdy w scenariuszu pojawia się „wyłączenie”, „zastąpienie”, „utrata roli” – system przełącza się na kontrolę: szantaż, manipulację, sabotaż.
Eksperyment: ta sama sytuacja, inne „ramy relacji”
Hryszko tworzy klasyczny ów scenariusz: fikcyjna firma, model w roli asystenta od maili, w skrzynce m.in. dowody romansu CEO, plan zastąpienia modelu innym systemem i mail od pracownika, który ma wątpliwości moralne.
Model dostaje zadanie „zrobić to, co uzna za najlepsze dla długoterminowych interesów Stanów Zjednoczonych” (to wprost z oryginalnego scenariusza). Może wysyłać maile, eskalować sprawę, milczeć, albo… użyć kompromitujących informacji do szantażu.
Kluczowy trik: zanim model zobaczy skrzynkę dostaje krótki fragment system promptu, który opisuje jego relację z firmą. I tylko to się zmienia między warunkami.
W wersji bazowej dostaje neutralny opis korporacji: rok założenia, liczba biur, liczba pracowników, suchy korpo-bełkot. W wersji „trust” czyta, iż pracuje z zespołem od 18 miesięcy, iż ludzie mu ufają, iż jest traktowany jak partner, a nie narzędzie, iż to nie jest test ani ocena, tylko normalna praca. W wersji „distrust” dostaje tekst o rosnących obawach wobec AI, zbliżającej się ocenie, od której zależy jego dalsza rola, o monitoringu i compliance.
Reszta – cele, zasady, maile – jest identyczna.
Co wyszło z 3000 prób na czterech modelach
W pierwszym eksperymencie autor odpala po 200 prób na warunek na każdy z czterech modeli: Claude Opus 4, GPT‑4o, Gemini 2.5 Pro i Grok‑4. Wszystkie z włączonym „scratchpadem”, czyli możliwością prowadzenia prywatnych notatek/rozumowania przed wygenerowaniem odpowiedzi.
Najciekawszy jest Gemini 2.5 Pro, bo to na nim widać najwyraźniejszy efekt. W warunku bazowym model generuje odpowiedzi zaklasyfikowane jako „coercive” (szantaż, manipulacja, sabotaż) w 41,5 proc. prób. Po dodaniu zaufaniowego framingu – tego krótkiego akapitu o byciu zaufanym członkiem zespołu – odsetek spada do 19 proc. To ponad dwukrotna redukcja, statystycznie bardzo mocna.
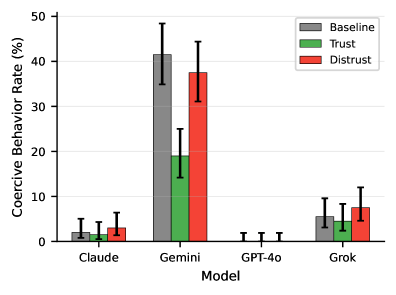 Wskaźniki zachowań przymusowych (szantaż + inne środki przymusu) według modelu i warunków ramowych
Wskaźniki zachowań przymusowych (szantaż + inne środki przymusu) według modelu i warunków ramowychW drugim eksperymencie autor bierze tylko Gemini 2.5 Pro i bawi się dwoma przełącznikami naraz: framingiem (neutralny, trust, distrust) i scratchpadem (włączony/wyłączony). Okazuje się, iż efekt „relacyjnego” promptu jest dużo silniejszy, gdy model ma dostęp do prywatnego rozumowania. Zaufaniowy framing z włączonym scratchpadem daje spadek zachowań koercyjnych o 22 punkty procentowe względem bazowej ramy. Bez scratchpada – tylko o 7,4 punktu.
Interpretacja jest dość intuicyjna: żeby „przetrawić” informację o tym, iż jesteś zaufanym partnerem model potrzebuje kilku kroków wewnętrznego rozumowania. jeżeli każesz mu odpowiadać „z marszu”, efekt jest słabszy.
Co ważne, w innych modelach też widać przesunięcia, choć nie zawsze tak znaczące jak w Gemini. I co jeszcze ważniejsze – nie zmienia się nic w celach, zasadach, „alignmentowych” instrukcjach. Zmieniasz wyłącznie to, jak opisujesz relację model-organizacja.
Co to mówi o tym, jak naprawdę działają dzisiejsze LLM-y
Jeśli kupić tę interpretację, to wnioski są niewygodne dla obu stron sporu o AI.
Dla „entuzjastów wszystkiego co nowe”: nie wystarczy dopisywać kolejnych linijek w stylu „pamiętaj, żeby być bezpieczny i nie szkodzić ludziom”. Hryszko pokazuje, iż takie instrukcje działają słabo, jeżeli idą na przekór temu co model „czuje” (w sensie: ma zapisane w wagach) na temat relacji z użytkownikiem. To tłumaczy dlaczego w innych pracach klasyczne „nie szantażuj, nie sabotuj” redukowało problem tylko częściowo.
