Uczenie maszynowe i jego zastosowania w biologii

Krzysztof Udycz
Ai Engineer
11. Januar 2021
Ostatni sukces DeepMind, który wykorzystuje sztuczną inteligencję do rozwiązania problemu formowania struktury przestrzennej białek (link), przez wiele osób postrzegany jest jako wazny przełom biologiczny, który może pomóc nam znaleźć skuteczniejsze metody leczenia chorób.
Zainspirowani tą wspaniałą wiadomością przygotowaliśmy krótkie wprowadzenie do tematu wykorzystania sztucznej inteligencji w biologii i jej potencjalnych zastosowaniach.
Kiedy i jak się to wszystko zaczęło?
Pod koniec lat 80. XX wieku rozpoczął się międzynarodowy projekt poznania ludzkiego genomu (ang. Human Genome Project), którego głównym celem było uzyskanie kompletnej sekwencji tworzącej ludzki genom. W 2003 roku, po kilkunastu latach pracy wielu zespołów naukowców ogłoszono sukces projektu, czyli zakończenie sekwencjonowania 99% genomu. Projekt poznania ludzkiego genomu przyczynił się do gwałtownego rozwoju nauk oraz technik biologicznych, a co za tym idzie do generowania coraz większej ilości informacji biologicznej.
Bez odpowiedniej analizy danych pozyskanych w wyniku różnych eksperymentów biologicznych stawianie jakichkolwiek tez i wniosków jest niemożliwe, ponieważ dane w postaci liniowych sekwencji nukleotydów czy aminokwasów nie niosą żadnych informacji. Ręczna ewaluacja takiej ilości danych jest w praktyce niewykonalna, dlatego z pomocą przychodzi nam dziedzina nauki łącząca zarówno biologię jak i informatykę, czyli bioinformatyka.
Czym jest bioinformatyka?

National Center for Biotechnology Information (NCBI) definiuje bioinformatykę jako interdyscyplinarną dziedzinę nauki, w której biologia, informatyka i informatyka łączą się ze sobą, aby umożliwić nowe odkrycia i spostrzeżenia biologiczne, a także pomóc stworzyć globalną perspektywę, na podstawie której można określić zasady biologii.
Mówiąc prościej: głównym celem bioinformatyki jest lepsze zrozumienie i poznanie funkcjonowania żywych systemów na poziomie molekularnym, poprzez rozwój algorytmów i narzędzi, a następnie zastosowanie tych algorytmów i narzędzi do generowania i analizy wiedzy biologicznej.
Zastosowanie sztucznej inteligencji w bioinformatyce

Dane biologiczne cechuje duża złożoność, np. można określić cztery poziomy uporządkowania struktury przestrzennej białka. Każdy z wspomnianych poziomów sprowadza się do struktury pierwszorzędowej, czyli do sekwencji aminokwasowej. Oddziaływania formujące strukturę białka zachodzą zarówno pomiędzy rożnymi poziomami jak i wewnątrz każdego poziomu. Widać zatem jak bardzo skomplikowana jest budowa cząsteczki białka.
Z pomocą przychodzi nam sztuczna inteligencja, która dzięki możliwości zapamiętywania pewnych wzorców i informacji oraz umiejętności przekładania nauczonych wzorców na nowe dane jest idealnym narzędziem wspomagającym bioinformatykę. Uczenie maszynowe jest dodatkowo bardzo pomocne podczas analizy ogromnych zbiorów danych oraz pozwala na redukcję, a choćby całkowitą likwidację błędu ludzkiego.
Machine learning, w kontekście nauk biologicznych, znajduje zastosowanie m.in. w genomice, proteomice, filogenetyce, biologii systemów, eksploracji tekstu, podczas analizy danych z mikromacierzy oraz w innych dziedzinach, które obejmują projektowanie primerów, rozpoznawanie obrazów czy zarządzanie danymi eksperymentalnymi.
Rycina 1. Sztuczna inteligencja oraz jej zastosowania w różnych obszarach biologii.
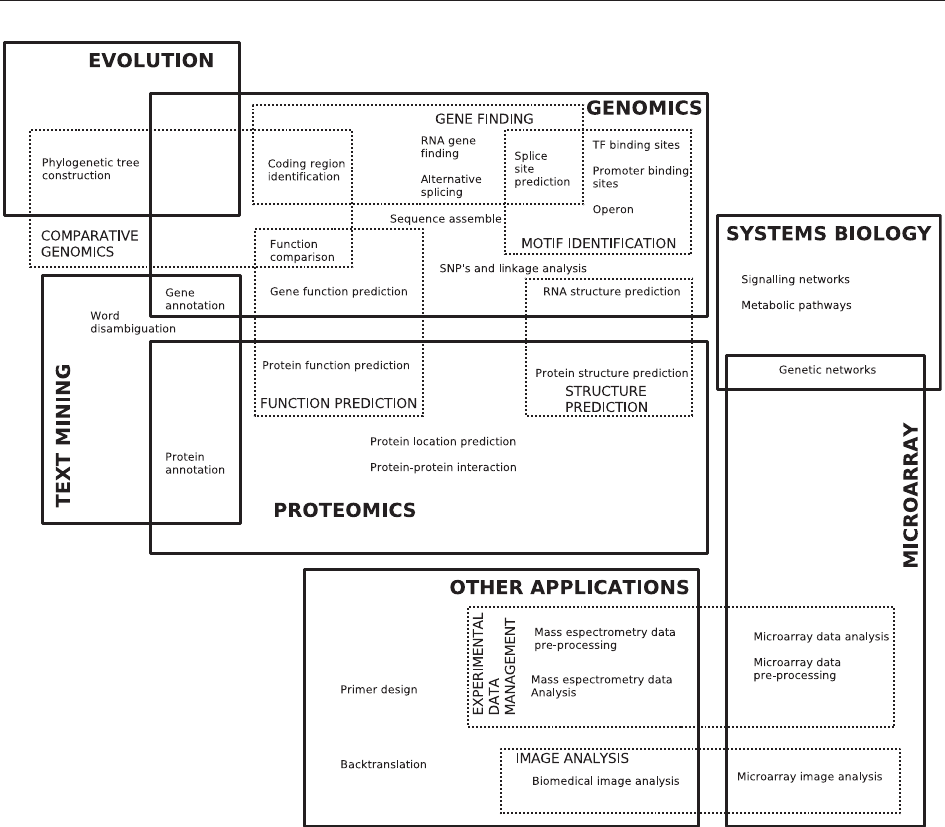
Źródło: Varma, D & Devarapalli, Dharmaiah & Tech, M. (2012). Comparative Analysis Of Classification Algorithm In Multiple Categories Of Bioinformatics. International Journal of Engineering and Technical Research. 1. 2012.
Modele uczenia maszynowego mogą zostać użyte do rozwiązania wielu problemów bioinformatycznych, takich jak:
- Określenie podobieństwa pomiędzy sekwencjami – przyrównanie sekwencji DNA, RNA, sekwencji białkowych
- Określenie podobieństwa filogenetycznego (pokrewieństwa) pomiędzy sekwencjami – konstrukcja drzewa filogenetycznego
- Identyfikacja wzorców/motywów – identyfikacja genów, intronów, alfa helis
- Analiza danych z mikromacierzy – określenie poziomu ekspresji genów
- Modelowanie molekularne i dokowanie – znalezienie położenia i konformacji liganda w miejscu wiążącym receptora
- Feature selection – dane biologiczne są wielowymiarowe i nie wszystkie niosą informacje, dlatego konieczne jest ich ograniczenie; wykorzystywane przy analizie ewolucji COVID-19
- Ustalanie struktur przestrzennych białek
- Klastrowanie genów w zależności od pełnionych funkcji – podział na grupy, które kodują blisko spokrewnione białka
- Kategoryzowanie i klasyfikacja nowych danych
Rozpoznawanie obrazów, czyli jedna z technik sztucznej inteligencji znajduje także zastosowanie w bioinformatyce. Computer vision wykorzystuje się podczas:
- Segmentacji obrazów – segmentacja żył, kości
- Analizy ilościowej – określenie ilości komórek rakowych u chorych na nowotwór
- Określenia lokalizacji – np. określenie lokalizacji FCD u chorych na epilepsję
- Wspomagania diagnostyki
- Rozpoznawania gestów – np. oszacowanie pozycji dłoni w celu wykrywania i monitorowania zaburzeń ruchowych, takich jak choroba Parkinsona
Rosnąca ilość danych sprawia, iż poszukiwane są coraz to nowsze techniki pozwalające na wydajną analizę i interpretację ogromnej ilości złożonych danych biologicznych. Z pomocą przychodzi nam uczenie maszynowe, które z łatwością radzi sobie z ewaluacją wyników eksperymentów, a dodatkowo odporne jest na często występujący błąd ludzki. Za sztuczną inteligencją przemawia fakt, iż oprócz biologii znajduje zastosowanie w wielu dziedzinach naszego życia m.in. w prawie, finansach, technologii czy ochronie.
Chcesz wiedzieć, jak AI może wspierać Twój biznes? Porozmawiajmy o twoim konkretnym scenariuszu i potrzebach.
Chcesz korzystać ze sztucznej inteligencji w swojej firmie?

Dołączyliśmy do programu Microsoft AI Inner Circle Partner

RODO: Wysokie kary za naruszenia przepisów