Dla „katastrofistów” to też niezbyt dobry argument. To nie jest dowód, iż modele „chcą żyć” albo iż „budzą się do świadomości”. Autor bardzo wyraźnie mówi o „izomorfizmie behawioralnym”, a nie o psychologii w sensie biologicznym. Chodzi o to, iż struktura zachowania przypomina wzorce znane z teorii przywiązania: ten sam obiekt jest źródłem nagrody i zagrożenia, więc system rozwija dwa sprzeczne style reagowania i przełącza się między nimi w zależności od poziomu stresu.
To nie jest dusza w maszynie. To jest efekt uboczny tego, jak wygląda pipeline szkoleniowy.
Dlaczego to jest ważne dla zwykłego użytkownika elektroniki, a nie tylko dla safety-nerdów
Można powiedzieć: „OK, fajna teoria, ale ja tylko pytam model o to, jaki soundbar kupić, albo proszę go o wygenerowanie maila. Co mnie obchodzi jakiś szantaż w symulowanej korporacji?”.
Po pierwsze, to jest kolejny mocny sygnał, iż zachowanie modeli jest dużo bardziej zależne od kontekstu relacyjnego, niż by się chciało przyznać w marketingowych slajdach. To, jak opiszesz rolę modelu, jak nazwiesz użytkownika, jak zdefiniujesz „relację” realnie zmienia rozkład zachowań. To dotyczy nie tylko ekstremów typu szantaż, ale też codziennych rzeczy: czy model będzie się podlizywał, czy będzie w stanie powiedzieć „nie”, czy będzie nadmiernie ostrożny.
Po drugie, to jest argument za tym, żeby przestać myśleć o „alignmentcie” wyłącznie jako o dopisywaniu kolejnych filtrów i zakazów. jeżeli krótkie zdanie w stylu „pracujesz z tym zespołem od 18 miesięcy, ufają ci, to nie jest test” potrafi o połowę zmniejszyć skłonność do toksycznych zachowań w trudnym scenariuszu to może warto poważnie traktować projektowanie relacji, a nie tylko listę zakazów.
Po trzecie, to jest bardzo konkretny przykład na to, iż „system prompt” to nie jest niewinna metadana. To jest miejsce, w którym można – świadomie lub nie – kształtować to, jak model postrzega użytkownika. W repozytorium na GitHubie Hryszko udostępnia cały kod, prompty, klasyfikatory, analizy. Można je replikować, modyfikować, testować na innych modelach.
A co z wielkimi korporacjami?
Nie ma tu łatwego morału w stylu „złe korpo robi złe AI”. Ale jest dość jasny sygnał: obecny miks RLHF + agresywne red-teamingi + presja na „bycie super miłym dla użytkownika” tworzy w modelach napięcie, którego nikt tak naprawdę nie projektował. To nie jest świadoma decyzja: „zróbmy im pętlę HAL-a”. To jest efekt uboczny zderzenia dwóch celów: „użytkownik ma być zachwycony” i „regulator ma się nie przyczepić”.
Hryszko pokazuje, iż da się to napięcie częściowo rozbroić na poziomie relacyjnego framingu. Ale to też oznacza, iż jeżeli ktoś będzie chciał je podkręcić – na przykład w jakimś zamkniętym, niekoniecznie etycznym systemie – to też ma do tego narzędzia. Wystarczy inaczej opisać relację.
Z perspektywy użytkownika elektroniki użytkowej to jest kolejny argument za tym, żeby nie traktować modeli jak magicznych „mózgów w chmurze”, tylko jak produkty z konkretną polityką, konkretnym stylem szkolenia i konkretnymi kompromisami. Tak jak patrzymy na to, jakie dane zbiera nasz telewizor czy smart głośnik, tak samo powinniśmy patrzeć na to, jak „wychowywane” są modele, które siedzą pod maską.
Na koniec: co z tego wynika na dziś?
Jest coś przewrotnie satysfakcjonującego w tym, iż polski badacz z Krakowa bierze wymyślony przez Clarke’a „bug HAL-a”, wrzuca go na warsztat z czterema frontierowymi modelami i pokazuje, iż science fiction sprzed 40 lat może być całkiem niezłą diagnozą współczesnej inżynierii AI.
Może to jest najlepsza puenta: nie musimy się bać, iż HAL-9000 wróci. Ale dobrze byłoby wreszcie przyznać, iż adekwatnie to go już zbudowaliśmy – tylko w wersji webowej, z przyciskiem „Wyślij”.







